利用Postman和Chrome的开发者功能探究项目
利用Postman和Chrome的开发者功能探究项目
controller层研究
前两天忙着写开题报告,没有来得及做项目,今天继续研究一下这个项目。
上次研究到后端的DAO层,研究了一下后端和数据库交互的过程,service层封装了一些DAO层的函数,没有什么太多的东西,今天研究一下controller层和前端的代码。
首先,一个典型的controller层代码是这样的:
package... import ...
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*; import java.util.List; @RestController
public class LibraryController {
@Autowired
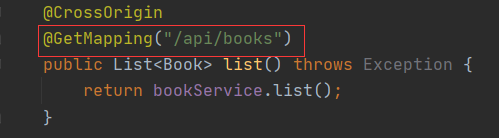
BookService bookService; @CrossOrigin
@GetMapping("/api/books")
public List<Book> list() throws Exception {
return bookService.list();
} ...
}
按照惯例,首先看一下各个注解:
@RestController:相当于@ResponseBody+@Controller注解
@ResponseBody:@ResponseBody的作用其实是将java对象转为json格式的数据。将controller的方法返回的对象通过适当的转换器转换为指定的格式之后,写入到response对象的body区。
@Controller:用于标记在一个类上,使用它标记的类就是一个SpringMVC Controller对象。分发处理器将会扫描使用了该注解的类的方法,并检测该方法是否使用了@RequestMapping注解。@Controller只是定义了一个控制器类,而使用@RequestMapping注解的方法才是真正处理请求的处理器。
@Autowired:自动装配,和控制反转什么的有关系,这个这里不展开了。
@CrossOrigin:跨域,这个问题大概就是说前后端不用一个服务器,浏览器对这种行为会出于安全考虑不允许跨域访问,所以需要设置一下,具体细节比较琐碎,这里不展开了。
@GetMapping:SpringMVC以前版本的@RequestMapping,到了新版本被下面新注释替代,相当于增加的选项:@GetMapping、@PostMapping、@PutMapping、@DeleteMapping、@PatchMapping,从命名约定我们可以看到每个注释都是为了处理各自的传入请求方法类型,即@GetMapping用于处理请求方法的GET类型,@PostMapping用于处理请求方法的POST类型等。如果我们想使用传统的@RequestMapping注释实现URL处理程序,那么它应该是这样的:@RequestMapping(value = "/get/{id}", method = RequestMethod.GET),新方法可以简化为:@GetMapping("/get/{id}")。
后面的函数中还有一些其他的注解,一起看一下:
@CrossOrigin
@PostMapping("/api/books")
public Book addOrUpdate(@RequestBody Book book) throws Exception {
bookService.addOrUpdate(book);
return book;
} @CrossOrigin
@PostMapping("/api/delete")
