python 下载小说
以下载官场风月小说为例:
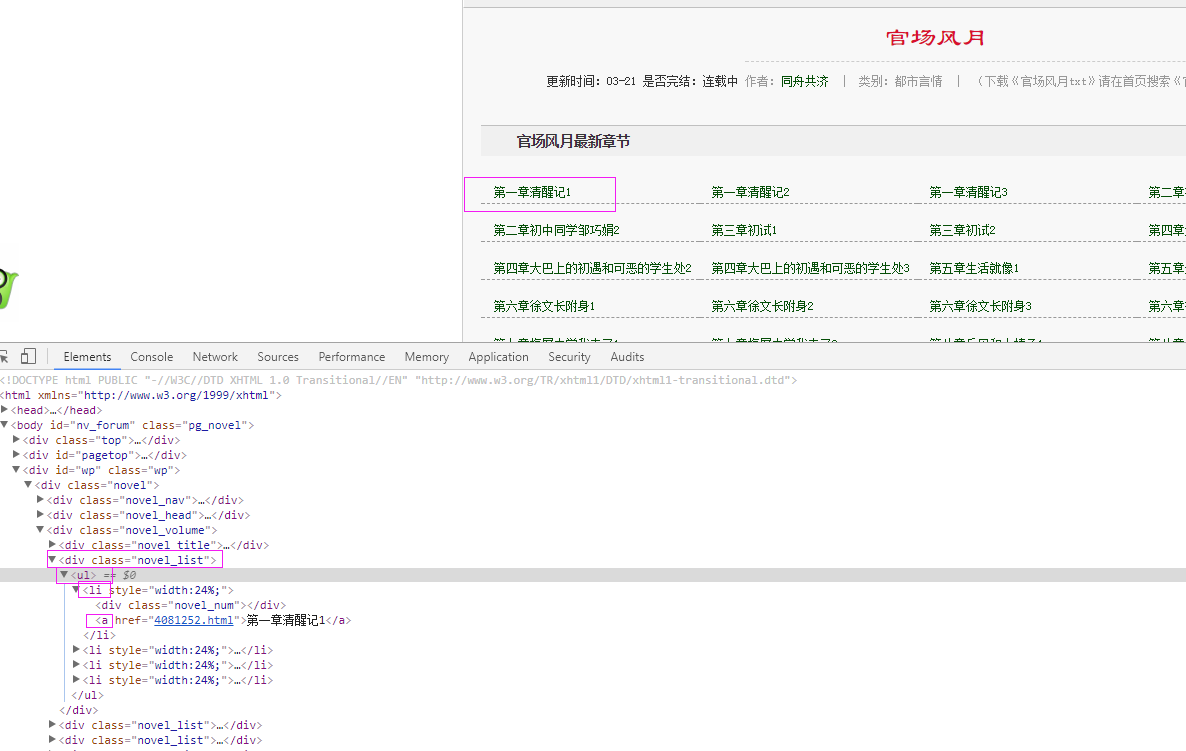
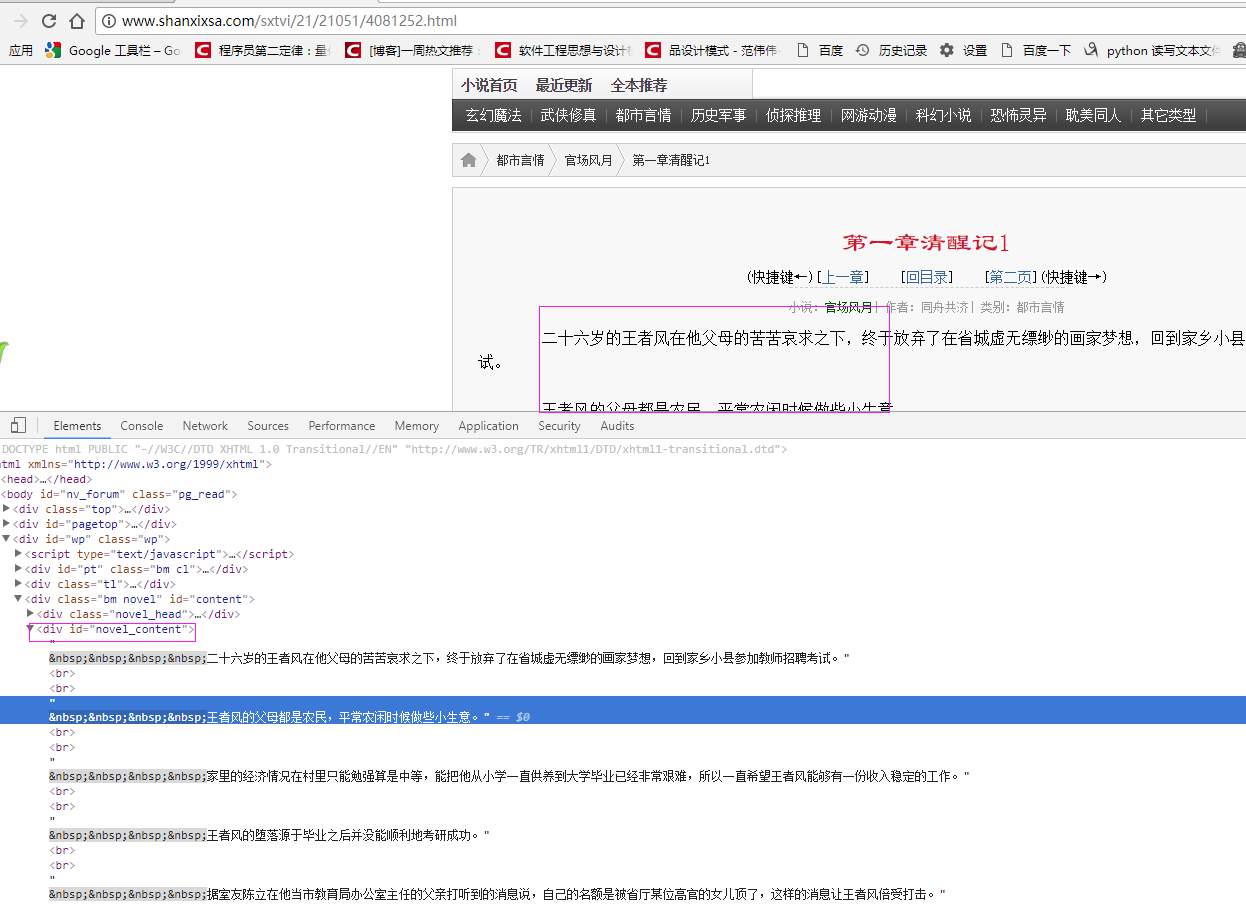
具体代码:
# coding=utf-8
import os
import re
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
import selenium.webdriver.support.ui as ui
import time
from datetime import datetime
from selenium.webdriver.common.action_chains import ActionChains # from threading import Thread
from pyquery import PyQuery as pq
import LogFile import urllib
class downfile(object):
def __init__(self,websearch_url,novelname):
self.driver = webdriver.PhantomJS()
# self.driver.set_page_load_timeout(10)
self.driver.maximize_window()
novel_name = unicode(novelname,'utf8')
logfile = os.path.join(os.getcwd(), 'novel\\' + novel_name + '.txt')
self.log = LogFile.LogFile(logfile)
self.websearch_url = websearch_url def scroll_foot(self):
'''
滚动条拉到底部
:return:
'''
js = ""
# 如何利用chrome驱动或phantomjs抓取
if self.driver.name == "chrome" or self.driver.name == 'phantomjs':
js = "var q=document.body.scrollTop=10000"
# 如何利用IE驱动抓取
elif self.driver.name == 'internet explorer':
js = "var q=document.documentElement.scrollTop=10000"
return self.driver.execute_script(js) def scrapy_date(self):
self.driver.get( self.websearch_url)
htext = self.driver.execute_script("return document.documentElement.outerHTML")
dochtml = pq(htext)
Elements = dochtml('div[class="novel_list"]').find('ul').find('li').find('a') for e in Elements.items():
url = 'http://www.shanxixsa.com/sxtvi/21/21051/'+e.attr('href')
txt = e.text().encode('utf8').strip()
