在Spark shell中基于HDFS文件系统进行wordcount交互式分析
Spark是一个分布式内存计算框架,可部署在YARN或者MESOS管理的分布式系统中(Fully Distributed),也可以以Pseudo Distributed方式部署在单个机器上面,还可以以Standalone方式部署在单个机器上面。运行Spark的方式有interactive和submit方式。本文中所有的操作都是以interactive方式操作以Standalone方式部署的Spark。具体的部署方式,请参考Hadoop Ecosystem。
HDFS是一个分布式的文件管理系统,其随着Hadoop的安装而进行默认安装。部署方式有本地模式和集群模式,本文中使用的时本地模式。具体的部署方式,请参考Hadoop Ecosystem。
目标:
能够通过HDFS文件系统在Spark-shell中进行WordCount的操作。
前提:
存在一个文件,可通过下面的命令进行查看。
hadoop fs -ls /

如果不存在,添加一个(LICENSE文件需要在本地目录中存在)。更多hadoop命令,请参考hadoop命令。
hadoop fs -put LICENSE /license.txt
通过Web Browser查看Hadoop是否已经运行。
http://localhost:50070

步骤:
Step 1:进入Spark-shell交互式命令行。
spark-shell
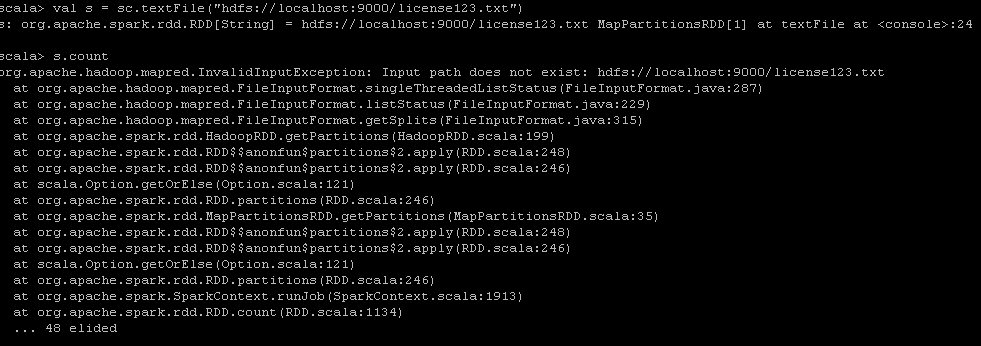
Step 2:读取license.txt文件,并check读取是否成功。如果不存在,则提示如下错误。
val s = sc.textFile("hdfs://localhost:9000/license.txt")
s.count
Step 3:设定输出的文件个数并执行统计逻辑
val numOutputFiles = 128
val counts = s.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _, numOutputFiles)
Step 4:保存计算结果到HDFS中
counts.saveAsTextFile("hdfs://localhost:9000/license_hdfs.txt")
Step 5:在shell中查看结果
hadoop fs -cat /license_hdfs.txt/*
结论:
通过HDFS,我们可以在Spark-shell中轻松地进行交互式的分析(word count统计)。
参考资料:
http://hadoop.apache.org/docs/r1.0.4/cn/commands_manual.html
http://spark.apache.org/docs/latest/programming-guide.html
http://coe4bd.github.io/HadoopHowTo/sparkScala/sparkScala.html
http://coe4bd.github.io/HadoopHowTo/sparkJava/sparkJava.html
在Spark shell中基于HDFS文件系统进行wordcount交互式分析的更多相关文章
- 在Spark shell中基于Alluxio进行wordcount交互式分析
Spark是一个分布式内存计算框架,可部署在YARN或者MESOS管理的分布式系统中(Fully Distributed),也可以以Pseudo Distributed方式部署在单个机器上面,还可以以 ...
- 输入DStream之基础数据源以及基于HDFS的实时wordcount程序
输入DStream之基础数据源以及基于HDFS的实时wordcount程序 一.Java方式 二.Scala方式 基于HDFS文件的实时计算,其实就是,监控一个HDFS目录,只要其中有新文件出现,就实 ...
