Java编程思想 笔记
date: 2019-09-06 15:10:00
updated: 2019-09-24 08:30:00
Java编程思想 笔记
1. 四类访问权限修饰词
| \ | 类内部 | 本包 | 子类 | 其他包 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | |
| default(friendly) | √ | √ | ||
| private | √ |
protected:处理的是继承的概念。子类 extends 父类,如果父类希望某个特定成员,把对它的访问权限赋予派生类而不是所有类,即可以使用 protected。
2. 8个基本类型
| 基本类型 | 大小 | 包装器类型 | 默认值 |
|---|---|---|---|
| boolean | - | Boolean | false |
| char | 16位 | Character | null |
| byte | 8位 | Byte | (byte)0 |
| short | 16位 | Short | (short)0 |
| int | 32位 | Integer | 0 |
| long | 64位 | Long | 0L |
| float | 32位 | Float | 0.0f |
| double | 64位 | Double | 0.0d |
默认值只是当变量作为类的成员使用时,才会给默认值,以确保成员变量得到初始化,防止程序错误。并不适用于局部变量!
int 的整数范围:-2147483648 ~ 2147483647
高精度数字的类:BigInteger 和 BigDecimal
float 创建变量的时候,后面必须要加一个 f
3. static 关键字
由 static 声明的变量或方法只有一份存储空间。关于变量,不管创建多少个对象,这些对象都共享同一个 i;关于方法,可以直接调用不用创建对象。
class StaticTest {
static int i = 1;
}
StaticTest st1 = new stStaticTest();
st1.i;
StaticTest.i; // 也可以直接访问
A a= new A()
A b =new A()
如果A里面有static int x
a.x和b.x是同一个x
即使没有显式使用 static 关键字,一个类的构造器实际上也是静态方法。
初始化的顺序是先静态对象(如果它们尚未因前面的对象创建过程而被初始化),其次是非静态对象。
一个类的初始化顺序:
- 将分配给对象的存储空间初始化成二进制的零
- 基类中的 static 静态代码块
- 子类中的 static 静态代码块
- 基类中的属性值和普通代码块,按书写顺序初始化(这些变量和方法肯定不是 static)
- 基类中的构造器执行
- 子类中的属性值和普通代码块,按书写顺序初始化(这些变量和方法肯定不是 static)
- 子类中的构造器执行
4. final 关键字
如果一个类被声明为 final,意味着它不能再派生出新的子类,不能作为父类被继承。因此一个类不能既被声明为 abstract,又被声明为 final。
将变量或方法声明为 final,可以保证它们在使用中不被改变。被声明为 final 的变量必须在声明时给定初值,而在以后的引用中只能读取,不可修改。被声明为final 的方法也同样只能使用,不能重载。
5. ++
++i 先执行运算,再生成值
i++ 先生成值,再执行运算
6. == 和 equals
equals:不同对象判断内容是否相等用 equals
==:比较的是对象的引用;基本类型使用 == 来判等
7. while 和 do...while
do...while 中的语句最少会执行一次,哪怕 while 中的判断是 false
for( ; ; ) 和 while(true) 是一样的,都表示无穷循环。
8. foreach
这里的 foreach 只是 for 循环的变形。Java8 之后可以使用 foreach + lambda 表达式来循环遍历。
for(type i : x) // x 比如是一个数组或容器
for(char c : "a test string".toCharArray()) // String 类通过 toCharArray() 方法来返回一个 char 数组
Java8 特性:foreach + lambda 表达式
items.foreach((k, v) -> {
System.out.println("key: " + k + ", value: " + v)
})
9. break 和 continue
break:用于强行退出循环,不执行循环中剩余的语句
continue:用于停止执行当前的迭代,然后退回循环起始处,开始下一次迭代
break 和 continue 针对的都是当前迭代层。如果有内外两层迭代,break写在内层,只是退出内层迭代,外层迭代继续。
10. 标签
标签是后面跟有冒号的标识符,类似:lable1:,一般和 break、continue 一同使用,表示中断当前循环,跳到标签所在的位置。
11. 垃圾回收
Java 垃圾回收器只知道释放那些由 new 分配内存的对象。如果一个对象并非使用 new 来获得一块内存的话,就需要在类中定义一个名为 finalize() 的方法。
关于回收的几个点:
- 对象不一定会被回收
- 垃圾回收不是析构函数
- 垃圾回收只与内存有关
- 如果 JVM 还没面临内存耗尽的情况,那它就不会浪费时间去执行垃圾回收来恢复内存。
几种垃圾回收技术:
引用计数:引用连接至对象,计数器加1;引用离开作用域或被设置为 null 时,计数器减1。当计数为0时回收。缺点:如果对象之间存在循环引用,可能会出现”对象应该被回收,但引用计数不为0“
停止-复制:先暂停程序运行,把所有存活的对象从当前堆复制到另一个堆,没有被复制的对象都是垃圾。缺点:所有引用需要修正;需要2倍的空间;如果有较少或甚至没有垃圾,就很浪费。
标记-清扫:遍历所有引用,标记存活对象,当过程结束后开始回收。
12. 可变参数列表
static void printArray(Object[] args){
...
