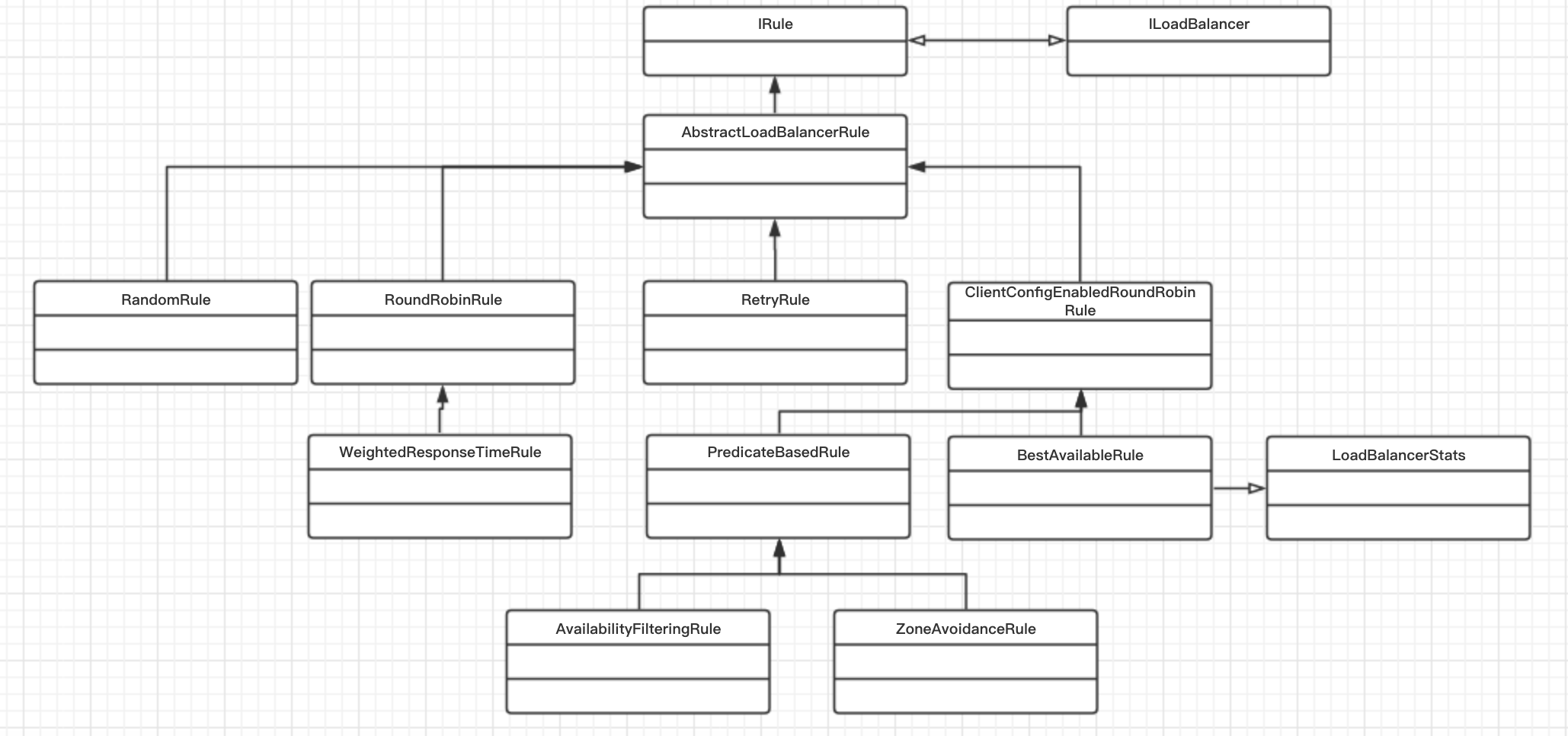
ribbon源码(4) 载均衡算法
负载均衡算法模块主要的功能是从负载均衡器中获取服务器列表信息,根据算法选取出一个服务器。
IRule
负载均衡算法接口
public interface IRule{
public Server choose(Object key);//选择一个服务器
public void setLoadBalancer(ILoadBalancer lb);//设置负载均衡器
public ILoadBalancer getLoadBalancer(); //获取负载均衡器
}
通过BaseLoadBalancer的setRule或构造函数来为BaseLoadBalancer添加IRule
public void setRule(IRule rule) {
if (rule != null) {
this.rule = rule;
} else {
/* default rule */
this.rule = new RoundRobinRule();
}
if (this.rule.getLoadBalancer() != this) {
this.rule.setLoadBalancer(this);
}
}
RandomRule
生成一个随机数,从负载均衡器中选取一个服务器。
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
return null;
}
Server server = null;
while (server == null) {
if (Thread.interrupted()) {
return null;
}
List<Server> upList = lb.getReachableServers();
List<Server> allList = lb.getAllServers();
int serverCount = allList.size();
if (serverCount == 0) {
return null;
}
int index = rand.nextInt(serverCount);
server = upList.get(index);
if (server == null) {
Thread.yield();
continue;
}
if (server.isAlive()) {
return (server);
}
server = null;
Thread.yield();
}
return server;
}
RoundRobinRule
轮询从负载均衡器中选取一个服务器。
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
log.warn("no load balancer");
return null;
}
Server server = null;
int count = 0;
while (server == null && count++ < 10) {
List<Server> reachableServers = lb.getReachableServers();
List<Server> allServers = lb.getAllServers();
int upCount = reachableServers.size();
int serverCount = allServers.size();
if ((upCount == 0) || (serverCount == 0)) {
log.warn("No up servers available from load balancer: " + lb);
return null;
}
int nextServerIndex = incrementAndGetModulo(serverCount);
server = allServers.get(nextServerIndex);
if (server == null) {
/* Transient. */
Thread.yield();
continue;
}
if (server.isAlive() && (server.isReadyToServe())) {
return (server);
}
server = null;
}
if (count >= 10) {
