zookeeper介绍及集群的搭建(利用虚拟机)
ZooKeeper
ZooKeeper是一个分布式的,开放源码(apache)的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase、dubbox、kafka的重要组件。它主要用来解决分布式集群中应用系统的一致性问题,例如怎样避免同时操作同一数据造成脏读的问题,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
其本质是一个分布式的小文件存储系统,这个文件系统是树形的,每个节点叫做znode,每个znode都有路径和存储的值(也就是同时具有文件夹和文件的作用)。
ZooKeeper特性
- 1. 全局数据一致:集群中每个服务器保存一份相同的数据副本,client 无论连接到哪个服务器,展示的数据都是一致的,这是最重要的特征。
- 2. 可靠性:如果消息被其中一台服务器接受,那么将被所有的服务器接受。
- 3. 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息 a 在消息 b 前发布,则在所有 Server 上消息 a 都将在消息 b 前被发布;偏序是指如果一个消息 b 在消息 a后被同一个发送者发布,a 必将排在 b 前面。
- 4. 数据更新原子性:一次数据更新要么成功(半数以上节点成功),要么失败,不存在中间状态。
- 5. 实时性:Zookeeper 保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。
ZooKeeper集群的角色
Leader:
Zookeeper 集群工作的核心,事务请求(写操作)的唯一调度和处理者,保证集群事务处理的顺序性;集群内部各个服务器的调度者。对于 create,setData,delete 等有写操作的请求,则需要统一转发给leader 处理,leader 需要决定编号、执行操作,这个过程称为一个事务。
Follower:
处理客户端非事务(读操作)请求,转发事务请求给 Leader;参与集群 Leader 选举投票。
此外,针对访问量比较大的 zookeeper 集群,还可新增观察者角色。
Observer:
观察者角色,观察 Zookeeper 集群的最新状态变化并将这些状态同步过来,其对于非事务请求可以进行独立处理,对于事务请求,则会转发给 Leader服务器进行处理。不会参与任何形式的投票只提供非事务服务,通常用于在不影响集群事务处理能力的前提下提升集群的非事务处理能力。
那么我们为什么要搭建zookeeper集群呢?
zookeeper一般是作为dubbo的注册中心存在的,搭建集群一是为了高可用(一个zookeeper挂了,另外一个可以立即补上),二是为了应付高并发的情况提高效率。
zookeeper在solrCloud中的作用
主要用来管理solr集群中的相关配置信息和集群的运行状态, 协助solr进行主节点的选举。
准备:zookeeper的安装包 三台linux虚拟机 虚拟机的安装
修改三台虚拟机的hosts文件: vi /etc/hosts
添加如下内容:
192.168.44.28 node-01
192.168.44.29 node-02
192.168.44.30 node-03
注意: 添加时, 前面ip地址一定是自己的三台linux的ip地址 切记不要搞错了
上传zookeeper的压缩包(上传其中一台即可)
cd /export/software/
rz #此时选择zookeeper的压缩包进行上传
解压zookeeper到指定的目录
tar -zxf zookeeper-3.4.9.tar.gz -C /export/servers/
cd /export/servers/
修改zookeeper的配置文件
cd /export/servers/zookeeper-3.4.9/conf
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
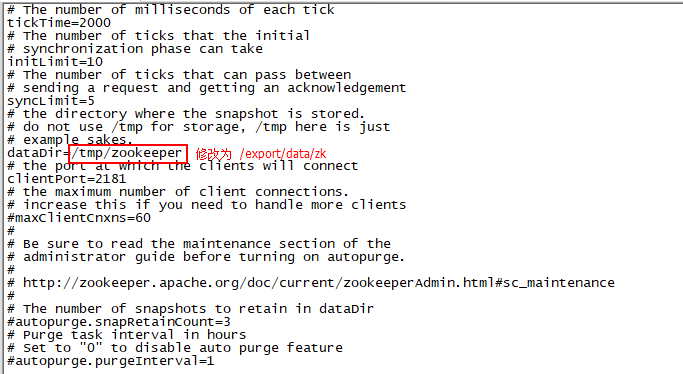
修改后, 在配置文件的底部, 添加如下内容
server.1=node-01:2888:3888
server.2=node-02:2888:3888
server.3=node-03:2888:3888
更改后配置文件整体内容如下:(如果担心修改错误, 可以直接将zoo.cfg中的内容全部删除, 复制以下内容即可)