}
13. 基类(继承)
如果 A 作为基类,B extends A,那么当 new 一个 B 类的对象时,会隐式地自动先执行 A 类的无参构造函数,即构造过程是从基类开始向外扩散的。
如果要调用 A 的有参构造函数,就必须显式地使用 super 来调用,并且传参。
14. 代理
子类 extends 基类,那么基类的所有方法都会暴露给子类。使用代理可以有选择地将基类的方法暴露给用户来使用。
其实相当于之前是通过 extends 的方式来继承基类,现在是在一个类下面创建基类的对象的方式来实现功能。
public class A {
void func1(int i){}
void func2(int i){}
void func3(int i){}
...
}
public class B extends A {
// 此时 A 中所有的方法都会暴露给 B
}
// 使用代理
public class C {
private A a = new A();
// 代理方法
// 在这里可以有选择地提供基类中的方法
public void func1(int i){
a.func1(i);
}
...
}
15. 向上转型与向下转型
15.1 向上转型
向上转型指的是从一个转专用类型向较通用类型转换,比如子类向上转型为基类,由于基类不会有大于子类的方法数量,所以是安全的。
15.2 向下转型
向下转型则不安全,需要在转型时在前面用小括号写出具体转型的类型。
16. 多态
OOP(面向对象编程)三大特征:
- 抽象:把一类事物的属性或行为提出来,形成一个模型(类)
- 继承:为了提高代码复用性,将共同的属性或方法提取出来作为基类,子类继承基类,获得基类所有属性和行为,并可以根据自身需求来拓展各自的功能。
- 多态:即同一消息可以根据发送对象的不同而采用多种不同的行为方式。
另外还有 封装(把数据和对数据的操作组合起来,对外隐藏实现细节,对外只能用提供的功能来实现需求)。
以下是还算较为简单的多态的实现,更麻烦的实现是在 Shapes 定义参数不同方法名相同的 draw 方法,然后调用的时候分别把 circle、triangle 对象传进去,通过传递对象的不同来调用各自的 draw 方法。但是这种方法的思想依旧是前期绑定,即在运行前就已经知道了对象的类型。
// 基类
class Shape {
public void draw(){
...
}
}
// 子类
class Cirle extends Shape {
@Override 避免了方法重载的麻烦,但是也可以不加
public void draw(){
...
}
}
class Triangle extends Shape {
public void draw(){
...
}
}
// 实现类
class Shapes {
public static void main(String[] args) {
Cirle circle = new Circle();
Triangle triangle = new Triangle();
circle.draw();
triangle.draw();
}
}
多态的思想是通过后期绑定(亦或动态绑定或运行时绑定),是在向上转型的基础上来实现的:因为 Cirle 和 Triangle 继承自 Shape,那么可以在创建对象的时候写成 Shape circle = new Circle();,创建一个 Circle 对象,把引用赋值给 Shape。在调用 circle.draw(); 时默认会调用基类中的 draw() 方法,但是如果子类中覆写了这个方法,那么就会调用在 Circle 类中覆写的 draw() 方法,从而实现了多态。
// 基类
class Shape {
public void draw(){
...
}
}
// 子类
class Cirle extends Shape {
public void draw(){
...
}
}
class Triangle extends Shape {
public void draw(){
...
