Spark3.0.1各种集群模式搭建
对于spark前来围观的小伙伴应该都有所了解,也是现在比较流行的计算框架,基本上是有点规模的公司标配,所以如果有时间也可以补一下短板。
简单来说Spark作为准实时大数据计算引擎,Spark的运行需要依赖资源调度和任务管理,Spark自带了standalone模式资源调度和任务管理工具,运行在其他资源管理和任务调度平台上,如Yarn、Mesos、Kubernates容器等。
spark的搭建和Hadoop差不多,稍微简单点,本文针对下面几种部署方式进行详细描述:
Local:多用于本地测试,如在eclipse,idea中写程序测试等。
Standalone:Standalone是Spark自带的一个资源调度框架,它支持完全分布式。
Yarn:Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。
了解一个框架最直接的方式首先要拿来玩玩,玩之前要先搭建,废话少说,进入正题,搭建spark集群。
一、环境准备
搭建环境:CentOS7+jdk8+Hadoop2.10.1+Spark3.0.1
- 机器准备,由于已经搭建过Hadoop,spark集群也是使用相同集群(个人电脑资源有限),可以参照Hadoop搭建博客:centos7中搭建hadoop2.10高可用集群
- 需要安装jdk1.8、Scala2.12.12、hadoop2.10.1、spark3.0.1,其中jdk1.8和Hadoop2.10也都已经安装完成,这里只介绍Scala和spark环境配置
- 机器免密登录,也在Hadoop部署时做过,可以参照Hadoop搭建博客:centos7中搭建hadoop2.10高可用集群
- 下载Scala2.12.12(https://www.scala-lang.org/download/2.12.12.html)、下载spark3.0.1(http://spark.apache.org/downloads.html)
二、配置环境变量
1.配置Scala环境
tar -zxvf scala-2.12.12.tgz -C /opt/soft/
