面试级解析HashMap
------------恢复内容开始------------
在介绍HashMap之前,有必要先给大家介绍一些参数的概念
HashMap的最大容量,capacity译为容量,capacity就是指HashMap中bucket(桶)的数量。官方给的注解必须为2的幂。默认为1<<4(ps:这里的<<是位移运算符),每次扩容都会扩容为原来的2倍。总之,容量都是2的幂。
1/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
ps:位移运算符: <<左移运算符,>>右移运算符,还有不带符号的位移运算
计算过程以1<<4为例,首先把1转为二进制数字0000 0001
然后将上面的二进制数字向左移动30位后面补0得到0001 0000
最后将得到的二进制数字转回对应类型的十进制,运行结果为:16
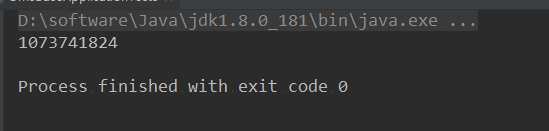
HashMap的最大容量,默认值为1<<30, 即1073741824
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
public static void main(String[] args) {
int i =1;
System.out.println(i << 30);
}
loadFactor译为装载因子,装载因子用来衡量HashMap的拥挤程度。loadFactor的默认值为0.75f。当HashMap里面容纳的元素已经达到HashMap容量的75%时,表示HashMap太挤了,需要扩容,在HashMap的构造器中可以定制loadFactor。
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
树化参数
/**
* 树化阀值,默认值为8
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 树退化阀值,默认为6
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* 最小树化HashMap的capacity(容量),默认为64
*/
static final int MIN_TREEIFY_CAPACITY = 64;
size
HashMap中实际存在的键值对的数量(为链表和树中的KV的总和)
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
threshold(扩容阀值)
threshold表示当HashMap的size大于threshold时会执行resize操作。
threshold=capacity*loadFactor
/**
* The next size value at which to resize (capacity * load factor).
* @serial
*/
int threshold;
接下来,我们通过一场小型面试来探究下HashMap的相关知识:
面试小会场:
面试官:你能跟我聊聊HashMap吗?
小明:HashMap存储键值对实现快速存取,允许为null,key值不可重复,若key值重复则覆盖;非同步,线程不安全;底层是hash表,不保证有序(比如插入的顺序)
面试官:那你能跟我聊聊它的结构和底层原理吗?
小明:HashMap是我们平时常用的数据结构,jdk1.7之前由数组和链表组合构成的数据结构。现在是由数组、链表加红黑树构成的数据结构。数组里面每个地方都存了Key-Value这样的实例,hashMap在put插入数据的时候会根据key去hash计算index的值,如果散列表为空时,调用resize()初始化散列表,如果没有发生hash碰撞,直接添加元素到散列表中去
如图:我们通过哈希函数计算出插入("name","张三")的位置, index = HashCode(Key) & (Length - 1)计算出来的index为2

在有限的数组中,我们使用hash会有一定的概率hash到一个值上
**如果发生了碰撞(hashCode值相同),进行三种判断 **
1.1:若key地址相同或者equals后内容相同,则替换旧值
1.2:如果是红黑树结构,就调用树的插入方法
1.3:链表结构,循环遍历直到链表中某个节点为空,尾插法进行插入,插入之后判断链表个数是否到达变成红黑树的树化阙值 8 ;也可以遍历到有节点与插入元素的哈希值和内容相同,进行覆盖。

所以在HashMap中只能使用引用类型(如Integer、String)来作为key,因为这些类已经很规范的覆写了hashCode()以及equals()方法。当我们去get时,对key的hashCode进行hashing,与运算计算下标获取bucket(桶)位置,如果在bucket桶的首位上就可以找到就直接返回,否则在树中找或者链表中遍历找,如果有hashCode相同,则利用equals方法去遍历链表查找节点
面试官:那你能说一下为什么要引入红黑树吗?
小明:JDK 1.8 以前 HashMap 的实现是 数组+链表,即使哈希函数取得再好,也很难达到元素百分百均匀分布。当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),完全失去了它的优势。针对这种情况,JDK 1.8 中引入了 红黑树(查找时间复杂度为 O(logn))来优化这个问题。
面试官:那你最后在说一下HashMap是如何扩容的吧

