mysql实战优化之二:limit优化(大表翻页查询时) sql优化
mysql的表test中有20105119行数据。
建立索引:data_status,place_cargo_status
场景1:
SELECT
id,
resource_id,
resource_type,
...
F_OMCS_LINK_GET_DAY_BY_WORKDAY('2017-03-13',arrive_work_day,send_work_day,1,cargo_arrive_time),
load_zone_code,
cargo_send_batch,
F_OMCS_LINK_GET_DAY_BY_WORKDAY('2017-03-13',send_work_day,send_work_day,2,cargo_arrive_time),
cargo_arrive_next_batch,
F_OMCS_LINK_GET_DAY_BY_WORKDAY('2017-03-13',send_work_day,arrive_next_work_day,3,cargo_arrive_time),
next_zone_code,
...
FROM
test
WHERE
data_status=1 and place_cargo_status=1
LIMIT 0,10000
结果:查询时间为:7.360s
场景1:
SELECT
id,
resource_id,
...
F_OMCS_LINK_GET_DAY_BY_WORKDAY('2017-03-13',arrive_work_day,send_work_day,1,cargo_arrive_time),
load_zone_code,
cargo_send_batch,
F_OMCS_LINK_GET_DAY_BY_WORKDAY('2017-03-13',send_work_day,send_work_day,2,cargo_arrive_time),
cargo_arrive_next_batch,
F_OMCS_LINK_GET_DAY_BY_WORKDAY('2017-03-13',send_work_day,arrive_next_work_day,3,cargo_arrive_time),
...
FROM
test
WHERE
data_status=1
LIMIT 0,10000
结果:查询时间为:7.111s
场景三:
select * from test
WHERE
data_status=1 and place_cargo_status=1
LIMIT 0,10000
结果:查询时间为0.141s
场景四:
select * from test
WHERE
data_status=1
LIMIT 0,10000
查询时间为0.140s
查看执行计划:
场景四的执行计划:
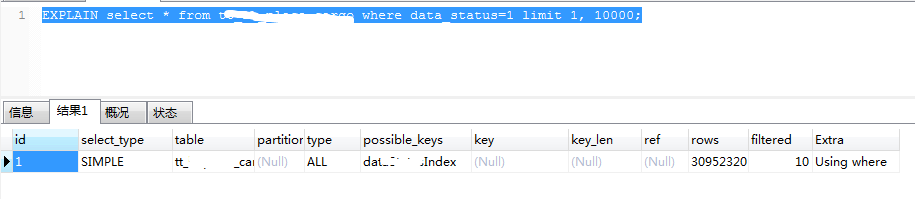
优化一:
如上type=all,是因为data_status是varchar型的,为其加单引号后,如下:

优化二:使用主键翻页,

测试结果如下:
select * from tt_lk_place_cargo where data_status='' and id between 20000000 and 20030000;
结果:使用时间0.381s

mysql实战优化之二:limit优化(大表翻页查询时) sql优化的更多相关文章
- MySQL大数据量分页查询方法及其优化
MySQL大数据量分页查询方法及其优化 ---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适 ...
- 如何对MySQL 对于大表(千万级)进行优化
如何对Mysql中的大型表进行优化 @(mysql 笔记) 收集信息 1.数据的容量:1-3年内会大概多少条数据,每条数据大概多少字节: 2.数据项:是否有大字段,那些字段的值是否经常被更新: 3.数 ...
- 1. 元信息:Meta类 2. 基于对象查询的sql优化 3. 自定义:Group_Concat() 4. ajax前后台交互
一.元信息 ''' 1. 元信息 1. Model类可以通过元信息类设置索引和排序信息 2. 元信息是在Model类中定义一个Meta子类 class Meta: # 自定义表名 db_table = ...
- SQL查询与SQL优化[姊妹篇.第四弹]
在上一篇文章中,我们一起了解了关系模型与关系运算相关的知识,接下来我们一起谈谈,面对复杂的关系数据,我们如何来优化,SQL如何玩转更优呢? 在上一篇中抛出了4个关于优化方面的问题: 1.返回表中0.0 ...
- 【1】MySQL大数据量分页查询方法及其优化
---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适应场景: 适用于数据量较少的情况(元组百/千 ...
- 大数据量高并发访问SQL优化方法
保证在实现功能的基础上,尽量减少对数据库的访问次数:通过搜索参数,尽量减少对表的访问行数,最小化结果集,从而减轻网络负担:能够分开的操作尽量分开处理,提高每次的响应速度:在数据窗口使用SQL时,尽量把 ...
- Oracle 表三种连接方式(sql优化)
在查看sql执行计划时,我们会发现表的连接方式有多种,本文对表的连接方式进行介绍以便更好看懂执行计划和理解sql执行原理. 一.连接方式: 嵌套循环(Nested Loops (NL)) (散列)哈希 ...
- SQL夯实基础(四):子查询及sql优化案例
首先我们先明确一下sql语句的执行顺序,如下有前至后执行: (1)from (2) on (3) join (4) where (5)group by (6) avg,sum... (7 ...
- Delete 语句带有子查询的sql优化
背景: 接到开发通知,应用页面打不开,让我协助... (开发跟我说,表GV_BOOKS一直有锁,锁了有1个多小时了,问我能不能把锁释放掉,我回答他们说,这肯定是sql性能问题,表上有锁是正常现象,不是 ...
随机推荐
- Treflection01_Class对象_构造函数_创建对象
1. package reflectionZ; import java.lang.reflect.Constructor; import java.util.List; public class Tr ...
- DPDK之(八)——vhost库
转:http://www.cnblogs.com/danxi/p/6652725.html vhost库实现了一个用户空间的virtio net server,允许用户直接处理virtio ring队 ...
- 四十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
Django实现搜索功能 1.在Django配置搜索结果页的路由映射 """pachong URL Configuration The `urlpatterns` lis ...
- zend studio 添加xdebug调试php代码
1.Eclipse下对于大部分语言都提供了调试器接口,自然的对于PHP,Zend已经集成了XDebug调试器,找到Zend中的Preferences->PHP->Debug, 将调试器设置 ...
- 通过Linux命令搭建测试环境里面的jdk
一.文件准备 1.1 文件名称 jdk-8u121-linux-x64.tar.gz 1.2 下载地址 http://www.oracle.com/technetwork/java/javase/do ...
- PhantomJS 和Selenium模拟页面js点击
由于自己不怎么会javascripts,无法找全所有的参数进行模拟提交,所以只能寻求Selenium和PhantpmJS的方式. 先说下ubuntu上怎么安装相应的环境,尤其PhantomJS安装比较 ...
- 详解 WebAPI 签名机制
首先,写这篇文章的原因是因为最近某一个项目中的接口被人为调用了,导致了数据库数据被串改.虽然是内部人无意点的,但还是引起了我的担忧,所有整理了下关于WebAPI的相关签名机制. 一.我们在开发接口时, ...
- js 取任意两个数之间的随机整数
function getRandomInt(min, max) { min = Math.ceil(min); max = Math.floor(max); return Math.floor(Mat ...
- Near Field Communication (NFC) applications
Near Field Communication (NFC) applications There has been little practical guidance available on NF ...
- 随机获取图片的api接口
http://lorempixel.com/1600/900 https://unsplash.it/1600/900?random(国内加载略慢) https://uploadbeta.com/ap ...