cd /opt/soft
ln -s scala-2.12.12 scala
vim /etc/profile
添加环境变量
#SCALA
export SCALA_HOME=/opt/soft/scala
export PATH=$PATH:$SCALA_HOME/bin
source /etc/profile
测试是否正常

正常
2.配置spark环境变量
由于各个部署方式都需要该步骤,在此单独配置,各个部署方式不再配置
tar -zxvf spark-3.0.1-bin-hadoop2.7.tgz -C /opt/soft
cd /opt/soft
ln -s spark-3.0.1-bin-hadoop2.7 spark
vim /etc/profile
添加环境变量
#spark
export SPARK_HOME=/opt/soft/spark
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile
三、搭建步骤
1.本地Local模式
上述已经解压配置好spark环境变量,本地模式不需要配置其他配置文件,可以直接使用,很简单吧,先测试一下运行样例:
cd /opt/soft/spark/binrun-example SparkPi 10

可以计算出结果
测试spark-shell
spark-shell

启动成功,说明Local模式部署成功
2.Standalone模式
1>修改Spark的配置文件spark-env.sh
cd /opt/soft/spark/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
添加如下配置:
# 主节点机器名称
export SPARK_MASTER_HOST=s141
# 默认端口号为7077
export SPARK_MASTER_PORT=7077
2>修改配置文件slaves(从节点配置)
cd /opt/soft/spark/conf
cp slaves.template slaves
vim slaves