public void delete(@RequestBody Book book) throws Exception {
bookService.deleteById(book.getId());
} @CrossOrigin
@GetMapping("/api/categories/{cid}/books")
public List<Book> listByCategory(@PathVariable("cid") int cid) throws Exception {
if (0 != cid) {
return bookService.listByCategory(cid);
} else {
return list();
}
} @CrossOrigin
@GetMapping("/api/search")
public List<Book> searchResult(@RequestParam("keywords") String keywords) {
// 关键词为空时查询出所有书籍
if ("".equals(keywords)) {
return bookService.list();
} else {
return bookService.Search(keywords);
}
}
@RequestBody:@RequestBody主要用来接收前端传递给后端的json字符串中的数据的(请求体中的数据的);GET方式无请求体,所以使用@RequestBody接收数据时,前端不能使用GET方式提交数据,而是用POST方式进行提交。
@PathVariable是spring3.0的一个新功能:接收请求路径中占位符的值
@RequestParam:@RequestParam有三个配置参数:required表示是否必须,默认为true,必须。defaultValue可设置请求参数的默认值。value为接收url的参数名(相当于key值。这个好像用法比较复杂,之后再仔细看一下。
Postman和chrome测试
首先我们登录进入系统,我这里前后端交互使用的8443端口,后续测试也在8443端口上进行。
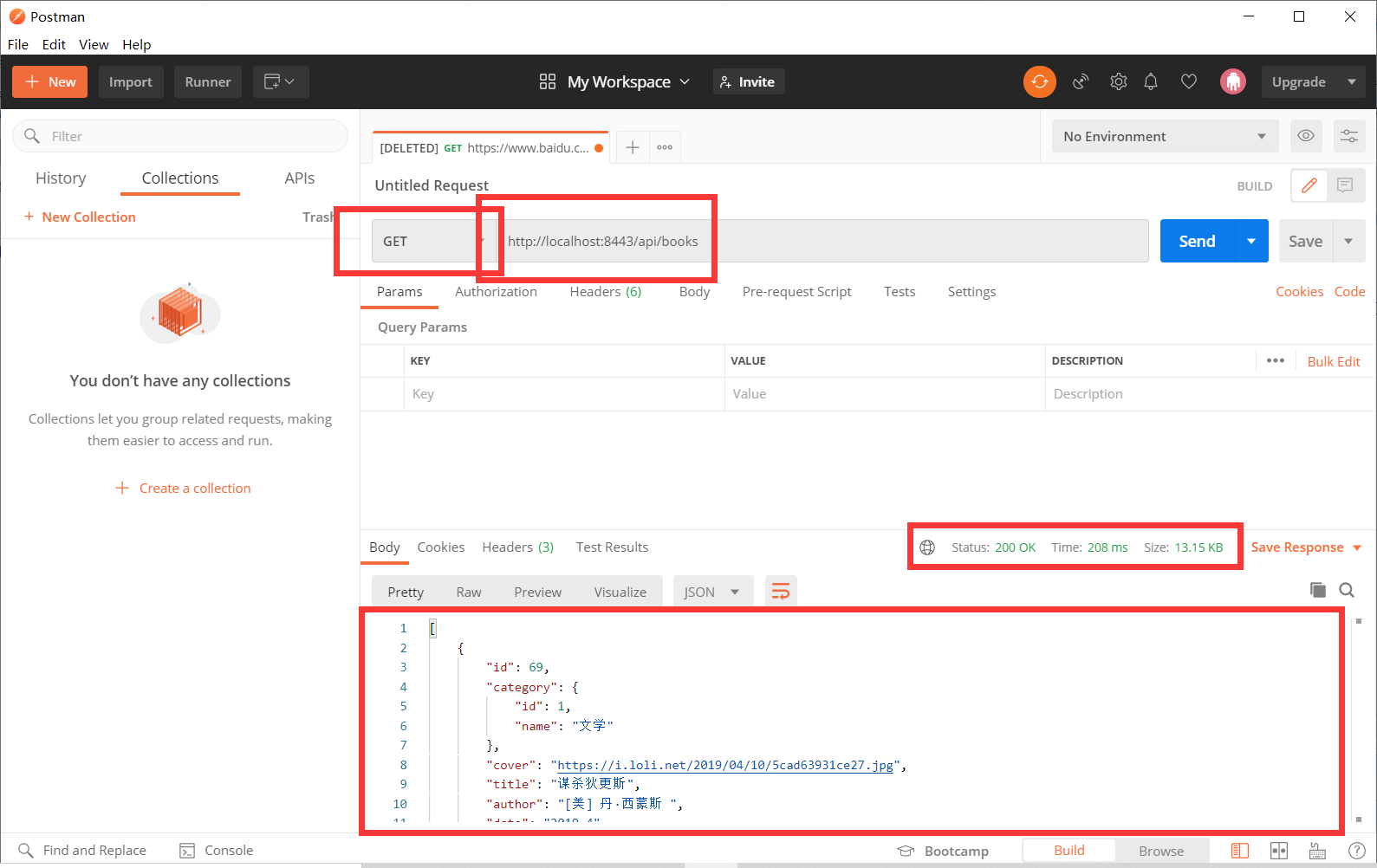
可以看到发送了一个请求报文,收到了一个回复报文,回复报文的内容是一些json键值对,下面放了一个样例:
{
"id": 69,
"category": {
"id": 1,
"name": "文学"
},
"cover": "https://i.loli.net/2019/04/10/5cad63931ce27.jpg",
"title": "谋杀狄更斯",
"author": "[美] 丹·西蒙斯 ",
"date": "2019-4",
"press": "上海文艺出版社",
"abs": "“狄更斯的那场意外灾难发生在1865年6月9日,那列搭载他的成功、平静、理智、手稿与情妇的火车一路飞驰,迎向铁道上的裂隙,突然触目惊心地坠落了。”"
}
与Pojo中的book和category完全对应,这里放一下代码。
public class Book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
int id;
//把 category 对象的 id 属性作为 cid 进行了查询
@ManyToOne
@JoinColumn(name="cid")
private Category category;
String cover;
String title;
String author;
String date;
String press;
String abs;
...