print txt
self.log.WriteLog(txt)
self.driver.get(url)
shtext = self.driver.execute_script("return document.documentElement.outerHTML")
sdochtml = pq(shtext) sElements = sdochtml('div[ID="novel_content"]')
for se in sElements.items():
stxt = se.text().encode('utf8').strip()
self.log.WriteLog(stxt) obj = downfile('http://www.shanxixsa.com/sxtvi/21/21051/index.html','官场风月')
obj.scrapy_date() # -*- coding: utf-8 -*- import os
import codecs
import datetime
import time
import logging #封装logging日志
class LogFile:
# def __init__(self,fileName):
# self.fileName = os.path.join(os.getcwd(), fileName)
# def WriteLog(self,message):
# strMessage = '\r\n%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), message)
# with open(self.fileName, 'a') as f:
# f.write(strMessage)
#构造函数 fileName:文件名
def __init__(self,fileName,level=logging.INFO):
fh = logging.FileHandler(fileName)
self.logger = logging.getLogger()
self.logger.setLevel(level)
# formatter = logging.Formatter('%(asctime)s : %(message)s','%Y-%m-%d %H:%M:%S')
formatter = logging.Formatter('%(message)s', '%Y-%m-%d %H:%M:%S')
fh.setFormatter(formatter)
self.logger.addHandler(fh) def WriteLog(self,message):
self.logger.info(message) def WriteErrorLog(self,message):
self.logger.setLevel(logging.ERROR)
self.logger.error(message)
python 下载小说的更多相关文章
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python爬虫之小说网站--下载小说(正则表达式)
python爬虫之小说网站--下载小说(正则表达式) 思路: 1.找到要下载的小说首页,打开网页源代码进行分析(例:https://www.kanunu8.com/files/old/2011/244 ...