删除原有节点,添加从节点主机如下配置:
s142
s143
s144
s145
3>将spark目录发送到其他机器,可以使用scp一个一个机器复制,这里使用的是自己写的批量复制脚本xrsync.sh(hadoop批量命令脚本xrsync.sh传输脚本)
xrsync.sh spark-3.0.1-bin-hadoop2.7
4>在各个机器中建立spark软连接,可以进入各个机器的/opt/soft目录
ln -s /opt/soft/spark-3.0.1-bin-hadoop2.7 /opt/soft/spark
这里使用的是批量执行命令脚本xcall.sh(hadoop批量命令脚本xcall.sh及jps找不到命令解决)
xcall.sh ln -s /opt/soft/spark-3.0.1-bin-hadoop2.7 /opt/soft/spark

5>启动spark集群
cd /opt/soft/spark/sbin 可以单独启动master和slave
./start-master.sh
./start-slaves.sh spark://s141:7077 也可以一键启动master和slave
./start-all.sh
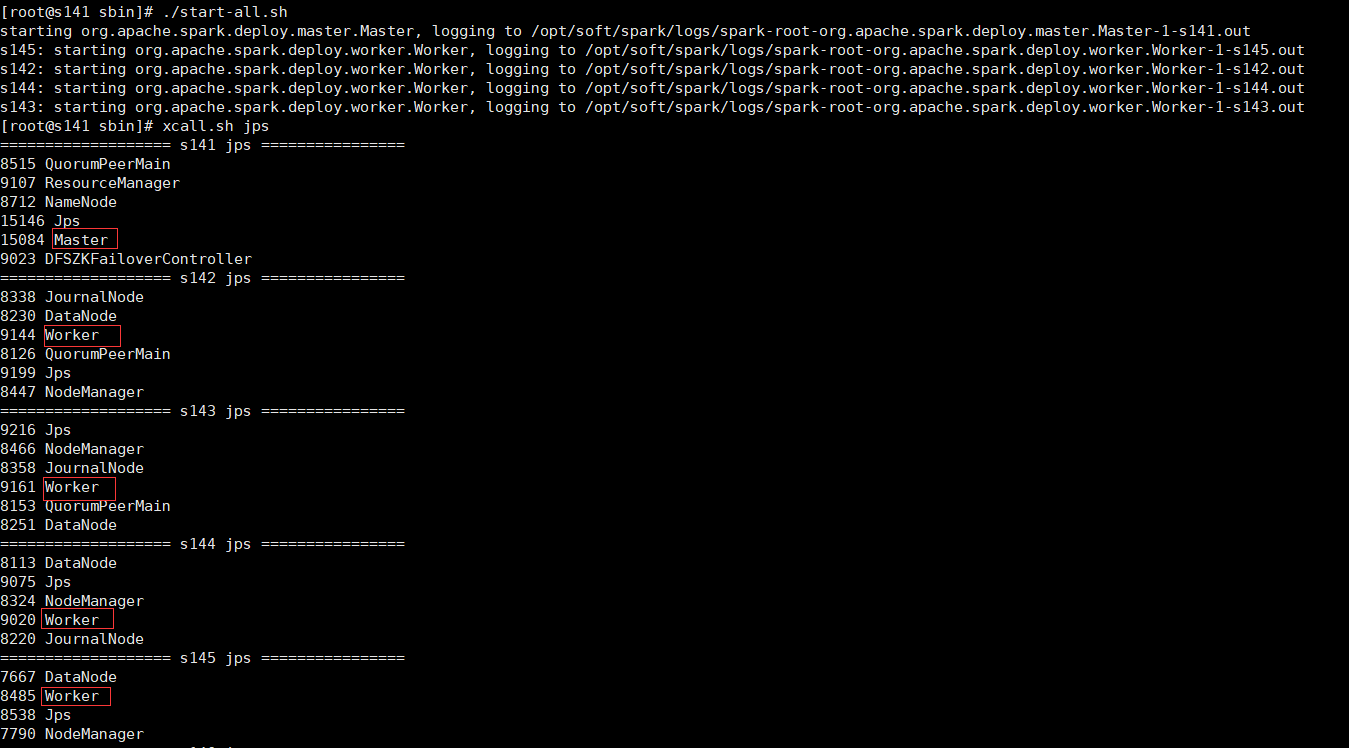
可以看到master和worker进程已经启动成功
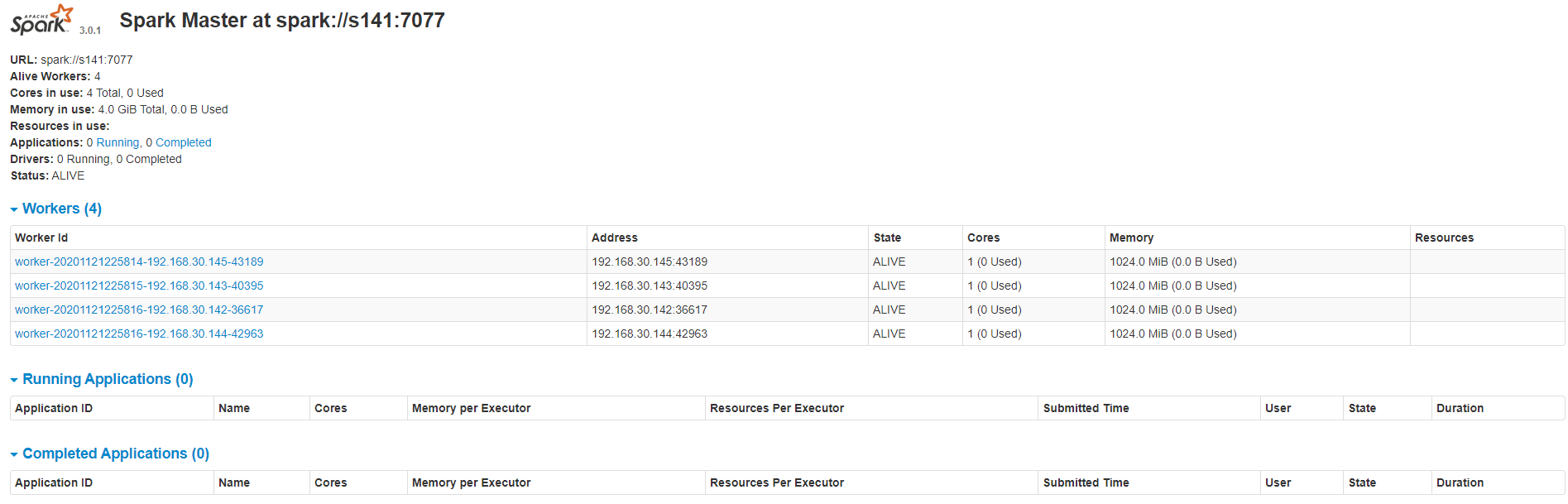
6>查看集群资源页面(webUI:http://192.168.30.141:8080/),如果8080端口查不到可以看一下master启动日志,可能是8081端口

7>进入集群shell验证
cd /opt/soft/spark/bin
./spark-shell –master spark://s141:7077

也是正常的,说明Standalone模式部署成功
3.yarn集群模式
1>修改配置文件spark-env.sh
在Standalone模式下搭建yarn集群模式很简单,只需要在spark-env.sh配置文件加入如下内容即可。
