Spring Cloud Hystrix应用篇(十一)
一、背景
分布式系统环境下,服务间类似依赖非常常见,一个业务调用通常依赖多个基础服务。如下图,对于同步调用,当库存服务不可用时,商品服务请求线程被阻塞,当有大批量请求调用库存服务时,最终可能导致整个商品服务资源耗尽,无法继续对外提供服务。并且这种不可用可能沿请求调用链向上传递,这种现象被称为雪崩效应。
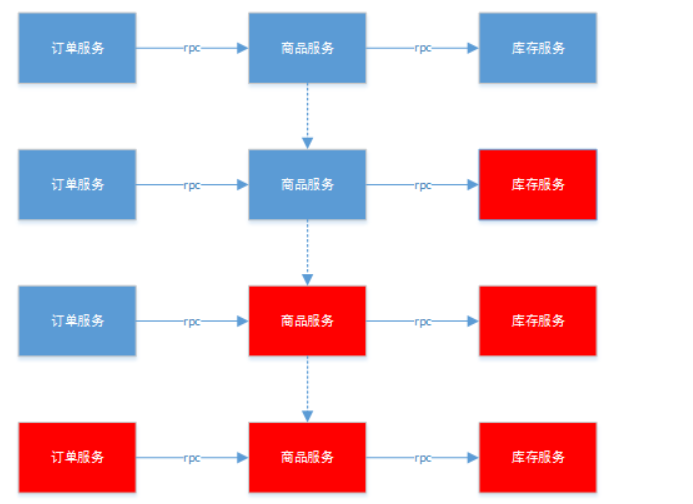
二、雪崩效应常见场景
- 硬件故障:如服务器宕机,机房断电,光纤被挖断等。
- 流量激增:如异常流量,重试加大流量等。
- 缓存穿透:一般发生在应用重启,所有缓存失效时,以及短时间内大量缓存失效时。大量的缓存不命中,使请求直击后端服务,造成服务提供者超负荷运行,引起服务不可用。
- 程序BUG:如程序逻辑导致内存泄漏,JVM长时间FullGC等。
- 同步等待:服务间采用同步调用模式,同步等待造成的资源耗尽。
三、雪崩效应应对策略
针对造成雪崩效应的不同场景,可以使用不同的应对策略,没有一种通用所有场景的策略,参考如下:
- 硬件故障:多机房容灾、异地多活等。
- 流量激增:服务自动扩容、流量控制(限流、关闭重试)等。
- 缓存穿透:缓存预加载、缓存异步加载等。
- 程序BUG:修改程序bug、及时释放资源等。
- 同步等待:资源隔离、MQ解耦、不可用服务调用快速失败等。资源隔离通常指不同服务调用采用不同的线程池;不可用服务调用快速失败一般通过熔断器模式结合超时机制实现。
综上所述,如果一个应用不能对来自依赖的故障进行隔离,那该应用本身就处在被拖垮的风险中。 因此,为了构建稳定、可靠的分布式系统,我们的服务应当具有自我保护能力,当依赖服务不可用时,当前服务启动自我保护功能,从而避免发生雪崩效应。本文将重点介绍使用Hystrix解决同步等待的雪崩问题。
四、什么是Hystrix
在分布式环境中,许多服务依赖项中的一些必然会失败。Hystrix是一个库,通过添加延迟容忍和容错逻辑,帮助你控制这些分布式服务之间的交互。Hystrix通过隔离服务之间的访问点、停止级联失败和提供回退选项来实现这一点,所有这些都可以提高系统的整体弹性。
Hystrix设计目标:
- 对来自依赖的延迟和故障进行防护和控制——这些依赖通常都是通过网络访问的
- 阻止故障的连锁反应
- 快速失败并迅速恢复
- 回退并优雅降级
- 提供近实时的监控与告警
Hystrix遵循的设计原则:
- 防止任何单独的依赖耗尽资源(线程)
- 过载立即切断并快速失败,防止排队
- 尽可能提供回退以保护用户免受故障
- 使用隔离技术(例如隔板,泳道和断路器模式)来限制任何一个依赖的影响
- 通过近实时的指标,监控和告警,确保故障被及时发现
- 通过动态修改配置属性,确保故障及时恢复
- 防止整个依赖客户端执行失败,而不仅仅是网络通信
Hystrix如何实现这些设计目标?