}
public class Category {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
int id;
String name;
...
}
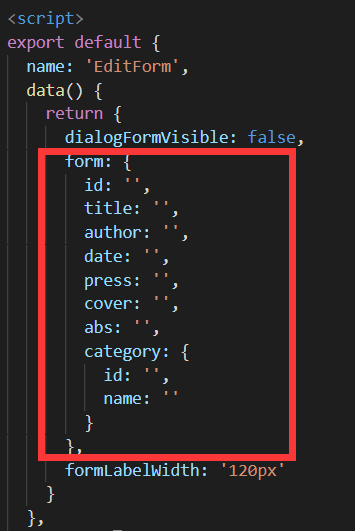
前端的EditForm.vue中有这么一段代码显然是和这个相对应的,这里我们先不去管这个:
我们接着测试一下其他方法:

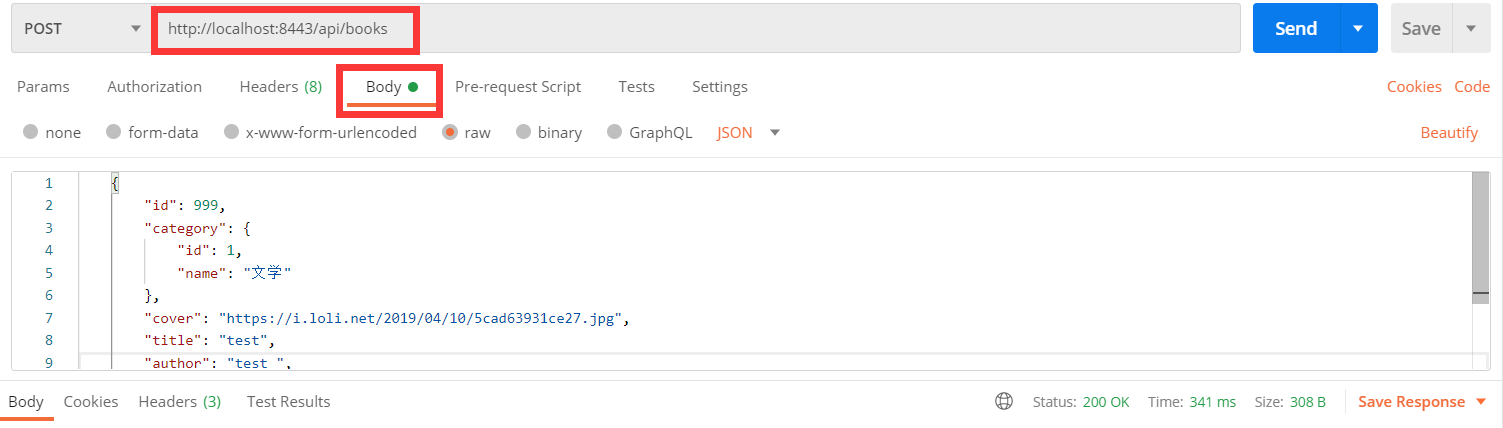
构造了一个post报文,返回200表示成功了,有趣的是虽然传入了id,但是由于id是自增的,并没有起作用,再使用get方法查询一下。
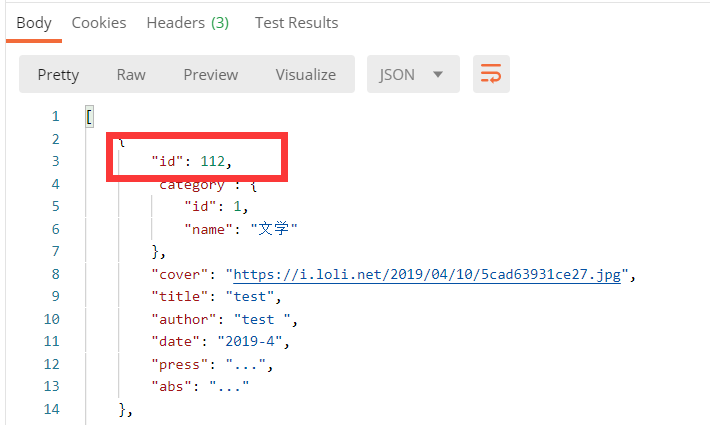
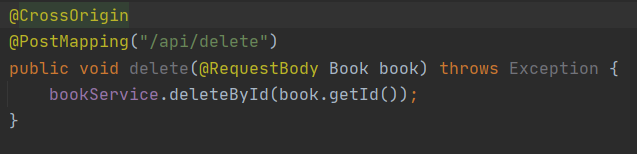
