面试20家互联网公司总结出的高频MySQL面试题
1、MyISAM存储获与InnoDB存储引擎
MyISAM存储引擎不支持事务、表锁设计、支持全文索引。缓冲池只缓存索引文件,并不缓存数据文件。
InnoDB存储引擎支持事务、行锁设计、支持外键,支持一致性的非锁定读,也就是默认读取的操作不会产生锁。通过多版本控制来获得高并发性,并实现了SQL标准的4种隔离级别。
2、MySQL中的InnoDB中有哪些锁?
如下图所示。
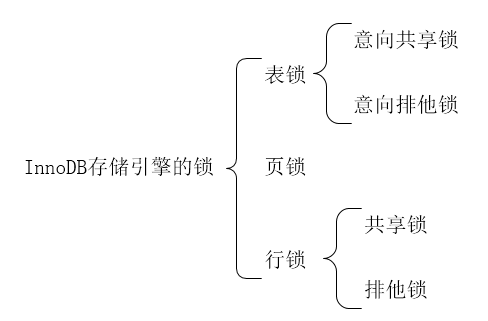
上图只是针对InnoDB存储引擎来说的,如对于此引擎来说,意向锁其实是表级别的锁。
行锁在实现时有3种算法,如下:
(1)Record Lock:间个行记录上锁
(2)Gap Lock:间隙锁,锁定一个范围,但不包含记录本身
(3)Next-Key Lock:Gap Lock + Record Lock,锁定一个范围,并且锁定记录本身,可解决幻读问题
3、数据库事务隔离级别
总结一下:
√: 可能出现 ×: 不会出现
|
事务的隔离级别 |
Read uncommitted 未提交读 |
Read committed 提交读 |
Repeatable read 可重复读 |
Serializable 序列化 |
|
脏读 事务1更新了记录,但没有提交,事务2读取了更新后的行,然后事务T1回滚,现在T2读取无效。违反隔离性导致的问题,添加行锁实现 |
√ |
× |
× |
× |
|
不可重复读 事务1读取记录时,事务2更新了记录并提交,事务1再次读取时可以看到事务2修改后的记录(修改批更新或者删除)需要添加行锁进行实现 |
√ |
√ |
× |
× |
|
幻读 事务1读取记录时事务2增加了记录并提交,事务1再次读取时可以看到事务2新增的记录。需要添加表锁进行实现。InnoDB存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题 |
√ |
√ |
√ |
× |
事务与锁是不同的。事务具有ACID属性:
(1)原子性(atomicity):由redo log重做日志来保证事务的原子性
(2)持久性(consistency):由redo log重做日志来保证事务的持久性
(3)一致性(isolation):undo log用来保证事务的一致性
(4)隔离性(durability):一个事务在操作过程中看到了其他事务的结果,如幻读。锁是用于解决隔离性的一种机制。事务的隔离级别通过锁的机制来实现。
5、InnoDB的索引
InnoDB的常见索引如下图所示。
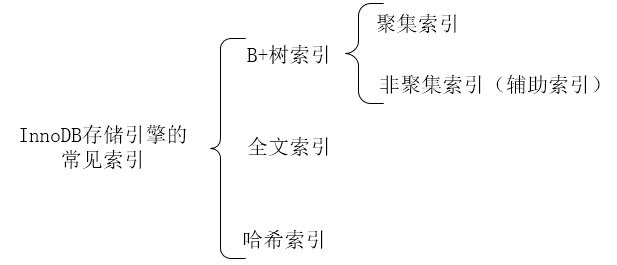
另外还有术语“联合索引”和“覆盖索引”,联合索引可能是聚集索引,也可能是非聚集索引,因为如果在建立表时,通过primary指定多个列为主键,则这多个列也算是联合索引,那么也是聚集索引。覆盖索引是非聚集索引,SQL只需要通过索引就可以返回查询所需要的数据,而不必通过二级索引查到主键之后再去查询数据。
6、索引建立原则
1、最左前缀匹配原则
非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,因为c用到了>符号。如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2、尽量选择区分度高的列作为索引
区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
3、索引列不能参与计算,保持列“干净”
比如from_unixtime(create_time) = 2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
7、一致性的非锁定读
(2)查询
查询时需要同时满足以下两个条件:
1、查找数据版本号,早于(小于等于)当前事务id的数据行。 这样可以确保事务读取的数据是事务之前已经存在的。或者是当前事务插入或修改的。
2、查找删除版本号为null或者大于当前事务版本号的记录。 这样确保取出来的数据在当前事务开启之前没有被删除。
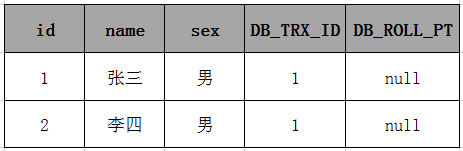
假如有一个事务中执行查询(假设事务id=2)
事务id为2 start transaction;
select * from user where sex = '男'; --(1)
select * from user where sex = '男'; --(2)
commit;
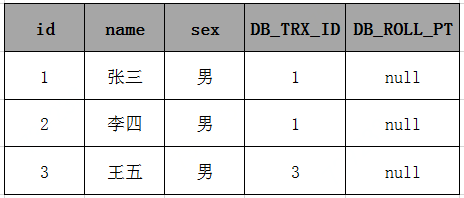
假设在执行这个事务ID为2的过程中,刚执行到(1),这时有另一个事务(假设事务id=3)往这个表里插入了一条数据;
事务id为3 start transaction;
INSERT INTO user (name,sex) VALUES ('王五','男');
commit;
此时表中的数据如下:
然后接着执行事务 id=2 中的(2),由于id=3的数据的创建时间(事务ID为3),执行当前事务的ID为2,而InnoDB只会查找事务ID小于等于当前事务ID的数据行,所以 id=3 的数据行并不会在执行事务 id=2 中的 (2) 被检索出来。在事务 id=2 中的两条select 语句检索出来的数据都只会下表:
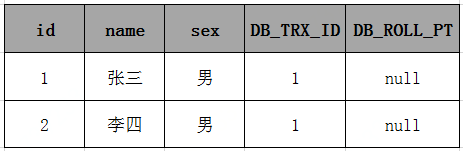
(3)删除
假如有一个事务中执行查询(假设事务id=4)
事务id为4 start transaction;
select * from user where sex = '男'; --(1)
select * from user where sex = '男'; --(2)
commit;
假设事务 id=4 刚执行到(1),此时有另外一个事务 id=5 执行了删除语句,会更新数据的删除版本号为当前事务id = 5
事务id为5 start transaction;
DELETE FROM user WHERE id = 1;
commit;
此时数据库表中数据如下:
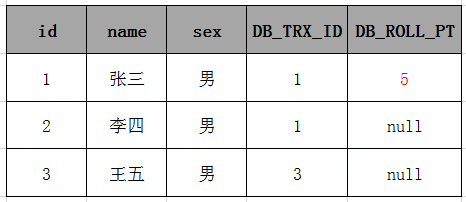
接着执行事务 id=4的事务(2),根据SELECT 检索条件可以知道,它会检索创建时间(创建事务的ID)小于当前事务ID的行和删除时间(删除事务的ID)大于当前事务的行,表中id=1的行由于删除时间(删除事务的ID)大于当前事务的ID,所以事务 id=2 的(2)在执行的时候也会把表中 id=1 的数据检索出来,所以事务4中的两条select 语句检索出来的数据都如下:
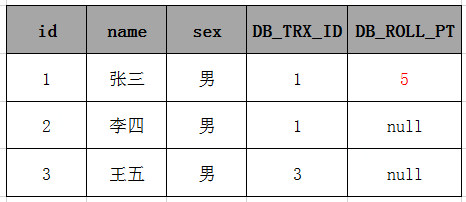
(4)修改
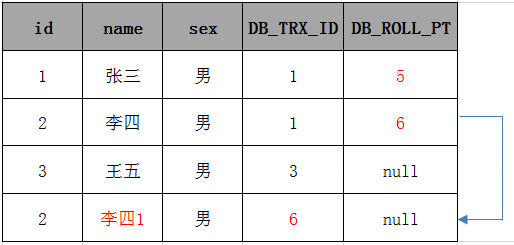
可以理解为,当一个事务中 修改一条记录时, 是先复制该数据,新数据数据版本号为当前事务id,删除版本号为 null 。然后更新 原来数据的删除版本号为 当前事务id。如下:
假如一个事务 id=6 执行了一条update语句
事务id为6 start transaction;
UPDATE user SET name='李四1' WHERE id = 2
commit;
执行结果如下:
8、MySQL大数据量分页优化
首先需要新建一张辅助分页的表pagination,有id与page字段,类型都为整数。同步id值与t_report_app表中的id,如下:
INSERT INTO pagination(id) SELECT id FROM t_report_app
然后使用如下语句插入page值。
SET @p:= 0; // 声明一个变量p并赋初始值为0