- 使用命令模式将所有对外部服务(或依赖关系)的调用包装在HystrixCommand或HystrixObservableCommand对象中,并将该对象放在单独的线程中执行;
- 每个依赖都维护着一个线程池(或信号量),线程池被耗尽则拒绝请求(而不是让请求排队)。
- 记录请求成功,失败,超时和线程拒绝。
- 服务错误百分比超过了阈值,熔断器开关自动打开,一段时间内停止对该服务的所有请求。
- 请求失败,被拒绝,超时或熔断时执行降级逻辑。
- 近实时地监控指标和配置的修改。
五、应用实战
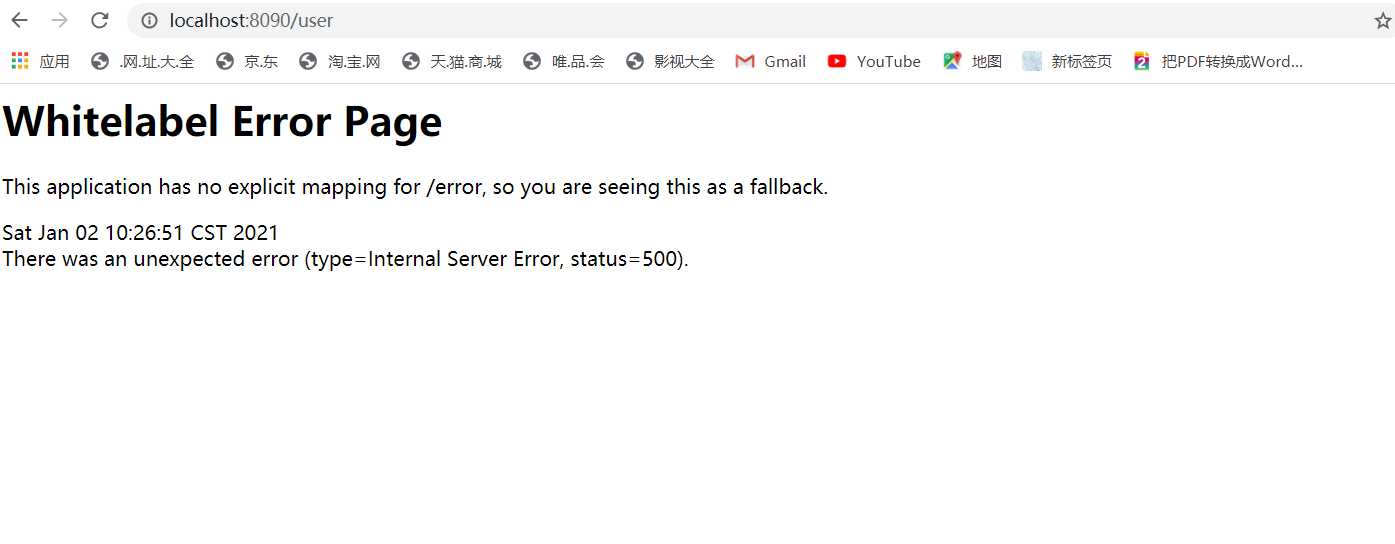
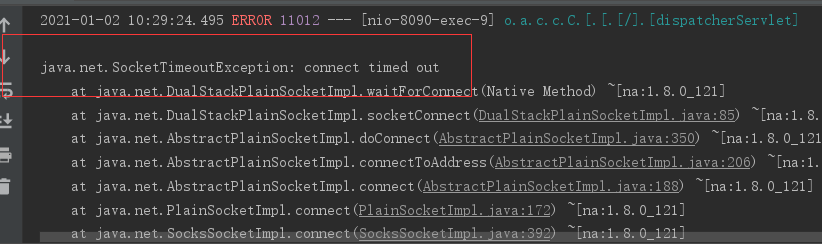
项目还是用以前的项目,之前在spring-cloud-user写了一个UserController,在里面调用了spring-cloud-service服务,下面