}
}
// 实现类
class Shapes {
public static void main(String[] args) {
Shape circle = new Cirle();
Shape triangle = new Triangle();
circle.draw();
triangle.draw();
}
}
多态的两个注意事项:
无法覆盖私有方法
变量和静态方法不具有多态性
17. 构造器
准则:用尽可能简单的方法使对象进入正常状态;避免调用其他方法。
在构造器内唯一能够安全调用方法是基类中的 final 方法(也适用于 private 方法,它们自动属于 final 方法),这些方法不能被覆盖。
18. 抽象类和抽象方法
建立抽象类的唯一目的是:不同的子类可以用不同的方式表示此接口(方法),抽象类就是把共同的部分提取了出来。像之前写的 Shape 就是一个抽象基类,或者抽象类。
如果一个类包含一个或多个抽象方法,该类就必须被限定为 abstract。同时,子类继承抽象类时,必须为基类中所有的抽象方法提供方法定义,否则,子类也必须被限定为 abstract。
基类中的抽象方法只定义方法,不具体实现。但是那些非抽象方法可以写实现体。(抽象类中的那些抽象方法类似于接口部分)
19. 接口
接口使抽象这一概念更进一步:全是抽象方法,只定义方法,都不实现。
接口中的方法都是 public。
一个类只能继承一个基类,但是可以实现多个接口。
class X extends A implements B, C {
}
扩展接口:接口 extends 接口1, 接口2 ... (只有接口继承是可以写多个的,除此之外,extends 只能后面跟一个类)
interface A {
void func1();
}
// 此时 B 就相当于有2个方法了
interface B extends A {
void func2();
}
class C implements B {
public void func1(){};
public void func2(){};
}
对于接口而言,如果使用了 extends,那么子类一定也是一个接口;如果使用了 implements,那么子类就是一个普通的类,并且必须实现接口中的所有方法。
接口中的任何变量都是 final 以及 static 的。
20. 内部类
使用内部类的原因:每个内部类都能独立地继承自一个(接口的)实现,所以无论外围类是否已经继承了某个(接口的)实现,对于内部类都没有影响。(比如想在一个类中以某种方式实现两个接口,可以使用单一类或者使用内部类,可以使用单一类的原因是因为可以继承多个接口,但是如果是抽象类或者具体类,即只能继承一个,那么就只能使用内部类来实现多重继承)
可以把一个类的定义放在另一个类的定义的内部(可以是类的内部,也可以是在某一个方法的内部),即为内部类。
内部类的好处之一是内部类拥有对其外部类的所有元素(成员变量及方法)的访问权。
在内部类里生成对外部类的引用:在外部类的名字后面加 .this
在外部类引用的基础上创建某个内部类的对象:在外部类的名字后面加 .new
Outer outer = new Outer();
Outer.Inner ini = outer.new Inner();
不过感觉最好是在外部类中添加一个返回内部类对象的方法
public class Outer {
public class Inner {
public Outer getOuter() {
return Outer.this; // .this 得到外部类的引用
}
}
public Inner inner() { return new Inner(); }
public static void main(String[] args){
Outer outer = new Outer();
Outer.Inner inner = outer.inner();
// Outer.Inner inner = outer.new Inner();
}
}
匿名内部类:(还不是很理解……)
public class A {
public Contents contents() {
return new Contents() {
private int i = 1;
public int value() { return i; }
}; // 这里的分号必要要有
}
public static void main(String[] args) {
A a = new A();
Contents contents = a.contents();
}
}
一个匿名类的组成部分:
- new 操作符
- new 之后可以写接口、抽象类、普通类名称。
- ():这个括号表示构造函数的参数列表。由于Runnable是一个接口,没有构造函数,所以这里填一个空的括号表示没有参数。
- {...}:大括号中间的代码表示这个类内部的一些结构。在这里可以定义变量名称、方法。跟普通的类一样。
嵌套类:将内部类声明为 static,此时内部类对象和其外部类对象之间就没有了联系。(普通的内部类对象隐式地保存了一个引用,指向创建它的外围类对象,但是使用了 static 之后,就没有了这个引用)
使用嵌套类意味着:
- 要创建嵌套类的对象,并不需要其外围类的对象(直接 new 一个就行)
- 不能从嵌套类的对象中访问非静态的外围类对象
嵌套类可以作为接口的一部分。因为接口中的任何类默认都是 public static
21. 容器类
容器类类库的用途是:保存对象。
分为两类:
Collection:一个独立元素的序列
- Collection 是 List 和 Set 两个接口的基接口,List 和 Set 也是接口
- List 在 Collection 之上增加了 ”有序“ 的概念,即必须按照插入的顺序保存元素
- ArrayList、LinkedList 是实现 List 接口的类。相同点:有序;不同点:ArrayList 是采用数组存放元素(索引查找快但是插入和删除慢),LinkedList 采用的则是链表(索引查找慢但是插入和删除快)
