最新Spark入门篇
一、Spark简介
1.什么是Spark
Apache Spark是一种快速的集群计算技术,基于Hadoop MapReduce技术,扩展了MapReduce模型,主要特性是在内存中集群计算,速度更快。即使在磁盘上进行复杂计算,Spark依然比MapReduce更加高效。另一方面,Apache Spark扩展了MapReduce模型以使用更多类型的计算。
1.1 使用基于Hadoop的Spark
Spark与Hadoop是兼容的,Hadoop组件可以通过以下方式与Spark一起使用:
HDFS
Spark可以在HDFS之上运行,以利用分布式存储
MapReduce
Spark可以与MapReduce一起用于同一个Hadoop集群,也可以单独作为处理框架使用
YARN
可以使Spark应用程序在YARN(Hadoop NextGen)上运行
批处理和实时处理
MapReduce和Spark一起使用,其中MapReduce用于批处理,Spark用于实时处理
1.2 Spark的组件
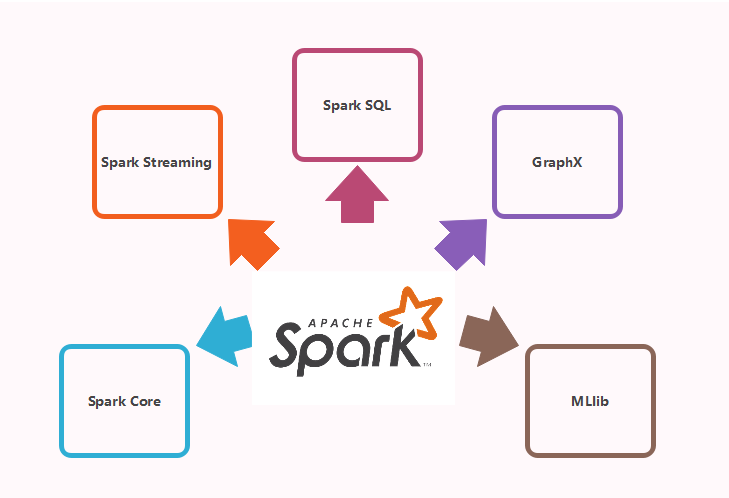
spark的组件主要有以下几种:
Spark Core
Spark Core是大规模并行和分布式数据处理的基础引擎。核心是分布式执行引擎,Java,Scala和Python API为分布式ETL应用程序开发提供了一个平台。此外,在核心上构建的其他库允许用于流式传输,SQL和机器学习的各种工作负载。它负责:
1.内存管理和故障恢复
2.在群集上调度,分发和监视作业
3.与存储系统交互
Spark Streaming
Spark Streaming是Spark的组件,用于处理实时流数据。因此,它是核心Spark API的补充。它支持实时数据流的高吞吐量和容错流处理。基本流单元是DStream,它基本上是一系列处理实时数据的RDD(弹性分布式数据集)
Spark SQL
Spark SQL是Spark中的一个新模块,它使用Spark编程API实现集成关系处理。它支持通过SQL或Hive查看数据。对于那些熟悉RDBMS的人来说,Spark SQL将很容易从之前的工具过度到可以扩展传统关系数据处理的边界。
Spark SQL通过函数编程API集成关系处理。此外,它为各种数据源提供支持,并且使用代理转换编织SQL查询,从而产生一个非常强大的工具。
Spark SQL包含四个库:
1.Data Source API
2.DataFrame API
3.Interpreter & Optimizer
4.SQL Service
GraphX
GraphX是用于图形和图形并行计算的Spark API。因此,它使用弹性分布式属性图扩展了Spark RDD。
属性图是一个有向多图,它可以有多个平行边。每个边和定点都有与之关联的用户定义属性。这里,平行边缘允许相同顶点之间的多个关系。在高层次上,GraphX通过引入弹性分布式属性图来扩展Spark RDD抽象:一个定向多图,其属性附加到每个顶点和边。
为了支持图形计算,GraphX公开了一组基本运算符(如,subgraph,joinVertices和mapReduceTriplets)以及Pregel API的优化变体。此外,GraphX包含越来越多的图算法和构建起,以简化图形分析任务。
MLlib(Machine Learning)
MLib代表机器学习库,用于在Apache Spark中执行机器学习功能。
2.Spark运行模式
5种模式:
local
本地模式,主要用于本地开发测试
Standlone
集群模式,典型的Master/slave模式
on yarn
集群模式,运行在yarn资源管理器框架之上,由yarn负责资源管理,Spark负责任务调度和计算
on mesos
集群模式,运行在mesos资源管理器框架之上,由mesos负责资源管理,Spark负责任务调度和计算
Kubernetes (experimental)
Kubernetes 提供以容器为中心的基础设施的开源平台
3.Spark运行流程
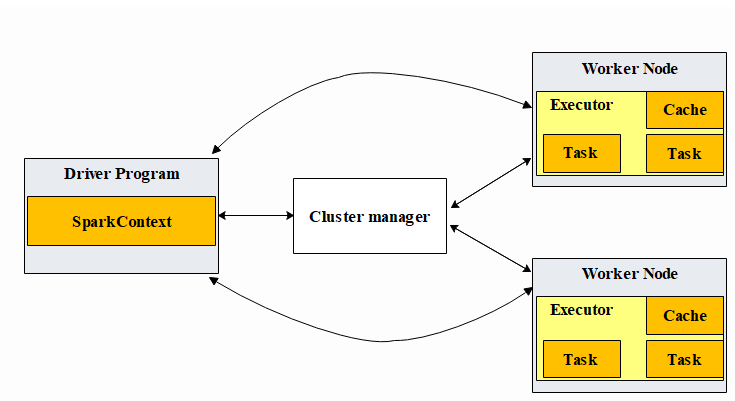
如上图所示,spark的运行流程为:
Spark通过SparkContext向Cluster manager(资源管理器)申请所需执行的资源(cpu、内存等)
Cluster manager分配应用程序执行需要的资源,在Worker节点上创建Executor
SparkContext 将程序代码(jar包或者python文件)和Task任务发送给Executor执行,并收集结果给Driver。
二、Spark安装
主机环境:ubuntu
1.下载文件
进入https://www.apache.org下载spark-2.4.3-bin-hadoop2.7.tgz
下载文件后,放到ubuntu的software文件夹
# 切换到software目录
zifan@ubuntu:~$ cd software/
zifan@ubuntu:~/software$ tar xvf spark-2.4.3-bin-hadoop2.7.tgz