# 添加hadoop的配置目录
export HADOOP_CONF_DIR=/opt/soft/hadoop/etc/hadoop
将spark-env.sh分发到各个机器

4>启动spark集群
先启动Hadoop的yarn集群
start-yarn.sh
再启动spark集群,和Standalone模式一样有两种方式
cd /opt/soft/spark/sbin 可以单独启动master和slave
./start-master.sh
./start-slaves.sh spark://s141:7077 也可以一键启动master和slave
./start-all.sh
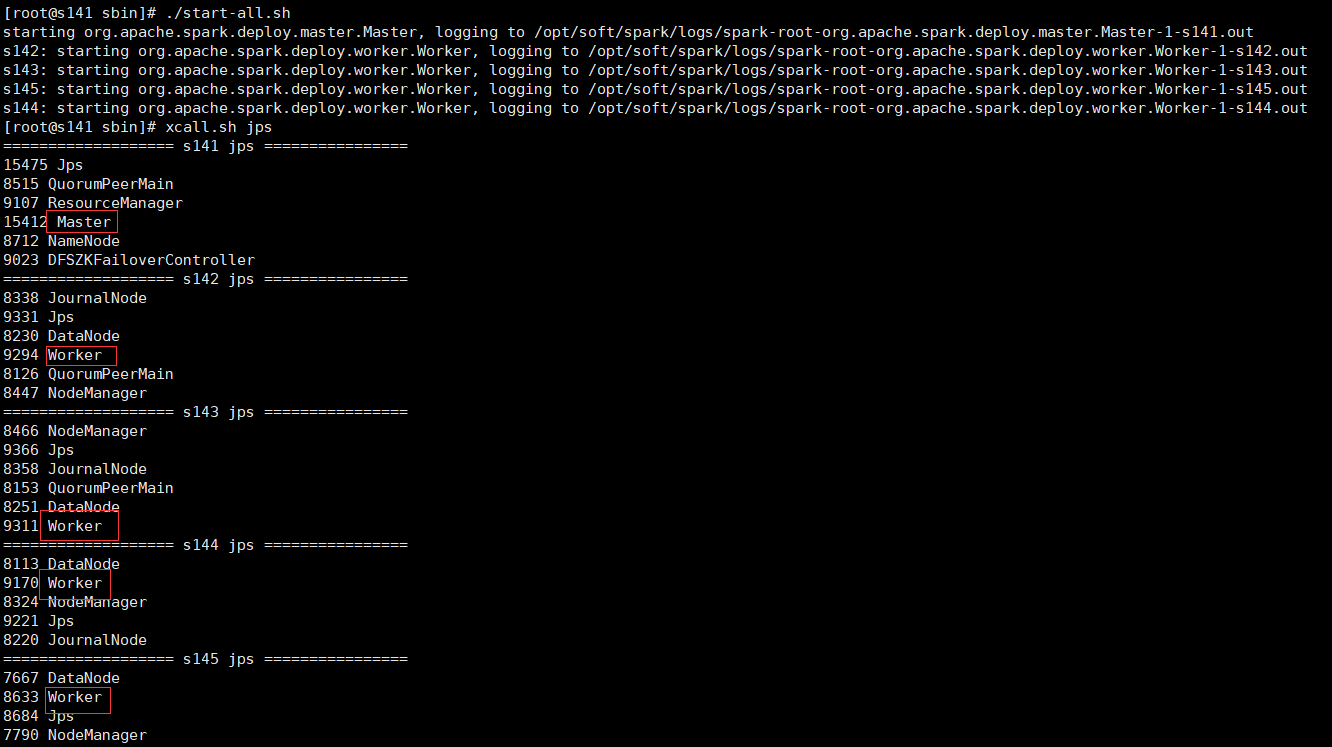
查看master和worker进程正常
5>查看集群资源页面(webUI:http://192.168.30.141:8080/),如果8080端口查不到可以看一下master启动日志,可能是8081端口
6>进入集群shell验证
cd /opt/soft/spark/bin
./spark-shell –master yarn

启动也正常
Spark3.0.1各种集群模式搭建的更多相关文章
- Redis 5.0.7 讲解,单机、集群模式搭建
Redis 5.0.7 讲解,单机.集群模式搭建 一.Redis 介绍 不管你是从事 Python.Java.Go.PHP.Ruby等等... Redis都应该是一个比较熟悉的中间件.而大部分经常写业 ...
- 深入剖析Redis系列: Redis集群模式搭建与原理详解
前言 在 Redis 3.0 之前,使用 哨兵(sentinel)机制来监控各个节点之间的状态.Redis Cluster 是 Redis 的 分布式解决方案,在 3.0 版本正式推出,有效地解决了 ...
- 微服务管理平台nacos虚拟ip负载均衡集群模式搭建
一.Nacos简介 Nacos是用于微服务管理的平台,其核心功能是服务注册与发现.服务配置管理. Nacos作为服务注册发现组件,可以替换Spring Cloud应用中传统的服务注册于发现组件,如:E ...