log.warn("No available alive servers after 10 tries from load balancer: "
+ lb);
}
return server;
}
BestAvailableRule
选择并发量最小且没有被熔断的服务器,需要使用到LoadBalancerStats来获取服务器的状态。
public Server choose(Object key) {
if (loadBalancerStats == null) {
return super.choose(key);
}
List<Server> serverList = getLoadBalancer().getAllServers();
int minimalConcurrentConnections = Integer.MAX_VALUE;
long currentTime = System.currentTimeMillis();
Server chosen = null;
for (Server server: serverList) {
ServerStats serverStats = loadBalancerStats.getSingleServerStat(server);
if (!serverStats.isCircuitBreakerTripped(currentTime)) {
int concurrentConnections = serverStats.getActiveRequestsCount(currentTime);
if (concurrentConnections < minimalConcurrentConnections) {
minimalConcurrentConnections = concurrentConnections;
chosen = server;
}
}
}
if (chosen == null) {
return super.choose(key);
} else {
return chosen;
}
}
WeightedResponseTimeRule
按照响应时间的比例来选择服务器。首先内部会有一个定时器,定时从负载均衡器里面读取服务器的平均响应时间,然后根据平均响应时间转换成权重。
class DynamicServerWeightTask extends TimerTask {
public void run() {
ServerWeight serverWeight = new ServerWeight();
try {
serverWeight.maintainWeights();
} catch (Exception e) {
logger.error("Error running DynamicServerWeightTask for {}", name, e);
}
}
}
class ServerWeight {
public void maintainWeights() {
ILoadBalancer lb = getLoadBalancer();
if (lb == null) {
return;
}
if (!serverWeightAssignmentInProgress.compareAndSet(false, true)) {
return;
}
try {
logger.info("Weight adjusting job started");
AbstractLoadBalancer nlb = (AbstractLoadBalancer) lb;
LoadBalancerStats stats = nlb.getLoadBalancerStats();
if (stats == null) {
return;
}
double totalResponseTime = 0;
// find maximal 95% response time
for (Server server : nlb.getAllServers()) {
// this will automatically load the stats if not in cache
ServerStats ss = stats.getSingleServerStat(server);
totalResponseTime += ss.getResponseTimeAvg();
}