- Set 在 Collection 之上增加了 ”唯一“ 的概念,不能有重复元素
- HashSet、TreeSet 是实现 Set 接口的类。相同点:元素不能重复。不同点:HashSet 是无序的,而 TreeSet 是有序的,但是这个有序和 List 不一样,List 是按照插入顺序,而 TreeSet 是按照元素自定义顺序进行排序(可自定义排序的比较器)。因此 HashSet 允许放入 null,且效率较高,TreeSet相反。
- LinkedHashSet 是另一个实现类,可以保证按照插入顺序来保存元素
- SortedSet 接口保证元素处于排序状态
Map:一组”键值对“对象
- 当 get() 方法返回 null 值时,即可以表示 Map 中没有该键,也可以表示该键所对应的值为 null。因此,在 Map 中不能由 get() 方法来判断 Map 中是否存在某个键,而应该用 containsKey() 方法来判断
- 实现 Map 的类有:HashMap、HashTable、TreeMap
- HashMap 允许有空键(null)与空值(null),在缺省情况下是非同步的,效率高于 HashTable,更推荐使用,在多线程环境下使用时,可以转换为同步
- HashTable 缺省是线程同步的;不允许关键字或值为null;不推荐使用
- TreeMap 能把其保存的记录根据key排序(类似TreeSet),默认是按照key的默认排序,但也可指定排序的比较器;不允许有空键(null)但可以有空值(null)。
- TreeMap 和 HashMap 比较:
- TreeMap 适合于:元素顺序很重要;增加、快速创建的情况;HashMap 适合于:元素顺序不是很重要;查询
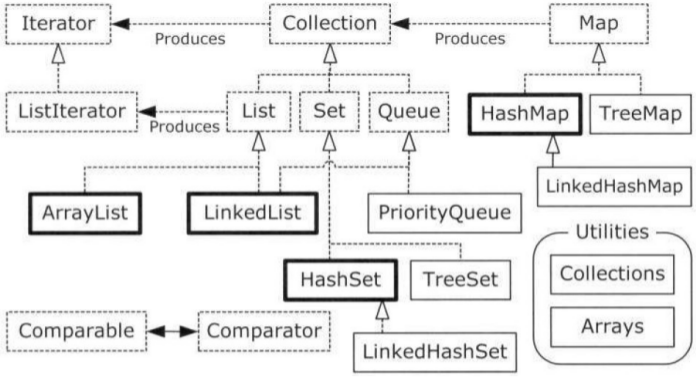
点线框表示接口,实现框表示具体的类,带有空心箭头的点线表示一个特定的类实现了一个接口,实心箭头表示某个类可以生成箭头所指向类的对象。eg:任意的 Collection 可以生成 Iterator,而 List 即可以生成 Iterator 也可以生成 ListIterator。

22. List
subList(fromIndex, toIndex):获取一个片段,fromIndex <= index < toIndex。需要注意的是 subList 获取的是原列表的引用,如果原列表发生改变(比如插入新的元素或者删除一个元素等等),那么在运行的时候 subList 就会报错。
22.1 迭代器
- Iterator
- 使用 iterator() 要求容器返回一个 Iterator。Iterator 将准备好返回序列的第一个元素
- 使用 next() 返回当前元素,并指向序列的下一个元素
- 使用 hasNext() 检查序列中是否还有元素
- 使用 remove() 将迭代器当前返回的元素删除,所以在使用 remove() 之前必须调用 next()
数组不是 Iterable,需要手动转换
- ListIterator:是 Iterator 的子类,只能用于对各种 List 类的访问。ListIterator 支持双向移动
22.2 LinkedList
在插入和删除操作上,LinkedList 比 ArrayList 更高效。
LinkedList 具有实现 Stack 的所有功能的方法,所以可以直接把 LinkedList 当栈使用。
addFirst() < - > push()
getFirst() < - > peek()
removeFirst() < - > pop()
LinkedList 实现了 Queue 接口,所以 LinkedList 可以作为 Queue 的一种实现类 -> 将 LinkedList 向上转型为 Queue 来使用。
在 Queue 的基础上,还有一个 PriorityQueue,用户可以自定义 Comparator 来定义优先级,下一个弹出的会是具有最高优先级的元素。
23. Set
查找是 Set 最重要的操作 => 通常会使用 HashSet,其对快速查找进行了优化
HashSet 和 LinkedHashSet 使用了散列函数来存储元素,LinkedHashSet 额外使用了链表来维护元素的插入顺序,TreeSet 使用了红黑树结构来存储元素
24. 异常处理
try 后面可以跟好几个 catch 字句,每个 catch 字句只能接一个参数。只有匹配的 catch 语句才会执行(这点和 switch 不一样,switch 语句需要在每一个 case 后面跟一个 break,以避免执行后续的 case 字句)。
在 finally 字句中调用 return,即使抛出了异常,也不会产生任何输出。
Java的异常(包括 Exception 和 Error)分为可查的异常(checked exceptions)和不可查的异常(unchecked exceptions)。
- 可查异常(编译器要求必须处置的异常):正确的程序在运行中,很容易出现的、情理可容的异常状况。可查异常虽然是异常状况,但在一定程度上它的发生是可以预计的,而且一旦发生这种异常状况,就必须采取某种方式进行处理。
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于可查异常。这种异常的特点是Java编译器会检查它,也就是说,当程序中可能出现这类异常,要么用try-catch语句捕获它,要么用throws子句声明抛出它,否则编译不会通过。
- 不可查异常(编译器不要求强制处置的异常):包括运行时异常(RuntimeException与其子类)和错误(Error)。
25. 字符串
推荐使用 StringBuilder
格式化输出:
System.out.println("Row1: [" + x + " " + y + "]");
System.out.format("Row1: [%d %f]\n", x, y);
System.out.printf("Row1: [%d %f]\n", x, y);
String 格式化:String.format(...)
