手把手教你爬取B站弹幕!
效果
输入要爬取的视频的BV号即可爬取该视频的弹幕。

过程
基本思路
基本的思路很简单,还是老步骤:
1、构造爬取的url
2、解析返回的数据
3、使用json或Xpath或正则表达式提取数据
4、保存数据
寻找url地址
第一步
刚开始还是从网页版中寻找url地址,结果请求很多,找了半天也没有找到
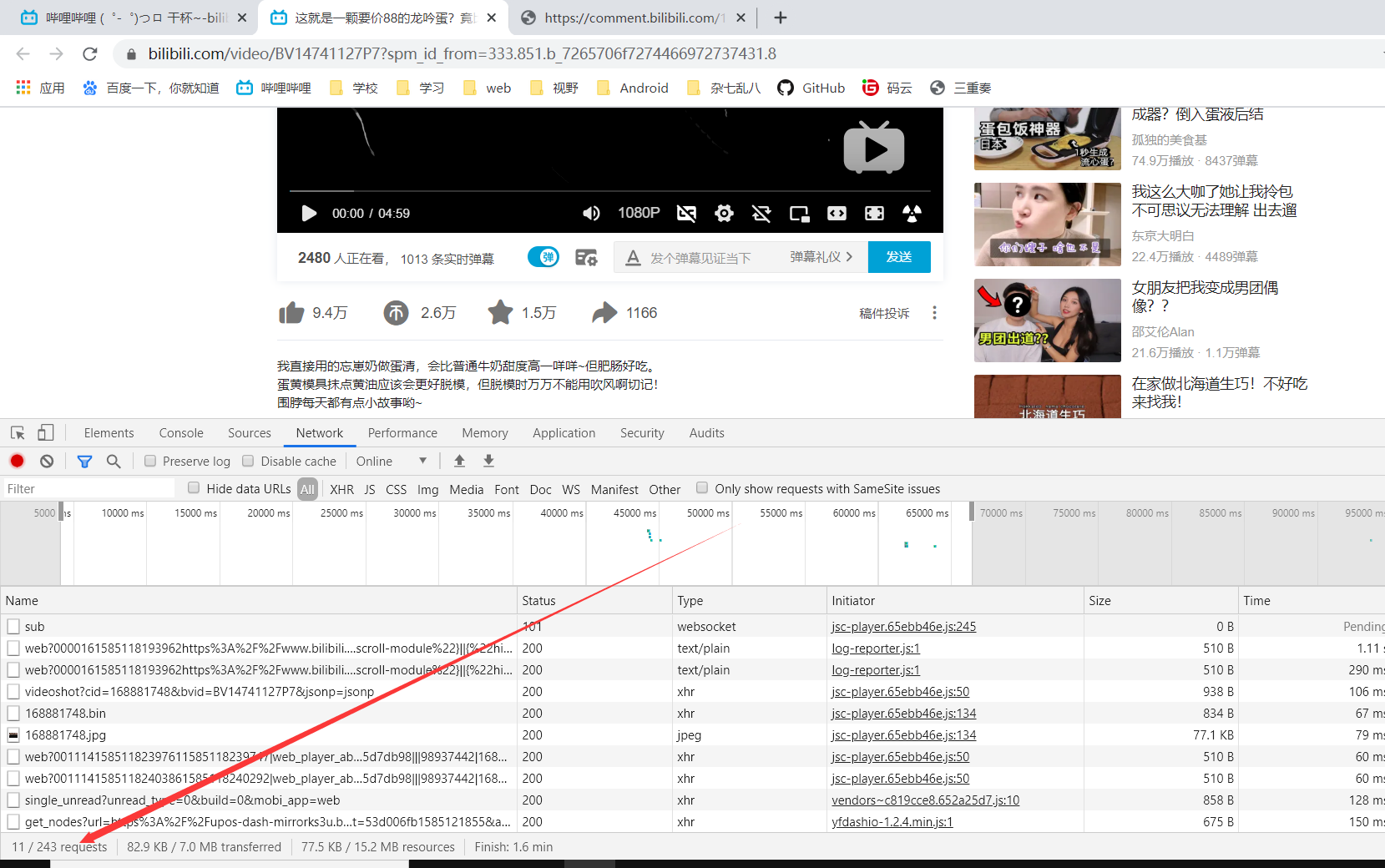
第二步
于是我们可以访问一下手机版的页面,而根据常识,弹幕这种东西一般是通过ajax来请求的,所以我们过滤一下,只看异步请求。
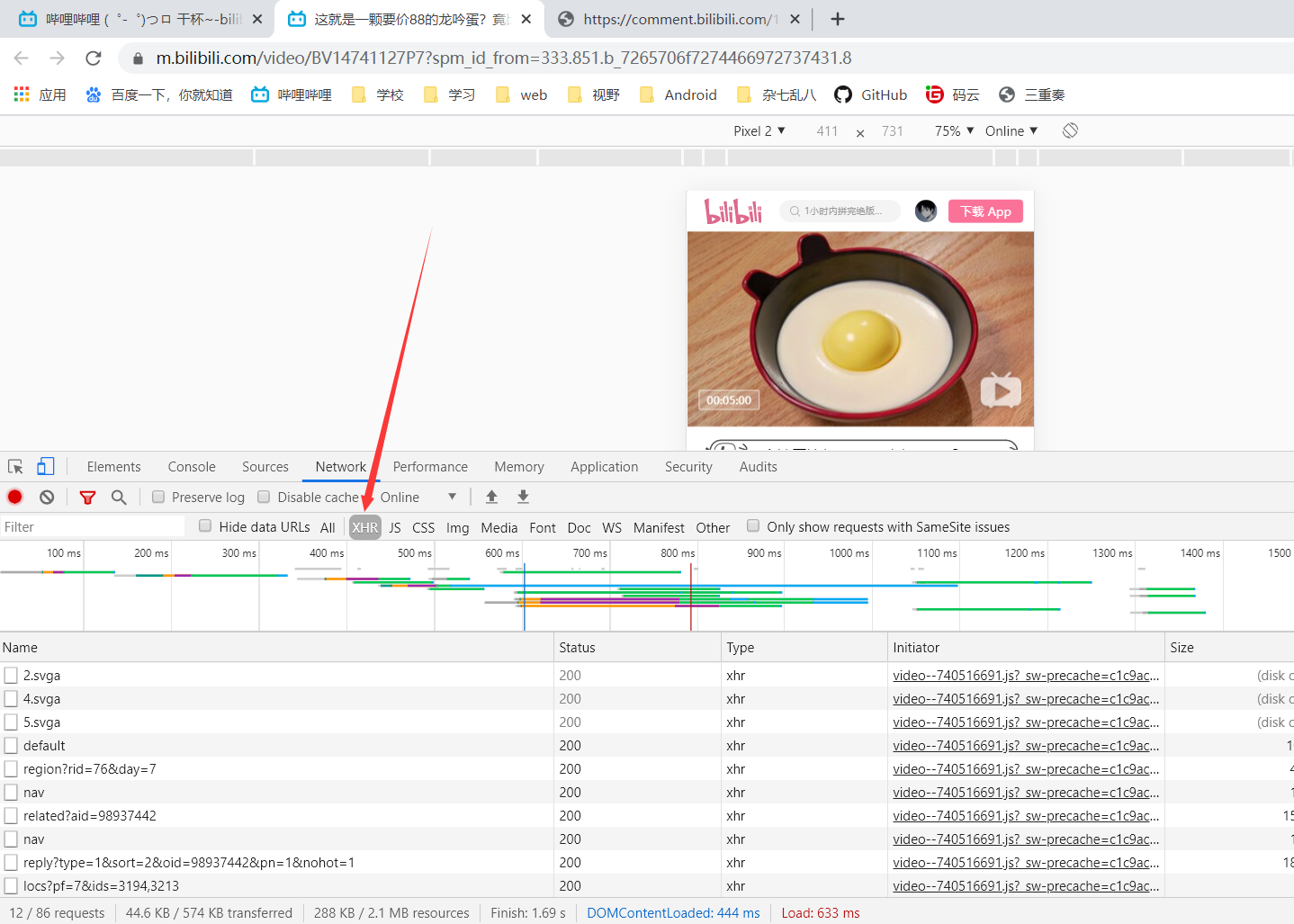
此时请求就变得少了很多,但是依然没有找到我们需要的弹幕数据,此时才发现我们并没有点击播放视频。
第三步
弹幕是在视频播放的过程中播放的,理所当然只有当我们播放视频并且打开弹幕后才会请求弹幕的数据,我们点击播放。