// weight for each server is (sum of responseTime of all servers - responseTime)
// so that the longer the response time, the less the weight and the less likely to be chosen
Double weightSoFar = 0.0;
// create new list and hot swap the reference
List<Double> finalWeights = new ArrayList<Double>();
for (Server server : nlb.getAllServers()) {
ServerStats ss = stats.getSingleServerStat(server);
double weight = totalResponseTime - ss.getResponseTimeAvg();
weightSoFar += weight;
finalWeights.add(weightSoFar);
}
setWeights(finalWeights);
} catch (Exception e) {
logger.error("Error calculating server weights", e);
} finally {
serverWeightAssignmentInProgress.set(false);
}
}
}
然后根据权重来选择服务器
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
return null;
}
Server server = null;
while (server == null) {
// get hold of the current reference in case it is changed from the other thread
List<Double> currentWeights = accumulatedWeights;
if (Thread.interrupted()) {
return null;
}
List<Server> allList = lb.getAllServers();
int serverCount = allList.size();
if (serverCount == 0) {
return null;
}
int serverIndex = 0;
// last one in the list is the sum of all weights
double maxTotalWeight = currentWeights.size() == 0 ? 0 : currentWeights.get(currentWeights.size() - 1);
// No server has been hit yet and total weight is not initialized
// fallback to use round robin
if (maxTotalWeight < 0.001d) {
server = super.choose(getLoadBalancer(), key);
if(server == null) {
return server;
}
} else {
// generate a random weight between 0 (inclusive) to maxTotalWeight (exclusive)
double randomWeight = random.nextDouble() * maxTotalWeight;
// pick the server index based on the randomIndex
int n = 0;
for (Double d : currentWeights) {
if (d >= randomWeight) {
serverIndex = n;
break;
} else {
n++;
}
}
server = allList.get(serverIndex);
}
if (server == null) {
/* Transient. */
Thread.yield();
continue;
}
if (server.isAlive()) {
return (server);
}
// Next.