格式化说明符:%[argument_index][flags][width][.precision]conversion
- flags:默认情况下数据是右对齐,使用 '-' 来使数据左对齐
- width:设置一个域的最小长度,过短时自动添加空格
- .precision:指定最大尺寸。如果应用在 String 时,表示打印 String 时输出字符的最大数量。如果应用在浮点数时,表示小数部分要显示出来的位数(默认是6位小数),如果小数位数过多则舍入,太少则补零。但是不能应用于整数,会报错。
26. 正则表达式
| code 需要多加一个斜线来转译 | 含义 |
|---|---|
\\d |
表示一位数字 [0-9] |
\\D |
表示一位非数字 [^0-9] |
\\\\ |
插入一个普通的反斜线,但是换行和制表符之类的东西只需要单反斜线即可:\n\t |
\\+ |
表示一个加号 |
\\w |
表示一个单词字符 [a-zA-Z0-9] |
\\W |
表示非单词字符 |
\\s |
空白符(空格、tab、换行、换页和回车) |
\\S |
非空白符 |
量词:
| code | 含义 |
|---|---|
| X? | 零个或一个X |
| X* | 零个或多个X |
| X+ | 一个或多个X |
| X{n} | n个X |
| X{n,} | 最少n个X |
| X{n,m} | n <= X的个数 <= m |
27. 类型信息
RTTI(Run-Time Type Identification): 运行时类型识别
28. 泛型
利用泛型概念,构建“元组”,来返回一组任意类型的对象,避免了使用类来返回信息,增加了复用性
// 泛型指代可以用任意的大写字母,不仅仅是 T
class TwoTuple<A, B>{
public final A first;
public final B second;
public TwoTuple(A a, B b) { first = a; second = b; }
public String toString(){
return "(" + first + "," + second + ")";
}
}
class ThreeTuple<A, B, C> extends TwoTuple<A, B>{
public final C third;
public ThreeTuple(A a, B b, C c){
super(a, b);
third = c;
}
public String toString(){
return "(" + first + "," + second + "," + third + ")";
}
}
泛型与可变参数列表:
// 第一个 <T> 很重要,相当于声明了当前这个方法是泛型方法
// 只有声明了<T>的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法
public static <T> List<T> makeList(T ... args) { ... }
使用泛型来构建复杂模型:
import java.util.*;
interface Generator<T> { T next(); }
class Generators {
public static <T> Collection<T> fill(Collection<T> coll, Generator<T> gen, int n){
for(int i = 0; i < n; i++){
coll.add(gen.next());
}
return coll;
}
}
class Product{
private final int id;
private String description;
private double price;
public Product(int IDnumber, String desc, double price){
this.id = IDnumber;
this.description = desc;
this.price = price;
// System.out.println(toString());
}
public String toString(){
return id + ": " + description + ", price: ¥" + price;
}
public void priceChange(double change){
price = change;
}
public static Generator<Product> generator = new Generator<Product>() {
private Random rand = new Random(47);
@Override
public Product next() {
return new Product(rand.nextInt(1000), "Test",
Math.round(rand.nextDouble() * 1000.0) + 0.99);
}
};
}
class Shelf extends ArrayList<Product> {
public Shelf(int nProducts){
Generators.fill(this, Product.generator, nProducts);
}
}
class Aisle extends ArrayList<Shelf> {
public Aisle(int nShelves, int nProducts){
for(int i = 0; i < nShelves; i++){
add(new Shelf(nProducts));
}
}
}
class CheckoutStand {}
class Office {}
public class Store extends ArrayList<Aisle> {
private ArrayList<CheckoutStand> checkouts = new ArrayList<CheckoutStand>();
private Office office = new Office();