把除了spring-cloud-service外的其它服务都开启,然后访问接口会发现报错,看控制台,控制台报的是连接异常,这就是一个典型的通信失败的案例,在生产过程中如果访问报一个这个页面总是不那么友好的,那么怎么解决这个通信失败呢。
为了解决这个问题就引入了hystrix,在服务调用端加入Hystrix包,因为我后面每个应用都会加入spring-cloud-api这个工程,为了减少后面应用重复导包,我将此包放入spring-cloud-api工程,并且要在调用端加入@EnableCircuitBreaker注解
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
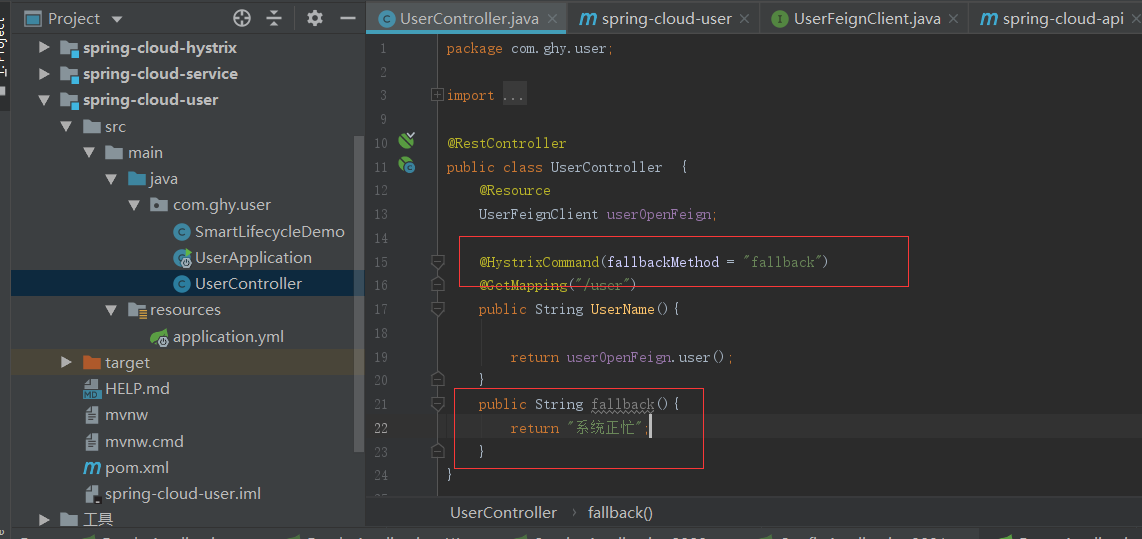
然后就可以对服务进行降级和熔断机制了,在UserController类方法中加入@HystrixCommand(fallbackMethod = "fallback")