UPDATE pagination SET page=CEIL((@p:= @p + 1) / 10) ORDER BY id DESC;
我们按每页10条记录,id降序进行分页。如果插入或删除记录则需要同步pagination表记录。
这样如果我们查询第10页的记录就可以直接知道t_report_app记录中10条数据的id了,如下:

9、SQL性能分析
MySQL的调优手段,主要包括慢日志查询分析与Explain查询分析SQL执行计划。
explain模拟优化器执行SQL语句,在5.6以及以后的版本中,除过select,其他比如insert,update和delete均可以使用explain查看执行计划,从而知道mysql是如何处理sql语句,分析查询语句或者表结构的性能瓶颈。执行计划包含的信息如下:
| 信息 | 描述 |
| id |
查询的序号,包含一组数字,表示查询中执行select子句或操作表的顺序 id值如果为NULL则最后执行 |
| select_type | 查询类型,主要用于区别普通查询,联合查询,子查询等的复杂查询 1、simple 简单的select查询,查询中不包含子查询或者UNION 2、primary 查询中若包含任何复杂的子部分,最外层查询被标记 3、subquery 在select或where列表中包含了子查询 4、derived 在from列表中包含的子查询被标记为derived(衍生),MySQL会递归执行这些子查询,把结果放到临时表中 5、union 如果第二个select出现在UNION之后,则被标记为UNION,如果union包含在from子句的子查询中,外层select被标记为derived 6、union result:UNION 的结果 |
| table | 输出的行所引用的表 |
| type | 显示联结类型,显示查询使用了何种类型,按照从最佳到最坏类型排序 1、system:表中仅有一行(=系统表)这是const联结类型的一个特例。 2、const:表示通过索引一次就找到,const用于比较primary key或者unique索引。因为只匹配一行数据,所以如果将主键置于where列表中,mysql能将该查询转换为一个常量 3、eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于唯一索引或者主键扫描 4、ref:非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回所有匹配某个单独值的行,可能会找多个符合条件的行,属于查找和扫描的混合体 5、range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引,一般就是where语句中出现了between,in等范围的查询。这种范围扫描索引扫描比全表扫描要好,因为它开始于索引的某一个点,而结束另一个点,不用全表扫描 6、index:index 与all区别为index类型只遍历索引树。通常比all快,因为索引文件比数据文件小很多。 7、all:遍历全表以找到匹配的行 注意:一般保证查询至少达到range级别,最好能达到ref。 |
| possible_keys | 指出MySQL能使用哪个索引在该表中找到行 |
| key | 显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。查询中如果使用覆盖索引,则该索引和查询的select字段重叠。 |
| key_len | 表示索引中使用的字节数,该列计算查询中使用的索引的长度在不损失精度的情况下,长度越短越好。如果键是NULL,则长度为NULL。该字段显示为索引字段的最大可能长度,并非实际使用长度。 |
| ref | 显示索引的哪一列被使用了,如果有可能是一个常数,哪些列或常量被用于查询索引列上的值 |
| rows | 根据表统计信息以及索引选用情况,大致估算出找到所需的记录所需要读取的行数 |