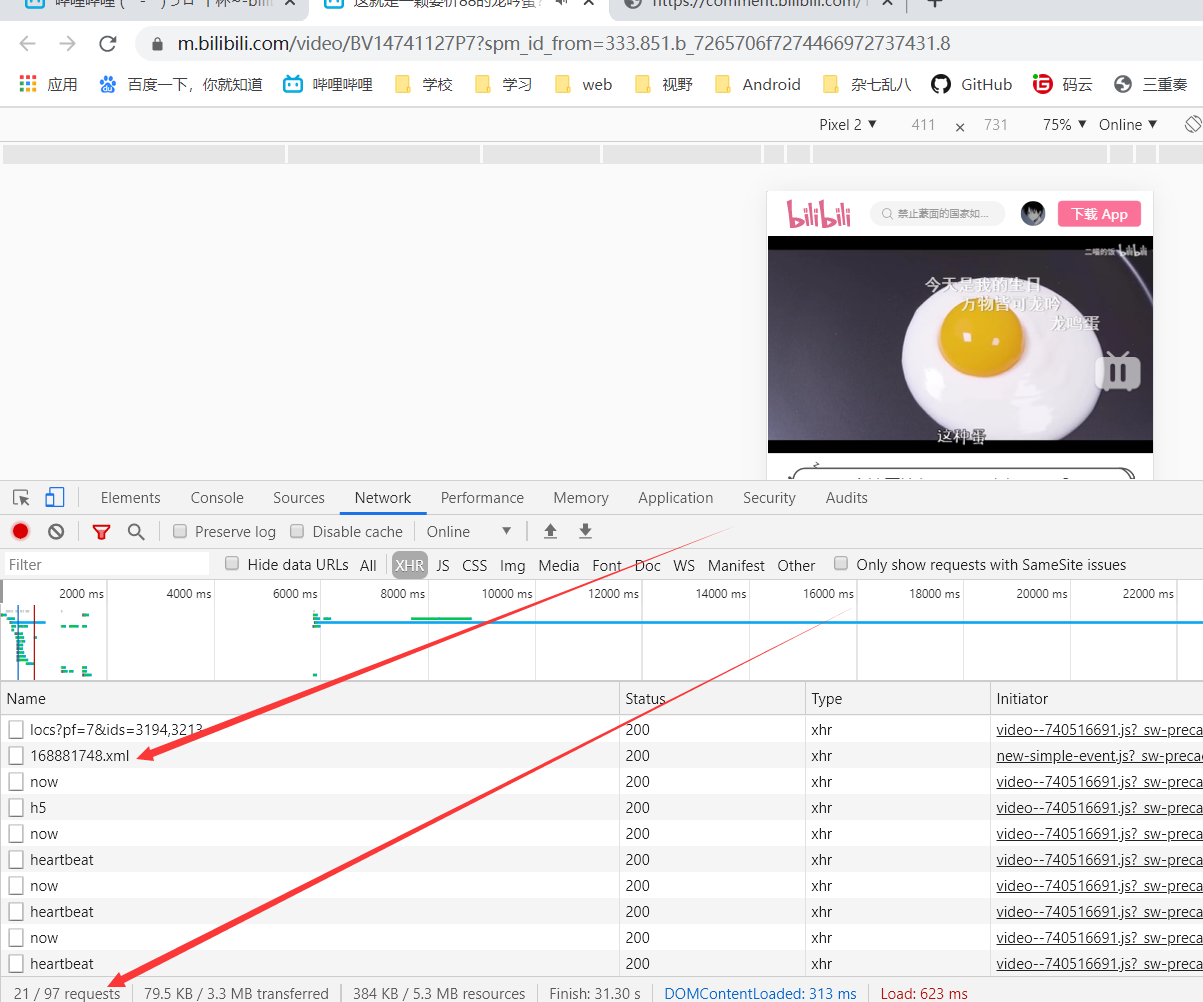
点击播放后我们可以发现请求变多了,再次寻找我们发现 168881748.xml 请求的地址便是弹幕数据了。
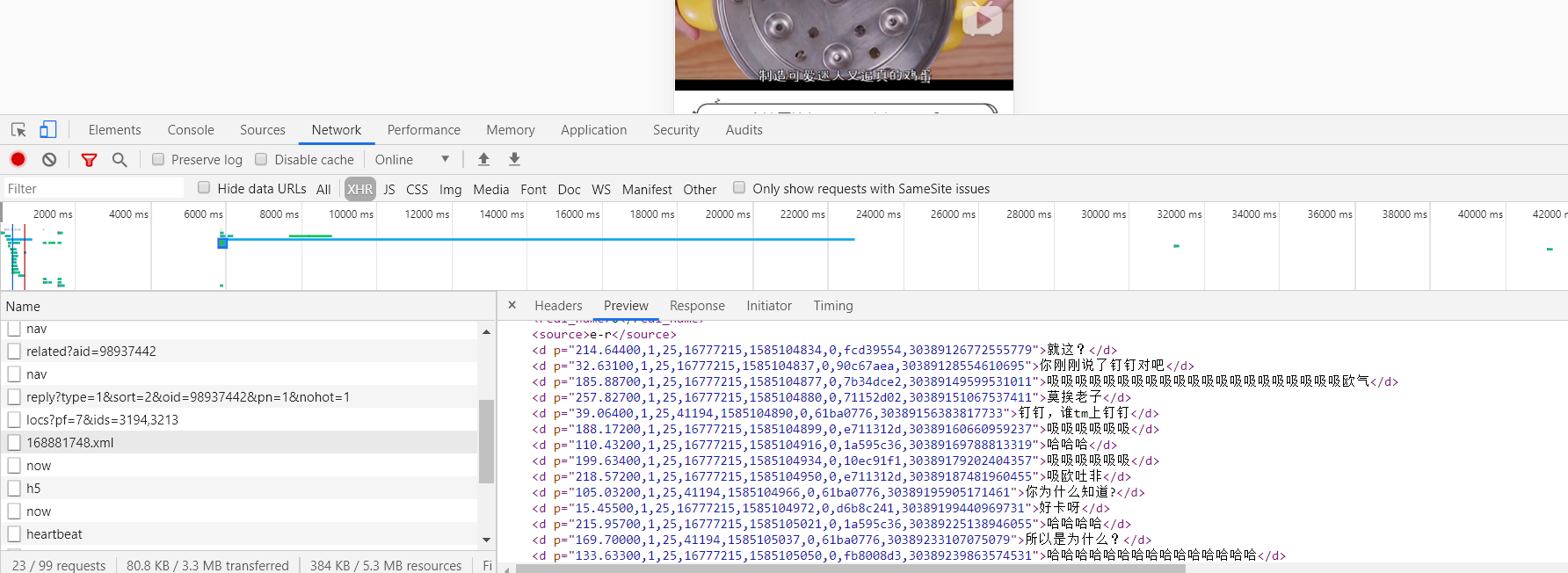
第四步
到这里我们就想到了,这种地址是怎么请求的呢?不同的视频请求的地址肯定是不一样的,应该是js生成的吧!现在我们来搜索一下该文件名``168881748`

很显然这是构造出来的地址,我们点进去看一下

不出所料是js构成的请求地址,我们可以发现这便是页面的数据,我们进一步去验证一下,刷新页面,查看一下网页的数据。
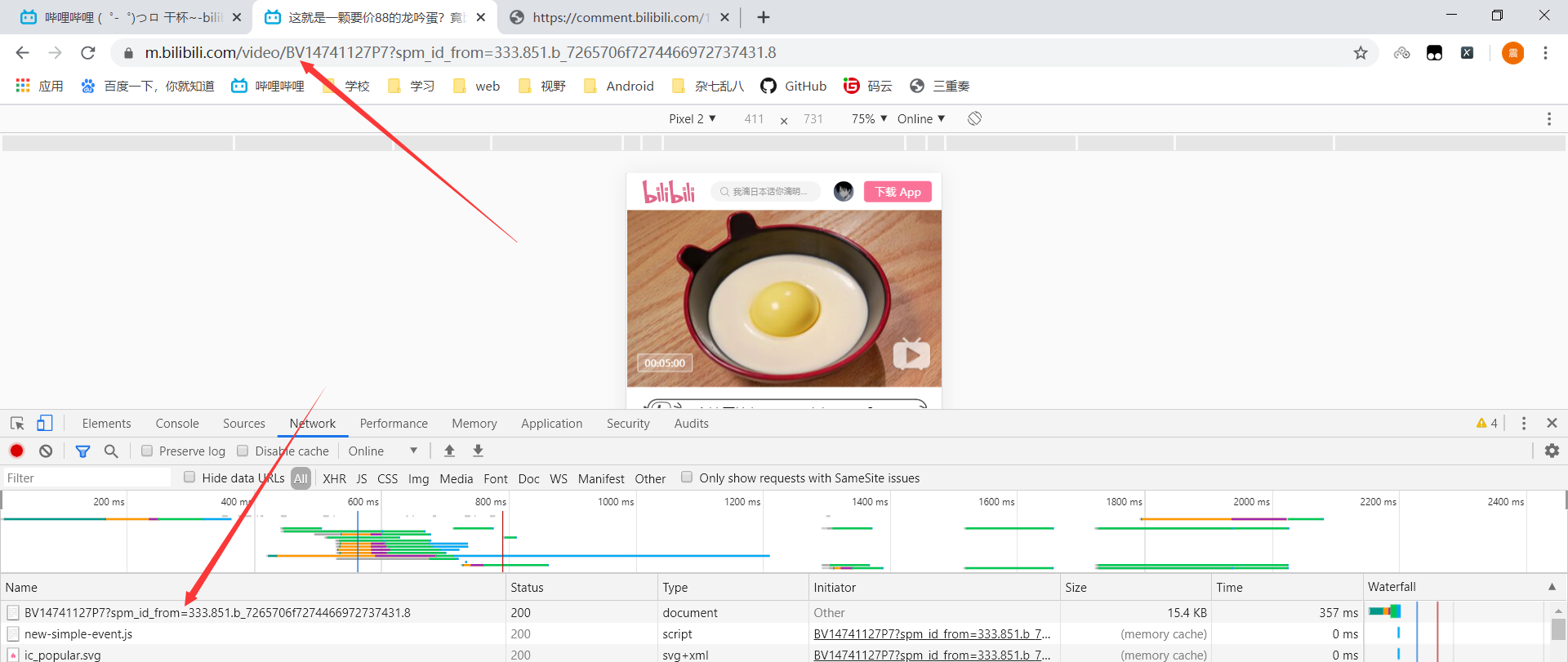
果然在该页面的文档中我们找到了
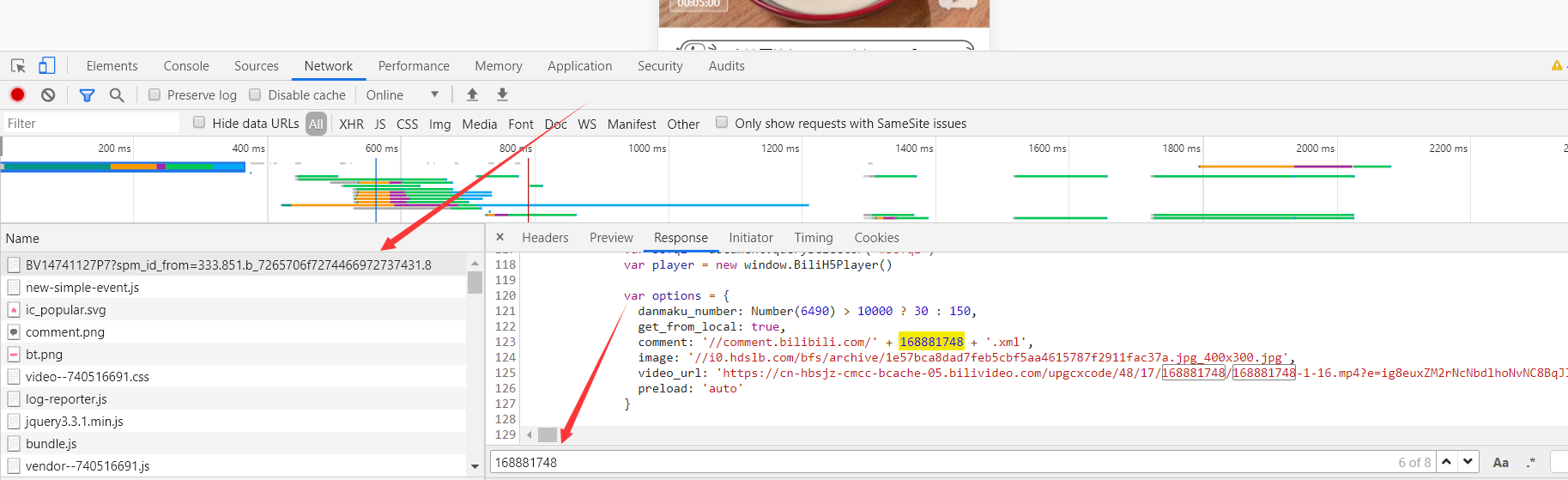
现在的思路
现在思路就很清晰了
1、通过视频url获取弹幕文件url
2、爬取弹幕文件url
