Robot Framework 使用总结
最近项目上使用了RF快速实现了一些验收测试的自动化case,感觉不错,很好用,下面就记录一下使用RF实现自动化的过程。
什么是RF?
RF是一种测试框架,帮助测试人员在其框架下快速实现验收测试的自动化。提供很多的扩展库供你使用,在没有任何一种语言编程基础的情况下也能实现一些自动化测试用例。
说白了,任何一种框架的作用就是帮你完成一些基础的工作,使你更加关注于要测试的业务逻辑,而不是关心技术细节,这些技术细节包括用例如何运行、如何组织、日志怎么记录,怎么展现,如何与CI集成等等。
使用RF框架与Jenkins CI工具结合,可以很容易的实现测试的远程部署、运行与结果展现。比起重写造轮子,自己写一套系统,这种方式还是快得多,最适合刚刚起步的项目。
RF能做什么?
RF能做什么取决于使用什么样的扩展框架,RF提供的默认内置库与外部扩展库,当然也可以自己写扩展库来定制功能。基本提供的库已经可以满足一般的测试需求了,包括对手机端、网页端的自动化测试,还有API接口的测试。
编写RF文件
RF文件通常以robot为后缀名,并且提供了很多的编辑工具,方便的进行robot文件的编辑。我使用的是pycharm的RF插件进行编辑,因为需要使用python写大量的扩展库,所以在pycharm里面统一进行robot与py文件的编辑,还是很方便的。或者使用官方的RIDE也是很好的选择,纯图形化界面,方便团队没有开发经验的人参与其中。
RF文件的结构
先看一个RF文件示例: 
如上所示,一个RF文件通常包括三个节点:
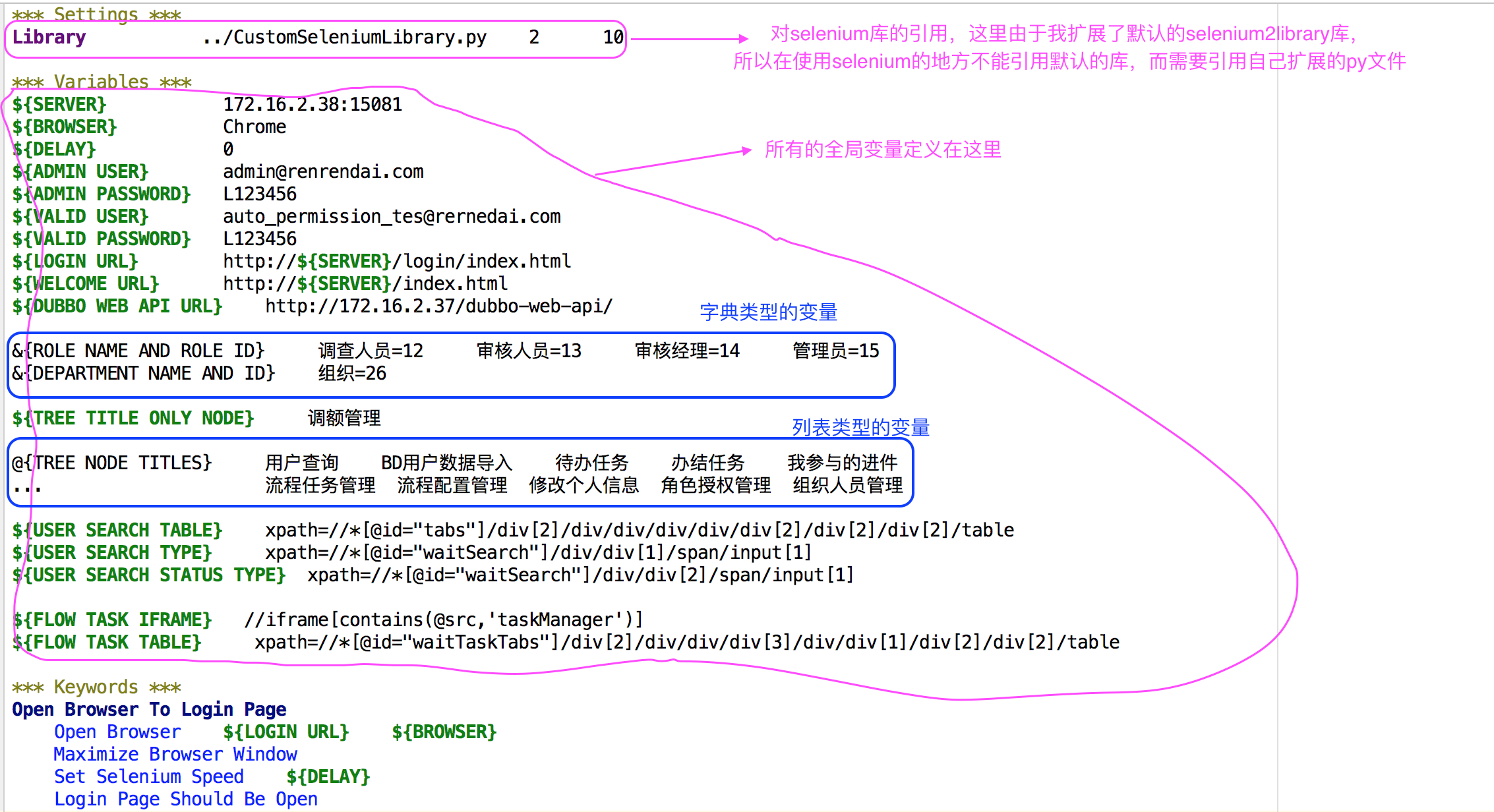
Settings节点:
1. 设置此test suite的setup与tearndown操作
2. 此test suite 中每个test case的setup与tearndown操作
3. 指定测试模板test template
4. 指定此test suite引用的资源文件的位置
5. 使用Library关键字引用RF标准库,或者自定义库:

Test Cases节点:
1. 可以定义一个普通的测试用例
2. 也可以调用模板,并给模板传入它所需要的参数
3. 测试用例里面所调用的关键词可能来自下面三个地方:
* 当前test suite文件的keywords节点中定义的keyword
* Setttings节点指定的资源文件中所定义的keyword
* 内建的BuiltIn库中定义的keywordKeywords节点:
1. keyword可以理解为一个公用的方法,供test case使用
2. keyword可以传入参数,返回结果
3. RF也提供很多逻辑判断IF,循环FOR等关键词
Resource资源文件的结构
其实resource文件与普通robot文件没多大区别,只不过它是被导入的库文件,通常用来定义一些公用的变量和keywords:
编写自己的Library文件
RF运行使用很多语言编写自己的Library文件,这里选择python编写,首先看一下对已存在的库文件的扩展
对selenium2library库文件的扩展:
# 导入Selenium2Library模块
from Selenium2Library import Selenium2Library模块
from selenium.common.exceptions import StaleElementReferenceException
import time def _get_table_field_value(element, field):
return element.find_element_by_xpath("./td[@field='" + field + "']").text.strip() # 继承Selenium2Library
class CustomSeleniumLibrary(Selenium2Library):
def get_table_row_count(self, table_locator):
attempts = 0
while True:
try:
table = self._table_element_finder.find(self._current_browser(), table_locator)
return len(table.find_elements_by_xpath("./tbody/tr"))
except StaleElementReferenceException:
time.sleep(1)
if attempts >= 1:
raise AssertionError("Cell in table %s could not be found." % table_locator)
else:
pass
attempts += 1 def get_user_search_results(self, table_locator, row_index):
table = self._table_element_finder.find(self._current_browser(), table_locator)
ret = []