然后再访问浏览器,发现没啥用,
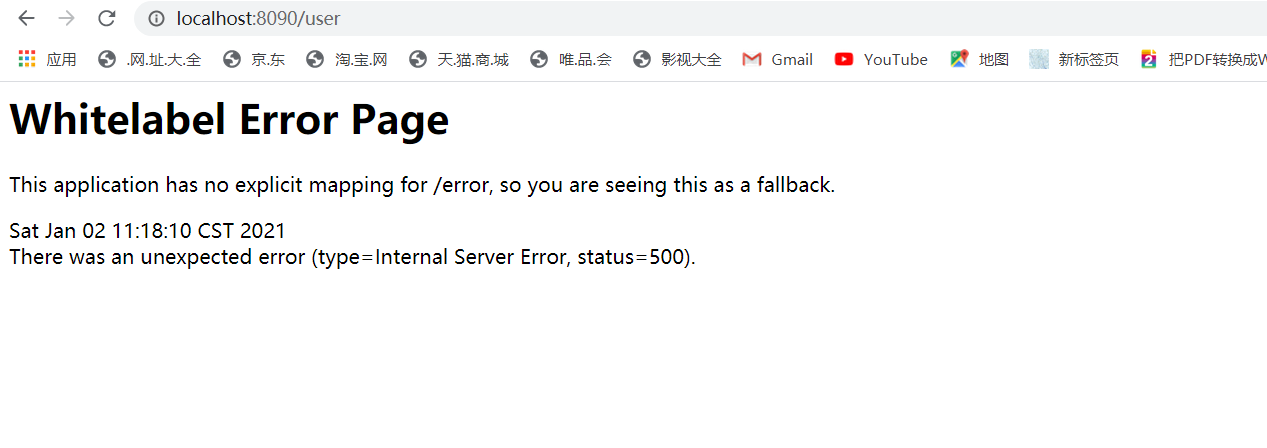
这正好引出今天问题,怎么触发降级,刚刚配置的方法其实是回退,降级有三种方案:
5.1、熔断触发降级
熔断的配置信息可以在HystrixCommandProperties类中找到,这里我只写3个

然后再次发起访问,发现发生了熔断
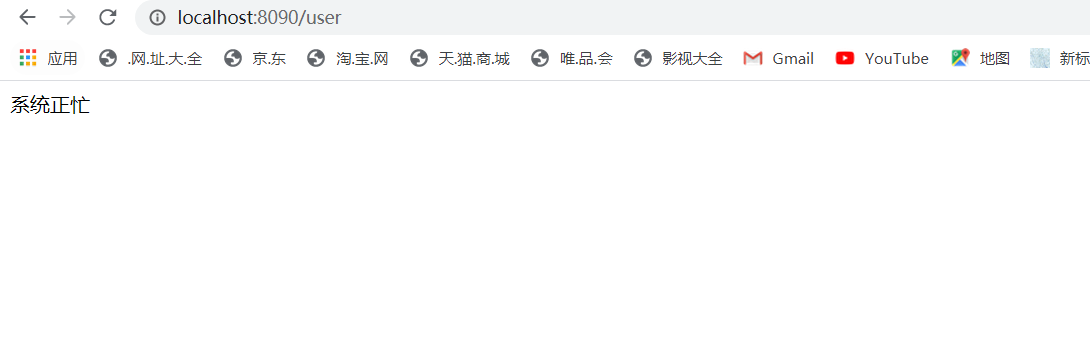
这里有个问题,我这里不演示了,那就是熔断开启之后,后续的正常请求也无法发送过去;说完了这个下面就看下,熔断是如何触发的的,又是怎么恢复的;
1.如何触发熔断?"判断阈值"
10s钟之内,发起了20次请求,失败率超过50%。 熔断的恢复时间(熔断5s)也就是说熔断触发了后,后续请求在5S内都不会发生到服务端 ,这就是熔断的时间窗口说明.