public Store(int nAisles, int nShelves, int nProducts){
for(int i = 0; i < nAisles; i++){
add(new Aisle(nShelves,nProducts));
}
}
public String toString(){
StringBuilder result = new StringBuilder();
for(Aisle a : this){
for(Shelf s : a){
for(Product p : s){
result.append(p);
result.append("\n");
}
}
}
return result.toString();
}
public static void main(String[] args) {
System.out.println(new Store(3, 5, 2));
}
}
在泛型代码内部,无法获得任何有关泛型参数类型的信息。
由于擦除(在方法或类内部移除相关实际类型的信息)的存在,ArrayList<Integer> 和 ArrayList<String> 是相同的类( getClass() 之后是判等返回 true)。
一个类不能实现同一个泛型接口的两种变体,由于擦除的原因,这两个变体会成为相同的接口(一个泛型接口,仅实现一次即可)。
interface Payable<T> {}
class Employee implements Payable<Employee> {}
class Hourly extends Employee implements Payable<Hourly> {}
// Hourly 无法编译,因为擦除会将 Payable<Employee> 和 Payable<Hourly> 简化为相同的类 Payable
// class Hourly implements Payable<Hourly> {} 这样是可以编译的,但是相当于重复两次地实现相同的接口
// 同理可推,方法重载也会因为擦除的原因,导致产生相同的类型签名,从而无法编译,但是可以把方法名 f 改成 f1, f2
public class useList<T, W> {
void f(List<T> t) {}
void f(List<W> w) {}
}
至 15.11
29. 数组
数组初始化:
int[][] a = { { 1, 2, 3 }, { 4, 5, 6 } }
int[][] a = new int[1][2] // 数组中构成矩阵的每个向量都可以具有任意的长度
打印一维数组:Arrays.toString(a); 打印多维数组:Arrays.deepToString(a)
Arrays 类的6个基本方法:
- equals():用于比较两个数组是否相等(deepEquals() 用于比较多维数组)
- fill():用同一个值来填充数组,可以指定起始下标和结束下标
- sort():用于对数组排序
- binarySearch():用于在已经排序的数组中查找元素
- toSring()
- hashCode():产生数组的散列码
另外 asList() 接受任意的序列和数组作为参数,并将其转换为 List 容器
复制数组:System.arraycopy() 比 for 循环复制要快很多,但是必须保证两个数组具有相同的确切类型。
30. 散列
使用散列的数据结构:HashSet、HashMap、LinkedHashSet、LinkedHashMap
使用散列的目的:想要使用一个对象来查找另一个对象
31. ref 类
java.lang.ref 类库包含了一组类,这些类为垃圾回收提供了更大的灵活性。
有三个继承自抽象类 Reference 的类:
- SoftReference:用以实现内存敏感的高速缓存
- WeakReference:是为实现“规范映射”而设计的,不妨碍垃圾回收期回收映射的键或值
- WeakHashMap:被用来保存 WeakReference。每个值只保存一份实例以节省存储空间。当程序需要那个”值“的时候,便在映射中查询现有的对象,然后使用它(而不是重新再创建)。WeakHashMap 允许垃圾回收期自动清理键和值。
- PhantomReference:用以调度回收前的清理工作,比Java终止机制更灵活
32. I/O
33. 对象序列化
Java 的对象序列化将那些实现了 Serializable 接口的对象转换成一个字节序列,并能够在以后将这个字节序列完全恢复为原来的对象,从而实现轻量级持久性(持久性意味着一个对象的生存周期并不取决于程序是否正在执行,可以生存于程序的调用之间)。
34. 枚举
除了不能继承 enum 之外,基本上可以把 enum 看成一个常规的类——可以向里面添加方法,甚至 enum 可以有 main() 方法
可以为每一个 enum 的实例编写方法,从而为每一个实例赋予不同的行为。
public enum ConstantSpecificMethod {
DATE_TIME {
String getInfo(){
return DateFormat.getDateInstance().format(new Date());
}
},
CLASSPATH {
String getInfo(){
return System.getenv("CLASSPATH");
}
}
}
35. 注解
注解的使用方式几乎和修饰符的使用一模一样。
public class Testable{
public void execute(){
...
}
@Test void testExecute() { execute(); }
}
注解的定义像是接口的定义,也会被编译成 class 文件。定义注解时,会需要一些元注解,如 @Target(用来定义注解将应用于什么,比如是一个方法或者一个域) 和 @Retention(用来定义该注解在哪一个级别可用,在源代码中(SOURCE)、类文件中(CLASS)或者运行时(RUNTIME))
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Test {
...