- 52、Spark Streaming之输入DStream之基础数据源以及基于HDFS的实时wordcount程序
一.概述 1.Socket:之前的wordcount例子,已经演示过了,StreamingContext.socketTextStream() 2.HDFS文件 基于HDFS文件的实时计算,其实就是, ...
- Spark MLlib LDA 基于GraphX实现原理及源代码分析
LDA背景 LDA(隐含狄利克雷分布)是一个主题聚类模型,是当前主题聚类领域最火.最有力的模型之中的一个,它能通过多轮迭代把特征向量集合按主题分类.眼下,广泛运用在文本主题聚类中. LDA的开源实现有 ...
- 在spark udf中读取hdfs上的文件
某些场景下,我们在写UDF实现业务逻辑时候,可能需要去读取某个文件. 我们可以将此文件上传个hdfs某个路径下,然后通过hdfs api读取该文件,但是需要注意: UDF中读取文件部分最好放在静态代码 ...
- cloudera manager安装spark后使用spark shell编写基于scala的world count
val file = sc.textFile("hdfs://zhcloudil-lcnode04:8020/user/cloudil/wc_spark.txt") val cou ...
- Spark Shell简单使用
基础 Spark的shell作为一个强大的交互式数据分析工具,提供了一个简单的方式学习API.它可以使用Scala(在Java虚拟机上运行现有的Java库的一个很好方式)或Python.在Spark目 ...
- Hadoop Shell命令(基于linux操作系统上传下载文件到hdfs文件系统基本命令学习)
Apache-->hadoop的官网文档命令学习:http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html FS Shell 调用文件系统( ...
- Tachyon:Spark生态系统中的分布式内存文件系统
转自: http://www.csdn.net/article/2015-06-25/2825056 摘要:Tachyon把内存存储的功能从Spark中分离出来, 使Spark可以更专注计算的本身, ...
随机推荐
- angular resolve路由
import { Resolve, ActivatedRouteSnapshot, RouterStateSnapshot, Router } from "@angular/router&q ...
- Task 回调
前正无生意,且记录Task回调之用法. using System; using System.Collections.Generic; using System.Diagnostics; using ...
- C# LINQ(5)
目前都是说的单数据差距,如果多数据进行查询LINQ该如何呢? 那么LINQ就应该使用关键字 join on equals 现有代码: static void Main(string[] args) { ...
- session相关
判断session是否已失效: HttpSession session=request.getSession(false); getSession(boolean)相比于getSession()更安全 ...
- Scrapy 增量式爬虫
Scrapy 增量式爬虫 https://blog.csdn.net/mygodit/article/details/83931009 https://blog.csdn.net/mygodit/ar ...
- 【bzoj4007】[JLOI2015]战争调度 暴力+树形dp
Description 脸哥最近来到了一个神奇的王国,王国里的公民每个公民有两个下属或者没有下属,这种 关系刚好组成一个 n 层的完全二叉树.公民 i 的下属是 2 * i 和 2 * i +1.最下 ...
- 了解一个名词——GTD
概念:就是Getting Things Done的缩写,翻译过来就是“把事情做完”,是一个管理时间的方法. 核心理念概括:就是必须记录下来要做的事,然后整理安排并使自己一一去执行. 五个核心原则是:收 ...
- ubuntu 上的python不能解析jpeg,png?
在安装pillow之前需要先安装以下支持包1.apt-get install libjpeg-dev libfreetype6-dev zlib1g-dev libpng12-dev2.安装pillo ...
- SDK 开发 .a .framework .bundle (xcode引用) 依赖sdk工程
一. 静态库.a 1.创建静态库工程 Cocoa Touch Static Libray ,然后可以创建一个测试视图 TestView 2.暴露头文件 -> Build Phases--> ...
- shell-001:记录每天的磁盘情况
# shell-100只是为了练习!!适合新手! #!/bin/bash # 此脚本是记录每天的磁盘情况,记录保存30天! # 当前的日期 current_time=$(date +%F) # 保存的 ...