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/export/data/zk
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1 #zookeeper集群配置
server.1=node-01:2888:3888
server.2=node-02:2888:3888
server.3=node-03:2888:3888
将配置好的zookeeper发送到其他两台主机上
cd /export/servers/
scp -r zookeeper-3.4.9/ root@node-02:$PWD //将zookeeper复制到node-02的同级目录下
scp -r zookeeper-3.4.9/ root@node-03:$PWD //将zookeeper复制到node-03的同级目录下

发送完成后,在其他两台主机查看, 是否已经成功接收到
cd /export/servers
ll
分别在三台主机输入如下命令给zookeeper设置id
node-01:执行的命令
mkdir -p /export/data/zk //这个路径和上面修改配置文件dataDir一致
echo "1" > /export/data/zk/myid
cat /export/data/zk/myid //此命令用于查看此文件有没有正确写入 1 node-02:执行的命令
mkdir -p /export/data/zk
echo "2" > /export/data/zk/myid
cat /export/data/zk/myid //此命令用于查看此文件有没有正确写入 2 node-03:执行的命令
mkdir -p /export/data/zk
echo "3" > /export/data/zk/myid
cat /export/data/zk/myid //此命令用于查看此文件有没有正确写入 3
分别启动三台zookeeper(建议启动顺序 node1>>node2>>node3 依次启动)
cd /export/servers/zookeeper-3.4.9/bin/
./zkServer.sh start
一个leader 其余的为follower



zookeeper的选举机制
初始化集群: 采取投票机制, 选举过半即为leader
1. 当第一台(id=1),启动后, 由于目前自有自己,故会把票投给自己
2. 当第二台(id=2),启动后, 由于目前已经又二台启动, 这时候会将票投给id最大的机器, 此时三台中已经有二台启动, 数量过半, 第二台理所应当的成为了leader
3. 当第三台(id=3),启动后, 虽然id=3为最大, 但是由于leader已经产生, 故只能担任follower
当下一次在重新启动时, 又会恢复选举,此时谁的数据多, 谁为leader, 如果数据都一样, 那么看id谁最大,同时一般选举过半,就会产生leader
还有一种选举方式是非全新集群选举:
对于运行正常的 zookeeper 集群,中途有机器 down 掉,需要重新选举时,选举过程就需要加入数据 ID、服务器 ID 和逻辑时钟。
数据 ID:数据新的 version 就大,数据每次更新都会更新 version。
服务器 ID:就是我们配置的 myid 中的值,每个机器一个。
逻辑时钟:这个值从 开始递增,每次选举对应一个值。 如果在同一次选举中,这个值是一致的。
这样选举的标准就变成:
、逻辑时钟小的选举结果被忽略,重新投票;
、统一逻辑时钟后,数据 id 大的胜出;
、数据 id 相同的情况下,服务器 id 大的胜出;
根据这个规则选出 leader。
在zookeeper集群的基础上,搭建solrCloud
zookeeper伪集群的搭建
zookeeper介绍及集群的搭建(利用虚拟机)的更多相关文章
- ZooKeeper 介绍及集群环境搭建
本篇由鄙人学习ZooKeeper亲自整理的一些资料 包括:ZooKeeper的介绍,我们要学习ZooKeeper的话,首先就要知道他是干嘛的对吧. 其次教大家如何去安装这个精巧的智慧品! 相信你能研究 ...
- 【Hadoop离线基础总结】zookeeper的介绍以及集群环境搭建、网络编程和RPC的简单了解
ZooKeeper的介绍以及集群环境搭建.网络编程和RPC的简单了解 ZooKeeper介绍 概述 ZooKeeper是一个分布式协调服务的开源框架,主要用来解决分布式集群中应用系统的一致性问题.例如 ...