| Extra | 包含不适合在其他列中显示,但是十分重要的额外信息 1、Using filesort:说明mysql会对数据适用一个外部的索引排序。而不是按照表内的索引顺序进行读取。MySQL中无法利用索引完成排序操作称为“文件排序” 2、Using temporary:使用了临时表保存中间结果,mysql在查询结果排序时使用临时表。常见于排序order by和分组查询group by。 3、Using index:表示相应的select操作使用覆盖索引,避免访问了表的数据行。如果同时出现using where,表名索引被用来执行索引键值的查找;如果没有同时出现using where,表名索引用来读取数据而非执行查询动作。 4、Using where :表明使用where过滤 5、using join buffer:使用了连接缓存 6、impossible where:where子句的值总是false,不能用来获取任何元组 7、select tables optimized away:在没有group by子句的情况下,基于索引优化Min、max操作或者对于MyISAM存储引擎优化count(*),不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。 8、distinct:优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作。 |
10、数据库表水平拆分和垂直拆分
(1)水平拆分举例
假设QQ的用户有100亿,如果只有一张表,每个用户登录的时候数据库都要从这100亿中查找,会很慢很慢。如果将这一张表分成100份,每张表有1亿条,就小了很多,比如qq0,qq1,qq1…qq99表。
用户登录的时候,可以将用户的id%100,那么会得到0-99的数,查询表的时候,将表名qq跟取模的数连接起来,就构建了表名。比如123456789用户,取模的89,那么就到qq89表查询,查询的时间将会大大缩短。
(2)垂直拆分举例
通常我们按以下原则进行垂直拆分:
1,把不常用的字段单独放在一张表;,
2,把text,blob等大字段拆分出来放在附表中;
3,经常组合查询的列放在一张表中;
例如存储一个文件时,简要的常见信息放到一张表中,而真正存储文件内容的text放到另外一张附表中。
面试20家互联网公司总结出的高频MySQL面试题的更多相关文章
- 新鲜出炉!面试90%会被问到的Java多线程面试题,史上最全系列!
前言 最近很多粉丝朋友私聊我说能不能给整理出一份多线程面试题出来,说自己在最近的面试中老是被问到这一块的问题被问的很烦躁,前一段时间比较忙没时间回私信,前两天看到私信我也是赶紧花了两天给大家整理出这一 ...
- 剑指offer 面试20题
面试20题: 题目:表示数值的字符串 题:请实现一个函数用来判断字符串是否表示数值(包括整数和小数).例如,字符串"+100","5e2","-123 ...
- 互联网大厂高频重点面试题 (第2季)JUC多线程及高并发
本期内容包括 JUC多线程并发.JVM和GC等目前大厂笔试中会考.面试中会问.工作中会用的高频难点知识.斩offer.拿高薪.跳槽神器,对标阿里P6的<尚硅谷_互联网大厂高频重点面试题(第2季) ...
- Java面试炼金系列 (1) | 关于String类的常见面试题剖析
Java面试炼金系列 (1) | 关于String类的常见面试题剖析 文章以及源代码已被收录到:https://github.com/mio4/Java-Gold 0x0 基础知识 1. '==' 运 ...
- [ZZ]知名互联网公司Python的16道经典面试题及答案
知名互联网公司Python的16道经典面试题及答案 https://mp.weixin.qq.com/s/To0kYQk6ivYL1Lr8aGlEUw 知名互联网公司Python的16道经典面试题及答 ...