移动spark文件夹到/usr/local/spark目录
# 移动文件夹使用sudo mv指令
zifan@ubuntu:~/software$ sudo mv spark-2.4.3-bin-hadoop2.7 /usr/local/spark
切换到/usr/local/spark目录查看
# 切换到/usr/local/spark目录
zifan@ubuntu:~/software$ cd /usr/local/spark
zifan@ubuntu:/usr/local/spark$ ls
bin data jars LICENSE NOTICE R RELEASE yarn
conf examples kubernetes licenses python README.md sbin
2.配置Spark环境变量
zifan@ubuntu:/usr/local/spark$ sudo vi ~/.bashrc
# 打开文件,最后一行加上
export PATH=$PATH:/usr/local/spark/bin
使配置生效
zifan@ubuntu:/usr/local/spark$ source ~/.bashrc
3.验证Spark安装
在控制台输入spark-shell指令
zifan@ubuntu:/usr/local/spark$ spark-shell
如果出现以下输出结果,则表示spark安装成功。
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
4.退出
使用Ctrl+D或 :quit退出
三、使用Java开发本地Spark应用
1. 操作步骤
以下表述为在ubuntu环境里面操作的记录。
安装maven
https://maven.apache.org,选择合适的版本下载,这里选择的是apache-maven-3.6.1-bin.tar.gz版本
下载文件后,放到ubuntu的software文件夹
# 切换到software目录
zifan@ubuntu:~$ cd software/
zifan@ubuntu:~/software$ tar zxvf apache-maven-3.6.1-bin.tar.gz
移动文件夹到/usr/local/maven目录
# 移动文件夹使用sudo mv指令
zifan@ubuntu:~/software$ sudo mv apache-maven-3.6.1 /usr/local/maven
切换到/usr/local/maven目录查看
# 切换到/usr/local/sbt
zifan@ubuntu:~/software$ cd /usr/local/maven
zifan@ubuntu:/usr/local/maven$ ls
bin boot conf lib LICENSE NOTICE README.txt
配置环境变量
zifan@ubuntu:~/sparkapp2$ sudo vim ~/.bashrc
在文件末尾添加
export M2_HOME=/usr/local/maven
export CLASSPATH=$CLASSPATH:$M2_HOME/lib
export PATH=$PATH:$M2_HOME/bin
保存后退出
使环境变量生效
zifan@ubuntu:~/sparkapp2$ source ~/.bashrc
测试
zifan@ubuntu:~/sparkapp2$ mvn -v
显示内容表示安装成功
Apache Maven 3.6.1 (d66c9c0b3152b2e69ee9bac180bb8fcc8e6af555; 2019-09-05T03:00:29+08:00)
Maven home: /usr/local/maven
Java version: 1.8.0_171, vendor: Oracle Corporation, runtime: /home/zifan/software/jdk1.8.0_171/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "4.4.0-142-generic", arch: "amd64", family: "unix"
编写Java应用程序
1.创建文件夹sparkapp2作为应用程序根目录
# 逐级创建目录
zifan@ubuntu:~$ mkdir -p ./sparkapp2/src/main/java
2.在./sparkapp2/src/main/java目录下创建SparkTest1.java
zifan@ubuntu:~$ vim ./sparkapp2/src/main/java/SparkTest1.java
写入以下内容
/*** SparkTest1.java ***/
import org.apache.spark.api.java.*;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.Function; public class SparkTest1 {