- Zookeeper简介及单机、集群模式搭建
1.zookeeper简介 一个开源的分布式的,为分布式应用提供协调服务的apache项目. 提供一个简单的原语集合,以便于分布式应用可以在它之上构建更高层次的同步服务. 设计非常易于编程,它使用的是 ...
- ES搜索引擎集群模式搭建【Kibana可视化】
一.简介 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎(与Solr类似),基于RESTful web接口.Elasticsearch是用Ja ...
- Hbase集群模式搭建
1.官网下载hbase安装包 这里不做赘述. 2.解压---直接tar -zxvf xxxx 3.配置hbase集群,要修改3个文件(首先zk集群已经安装好了) 注意:要把hadoop的hdfs-si ...
- 3、zookeeper 集群模式搭建
服务器 1:192.168.1.81 端口:2181.2881.3881 服务器 2:192.168.1.82 端口:2182.2882.3882 服务器 3:192.168.1.83 端口:2 ...
- nacos集群模式搭建踩坑记录
首先数据库使用的本地的mysql 1.看日志提示no set datasource,使用虚拟机ping本地后发现无法ping通,原因是本地没有关闭防火墙. 2.看日志提示不允许建立数据库连接,原因是r ...
- redis安装、测试&集群的搭建&踩过的坑
1 redis的安装 1.1 安装redis 版本说明 本教程使用redis3.0版本.3.0版本主要增加了redis集群功能. 安装的前提条件: 需要安装gcc:yum install gcc- ...
随机推荐
- centos8平台使用stress做压力测试
一,安装stress: 说明:el8的源里面还没有,先用el7的rpm包 [root@centos8 source]# wget https://download-ib01.fedoraproject ...
- salesforce零基础学习(九十六)项目中的零碎知识点小总结(四)
本篇参考: https://developer.salesforce.com/docs/atlas.en-us.216.0.apexcode.meta/apexcode/apex_classes_ke ...
- CentOS8 安装
CentOS8 1911 下载 https://mirrors.aliyun.com/centos/8/isos/x86_64/CentOS-8.1.1911-x86_64-dvd1.iso Step ...
- Microsoft.Extensions.DependencyInjection中的Transient依赖注入关系,使用不当会造成内存泄漏
Microsoft.Extensions.DependencyInjection中(下面简称DI)的Transient依赖注入关系,表示每次DI获取一个全新的注入对象.但是使用Transient依赖注 ...
- 基于.Net Core开发的物联网平台 IoTSharp V1.5 发布
很高兴的宣布新版本的发布, 这次更新我们带来了大量新特性, 最值得关注的是, 我们逐步开始支持分布式, 这意味着你可以通过多台服务器共同处理数据, 而不是原来的单机处理, 我们也将遥测数据进行分开存储 ...
- 爬虫在linux下启动selenium-安装谷歌浏览器和驱动(傻瓜式教程)
一.升级yum(防止不必要的麻烦) yum update -y yum -y groupinstall "Development tools" yum install openss ...
- ssm整合所用全部依赖pom.xml(idea版)
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven ...
- 常用的实现Javaweb页面跳转的方式
我们有两大种方式来实现页面跳转:1.JS(javascript):2.jsp跳转 先说jsp(金j三s胖p):1.转发:request.getRequestDispatcher("1.jsp ...
- short i =1; i=i+1与short i=1; i+=1的区别
很典型的一到JAVA 基础面试题,上次面试遇到的,现在记录一下. short i =1; i=i+1;short i=1;i+=1;这两有什么区别呢 ?对两个容量不一样的数据类型的变量进行算术运算时, ...
- Jenkins部署持续集成远程机节点的问题
工作需要把工作电脑作为持续集成的执行机,最近研究Jenkins,在工作电脑上搭了一套环境,期间把原来的JDK删除掉了,导致持续集成的Jenkins节点slave-agent.jnlp打不开.解决方法是 ...