- ZooKeeper 完全分布式集群环境搭建
1. 搭建前准备 示例共三台主机,主机IP映射信息如下: 192.168.32.101 s1 192.168.32.102 s2 192.168.32.103 s3 2.下载ZooKeeper, 以 ...
- 2. zookeeper介绍及集群搭建
ZooKeeper 概述 Zookeeper 是一个分布式协调服务的开源框架. 主要用来解决分布式集群中 应用系统的一致性问题,例如怎样避免同时操作同一数据造成脏读的问题. ZooKeeper 本质上 ...
- 大数据 -- zookeeper和kafka集群环境搭建
一 运行环境 从阿里云申请三台云服务器,这里我使用了两个不同的阿里云账号去申请云服务器.我们配置三台主机名分别为zy1,zy2,zy3. 我们通过阿里云可以获取主机的公网ip地址,如下: 通过secu ...
- STORM_0004_windows下zookeeper的伪集群的搭建
-----------------------------------------------------START------------------------------------------ ...
- kafka介绍和集群环境搭建
kafka概念: kafka是一个高吞吐量的流式分布式消息系统,用来处理活动流数据.比方网页的訪问量pm,日志等,既可以实时处理大数据信息 也能离线处理. 特点: ...
- zookeeper 介绍与集群安装
zookeeper 介绍 ZooKeeper是一个分布式开源框架,提供了协调分布式应用的基本服务,它向外部应用暴露一组通用服务——分布式同步(Distributed Synchronization). ...
- 吴超老师课程---ZooKeeper介绍和集群安装
1.ZooKeeper 1.1 zk可以用来保证数据在zk集群之间的数据的事务性一致.2.如何搭建ZooKeeper服务器集群 2.1 zk服务器集群规模不小于3个节点,要求各服务器之间系 ...
随机推荐
- Nodejs之静态资源处理
前言 着眼于问题 重现问题 indexhtml indexcss serverjs 发现问题 解决问题 serverjs express 核心 server-expressjs indexhtml 总 ...
- 用java网络编程中的TCP方式上传文本文件及出现的小问题
自己今天刚学java网络编程中的TCP传输,要用TCP传输文件时,自己也是遇到了一些问题,抽空把它整理了一下,供自己以后参考使用. 首先在这个程序中,我用一个客户端,一个服务端,从客户端上传一个文本文 ...
- 暴力破解Windows RDP(3389)
RDP是远程桌面协议. $ nmap your_target Starting Nmap 7.01 ( https://nmap.org ) at 2016-09-20 17:29 CST Nmap ...
- centOS 7 tomcat nginx 验证码乱码
将服务部署在centOS 7上,配置完tomcat和nginx之后,启动服务后,发现验证码这样了~~~ 一开始是以为nginx的原因,但是在Ubuntu系统相同操作发现没有问题,后发现,系统的字体库中 ...
- vue动态 设置类名
<div class="tab"> <navigator :class="currentTab=='mzfw'?'nav active': 'nav'& ...
- 使用 event.preventDefault 拦截表单的提交
event.preventDefault() 方法 W3C 官方的定义是:取消事件的默认动作,不单单可以拦截表单的提交,<a>标签的跳转, <input>标签的输入等等默认动作 ...
- computed属性与methods、watched
一.计算属性 new Vue({ data: { message: 'hello vue.js !' }, computed: { reverseMessage: function () { retu ...
- fn project 扩展
目前支持的扩展方式 Listeners - listen to API events such as a route getting updated and react accordingly. ...
- Windows下通过Composer安装Yii2 [ 2.0 版本 ]
安装好大于5.4或更高版本的PHP环境并开启openssl扩展.如果是Apache服务器,加载Apache的mod_ssl模块. 下载Composer并安装. 开始->运行[或者WIN+R]-& ...
- 腾讯云搭建php环境
1.安装搭建论坛必要的软件 apache php mysql CentOS系统我们可以直接使用 yum install 的方式进行软件安装,腾讯云有提供软件安装源,是同步CentOS官方的安装源, ...