public static void main(String[] args) {
String logFile = "file:///usr/local/spark/README.md"; // 此文件为安装时的说明文件
SparkConf conf=new SparkConf().setAppName("SparkTest1");
JavaSparkContext sc=new JavaSparkContext(conf);
JavaRDD<String> logData = sc.textFile(logFile).cache(); long A1 = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("spark"); }
}).count(); long B1 = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("test"); }
}).count(); System.out.println("Lines with spark: " + A1 + ", lines with test: " + B1);
}
}
该程序依赖Spark Java API,需要通过Maven进行编译打包。
3.在./sparkapp2中新建文件pom.xml
zifan@ubuntu:~$ vim ./sparkapp2/pom.xml
写入内容
<project>
<groupId>com.zifan.example</groupId>
<artifactId>sparktest1-project</artifactId>
<modelVersion>4.0.0</modelVersion>
<name>Spark Project</name>
<packaging>jar</packaging>
<version>1.0</version>
<repositories>
<repository>
<id>maven-ali</id>
<url>http://maven.aliyun.com/nexus/content/groups/public//</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>fail</checksumPolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency> <!-- Spark依赖,注意version为spark版本 -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
</dependencies>
</project>
使用maven打包java程序
1.为了保证maven能够正常运行,先执行如下命令检查整个应用程序的文件结构
zifan@ubuntu:~$ cd sparkapp2
zifan@ubuntu:~/sparkapp2$ find .
# 结果显示
.
./pom.xml
./src
./src/main
./src/main/java
./src/main/java/SparkTest1.java
2.使用mvn打包
# sparkapp2目录下执行
zifan@ubuntu:~/sparkapp2$ mvn package
结果显示
Downloaded from central: https://repo.maven.apache.org/maven2/org/codehaus/plexus/plexus-io/2.0.2/plexus-io-2.0.2.jar (58 kB at 3.6 kB/s)
Downloaded from central: https://repo.maven.apache.org/maven2/org/codehaus/plexus/plexus-archiver/2.1/plexus-archiver-2.1.jar (184 kB at 4.0 kB/s)
[INFO] Building jar: /home/zifan/sparkapp2/target/sparktest1-project-1.0.jar
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 0:45 min
[INFO] Finished at: 2019-09-20T20:26:15+08:00
[INFO] ------------------------------------------------------------------------
至此jar包完成,下面讲述通过spark运行的方式,spark运行jar包通过spark-submit命令进行。
spark-submit的命令格式:
./bin/spark-submit
--class <main-class> //需要运行的程序的主类,应用程序的入口点
--master <master-url> //Master URL,下面会有具体解释