- 使用Python开发小说下载器,不再为下载小说而发愁 #华为云·寻找黑马程序员#
需求分析 免费的小说网比较多,我看的比较多的是笔趣阁.这个网站基本收费的章节刚更新,它就能同步更新,简直不要太叼.既然要批量下载小说,肯定要分析这个网站了- 在搜索栏输入地址后,发送post请求获取数 ...
- 【Python 爬虫系列】从某网站下载小说《鬼吹灯》,正则解析html
import re import urllib.request import urllib.parse import urllib.error as err import time # 下载 seed ...
- 从网上下载小说_keywords:python、multiprocess
# -*- coding: utf-8 -*- __author__ = "YuDian" from multiprocessing import Pool # Pool用来创建进 ...
- Python下载网页的几种方法
get和post方式总结 get方式:以URL字串本身传递数据参数,在服务器端可以从'QUERY_STRING'这个变量中直接读取,效率较高,但缺乏安全性,也无法来处理复杂的数据(只能是字符串,比如在 ...
- 【python 下载】-各种版本都有!
python 是一种全功能的语言,2.7很稳定,成熟的版本,且有很多开源的模块. 小编个人觉得python有一个很大的优点,就是语法简练,甚至可以说简单.比起pascal或者 C什么的,简单的难以置信 ...
- Python下载Yahoo!Finance数据
Python下载Yahoo!Finance数据的三种工具: (1)yahoo-finance package. (2)ystockquote. (3)pandas.
- [转] 三种Python下载url并保存文件的代码
原文 三种Python下载url并保存文件的代码 利用程序自己编写下载文件挺有意思的. Python中最流行的方法就是通过Http利用urllib或者urllib2模块. 当然你也可以利用ftplib ...
随机推荐
- 转载:超级强大的vim配置(vimplus)--续集
超级强大的vim配置(vimplus)--续集 原文地址:https://www.cnblogs.com/highway-9/p/5984285.html An automatic configura ...
- wait(),sleep(),notify(),join()
wait()注意以下几点: 1)wait()是属于Object类的方法. 2)调用了wait()之后会引起当前线程处于等待状态. 3)将当前线程置入“预执行队列”中,并且在wait()所在的代码行处停 ...
- 【bzoj3261】最大异或和
就是一个可持久化Trie....... #include<bits/stdc++.h> #define N 600005 using namespace std; inline int r ...
- 层级数据模板 案例(HierarchicalDataTemplateWindow)
1.xaml 文件 <Window x:Class="DataTemplate.HierarchicalDataTemplateWindow" xmlns=&q ...
- 轻量级批量管理工具pssh
pssh工具 pssh工具是个轻量级的批量管理工具,相比同类型的开源工具 Ansible,Saltstack,他比较轻量级,需要对管理的主机做秘钥认证 Ansible是可以做秘钥认证,也可以通过配置文 ...
- docker从零开始网络(一)概述
概述 预计阅读时间: 4分钟 Docker容器和服务如此强大的原因之一是您可以将它们连接在一起,或者将它们连接到非Docker工作负载.Docker容器和服务甚至不需要知道它们部署在Docker上,或 ...
- window10下部署flask系统(apache和wsgi)
公司有一个小系统,通过url和其他系统进行数据交互(有点土). 因此,利用flask写了一个小程序. 现在,考虑到并发问题(flask自身是不会并发的),准备部署在apache+wsgi环境. 网上百 ...
- 最适合2018年自学的web前端零基础系统学习视频+资料
这份资料整理花了近7天,如果感觉有用,可以分享给更有需要的人. 在看接下的介绍前,我先说一下整理这份资料的初衷: 我的初衷是想帮助在这个行业发展的朋友和童鞋们,在论坛博客等地方少花些时间找资料,把有限 ...
- Nodejs调用Aras Innovator服务,处理AML并返回AML
公司已经布署了Aras Innovator服务器,如果需要与Aras Innovator进行交互,需要进行自主开发程序,例如使用C#.VB.Java等,都是可以与它进行交互的 C#:调用Aras In ...
- 最近项目中用到的js
1.用字典判断数组是否有重复function ticketTypeValidate() { var ticketArr = []; var tickettype = $("div[name= ...