2.熔断会有一个自动恢复。
自支恢复的概念是,5S后请求会自动试着发送到服务端,如果发现发送通信正常了,熔断就会成为关闭状态
5.2、请求超时触发降级
在继续写时要说明一个情况那就是熔断后超时是两个概念,希望不要搞混了,超时是请求发送中只是时间超了阈值

5.3、资源隔离触发降级
隔离分为平台隔离、部署隔离、业务隔离、 服务隔离、资源隔离;比喻说项目中的一个case,有一块东西,是要用多线程做一些事情,小伙伴做项目的时候,没有太留神,资源隔离,那块代码,在遇到一些故障的情况下,每个线程在跑的时候,因为那个bug,直接就死循环了,导致那块东西启动了大量的线程,每个线程都死循环最终导致系统资源耗尽,崩溃,不工作,不可用,废掉了;在系统中值得我们隔离的资源无非就几种:CPU、内存、线程
信号量隔离:
/**
* 信号量隔离实现
* 不会使用Hystrix管理的线程池处理请求。使用容器(Tomcat)的线程处理请求逻辑。
* 不涉及线程切换,资源调度,上下文的转换等,相对效率高。
* 信号量隔离也会启动熔断机制。如果请求并发数超标,则触发熔断,返回fallback数据。
* commandProperties - 命令配置,HystrixPropertiesManager中的常量或字符串来配置。
* execution.isolation.strategy - 隔离的种类,可选值只有THREAD(线程池隔离)和
SEMAPHORE(信号量隔离)。
* 默认是THREAD线程池隔离。
* 设置信号量隔离后,线程池相关配置失效。
* execution.isolation.semaphore.maxConcurrentRequests - 信号量最大并发数。默认
值是10。常见配置500~1000。
* 如果并发请求超过配置,其他请求进入fallback逻辑。
*/
@HystrixCommand(fallbackMethod="semaphoreQuarantineFallback",
commandProperties={
@HystrixProperty(
name=HystrixPropertiesManager.EXECUTION_ISOLATION_STRATEGY,
value="SEMAPHORE"), // 信号量隔离
@HystrixProperty(
name=HystrixPropertiesManager.EXECUTION_ISOLATION_SEMAPHORE_MAX_CONCURRENT_REQU
ESTS,
value="100") // 信号量最大并发数
线程池隔离
@HystrixCommand(groupKey="spring-cloud-service",
commandKey = "orders",
threadPoolKey="spring-cloud-service",
threadPoolProperties = {
