在Spark shell中基于HDFS文件系统进行wordcount交互式分析
Spark是一个分布式内存计算框架,可部署在YARN或者MESOS管理的分布式系统中(Fully Distributed),也可以以Pseudo Distributed方式部署在单个机器上面,还可以以Standalone方式部署在单个机器上面。运行Spark的方式有interactive和submit方式。本文中所有的操作都是以interactive方式操作以Standalone方式部署的Spark。具体的部署方式,请参考Hadoop Ecosystem。
HDFS是一个分布式的文件管理系统,其随着Hadoop的安装而进行默认安装。部署方式有本地模式和集群模式,本文中使用的时本地模式。具体的部署方式,请参考Hadoop Ecosystem。
目标:
能够通过HDFS文件系统在Spark-shell中进行WordCount的操作。
前提:
存在一个文件,可通过下面的命令进行查看。
hadoop fs -ls /

如果不存在,添加一个(LICENSE文件需要在本地目录中存在)。更多hadoop命令,请参考hadoop命令。
hadoop fs -put LICENSE /license.txt
通过Web Browser查看Hadoop是否已经运行。
http://localhost:50070

步骤:
Step 1:进入Spark-shell交互式命令行。
spark-shell
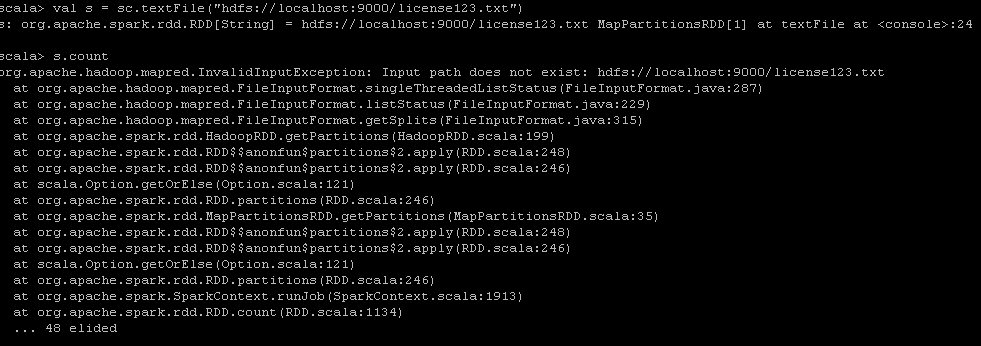
Step 2:读取license.txt文件,并check读取是否成功。如果不存在,则提示如下错误。
val s = sc.textFile("hdfs://localhost:9000/license.txt")
s.count
Step 3:设定输出的文件个数并执行统计逻辑
val numOutputFiles = 128
val counts = s.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _, numOutputFiles)
Step 4:保存计算结果到HDFS中
counts.saveAsTextFile("hdfs://localhost:9000/license_hdfs.txt")
Step 5:在shell中查看结果
hadoop fs -cat /license_hdfs.txt/*
结论:
通过HDFS,我们可以在Spark-shell中轻松地进行交互式的分析(word count统计)。
参考资料:
http://hadoop.apache.org/docs/r1.0.4/cn/commands_manual.html
http://spark.apache.org/docs/latest/programming-guide.html
http://coe4bd.github.io/HadoopHowTo/sparkScala/sparkScala.html
http://coe4bd.github.io/HadoopHowTo/sparkJava/sparkJava.html
在Spark shell中基于HDFS文件系统进行wordcount交互式分析的更多相关文章
- 在Spark shell中基于Alluxio进行wordcount交互式分析
Spark是一个分布式内存计算框架,可部署在YARN或者MESOS管理的分布式系统中(Fully Distributed),也可以以Pseudo Distributed方式部署在单个机器上面,还可以以 ...
- 输入DStream之基础数据源以及基于HDFS的实时wordcount程序
输入DStream之基础数据源以及基于HDFS的实时wordcount程序 一.Java方式 二.Scala方式 基于HDFS文件的实时计算,其实就是,监控一个HDFS目录,只要其中有新文件出现,就实 ...