if table is not None:
rows = table.find_elements_by_xpath("./tbody/tr")
if len(rows) <= 0:
return None
row_index = int(row_index)
if len(rows)-1 < row_index:
raise AssertionError("The row index '%s' is large than row length '%s'." % (row_index, len(rows)))
for row in rows:
dic = {
'userId': _get_table_field_value(row, 'userId'),
'nickName': _get_table_field_value(row, 'nickName'),
'realName': _get_table_field_value(row, 'realName'),
'mobile': _get_table_field_value(row, 'mobile'),
'idNo': _get_table_field_value(row, 'idNo'),
'userType': _get_table_field_value(row, 'userType'),
'verifyUserStatus': _get_table_field_value(row, 'verifyUserStatus'),
'operator': _get_table_field_value(row, 'operater'),
'operateTime': _get_table_field_value(row, 'operateTime'),
}
ret.append(dic)
return ret[row_index]
else:
return None ...
创建全新的库文件:
# -*- coding: utf-8 -*- from libs.DB_utils.utils import *
from libs.request_utils import utils
from libs.request_utils import flow_task_manage
from libs.global_enum import *
from libs.model import user_search_result
from robot.libraries.BuiltIn import BuiltIn
import time class VerifyLibrary(object): def __init__(self, base_URL, username, dubbo_web_base_URL=None):
self.base_URL = base_URL
self.username = username
self.request_utils = utils.RequestUtil(base_URL, username)
self.flow_task_request_utils = flow_task_manage.FlowTaskManage(base_URL, username)
self.built_in = BuiltIn()
if dubbo_web_base_URL is not None:
self.dubbo_web_request_utils = utils.RequestUtil(dubbo_web_base_URL) def update_verify_user_role(self, email, dept_id, role_id, amount_limit=5000):
real_name = get_verify_user_name_by_email(email)
verify_user_id = get_verify_user_id_by_email(email)
self.request_utils.login()
response = self.request_utils.update_verify_user(real_name, verify_user_id, amount_limit, dept_id, role_id)
return response.json()
注意VerifyLibrary的构造函数,需要最少传入两个参数,这是在robot文件引用此库文件的时候传入的: 
RF框架与Jenkins CI集成
使用Jenkins来运行RF写的test case很简单,首先需要在Jenkins上安装RF扩展插件:

然后,使用pybot命令行去运行写好的RF测试用例:

最后执行完测试后,可以在jenkins上很好的解析出测试结果的走势与具体的每个build的测试结果:


Robot Framework 使用总结的更多相关文章
- Robot Framework用户手册 (版本:3.0)
版权信息:诺基亚网络和解决中心 本翻译尊重原协议,仅用于个人学习使用 1.开始: 1.1 介绍: Robot Framework是一个基于Python的,为终端测试和验收驱动开发(ATDD)的可扩展的 ...