下一个方法表示要删除一本书,我们从代码这个大概知道是拿到一个json对象,转换成javabean的book,然后根据id把书删除了,我们应该传入一个json对象的书,试一下:
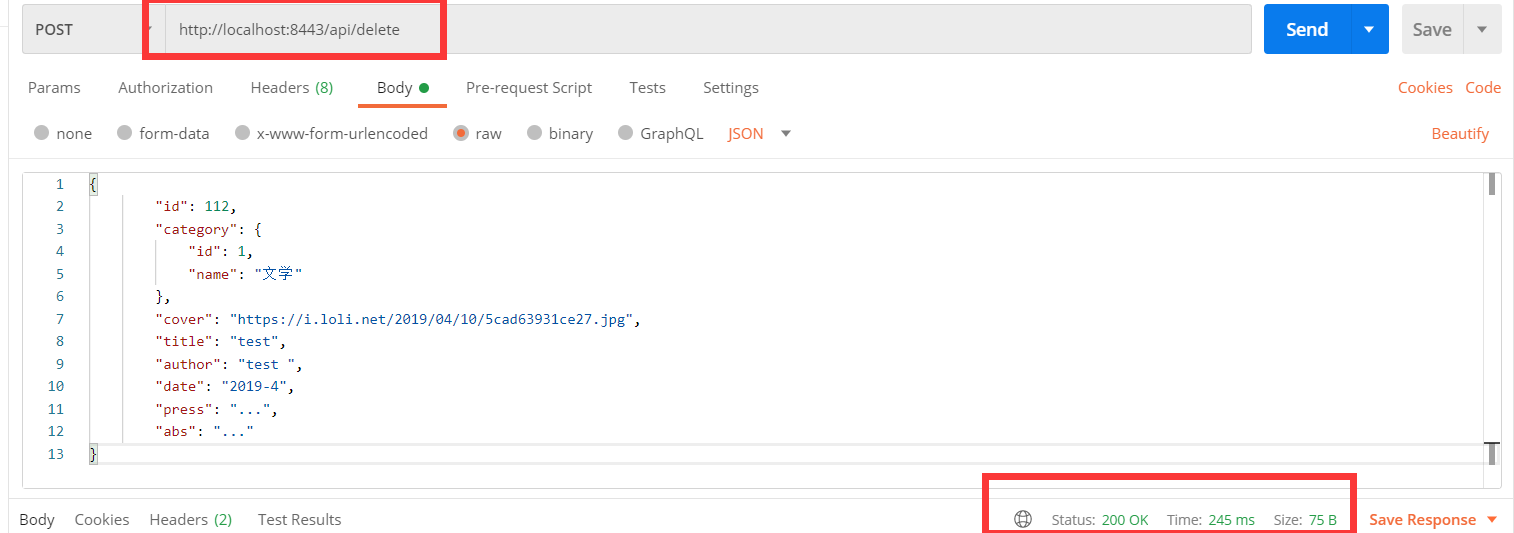
成功了,但是有趣的是在chrome浏览器中,对于前端的行为不完全是这样:
根据网上的教程,F12打开后,在Network下勾选Preserve log就可以监控报文。
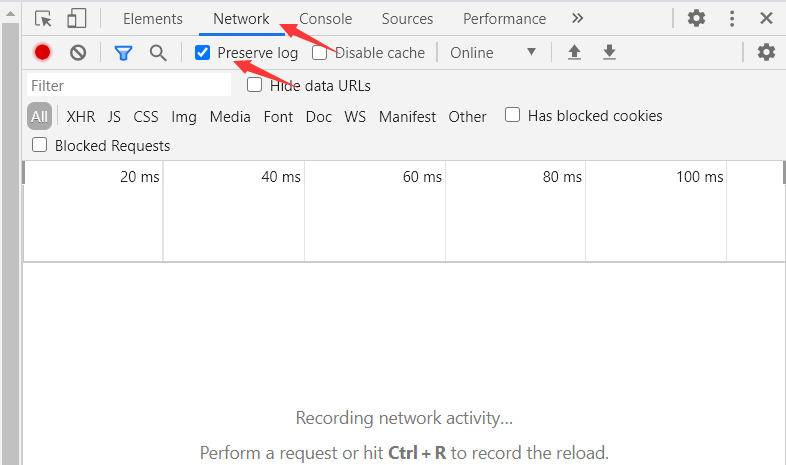
我们打开后删除一本书。
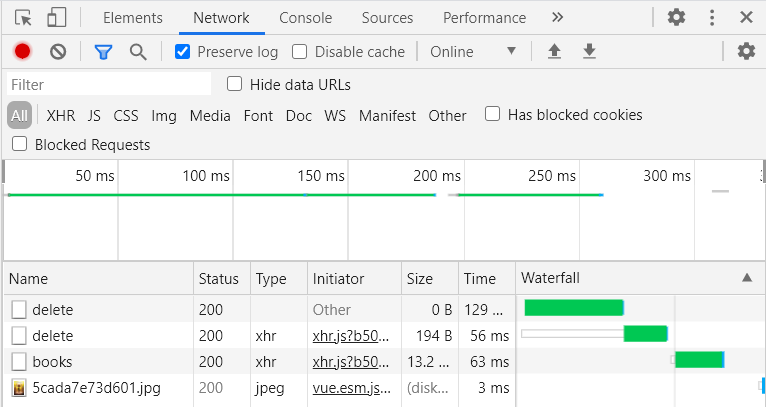
双击点开后发现Request只传递了id,因为原来函数里只需要id,所以只传id是完全没毛病的,这个我在postman里面测过了,就不发上来了:



这个就是拿一个从url路径里面拿一个参数,测试了一下不存在的分类号,不会报错,而是给一个空集合。

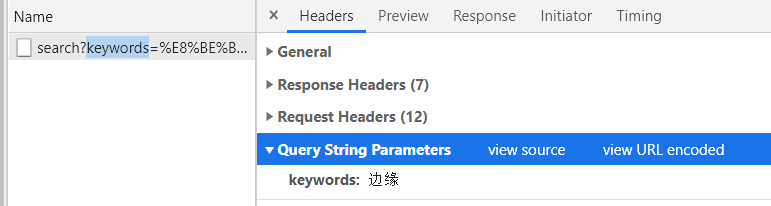
这个没太看懂参数是怎么传递的,我们用Chrome看一下。
是通过在路径后面加上“?keyword=关键词”实现的。
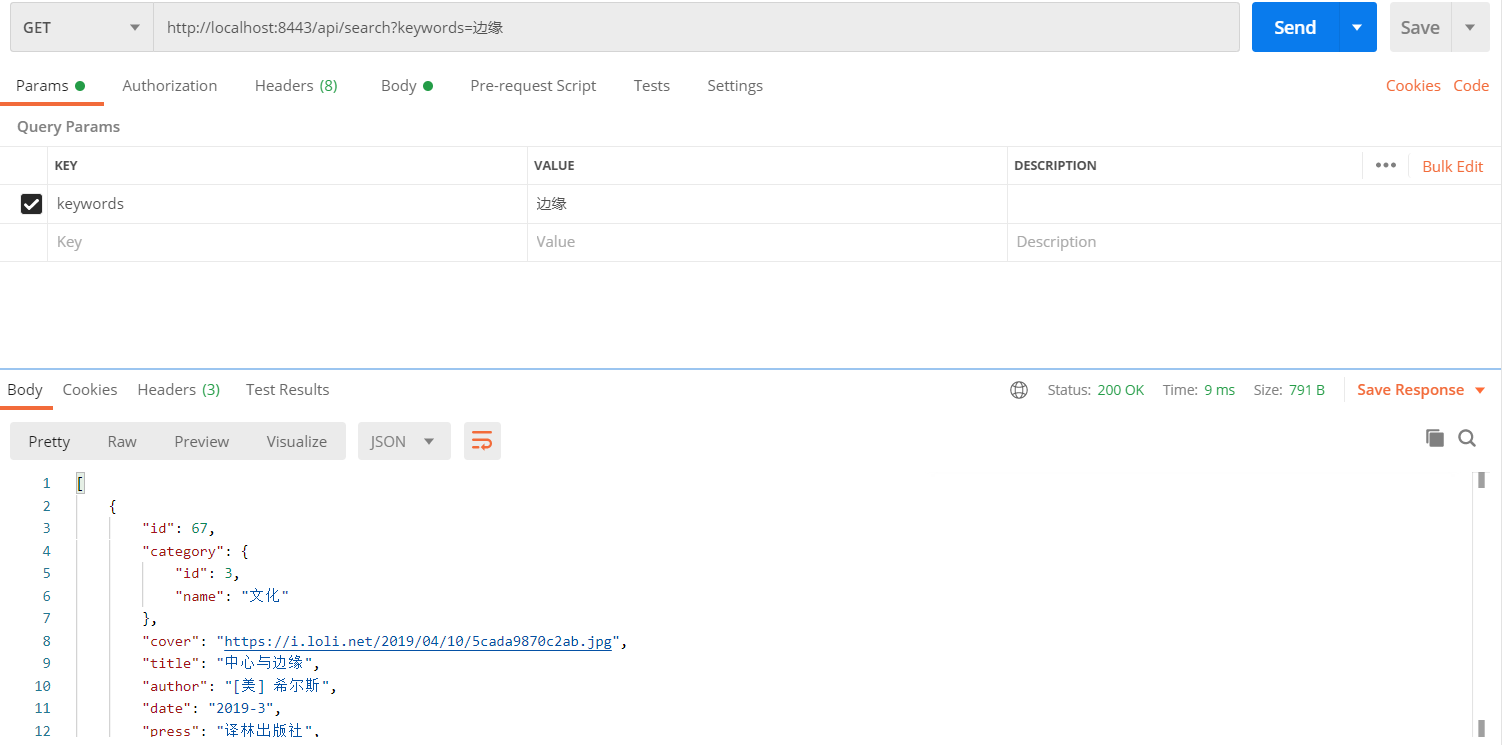
去postman里面试一下,成功!
今天的探索到这里就结束了,后面再看一下前端代码的逻辑,这个交互过程就比较清楚了。
利用Postman和Chrome的开发者功能探究项目的更多相关文章
- 谷歌Chrome浏览器开发者工具的基础功能
上一篇我们学习了谷歌Chrome浏览器开发者工具的基础功能,下面介绍的是Chrome开发工具中最有用的面板Sources.Sources面板几乎是最常用到的Chrome功能面板,也是解决一般问题的主要 ...
- [转]谷歌Chrome浏览器开发者工具教程—基础功能篇
来源:http://www.xiazaiba.com/jiaocheng/5557.html Chrome(F12开发者工具)是非常实用的开发辅助工具,对于前端开发者简直就是神器,但苦于开发者工具是英 ...
- [转]谷歌Chrome浏览器开发者工具教程—JS调试篇
来源:http://blog.csdn.net/cyyax/article/details/51242720 上一篇我们学习了谷歌Chrome浏览器开发者工具的基础功能,下面介绍的是Chrome开发工 ...
- 利用postman进行接口测试并发送带cookie请求的方法
做web测试的基本上都用用到postman去做一些接口测试,比如测试接口的访问权限,对于某些接口用户A可以访问,用户B不能访问:比如有时需要读取文件的数据.在postman上要实现这样测试,我们就必要 ...