}
| 元注解 | 解释 |
|---|---|
| @Target | 表示该注解可以用于什么地方。可能的ElementType参数包括: CONSTRUCTOR:构造器的声明 FIELD:域声明(包括 enum 实例) LOCAL_VARIABLE:局部变量 METHOD:方法 PACKAGE:包 PARAMETER:方法参数 TYPE:类、接口(包括注解类型)或 enum 声明 |
| @Retention | 表示需要在什么级别保存该注解信息。可选的RetentionPolicy参数包括: SOURCE:注解将被编译器丢弃 CLASS:注解在 class 文件中可用,但会被 VM 丢弃 RUNTIME:VM 将在运行期也保留注释,因此可以通过反射机制读取注解的信息 |
| @Documented | 将此注解包含在 Javadoc 中 |
| @Inherited | 允许子类继承父类中的注解 |
36. 并发
implements Runnable 必须具有 run() 方法,但是并不相当于具有了线程的能力,只是写了一个任务,需要把这个任务显式地附着到线程上。
Runnable 是执行工作的独立任务,但是并不返回任何值。如果希望任务在完成时能够返回一个值,可以换成实现 Callable 接口(需要指明类型参数,这个类型是从 call() 方法中返回的值的类型),必须具有 call() 方法,并且使用 ExecutorService.submit() 方法调用它(会自动得到 call() 方法的返回值)。
后台程序:必须要在线程调用(执行 thread.start() 方法)之前,调用 thread.setDaemon(true) 方法,才能将线程设置为后台程序
线程之间等待:在 A 线程下传入 B 线程,在调用 A.run() 方法时,调用 B.join(),其作用是让 A 线程等到 B 线程结束之后再执行(即当 B.isAlive() 返回为假的时候 A 线程才会执行),也可以在 B.join() 加上一个参数,如果 B 线程在目标时间内还没结束的话,join() 也会返回
在 Java 多线程程序中,所有线程都不允许抛出未捕获的 checked exception(比如 sleep() 时的 InterruptedException),也就是说各个线程需要自己把自己的 checked exception 处理掉。这一点是通过 java.lang.Runnable.run() 方法声明(因为此方法声明上没有 throw exception 部分)进行了约束。但是线程依然有可能抛出 unchecked exception(如运行时异常),当此类异常跑抛出时,线程就会终结,而对于主线程和其他线程完全不受影响,且完全感知不到某个线程抛出的异常(也是说完全无法 catch 到这个异常)。JVM 的这种设计源自于这样一种理念:”线程是独立执行的代码片断,线程的问题应该由线程自己来解决,而不要委托到外部。”基于这样的设计理念,在 Java 中,线程方法的异常(无论是 checked 还是 unchecked exception),都应该在线程代码边界之内( run() 方法内)进行 try catch 并处理掉。换句话说,我们不能捕获从线程中逃逸的异常。
如果需要捕获线程的 unchecked exception 时,可以通过修改 Executor 产生线程的方式来解决这个问题。Thread.UncaughtExceptionHandler 接口允许在每一个 Thread 对象上添加一个异常处理器。Thread.UncaughtExceptionHandler.uncaughtException() 方法会在线程因未捕获的异常而面临死亡时被调用。
原子操作:是不能被线程调度机制中断的操作。可以利用这一点来编写无锁的代码,这些代码不需要被同步,但是也可能不安全。
临界区(同步控制块):有时只是希望多个线程同时访问方法内部的部分代码而不是防止访问整个方法。通过这种方式分离出来的代码段称为临界区。
// 在进入这段代码前,必须得到 syncObject 对象的锁
// 如果其他线程已经得到这个锁,那么就得等到锁被释放以后,才能进入临界区
synchronized(syncObject){
...
}
线程四个状态:
- 新建(new):线程被创建后,只会短暂处于这种状态。之后调度器将把这个线程转变为可运行状态或阻塞状态
- 就绪(runable):在这个状态下,只要调度器把时间片分给线程,线程就可以运行。即,在任意时刻,线程可以运行也可以不运行,去看调度器是否分配了时间片
- 阻塞(blocked):当线程处于阻塞状态时,调度器会忽略线程,直到线程重新进入了就绪状态,才可能执行
- 进入阻塞状态的原因
- 通过调用 sleep(milliseconds) 使任务进入休眠状态
- 通过调用 wait() 将线程挂起,直到线程得到了 notify() 或者 notifyAll() 消息,线程才会进入就绪状态
- 任务在等待某个输入/输出完成
- 任务视图在某个对象上调用其同步控制方法,但是对象锁不可用,因为另一个任务已经获取了这个锁
- 进入阻塞状态的原因
- 死亡(dead):此时线程不再是可调度的
Java编程思想 笔记的更多相关文章
- java编程思想笔记(1)
java编程思想笔记(1) 一,对象的创建和生命周期 对象的数据位于何处?怎样控制对象的生命周期? 在堆(heap)的内存池中动态地创建对象. java完全采用了动态内存分配方式. 二,垃圾回收器 自 ...
- #Java编程思想笔记(一)——static
Java编程思想笔记(一)--static 看<Java编程思想>已经有一段时间了,一直以来都把笔记做在印象笔记上,今天开始写博客来记录. 第一篇笔记来写static关键字. static ...