- RIDE -- Robot Framework setup
RobotFramework 是一款基于python 的可以实现关键字驱动和数据驱动并能够生成比较漂亮的测试报告的一款测试框架 这里使用的环境是 python-2.7.10.amd64.msi RID ...
- Robot Framework自动化测试 ---视频与教程免费分享
当我第一次使用Robot Framework时,我是拒绝的.我跟老大说,我拒绝其实对于习惯了代码的自由,所以讨厌这种“填表格”式的脚本.老大说,Robot Framework使用简单,类库丰富,还可以 ...
- Robot Framework 的安装和配置(转载)
Robot Framework 的安装和配置 在使用 RF(Rebot framework)的时候需要 Python 或 Jython 环境,具体可根据自己的需求来确定.本文以在有 Python 的环 ...
- 解决从jenkins打开robot framework报告会提示‘Opening Robot Framework log failed ’的问题
最新的jenkins打开jenkins robot framework报告会提示如下 Verify that you have JavaScript enabled in your browser. ...
- 在centos7中安装Robot Framework
安装前景介绍: 最初,我们是在Windows环境下搭建Robot Framework来对我们的服务进行接口测试的(想知道如何在Windows下安装Robot Framework,可以参考我同事的博客h ...
- 移动端自动化环境搭建-Robot Framework的安装
A.安装依赖 RF框架,robotframework本身. B.安装过程 可以通过下载 exe 程序进行安装,Robot Framework 分别提供了,win-amd64.exe 和 win32.e ...
- robot framework 安装配置
robot framework 是一款专门用作自动化测试的框架,提供了丰富的内置库,与第三方库,也支持用户自己编写的库,robot framework +library 可以 用来做ui的自动化测试, ...
- Robot Framework入门学习1 安装部署详解
安装注意: 目前Robot framework-ride不支持python3,安装时请下载python2.7版本. Robot Framework安装时出现了一点小问题,网上没有找到直接的介绍,现将安 ...
- Robot Framework自动化测试(七)--- jybot模式
虽然,很久不用关于Robot Framework框架了,但我这里应该是除了@齐涛-道长之外分享Robot Framework 相关资料比较多的地方了.所以,常常被问到一些关于该框架的问题. 虽然,我一 ...
随机推荐
- mysql命令 show slave status\G;命令输出详解
show slave status\G; 命令输出详解 mysql> show slave status\G; *************************** . row ******* ...
- 【转】关于一个Jmeter interface testing的实例
目标:测试某个保险系统的费率接口 准备:a 请求方式:Http b 接口地址://10.1.1.223:9090/rulesEngine/executeRateRule.do Jmeter 设置: a ...
- mysql索引之二:数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- Netty实现原理浅析
1.总体结构 先放上一张漂亮的Netty总体结构图,下面的内容也主要围绕该图上的一些核心功能做分析,但对如Container Integration及Security Support等高级可选功能,本 ...
- Jenkins设置自动发邮件
安装Jenkins方法详解:https://www.cnblogs.com/lizhe860/p/9901257.html 一.设置全局变量 从首页依次进入系统工具→系统设置 二.在项目配置中设置项目 ...
- spring mvc helloworld 和表单功能、页面重定向
Spring MVC Hello World 例子 这里有个很好的教程:https://www.cnblogs.com/wormday/p/8435617.html 下面的例子说明了如何使用 Spri ...
- 16c550芯片编写的优化
参考了 <Altera FPGA/CPLD 设计>高级篇, 关于状态机的推荐写法实现的功能是一样的但是编译使用的逻辑门如下图: 下图是我自己编的状态机需要的逻辑: 下图是使用推荐的有限状态 ...
- Py修行路 python基础(六)前期基础整理
计算机中,有且仅有CPU具有执行权限,能够执行指令的只有CPU! 人在应用程序上输入的文字或文本,叫做明文! 在屏幕上输入或是输出的是字符,计算机保存的是 有字符编码的 二进制数. 变量赋值规则:例如 ...
- 编写一个jQuery的扩展方法(插件)
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- IDA Pro 权威指南学习笔记(五) - IDA 主要的数据显示窗口
在默认配置下,IDA(从 6.1 版开始)会在对新二进制文件的初始加载和分析阶段创建 7 个显示窗口 3 个立即可见的窗口分别为 IDA-View 窗口.函数窗口和消息输出窗口 可以通过 View - ...