- 52、Spark Streaming之输入DStream之基础数据源以及基于HDFS的实时wordcount程序
一.概述 1.Socket:之前的wordcount例子,已经演示过了,StreamingContext.socketTextStream() 2.HDFS文件 基于HDFS文件的实时计算,其实就是, ...
- Spark MLlib LDA 基于GraphX实现原理及源代码分析
LDA背景 LDA(隐含狄利克雷分布)是一个主题聚类模型,是当前主题聚类领域最火.最有力的模型之中的一个,它能通过多轮迭代把特征向量集合按主题分类.眼下,广泛运用在文本主题聚类中. LDA的开源实现有 ...
- 在spark udf中读取hdfs上的文件
某些场景下,我们在写UDF实现业务逻辑时候,可能需要去读取某个文件. 我们可以将此文件上传个hdfs某个路径下,然后通过hdfs api读取该文件,但是需要注意: UDF中读取文件部分最好放在静态代码 ...
- cloudera manager安装spark后使用spark shell编写基于scala的world count
val file = sc.textFile("hdfs://zhcloudil-lcnode04:8020/user/cloudil/wc_spark.txt") val cou ...
- Spark Shell简单使用
基础 Spark的shell作为一个强大的交互式数据分析工具,提供了一个简单的方式学习API.它可以使用Scala(在Java虚拟机上运行现有的Java库的一个很好方式)或Python.在Spark目 ...
- Hadoop Shell命令(基于linux操作系统上传下载文件到hdfs文件系统基本命令学习)
Apache-->hadoop的官网文档命令学习:http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html FS Shell 调用文件系统( ...
- Tachyon:Spark生态系统中的分布式内存文件系统
转自: http://www.csdn.net/article/2015-06-25/2825056 摘要:Tachyon把内存存储的功能从Spark中分离出来, 使Spark可以更专注计算的本身, ...
随机推荐
- c++基础之引用reference
1.何为引用 简单来说就是,比如你换了个新名字,用新名字叫你,你也会答应 2.引用vs指针 -引用没有null,好比你说你换了个新名字,但是新名字是啥总得有点东西 -一旦引用被初始化后就不可以指到另外 ...
- Python实现wc.exe
github传送门 项目相关要求 基本功能 -c file.c 返回文件file.c的字符数 (实现) -w file.c 返回文件file.c的词的数目(实现) -l file.c 返回文件file ...
- DELPHI XE5轻松输出到MacOsX
配置:MACOSX10.9.3 +XCODE5.1 + VBOX + WINXP + DELPHI XE 5UP2 配置步骤从略. 1.选择firemonkey desktop application ...
- 【C#】CLR内存那点事(高级)
对于这篇,不想再对值类型进行讨论,如要看值类型的内存怎么玩可以看一下(CLR内存那点事 初级),我们这篇主要讨论一下引用类型. 先来装备两个类 internal class Employee { pu ...
- android 多点触控
多点触控 1.多点触控从字面意思讲就是你用大于等于2根的手指触摸子啊手机屏幕上. Android中监听触摸事件是onTouchEvent方法,它的参数为MotionEvent,下面列举MotionEv ...
- 干掉MessageBox,自定义弹出框JMessbox (WindowsPhone)
先上效果图 QQ退出效果 ...
- cookie,session 的概念以及在django中的用法,以及cbv装饰器用法
cookie的由来: 大家都知道HTTP协议是无状态的. 无状态的意思是每次请求都是独立的,它的执行情况和结果与前面的请求和之后的请求都无直接关系,它不会受前面的请求响应情况直接影响,也不会直接影响后 ...
- 自动备份数据库crond
#!/bin/bash # export and backup the abgent_web database.sql mysqldump -uuser -ppassword ltden_db --s ...
- SDUT OJ 顺序表应用6:有序顺序表查询
顺序表应用6:有序顺序表查询 Time Limit: 1000 ms Memory Limit: 4096 KiB Submit Statistic Discuss Problem Descripti ...
- Spring Cloud-服务的注册与发现之服务注册中心(Eureka Server)
Spring cloud是为了什么产生的? 根据官网的这个介绍来看,我们可以知道,Spring cloud是为开发者提供的一个工具,而使用这个工具的产生就是为了帮助开发者快速的开发一套比较通用的分布式 ...