ActiveMQ+Zookeeper集群配置文档
Zookeeper + ActiveMQ 集群整合配置文档
一:使用ZooKeeper实现的MasterSlave实现方式
是对ActiveMQ进行高可用的一种有效的解决方案, 高可用的原
理:使用ZooKeeper(集群)注册所有的ActiveMQ
Broker。只有其中的一个Broker可以对外提供服务( 也就是Master节点) ,其
他的Broker处于待机状态,被视为Slave。如果Master因故障而不能提供服务,
则利用ZooKeeper的内部选举机制会从Slave中选举出一个Broker充当Master节
点,继续对外提供服务。
官网文档如下:
http://activemq.apache.org/replicated-leveldb-store.html
二:部署方案, ActiveMQ集群环境准备:
( 1) 首先我们下载apache-activemq-5.11.1-
bin.tar.gz,到我们的一台主节点上去,然后我们在( 192.168.1.111一个节点
上实现集群即可)
( 2) Zookeeper方案
| 主机IP | 消息端口 | 通信端口 | 节点目录/usr/local/下 |
| 192.168.1.111 | 2181 | 2888:3888 | zookeeper |
| 192.168.1.112 | 2181 | 2888:3888 | zookeeper |
| 192.168.1.113 | 2181 | 2888:3888 | zookeeper |
( 3) ActiveMQ方案
| 主机IP | 集群通信端口 | 消息端口 | 控制台端口 | 节点目录/usr/local/下 |
| 192.168.1.111 | 62621 | 51511 | 8161 | activemq-cluster/node1/ |
| 192.168.1.111 | 62622 | 51512 | 8162 | activemq-cluster/node2/ |
| 192.168.1.111 | 62623 | 51513 | 8163 | activemq-cluster/node3/ |
1:首先搭建zookeeper环境
在192.168.1.111节点下software下,解压zookeeper-3.4.5.tar.gz文件,然后改名,操作如下:(在三台机器上都进行这样的配置)
命令: mv zookeeper-3.4.5 zookeeper
配置环境变量:vim /etc/profile
添加:export ZOOKEEPER_HOME=/usr/local/zookeeper,并添加PATH
使环境变量生效:source /etc/profile
然后:cd zookeeper/conf
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
找到datadir修改为:/usr/local/zookeeper/data
在最下面添加:server.0=192.168.1.111:2888:3888
server.1=192.168.1.112:2888:3888
server.2=192.168.1.113:2888:3888
建立zookeeper/data文件夹,并cd进入
执行vim myid
第一行添加0即可
在112中添加1,113中添加2
搭建完成
三台机器上运行:zkServer.sh start
任意一台运行:zkCli.sh可以连接上客户端
2:继续搭建activemq环境
( 1) 在192.168.1.111节点下,创建/usr/local/activemq-cluster文件夹,解压apache-activemq-5.11.1-
bin.tar.gz文件,然后对解压好的文件改名,操作如下:
1 命令: mkdir /usr/local/activemq-cluster
2 命令: cd software/
3 命令: tar -zxvf apache-activemq-5.11.1-bin.tar.gz -C
/usr/local/activemq-cluster/
4 命令: cd /usr/local/activemq-cluster/
5 命令: mv apache-activemq-5.11.1/ node1
如此操作,再次反复解压apache-activemq-5.11.1-
bin.tar.gz文件到/usr/local/activemqcluster/下,建立node2和node3文件夹,如下:
( 2) 那我们现在已经解压好了三个mq节点也就是node1、 node2、 node3,下面
我们要做的事情就是更改每个节点不同的配置和端口(由于是在一台机器上实
现集群)。
1 修改控制台端口(默认为8161) ,在mq安装路径下的conf/jetty.xml进
行修改即可。(三个节点都要修改,并且端口都不同)
1命令: cd /usr/local/activemq-cluster/node1/conf/
2命令: vim /usr/local/activemq-cluster/node1/conf/jetty.xml

三个节点都需要修改为8161、8162、8163!!!