- 就目前市面上的面试整理来说,最全的BAT大厂面试题整理在这
原标题:就目前市面上的面试整理来说,最全的BAT大厂面试题整理在这 又到了面试求职高峰期,最近有很多网友都在求大厂面试题.正好我之前电脑里面有这方面的整理,于是就发上来分享给大家. 这些题目是网友去百 ...
- 金九银十跳槽高峰,面试必备之 Redis + MongoDB 常问80道面试题
前言 有着“金九银十”之称的招聘旺季已经开启,跳槽高峰期也如约而至. 本文为主要是 Redis + MongoDB 知识点的攻略,希望能帮助到大家. 内容较多,大家准备好耐心和瓜子矿泉水. Redis ...
- 测试者出的APP测试面试题
测试者出的APP测试面试题 一.开场问题:(自由发挥) 1.请自我介绍一下: 2.为什么离开上一个公司呢? 3.做测试多久了?以前做过哪些项目?你们以前测试的流程是怎样的?用过哪些测试工具? 4.你觉 ...
- 5年经验Java程序员面试20天
写在前面 今天分享的是一位5年工作经验的Java工程师在帝都的面试经验总结,看看这些互联网公司都爱问些什么题,希望对大家的面试有指导意义. 从事Java开发也有5年经验了,4月初自己的开启面试经历 ...
随机推荐
- Spark Straming,Spark Streaming与Storm的对比分析
Spark Straming,Spark Streaming与Storm的对比分析 一.大数据实时计算介绍 二.大数据实时计算原理 三.Spark Streaming简介 3.1 SparkStrea ...
- Spring boot 集成MQ
import lombok.extern.java.Log; import org.springframework.amqp.core.TopicExchange; import org.spring ...
- NodeRED常用操作
NodeRED常用操作 记录使用在云服务器操作NodeRED过程中常用的一些过程或方法 重启NodeRED 通过命令行重启 我的NodeRED在pm2的自启动管理下,因此使用pm2进行重启 pm2 r ...
- Pytest(13)命令行参数--tb的使用
前言 pytest 使用命令行执行用例的时候,有些用例执行失败的时候,屏幕上会出现一大堆的报错内容,不方便快速查看是哪些用例失败. --tb=style 参数可以设置报错的时候回溯打印内容,可以设置参 ...
- hdu 6681 Rikka with Cake(扫描线)
题意:给你一个n*m的的矩形框 现在又k条射线 问这个矩形框会被分为多少个区域 思路:之前的想法是枚举边界然后线段树扫一遍计算一下矩形个数 复杂度果断不行 后面发现其实答案就是交点数+1 然后就用线段 ...
- ACDream手速赛2
地址:http://acdream.info/onecontest/1014 都是来自Codeforce上简单题. A. Boy or Girl 简单字符串处理 B. Walking in ...
- POJ - 1743 Musical Theme (后缀数组)
题目链接:POJ - 1743 (不可重叠最长子串) 题意:有N(1<=N<=20000)个音符的序列来表示一首乐曲,每个音符都是1..88范围内的整数,现在要找一个重复的子串,它需要 ...
- Codeforces Round #650 (Div. 3) A. Short Substrings
题目链接:https://codeforces.com/contest/1367/problem/A 题意 给出一个字符串 $t$,找出原字符串 $s$,$t$ 由 $s$ 从左至右的所有长为 $2$ ...
- Codeforces Round #637 (Div. 2)
比赛链接:https://codeforces.com/contest/1341 A - Nastya and Rice 题意 有 n 堆米,每堆质量在 [a-b,a+b] 之间,这些米的总质量是否可 ...
- 【poj 3090】Visible Lattice Points(数论--欧拉函数 找规律求前缀和)
题意:问从(0,0)到(x,y)(0≤x, y≤N)的线段没有与其他整数点相交的点数. 解法:只有 gcd(x,y)=1 时才满足条件,问 N 以前所有的合法点的和,就发现和上一题-- [poj 24 ...