- 2.1(java编程思想笔记)位移操作
java位移操作主要有两种: 有符号位移:有符号位移会保留原有数字正负性,即正数依然是正数,负数依然是负数. 有符号位左移时,低位补0. 有符号右移时:当数字为正数,高位补0.当数字为负时高位补1. ...
- 7.JAVA编程思想笔记隐藏实施过程
欢迎转载,转载请标明出处:http://blog.csdn.net/notbaron/article/details/51040237 "进行面向对象的设计时,一项主要的考虑是:怎样将发生变 ...
- java编程思想笔记(第一章)
Alan Kay 第一个定义了面向对象的语言 1.万物皆对象 2.程序是对象的集合,他们彼此通过发送消息来调用对方. 3.每个对象都拥有由其他对象所构成的存储 4.每个对象都拥有其类型(TYpe) 5 ...
- java编程思想笔记(一)——面向对象导论
1.1 抽象过程 1.所有编程语言都提供抽象编程机制. 2.人们所能够解决的问题的复杂性直接取决于抽象的类型(所抽象的是什么)和质量. 3."命令式"语言(basic,c等)都是对 ...
- java继承内部类问题(java编程思想笔记)
普通内部类默认持有指向所属外部类的引用.如果新定义一个类来继承内部类,那“秘密”的引用该如何初始化? java提供了特殊的语法: class Egg2 { public class Yolk{ pub ...
- Java编程思想笔记
打好java基础 后续会增加相应基础笔试题 目录如下 1 对象导论2 一切都是对象3 操作符4 控制执行流程5 初始化与清理6 访问控制权限7 复用类8 多态9 接口10 内部类11 持有对象12 通 ...
- Java编程思想笔记(第二章)
第二章 一切都是对象 尽管Java是基于C++的,但相比之下,Java是一种更纯粹的面向对象程序设计语言. c++和Java都是杂合型语言(hybird language) 用引用(referenc ...
随机推荐
- MySql基础_DDL_DML_DQL(资料一)
今日内容 数据库的基本概念 MySQL数据库软件 安装 卸载 配置 SQL 数据库的基本概念 1. 数据库的英文单词: DataBase 简称 : DB 2. 什么数据库? * 用于存储和管理数据的仓 ...
- 深入理解SVM,详解SMO算法
今天是机器学习专题第35篇文章,我们继续SVM模型的原理,今天我们来讲解的是SMO算法. 公式回顾 在之前的文章当中我们对硬间隔以及软间隔问题都进行了分析和公式推导,我们发现软间隔和硬间隔的形式非常接 ...
- java 并发线程池的理解和使用
一.为什么要用线程池 合理利用线程池能够带来三个好处. 第一:降低资源消耗.通过重复利用已创建的线程降低线程创建和销毁造成的消耗. 第二:提高响应速度.当任务到达时,任务可以不需要的等到线程创建就能立 ...
- 剑指offer-二叉树
1. 平衡二叉树 输入一棵二叉树,判断该二叉树是否是平衡二叉树. 解: 要么是一颗空树,要么左右子树都是平衡二叉树且左右子树深度之差不超过1 1 # class TreeNode: 2 # def _ ...
- 【题解】[SDOI2015]星际战争
\(\color{red}{Link}\) \(\text{Solution:}\) 观察到,如果一个时间\(T\)可以完成任务,则\(T+1\)这个时间也可以完成任务. 于是我们可以二分. 为了避免 ...
- Ubuntu通过iptables防止ssh暴力破解
步骤 安装iptables-persistent用于保存iptables规则 配置iptables规则 实时更新iptables规则以拦截IP访问 安装iptables-persistent sudo ...
- 《穷查理年鉴》金钱 & 生意 & 律师(关于金钱)
金钱 025.钱还得快才会借得快. 030.钱和人有着复杂的友谊:人能让钱变坏,钱也能让人变坏. 034.绝望增加债务,勤奋偿还债务. 037.只有一无所有的人才会没有烦恼. 049.穷人为他的胃找食 ...
- tuple的增删改查
dict = {"k1": "v1", "k2": "v2", "k3": "v3&quo ...
- 2-K8S常用命令
kubectl 命令行管理工具 类型 命令 描述 基础命令 create 通过文件名或标准输入创建资源 expose 为Deployment,Pod创建service run 在集群中运行一个特定的镜 ...
- Docker笔记2:Docker 镜像仓库
Docker 镜像的官方仓库位于国外服务器上,在国内下载时比较慢,但是可以使用国内镜像市场的加速器(比如阿里云加速器)以提高拉取速度. Docker 官方的镜像市场,可以和 Gitlab 或 GitH ...