--deploy-mode <deploy-mode> //部署模式
... # other options //其他参数
<application-jar> //应用程序JAR包
[application-arguments] //传递给主类的主方法的参数
deploy-mode这个参数用来指定应用程序的部署模式,部署模式有两种:client和cluster,默认是client。
这两种模式的区别就是是否在本地运行程序,client模式会在本地运行;而cluster模式时,则不会,该模式一般会在Worker节点上运行程序。
Spark的运行模式取决于传递给SparkContext的Master URL的值。Master URL可以选择以下其中一种形式:
1.local 使用一个Worker线程本地化运行SPARK(完全不并行)
2.local[*] 使用逻辑CPU个数数量的线程来本地化运行Spark
3.local[K] 使用K个Worker线程本地化运行Spark
4.spark://HOST:PORT 连接到指定的Spark standalone master,本地独立集群运行,默认端口是7077
5.yarn-client 以客户端模式连接YARN集群。集群的位置可以在HADOOP_CONF_DIR 环境变量中找到
6.yarn-cluster 以集群模式连接YARN集群。集群的位置可以在HADOOP_CONF_DIR 环境变量中找到
7.mesos://HOST:PORT 连接到指定的Mesos集群。默认接口是5050
从上可以看出,本地化运行模式主要有前四种。前三种都是local模式,第四种为standalone模式。因此本地模式大致可以分为local和standalone 两个大类。
2. 本地local模式
- 运行程序
将生成的jar包通过spark-submit提交到Spark中运行,命令如下
# --master local[4]表示采用本地模式,在4个CPU核心上运行spark-shell
zifan@ubuntu:~/sparkapp$ /usr/local/spark/bin/spark-submit --class "SparkTest1" --master local[4] ~/sparkapp2/target/sparktest1-project-1.0.jar
最终显示结果
Lines with spark: 13, lines with test: 8
这个程序是计算一个文本文件中包含”spark"的行数和包含“test”的行数,注意统计是区分大小写的。
运行结果截图如下

3.本地独立集群模式
本地独立集群方式(Spark standalone),这里主要讲下本地独立集群模式的web-ui页面
- 启动Master
zifan@ubuntu:~$ cd /usr/local/spark
zifan@ubuntu:/usr/local/spark$ sbin/start-master.sh
打开http://ubuntu主机IP地址:8080/,界面如下:

- 启动Slave
注意图中的url
zifan@ubuntu:/usr/local/spark$ sbin/start-slave.sh spark://ubuntu:7077
启动成功后,刷新下页面,可以看到Alive Workers已经有值了

将jar包放置于spark中运行
# --master spark://ubuntu:7077表示采用本地独立集群模式运行spark-shell
zifan@ubuntu:~/sparkapp$ /usr/local/spark/bin/spark-submit --class "SparkTest1" --master spark://ubuntu:7077 ~/sparkapp2/target/sparktest1-project-1.0.jar
可以看到在Completed Applications栏多了一条记录,这条记录即为刚执行完的程序。
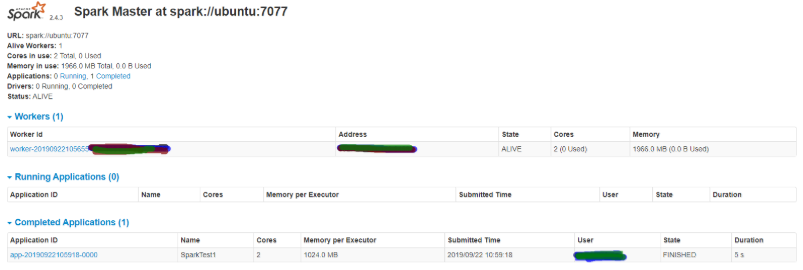
最终显示结果
Lines with spark: 13, lines with test: 8
运行结果截图如下

4.总结
上面的例子应该来说是比较简单的,spark框架优点在于处理大数据时的高效率,特别是对于百万级以上的数据,spark有着惊人的处理效率。
最新Spark入门篇的更多相关文章
- 最新MySQL入门篇
一.SQL简介 SQL:结构化查询语言(Structured Query Language),是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询.更新和管理关系数据库系 ...
- Spark中文指南(入门篇)-Spark编程模型(一)
前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apache Spark简介 Spark的四种运行模式 Spark基于Standlone的运行流程 Spark ...