2 集群配置文件修改:我们在mq安装路径下的conf/activemq.xml进行修
改其中的持久化适配器,修改其中的bind、 zkAddress、 hostname、 zkPath。
然后也需要修改mq的brokerName,并且每个节点名称都必须相同。
命令: vim /usr/local/activemq-cluster/node1/conf/activemq.xml
第一处修改: brokerName=”activemq-cluster”(三个节点都需要修改)

第二处修改:先注释掉适配器中的kahadb
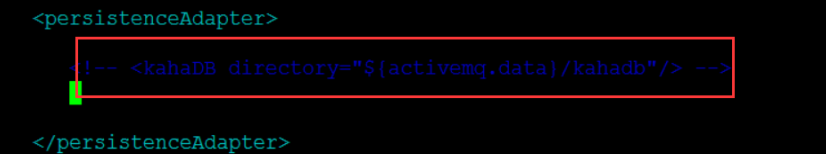
第三处修改:添加新的leveldb配置如下(三个节点都需要修改):
Node1:
<persistenceAdapter>
<!--kahaDB directory="${activemq.data}/kahadb"/ -->
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:62621"
zkAddress="192.168.1.111:2181,192.168.1.112:2181,192.168.1.113:2181"
hostname="bhz111"
zkPath="/activemq/leveldb-stores"
/>
</persistenceAdapter>
Node2:
<persistenceAdapter>
<!--kahaDB directory="${activemq.data}/kahadb"/ -->
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:62622"
zkAddress="192.168.1.111:2181,192.168.1.112:2181,192.168.1.113:2181"
hostname="bhz111"
zkPath="/activemq/leveldb-stores"
/>
</persistenceAdapter>
Node3:
<persistenceAdapter>
<!--kahaDB directory="${activemq.data}/kahadb"/ -->
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:62623"
zkAddress="192.168.1.111:2181,192.168.1.112:2181,192.168.1.113:2181"
hostname="bhz111"
zkPath="/activemq/leveldb-stores"
/>
</persistenceAdapter>
第四处修改:(修改通信的端口,避免冲突)
命令: vim /usr/local/activemq-cluster/node1/conf/activemq.xml
修改这个文件的通信端口号, 三个节点都需要修改( 51511,51512,51513)
Ok,到此为止,我们的activemq集群环境已经搭建完毕!
三:测试启动activemq集群:
第一步:启动zookeeper集群,命令: zkServer.sh start
第二步:启动mq集群:顺序启动mq:命令如下:
/usr/local/activemq-cluster/node1/bin/activemq start(关闭stop)
/usr/local/activemq-cluster/node2/bin/activemq start(关闭stop)
/usr/local/activemq-cluster/node3/bin/activemq start(关闭stop)
第三步:查看日志信息:
tail -f /usr/local/activemq-cluster/node1/data/activemq.log
tail -f /usr/local/activemq-cluster/node2/data/activemq.log
tail -f /usr/local/activemq-cluster/node3/data/activemq.log
如果不报错,我们的集群启动成功,可以使用控制台查看!
第四步:集群的brokerUrl配置进行修改即可:
failover:(tcp://192.168.1.111:51511,tcp://192.168.1.111:51512,tcp://1
92.168.1.111:51513)?Randomize=false
/usr/local/activemq-cluster/node1/bin/activemq stop
/usr/local/activemq-cluster/node2/bin/activemq stop
/usr/local/activemq-cluster/node3/bin/activemq stop
zkServer.sh stop
第四:负载均衡配置如下:
集群1链接集群2:
<networkConnectors>
<networkConnector
uri="static:(tcp://192.168.1.112:51514,tcp://192.168.1.112:51515,tcp://192.168.1.112:51516)"
duplex="false"/>
</networkConnectors>
集群2链接集群1:
<networkConnectors>
<networkConnector
uri="static:(tcp://192.168.1.111:51511,tcp://192.168.1.111:51512,tcp://192.168.1.111:51513)"
duplex="false"/>
</networkConnectors>
ActiveMQ+Zookeeper集群配置文档的更多相关文章
- Rhel6-mpich2 hpc集群配置文档
系统环境: rhel6 x86_64 iptables and selinux disabled 主机: 192.168.122.121 server21.example.com 192.168.12 ...