@HystrixProperty(name = "coreSize", value = "30"),//线程池大小
@HystrixProperty(name = "maxQueueSize", value = "100"),//最大队列长度
@HystrixProperty(name = "keepAliveTimeMinutes", value ="2"),//线程存活时间
@HystrixProperty(name = "queueSizeRejectionThreshold", value= "15")//拒绝请求
},
fallbackMethod = "fallback")
六、OpenFeign的降级策略
前面讲了hystrilx的降级方法,也在之前的篇幅中讲了OpenFeign的应用,下面就以hystrix为基础来讲下在OpenFeign中是怎么做到降级的进行对比一下,记得用OpenFeign要开启降级和之前篇幅一样要导入包还有在启动类上加上
@EnableFeignClients(basePackages = "com.ghy.*")注解,另外还要在调用者的配置文件中加入下面的开启配置
#开启feign的支持,触发降级的策略
feign:
hystrix:
enabled: true
这些搞定后,那就写降级策略了
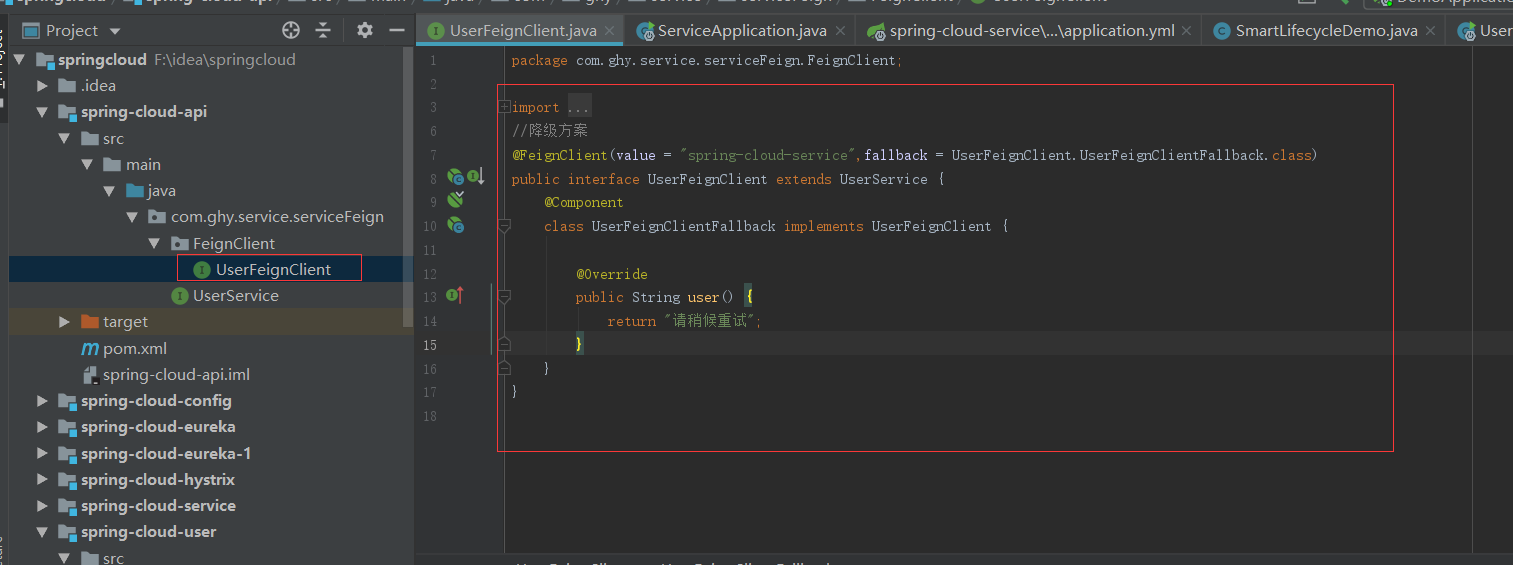
访问浏览器
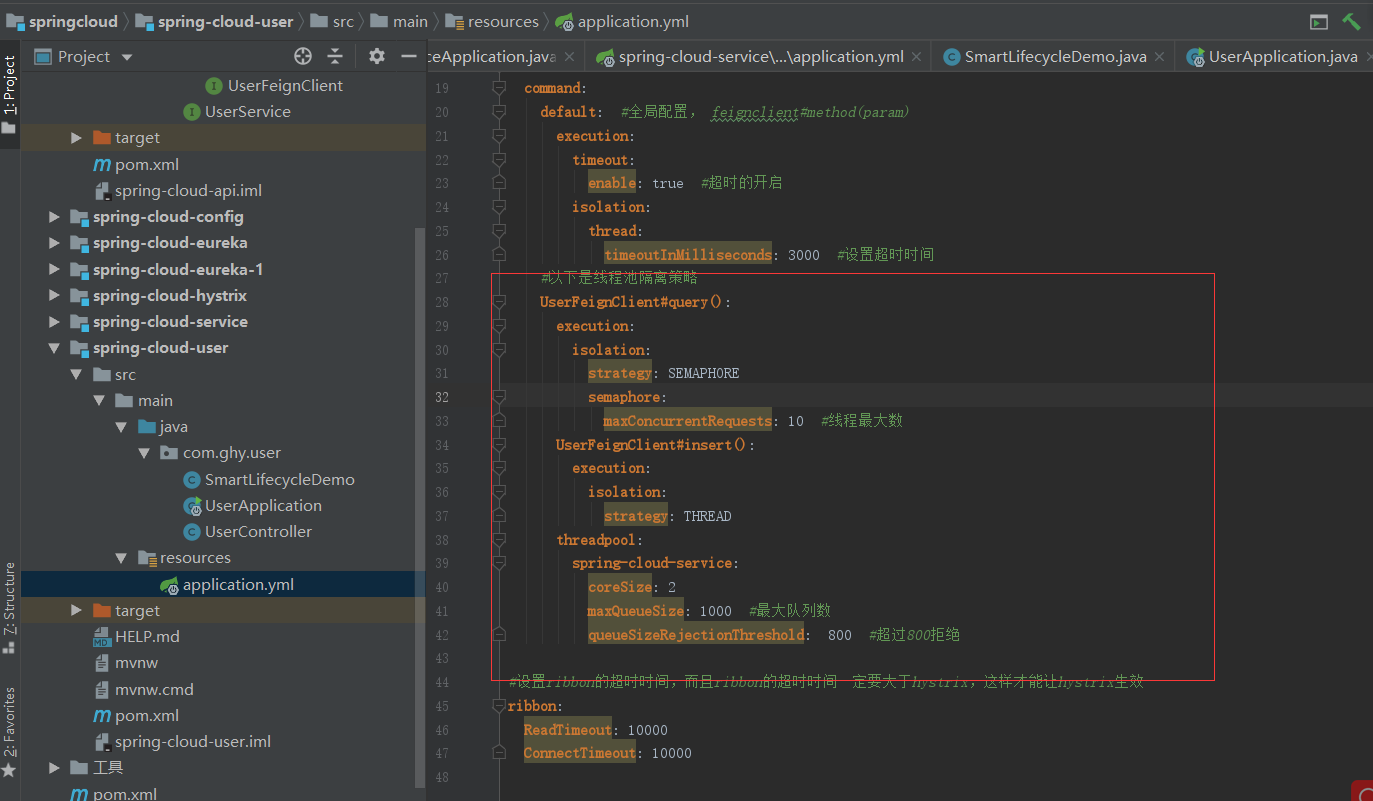
如果想在OpenFeign和hystrix一样配置很多信息的话是没办法用注解配置的,只能在配置文件中配置,下面配置下超时的时间配置,在调用端的配置文件中配置
#开启feign的支持,触发降级的策略
feign:
hystrix:
enabled: true
hystrix:
command:
default: #全局配置, feignclient#method(param)
execution:
timeout:
enable: true #超时的开启
isolation:
thread:
timeoutInMilliseconds: 3000 #设置超时时间 #设置ribbon的超时时间,而且ribbon的超时时间一定要大于hystrix,这样才能让hystrix生效
ribbon:
ReadTimeout: 10000
ConnectTimeout: 10000
下面看下线程池隔离的配置

然后创建一个spring-cloud-hystrix项目进行监控,在spring-cloud-hystrix导入以下包,然后spring-cloud-hystrix的启动类上加上@EnableHystrixDashboard注解
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
配置文件如下
server:
port: 9095 eureka:
instance:
hostname: localhost
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/,http://localhost:8762/eureka/ #指向服务注册中心的地址
访问浏览器登录到了登录面板,被监测的服务一定要有下面的包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
并且被监控的对象要配置如下配置以不断获取监控信息
management:
endpoints:
web:
exposure:
include: refresh,hystrix.stream

因为spring-cloud-user服务的端口号是8090,在浏览器上访问 http://localhost:8090/actuator/hystrix.stream可以发现在不停的Ping我们的服务,其实这面板的作用就是将ping的结果收集然后在面板上展示
在面板上输入要监控的服务信息,如果要监控多个这面板也能做到,要做一个聚合操作

下面有三行数据,左边第一行表示成功数,左边第二行表示熔断数量,左边最后一行表示失败数量

如果有兴趣的朋友可以下个Apache JMeter压测工具压测玩下,我电脑换系统了工具丢了就懒得搞了,这工具也挺简单的
git网址:https://github.com/ljx958720/Spring-Cloud-Hystrix.git
Spring Cloud Hystrix应用篇(十一)的更多相关文章
- Spring Cloud Hystrix原理篇(十一)
一.Hystrix处理流程 Hystrix流程图如下: Hystrix整个工作流如下: 构造一个 HystrixCommand或HystrixObservableCommand对象,用于封装请求,并在 ...
- Spring Cloud第五篇 | 服务熔断Hystrix
本文是Spring Cloud专栏的第五篇文章,了解前四篇文章内容有助于更好的理解本文: Spring Cloud第一篇 | Spring Cloud前言及其常用组件介绍概览 Spring Clo ...
- Spring Cloud第六篇 | Hystrix仪表盘监控Hystrix Dashboard
本文是Spring Cloud专栏的第六篇文章,了解前五篇文章内容有助于更好的理解本文: Spring Cloud第一篇 | Spring Cloud前言及其常用组件介绍概览 Spring Cloud ...
- Spring Cloud第八篇 | Hystrix集群监控Turbine
本文是Spring Cloud专栏的第八篇文章,了解前七篇文章内容有助于更好的理解本文: Spring Cloud第一篇 | Spring Cloud前言及其常用组件介绍概览 Spring Clo ...