3、提取数据
代码实现
# coding=utf-8
import requests
from lxml import etree
import re
class BiliSpider:
def __init__(self,BV):
# 构造要爬取的视频url地址
self.BVurl = "https://m.bilibili.com/video/"+BV
self.headers = {"User-Agent": "Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Mobile Safari/537.36"}
# 弹幕都是在一个url请求中,该url请求在视频url的js脚本中构造
def getXml_url(self):
# 获取该视频网页的内容
response = requests.get(self.BVurl, headers = self.headers)
html_str = response.content.decode()
# 使用正则找出该弹幕地址
# 格式为:https://comment.bilibili.com/168087953.xml
# 我们分隔出的是地址中的弹幕文件名,即 168087953
getWord_url = re.findall(" '//comment.bilibili.com/'+ (.*) +'.xml',", html_str)
getWord_url = getWord_url[0].replace("+","").replace(" ","")
# 组装成要请求的xml地址
xml_url = "https://comment.bilibili.com/{}.xml".format(getWord_url)
return xml_url
# Xpath不能解析指明编码格式的字符串,所以此处我们不解码,还是二进制文本
def parse_url(self,url):
response = requests.get(url,headers = self.headers)
return response.content
# 弹幕包含在xml中的<d></d>中,取出即可
def get_word_list(self,str):
html = etree.HTML(str)
word_list = html.xpath("//d/text()")
return word_list
def run(self):
# 1.根据BV号获取弹幕的地址
start_url = self.getXml_url()
# 2.请求并解析数据
xml_str = self.parse_url(start_url)
word_list = self.get_word_list(xml_str)
# 3.打印
for word in word_list:
print(word)
if __name__ == '__main__':
BVName = input("请输入要爬取的视频的BV号:")
spider = BiliSpider(BVName)
spider.run()
这里只打印了弹幕,并没有保存,可以根据自己的需求进行更改!
手把手教你爬取B站弹幕!的更多相关文章
- Java爬取B站弹幕 —— Python云图Wordcloud生成弹幕词云
一 . Java爬取B站弹幕 弹幕的存储位置 如何通过B站视频AV号找到弹幕对应的xml文件号 首先爬取视频网页,将对应视频网页源码获得 就可以找到该视频的av号aid=8678034 还有弹幕序号, ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
- 爬取B站弹幕并且制作词云
目录 爬取弹幕 1. 从手机端口进入网页爬取找到接口 2.代码 制作词云 1.文件读取 2.代码 爬取弹幕 1. 从手机端口进入网页爬取找到接口 2.代码 import requests from l ...