- HP DL160 Gen9服务器集群部署文档
HP DL160 Gen9服务器集群部署文档 硬件配置=======================================================Server Memo ...
- kafka集群搭建文档
kafka集群搭建文档 一. 下载解压 从官网下载Kafka,下载地址http://kafka.apache.org/downloads.html 注意这里最好下载scala2.10版本的kafka, ...
- Apache Hadoop 集群安装文档
简介: Apache Hadoop 集群安装文档 软件:jdk-8u111-linux-x64.rpm.hadoop-2.8.0.tar.gz http://www.apache.org/dyn/cl ...
- redis多机集群部署文档
redis多机集群部署文档(centos6.2) (要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如下 ...
- zookeeper集群配置与启动——实战
1,准备: A:三台linxu服务器: 10.112.29.177 10.112.29.172 10.112.29.174 命令 hostname 得到每台机器的 hostname vm-10-112 ...
- kafka集群与zookeeper集群 配置过程
Kafka的集群配置一般有三种方法,即 (1)Single node – single broker集群: (2)Single node – multiple broker集群: (3)Mult ...
- Redis集群部署文档(Ubuntu15.10系统)
Redis集群部署文档(Ubuntu15.10系统)(要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如 ...
- java:zookeeper集群配置,dubbo
1.zookeeper集群配置: 2.dubbo:(配置见视频)
随机推荐
- BZOJ2659: [Beijing wc2012]算不出的算式(数学)
Time Limit: 3 Sec Memory Limit: 128 MBSubmit: 1575 Solved: 939[Submit][Status][Discuss] Descriptio ...
- SPOJ8222 NSUBSTR - Substrings(后缀自动机)
You are given a string S which consists of 250000 lowercase latin letters at most. We define F(x) as ...
- mysql——查询重复数据,及删除重复数据只保留一条数据
查询 text 表中,user_name字段值重复的数据及重复次数 select user_name,count(*) as count from text 删除 text 表中,重复出现的数据只保留 ...
- Java : java基础(4) 线程
java开启多线程的方式,第一种是新建一个Thread的子类,然后重写它的run()方法就可以,调用类的对象的start()方法,jvm就会新开一个线程执行run()方法. 第二种是类实现Runabl ...
- html5 获取和设置data-*属性值的四种方法讲解
1.获取id的对象 2.需要获取的就是data-id 和 dtat-vice-id的值 一:getAttribute()方法 const getId = document.getElementById ...
- HBase学习(三):数据模型
和传统的关系型数据库类似,HBase以表(Table)的方式组织数据.HBase的表由行(Row)和列(Column)共同构成,与关系型数据库不同的是HBase有一个列族(ColumnFamily)的 ...
- 九、IIC驱动原理分析
学习目标:学习IIC驱动原理: 一.IIC总线协议 IIC串行总线包括一条数据线(SDA)和一条时钟线(SCL),支持“一主多从”和“多主机”模式:每个从机设备都有唯一的地址来识别. 图 1 IIC ...
- Python Web开发中,WSGI协议的作用和实现原理详解
首先理解下面三个概念: WSGI:全称是Web Server Gateway Interface,WSGI不是服务器,python模块,框架,API或者任何软件,只是一种规范,描述web server ...
- Python学习手册之数据类型
在上一篇文章中,我们介绍了 Python 的异常和文件,现在我们介绍 Python 中的数据类型. 查看上一篇文章请点击:https://www.cnblogs.com/dustman/p/99799 ...
- NO-ZERO(空格补全)
The NO-ZERO command follows the DATA statement REPORT Z_Test123_01. DATA: W_NUR(10) TYPE N. MOVE 50 ...