- Spring Cloud第十三篇 | Spring Boot Admin服务监控
本文是Spring Cloud专栏的第十三篇文章,了解前十二篇文章内容有助于更好的理解本文: Spring Cloud第一篇 | Spring Cloud前言及其常用组件介绍概览 Spring Clo ...
- 微服务架构之spring cloud hystrix&hystrix dashboard
在前面介绍spring cloud feign中我们已经使用过hystrix,只是没有介绍,spring cloud hystrix在spring cloud中起到保护微服务的作用,不会让发生的异常无 ...
- Spring Cloud Hystrix理解与实践(一):搭建简单监控集群
前言 在分布式架构中,所谓的断路器模式是指当某个服务发生故障之后,通过断路器的故障监控,向调用方返回一个错误响应,这样就不会使得线程因调用故障服务被长时间占用不释放,避免故障的继续蔓延.Spring ...
- Spring Cloud第七篇 | 声明式服务调用Feign
本文是Spring Cloud专栏的第七篇文章,了解前六篇文章内容有助于更好的理解本文: Spring Cloud第一篇 | Spring Cloud前言及其常用组件介绍概览 Spring Cloud ...
- Spring Cloud第十篇 | 分布式配置中心Config
本文是Spring Cloud专栏的第十篇文章,了解前九篇文章内容有助于更好的理解本文: Spring Cloud第一篇 | Spring Cloud前言及其常用组件介绍概览 Spring Clo ...
随机推荐
- Fiddler 4 断点调试(修改request请求参数)
1.选中要测试的链接 2然后点击规则的Automatic Breakpoints 的Before Requests 3.重新发送请求找到测试的点链接 最终效果如下
- mongo聚合操作
1 mongodb的聚合是什么 聚合(aggregate)是基于数据处理的聚合管道,每个文档通过一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组.过滤等功能,然后经过一系列的处理, ...
- springmvc<三> 异常解析链与视图解析链
1.1.7. Exceptions - 如果异常被Controller抛出,则DispatchServlet委托异常解析链来处理异常并提供处理方案(通常是一个错误的响应) spri ...
- 老猿学5G随笔:5G的三大业务场景eMBB、URLLC、mMTC
5G的三大业务场景eMBB.URLLC.mMTC: eMBB:英文全称Enhanced Mobile Broadband,即增强移动宽带,是利用5G更好的网络覆盖及更高的传输速率来为用户提供更好的上网 ...
- VMware-workstation-full-10.0.4安装
1.下载安装包 链接:https://pan.baidu.com/s/1SBd3KP4Nxk-RaHLv7HIYTw 提取码:8zkm 2.安装VMware-workstation 双击安装包 选择典 ...
- 使用 webpack 手动搭建 vue 项目
webpack 是一个前端工程化打包工具,对于前端工程师来说 webpack 是一项十分重要的技能.下面我们就通过搭建一个 vue 项目来学习使用 webpack 主要环境: node v14.15. ...
- vue 编程式导航
// 命名的路由(这里的name为路由中定义的name名称) this.$router.push({ name: 'user', params: { userId: '123' }}) // 带查询参 ...
- 介质访问控制子层-Medium Access Control Sublayer:多路访问协议、以太网、无线局域网
第四章 介质访问控制子层-Medium Access Control Sub-layer 4.1介质访问控制子层概述 MAC子层不属于之前提到的OSI或TCP/IP架构的任何一层,这也是为什么这一层被 ...
- 手动 jq 触发 动态的 layui select change 事件
var s= $('#province').val(); //先获取 默认选中的第一个 option 的值 ( value) var select = 'dd[lay-value=' + s ...
- 算法——移掉K位数字使得数值最小
给定一个以字符串表示的非负整数 num,移除这个数中的 k 位数字,使得剩下的数字最小. leetcode 解题思路:如果这个数的各个位是递增的,那么直接从最后面开始移除一定就是最最小的:如果这个数的 ...