server = null;
}
return server;
}
AvailabilityFilteringRule
使用RoundRobinRule来选择服务器,并且通过AvailabilityPredicate进行筛选。AvailabilityPredicate会剔除熔断的和超过指定并发量的server。
public Server choose(Object key) {
int count = 0;
Server server = roundRobinRule.choose(key);
while (count++ <= 10) {
if (predicate.apply(new PredicateKey(server))) {
return server;
}
server = roundRobinRule.choose(key);
}
return super.choose(key);
}
AvailabilityPredicate:
public boolean apply(@Nullable PredicateKey input) {
LoadBalancerStats stats = getLBStats();
if (stats == null) {
return true;
}
return !shouldSkipServer(stats.getSingleServerStat(input.getServer()));
}
private boolean shouldSkipServer(ServerStats stats) {
if ((CIRCUIT_BREAKER_FILTERING.get() && stats.isCircuitBreakerTripped())
|| stats.getActiveRequestsCount() >= activeConnectionsLimit.get()) {
return true;
}
return false;
}
使用AvailabilityFilteringRule涉及配置:
| 属性 | 实现 | 默认值 |
| niws.loadbalancer.availabilityFilteringRule.filterCircuitTripped | 是否剔除熔断server | true |
|
niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit |
最大连接数 | Integer.MAX_VALUE |
ZoneAvoidanceRule
这个rule虽然继承了PredicateBasedRule但是在使用上都与上面的rule不一样,其实他的核心主要是为ZoneAwareLoadBalancer提供了筛选zone的静态方法,他并不通用。
静态方法getAvailableZones,会遍历所有的zone,以zone为单位,检查各个zone的实例个数,熔断比率,来决定是否包含改zone。
静态方法createSnapshot,将LoadBalancerStats按zone返回map结构
类图
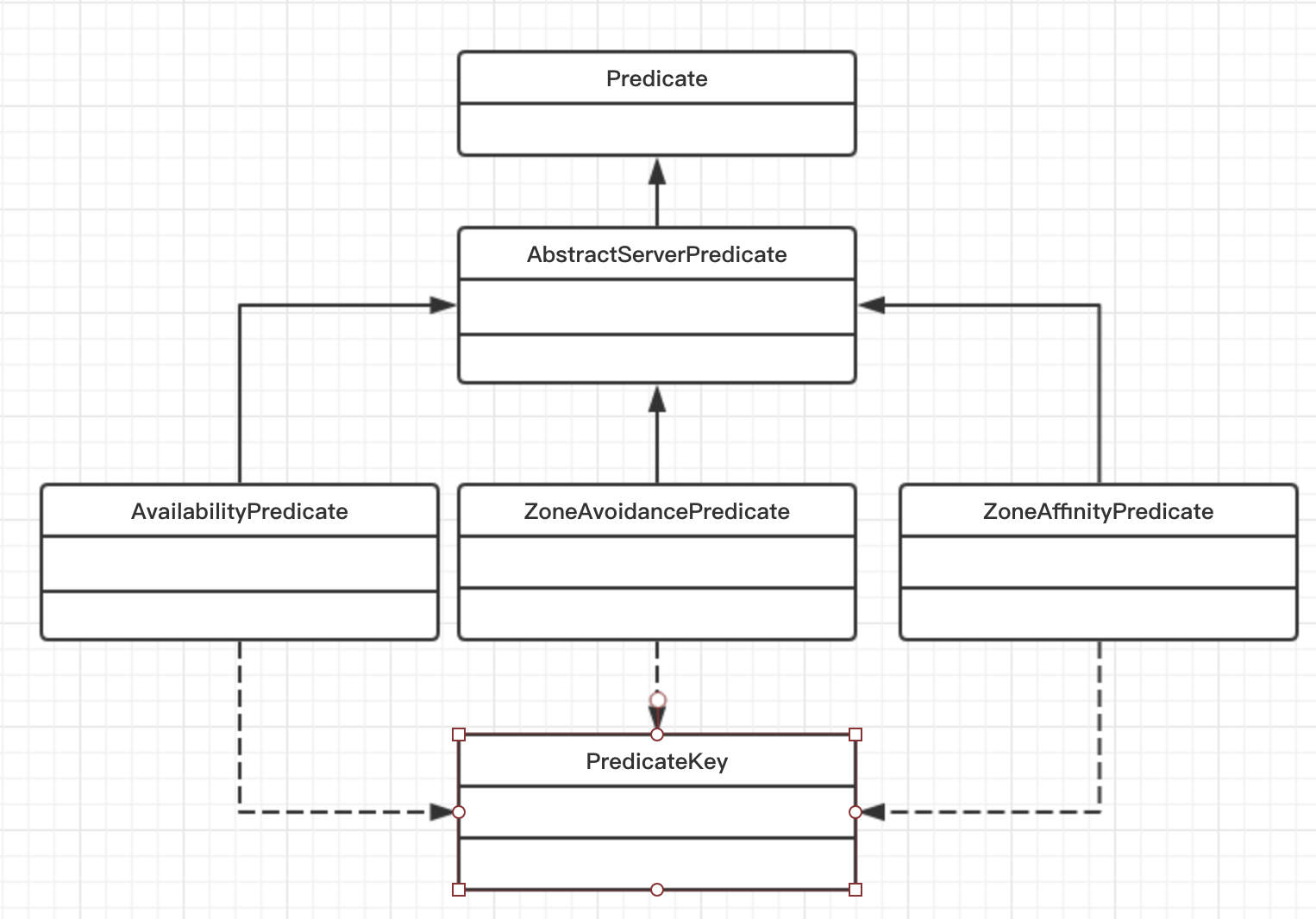
Predicate
用于过滤服务器,ribbon提供了三个过滤条件,AvailabilityPredicate、ZoneAvoidancePredicate、ZoneAffinityPredicate。PredicateKey为过滤的参数。
ribbon源码(4) 载均衡算法的更多相关文章
- Spring Cloud Ribbon 源码分析---负载均衡算法
上一篇分析了Ribbon如何发送出去一个自带负载均衡效果的HTTP请求,本节就重点分析各个算法都是如何实现. 负载均衡整体是从IRule进去的: public interface IRule{ /* ...
- Spring Cloud Ribbon源码分析---负载均衡实现
上一篇结合 Eureka 和 Ribbon 搭建了服务注册中心,利用Ribbon实现了可配置负载均衡的服务调用.这一篇我们来分析Ribbon实现负载均衡的过程. 从 @LoadBalanced入手 还 ...
- ribbon源码(2) 负载均衡器
负载均衡器对外提供负载均衡的功能,本质上是是维护当前服务的服务器列表和服务器状态,通过负载均衡算法选取合适的服务器地址. 用户可以通过实现ILoadBalancer来实现自己的负载均衡器,ribbon ...