- 最新版本elasticsearch本地搭建入门篇
最新版本elasticsearch本地搭建入门篇 项目介绍 最近工作用到elasticsearch,主要是用于网站搜索,和应用搜索. 工欲善其事,必先利其器. 自己开始关注elasticsearch, ...
- 转载:Spark中文指南(入门篇)-Spark编程模型(一)
原文:https://www.cnblogs.com/miqi1992/p/5621268.html 前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apac ...
- Spark入门(Python)
Hadoop是对大数据集进行分布式计算的标准工具,这也是为什么当你穿过机场时能看到”大数据(Big Data)”广告的原因.它已经成为大数据的操作系统,提供了包括工具和技巧在内的丰富生态系统,允许使用 ...
- Spark入门(Python版)
Hadoop是对大数据集进行分布式计算的标准工具,这也是为什么当你穿过机场时能看到”大数据(Big Data)”广告的原因.它已经成为大数据的操作系统,提供了包括工具和技巧在内的丰富生态系统,允许使用 ...
- spring boot(一):入门篇
构建微服务:Spring boot 入门篇 什么是spring boot Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框 ...
- 【three.js详解之一】入门篇
[three.js详解之一]入门篇 开场白 webGL可以让我们在canvas上实现3D效果.而three.js是一款webGL框架,由于其易用性被广泛应用.如果你要学习webGL,抛弃那些复杂的 ...
- Spark入门实战系列--3.Spark编程模型(下)--IDEA搭建及实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 . 安装IntelliJ IDEA IDEA 全称 IntelliJ IDEA,是java语 ...
随机推荐
- 线程安全与synchronized
线程安全性与synchronized 线程安全:多线程访问某个类时,这个类始终都能表现出正确的行为,这个类就是线程安全的. 简单的说,就是多线程执行的结果与单线程执行的结果始终一致,不会因为多线程的执 ...
- 利用 Powershell 编写简单的浏览器脚本
生活中有很多事情是低效益,重复性.比如每天上某些网站,先登录再签到打卡,比如每隔一段时间清理回收站的文件等等.一个成熟的软件工程师应该想到用软件解决他. 对于这些简单的小任务,一般用脚本实现.比如Py ...
- 小球(总结sort和cmp函数、结构体排序)
问题 N: 小球(点击) 时间限制: 1 Sec 内存限制: 128 MB ...
- SQL Beautifier & SQL2014自带的格式化工具
格式化工具(希望有几款集成在IDE中的格式化工具)为什么要说明这些,不是为说明这个工具而发,看到那几千行或集成在一起的存储过程觉得乱七八的不爽,后面将会强力训练下自己. --下面这款SQL Beaut ...
- AutoIt实现文件上传
AutoIt目前最新是v3版本,这是一个使用类似BASIC脚本语言的免费软件,它设计用于Windows GUI(图形用户界面)中进行自动化操作.它利用模拟键盘按键,鼠标移动和窗口/控件的组合来实现自动 ...
- elasticsearch unassigned shards 导致RED解决
先通过命令查看节点的shard分配整体情况 curl -X GET "ip:9200/_cat/allocation?v" 说明:有16个索引未分片 2.查看未分片的索引 curl ...
- Spring:BeanDefinition&PostProcessor不了解一下吗?
水稻:这两天看了BeanDefinition和BeanFactoryPostProcessor还有BeanPostProcessor的源码.要不要了解一下 菜瓜:six six six,大佬请讲 水稻 ...
- Oracle SQL调优系列之SQL Monitor Report
@ 目录 1.SQL Monitor简介 2.捕捉sql的前提 3.SQL Monitor 参数设置 4.SQL Monitor Report 4.1.SQL_ID获取 4.2.Text文本格式 4. ...
- Scanner扫描器的使用
Scanner:扫描器,可以通过Scanner类扫描用户在控制台录入的数据. 1.导包 //导包快捷键Alt+Enter 2.创建键盘录入对象 //键盘录入对象的名称为 “sc” 3.接收数据 //将 ...
- Linux 之Mycat搭建报错 java.net.MalformedURLException: Local host name unknown: java.net.UnknownHostException
搭建MyCat环境时出现 错误: 代理抛出异常错误: java.net.MalformedURLException: Local host name unknown: java.net.Unknown ...