- Python爬取b站任意up主所有视频弹幕
爬取b站弹幕并不困难.要得到up主所有视频弹幕,我们首先进入up主视频页面,即https://space.bilibili.com/id号/video这个页面.按F12打开开发者菜单,刷新一下,在ne ...
- Python爬取B站耗子尾汁、不讲武德出处的视频弹幕
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 前言 耗子喂汁是什么意思什么梗呢?可能很多人不知道,这个梗是出自马保国,经常上网的人可能听说过这个 ...
- 用Python爬取B站、腾讯视频、爱奇艺和芒果TV视频弹幕!
众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列.通过分析弹幕,我们可以快速洞察广大观众对于视频 ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- 爬虫练习四:爬取b站番剧字幕
由于个人经常在空闲时间在b站看些小视频欢乐一下,这次就想到了爬取b站视频的弹幕. 这里就以番剧<我的妹妹不可能那么可爱>第一季为例,抓取这一番剧每一话对应的弹幕. 1. 分析页面 这部番剧 ...
- Python 网络爬虫实战:爬取 B站《全职高手》20万条评论数据
本周我们的目标是:B站(哔哩哔哩弹幕网 https://www.bilibili.com )视频评论数据. 我们都知道,B站有很多号称“镇站之宝”的视频,拥有着数量极其恐怖的评论和弹幕.所以这次我们的 ...
随机推荐
- Linux系统中使用confluence构建企业wiki
搭建confluence服务需要的步骤有:一,安装java环境即安装jdk8.二,安装需要使用的数据库(建议使用mysql5.6).三,破解的confluence6服务. 一,所需软件下载 1,下载j ...
- HBuilderX SVN地址更改(SVN服务器IP地址变更)
HBuilderX编辑器中无法修改SVN地址,需要手动在SVN工具中修改 修改步骤: 1.右键编辑器中的SVN项目,选择打开文件所在目录 2.目录中空白处右键,选择TortoiseSVN --> ...
- 06、MyBatis 逆向工程
1.MyBatis逆向简介 mybatis需要程序员自己编写sql语句,mybatis官方提供逆向工程,可以针对单表自动生成mybatis执行所需要的代码(mapper.java.mapper.x ...
- PL/SQL Developer 13注册码(亲测可用)
product code: 4vkjwhfeh3ufnqnmpr9brvcuyujrx3n3le serial Number: 226959 password: xs374ca
- python3 多线程批量验证POC模板
#coding:utf-8 import threading,Queue,sys,os class RedisUN(threading.Thread): def __init__(self,queue ...
- [原题复现+审计][0CTF 2016] WEB piapiapia(反序列化、数组绕过)[改变序列化长度,导致反序列化漏洞]
简介 原题复现: 考察知识点:反序列化.数组绕过 线上平台:https://buuoj.cn(北京联合大学公开的CTF平台) 榆林学院内可使用信安协会内部的CTF训练平台找到此题 漏洞学习 数组 ...
- 【MathType教学】如何让括号内的内容居中
作为一款非常好用的公式编辑器,MathType它的功能十分强大,不仅包含了大量的数学符号,并且能和Office软件很好地兼容.但是有的时候打出来的公式可能不是自己想要的效果,这时我们就要用一些特别的办 ...
- Vegas视频的音频叠加效果怎么实现,可以用其他软件吗
有时我们会用Vegas为某段影片配音,我们要怎么把配音和背景声融合在一起呢?想必马上会有人反应过来:让配音和背景声分别置于两条轨道上就好了.这当然是一个相当好的方式. 可是,如果我想要把两段音频合成一 ...
- Vegas转场功能的妙用,让片头转场更酷炫
如今视频剪辑已经是一件非常平常的事情了,很多时候我们制作一段或者剪辑一段视频,其实都比较简单,但是如果想要视频显得高级些,这时候就可以给自己的视频制作一个好看的片头了,具体该怎么做呢? 用视频剪辑软件 ...
- MarkDown学习总结-2020.05.11
1.使用工具 1.1Typora 官网地址:https://www.typora.io/ 下载链接 2.基础入门 注意: []中的内容则是对应格式的标记符,默认全部标识符后面需要多加一个空格才能生效. ...