- Ribbon源码分析(二)-- 服务列表的获取和负载均衡算法分析
上一篇博客(https://www.cnblogs.com/yangxiaohui227/p/12614343.html)分享了ribbon如何实现对http://product/info/这个链接重 ...
- 【一起学源码-微服务】Ribbon 源码四:进一步探究Ribbon的IRule和IPing
前言 前情回顾 上一讲深入的讲解了Ribbon的初始化过程及Ribbon与Eureka的整合代码,与Eureka整合的类就是DiscoveryEnableNIWSServerList,同时在Dynam ...
- 【一起学源码-微服务】Ribbon源码五:Ribbon源码解读汇总篇~
前言 想说的话 [一起学源码-微服务-Ribbon]专栏到这里就已经全部结束了,共更新四篇文章. Ribbon比较小巧,这里是直接 读的spring cloud 内嵌封装的版本,里面的各种config ...
- ribbon源码(1) 概述
ribbon的核心功能是提供客户端在进行网络请求时负载均衡的能力.主要有以下几个模块: 负载均衡器模块 负载均衡器模块提供了负载均衡能力,详细参见ribbon源码之负载均衡器. 配置模块 配置模块管理 ...
- Android开源项目 Universal imageloader 源码研究之Lru算法
https://github.com/nostra13/Android-Universal-Image-Loader universal imageloader 源码研究之Lru算法 LRU - Le ...
- Spring源码加载过程图解(一)
最近看了一下Spring源码加载的简装版本,为了更好的理解,所以在绘图的基础上,进行了一些总结.(图画是为了理解和便于记忆Spring架构) Spring的核心是IOC(控制反转)和AOP(面向切面编 ...
随机推荐
- Devops与敏捷二者能否结合?
当前软件行业的趋势倾向于使应用程序开发和部署成为业务运营的重要组成部分.这些公司开始专注于实现像DevOps解决方案这样的方法,这有助于缩短产品开发时间.使用DevOps进行开发减少了交付软件所需的阶 ...
- 启动tomcat出现闪退的原因
出现闪退的可能有几点: 1.没有安装jdk或者配置jdk是否配置成功 2.找不到jdk安装的路径 3.tomcat环境配置失败 如果是第二点原因(确保第一第三点配置都正确无误)找不到jdk路径的话,可 ...
- selenium入门编程总结学习于龙腾)
"""编程题打开 http://ip/ecshop/wwwroot/admin/privilege.php?act=login登录(admin/123456)点击商品管理 ...
- ubuntu18.04 开机定时启动任务
1,crontab 格式:M H D m d cmd == 分 时 天 月 周几 命令 参数 : crontab -e : 执行文字编辑器来设定时程表,内定的文字编辑器是 VI,如果你想用别的文字编辑 ...
- asp.net报表结构学习记录
当一份web报表项目压缩包躺在我的文件夹里时,我是完全懵的.作为一个学习了一个月java的asp.net小白,以前从来没有接触过这方面,我完全不知道从何入手. 手里也有asp.net开发学习视频,但都 ...
- 揭秘|一探腾讯基于Kubeflow建立的多租户训练平台背后的技术架构
腾讯业务及组织架构现状 先简单和大家介绍一下腾讯内部的业务及相关组织架构的现状,有助于帮助大家理解为什么我们会基于后面的架构来设计整套方案. 下图的应用大多数人经常会用到,比如微信.腾讯视频.游戏等等 ...
- 大数据计算的基石——MapReduce
MapReduce Google File System提供了大数据存储的方案,这也为后来HDFS提供了理论依据,但是在大数据存储之上的大数据计算则不得不提到MapReduce. 虽然现在通过框架的不 ...
- 深度优先搜索(DFS)解题总结
定义 深度优先搜索算法(Depth-First-Search),是搜索算法的一种.它沿着树的深度遍历树的节点,尽可能深的搜索树的分支. 例如下图,其深度优先遍历顺序为 1->2->4-&g ...
- ARouter使用
1. androidstudio3.0配置 javaCompileOptions { annotationProcessorOptions { arguments = [AROUTER_MODULE_ ...
- F - 丘 (欧拉函数)
Chinese people think of '8' as the lucky digit. Bob also likes digit '8'. Moreover, Bob has his own ...