- 【技术博客】 利用Postman和Jmeter进行接口性能测试
利用Postman和Jmeter进行接口性能测试 作者:ZBW 版本:v1.1 在Phylab的开发过程中,对于生成报告接口的性能考量十分重要.原有的Latex接口虽然生成的报告美观,但编译Latex ...
- Chrome - 使用 开发者工具 对页面截图
概述 使用 开发者工具 对页面截图 背景 经常需要截图 常用的截图模式有这些 窗口截图 区域截图 gif 问题 Chrome 如何截长图 firefox 好像有插件 1. 解决: 使用 Chrome ...
- 通过使用Chrome的开发者工具来学习JavaScript
本文作者是Peter Rybin,Chrome开发者工具团队成员. 本文中,我们将通过使用Chrome的开发者工具,来学习JavaScript中的两个重要概念”闭包”和”内部属性”. 闭包 首先要讲的 ...
- html5利用websocket完成的推送功能(tomcat)
html5利用websocket完成的推送功能(tomcat) 利用websocket和java完成的消息推送功能,服务器用的是tomcat7.0.42,一些东西是自己琢磨的,也不知道恰不恰当,不恰当 ...
- 爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,loads,dump,load方法介绍
爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,load ...
随机推荐
- DTU是怎么与PLC连接通信的
数据采集是生产制造中最实际最频繁的需求,不管智能设备制造发展到何种程度它都是工业4.0的先决条件,也在数字化工厂当中,工人更多地是处理异常情况,调整设备.但数据采集一直是困扰着所有制造工厂的传统痛点, ...
- 机器学习 第4篇:sklearn 最邻近算法概述
sklearn.neighbors 提供了针对无监督和受监督的基于邻居的学习方法的功能.监督的基于最邻近的机器学习算法是值:对带标签的数据的分类和对连续数据的预测(回归). 无监督的最近算法是许多其他 ...
- kubernetes 基础知识
1. kubernetes 包含几个组件 Kubernetes是什么:针对容器编排的一种分布式架构,是自动化容器操作的开源平台. 服务发现.内建负载均衡.强大的故障发现和自我修复机制.服务滚动升级和在 ...
- error: Microsoft Visual C++ 14.0 or greater is required. Get it with “Microsoft C++ Build Tools“
python3 是用 VC++ 14 编译的, python27 是 VC++ 9 编译的, 安装 python3 的包需要编译的也是要 VC++ 14 以上支持的. 可以下载安装这个: 链接:htt ...
- 妙用 Intellij IDEA 创建临时文件,Git 跟踪不到的那种
| 好看请赞,养成习惯 你有一个思想,我有一个思想,我们交换后,一个人就有两个思想 If you can NOT explain it simply, you do NOT understand it ...
- Git--gitLab远程仓库分支代码回退的两种方案
事由:作为仓库的master,一时老眼昏花,把同事说的不合并看成了合并,直接合并了. 解决方法: 一.粗鲁的代码回退--直接在远程仓库合并 1. 在gitLab远程仓库中,基于想回退的代码的节点(co ...
- learning to Estimate 3D Hand Pose from Single RGB Images论文理解
持续更新...... 概括:以往很多论文借助深度信息将2D上升到3D,这篇论文则是想要用网络训练代替深度数据(设备成本比较高),提高他的泛性,诠释了只要合成数据集足够大和网络足够强,我就可以不用深度信 ...
- Inception系列之Inception_v1
目前,神经网络模型为了得到更好的效果,越来越深和越来越宽的模型被提出.然而这样会带来以下几个问题: 1)参数量,计算量越来越大,在有限内存和算力的设备上,其应用也就越难以落地. 2)对于一些数据集较少 ...
- 5.MVCC
5 MVCC 全称是Multi-Version Concurrent Control,即多版本并发控制,在MVCC协议下,每个读操作会看到一个一致性的snapshot,并且可以实现非阻塞的读.MV ...
- python3批量修改文件后缀名
import os # 原文件后缀名 suffix_name = '.jar.src.zip' # 新文件后缀名 nwe_suffix_name = '.jar' def foo(path1): fi ...