小明:如图,假设此时有一个容量为64的HashMap。1号桶内加上挂载的红黑树一共是46个KV,2号桶内加上链表上一共是3个KV,所以该hashmap实例的size = 46 +3 =49。此hashaMap的threshold(扩容阈值)=capacity(当前容量64) * loadfactory(负载因子 0.75) = 48 。由公式++size> load factor * capacity可知此时49>48,所以会扩容。
扩容分为两步
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
ad factor * capacity可知此时49>48,所以会扩容。
扩容分为两步
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
面试官:今天表现不错,等复试吧~
------------恢复内容结束------------
面试级解析HashMap的更多相关文章
- 知名互联网公司校招 Java 开发岗面试知识点解析
天之道,损有余而补不足,是故虚胜实,不足胜有余. 本文作者在一年之内参加过多场面试,应聘岗位均为 Java 开发方向.在不断的面试中,分类总结了 Java 开发岗位面试中的一些知识点. 主要包括以下几 ...
- Java 面试知识点解析(四)——版本特性篇
前言: 在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大 ...
- Java 面试知识点解析(一)——基础知识篇
前言: 在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大 ...
- Java 面试知识点解析(二)——高并发编程篇
前言: 在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大 ...
- Java 面试知识点解析(六)——数据库篇
前言: 在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大 ...
- 深入解析HashMap、HashTable
集合类之番外篇:深入解析HashMap.HashTable Java集合类是个非常重要的知识点,HashMap.HashTable.ConcurrentHashMap等算是集合类中的重点,可谓“重中之 ...
- 《Java面试全解析》505道面试题详解
<Java面试全解析>是我在 GitChat 发布的一门电子书,全书总共有 15 万字和 505 道 Java 面试题解析,目前来说应该是最实用和最全的 Java 面试题解析了. 我本人是 ...
- 《Java面试全解析》1000道面试题大全详解(转)
<Java面试全解析>1000道 面试题大全详解 本人是 2009 年参加编程工作的,一路上在技术公司摸爬滚打,前几年一直在上海,待过的公司有 360 和游久游戏,因为自己家庭的原因,放弃 ...
- 深度解析HashMap底层实现架构
摘要:分析Map接口的详细使用以及HashMap的底层是如何实现的? 本文分享自华为云社区<[图文并茂]深度解析HashMap高频面试及底层实现结构![奔跑吧!JAVA]>,原文作者:灰小 ...
随机推荐
- 「LOJ 541」「LibreOJ NOIP Round #1」七曜圣贤
description 题面很长,这里给出题目链接 solution 用队列维护扔掉的红茶,同时若后扔出的红茶比先扔出的红茶编号更小,那么先扔出的红茶不可能成为答案,所以可以用单调队列维护 故每次询问 ...
- 【PUPPETEER】初探之获取元素文本值(三)
一.知识点 page.$eval(selector, pageFunction[, ...args]) page.$$eval(selector, pageFunction[, ...args]) i ...
- day98:MoFang:服务端项目搭建
目录 1.准备工作 2.创建项目启动文件manage.py 3.构建全局初始化函数并在函数内创建app应用对象 4.通过终端脚本启动项目 5.项目加载配置 6.数据库初始化 1.SQLAlchemy初 ...
- 【操作系统】先来先服务和短作业优先算法(C语言实现)
[操作系统] 先来先服务算法和短作业优先算法实现 介绍: 1.先来先服务 (FCFS: first come first service) 如果早就绪的进程排在就绪队列的前面,迟就绪的进程排在就绪队列 ...
- markdown语法和数学公式
目录 Markdown简介 代码块 LaTeX 公式 表格 LaTeX 矩阵公式 Markdown简介 Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档,然后转换成格 ...
- CentOS下搭建简易iSCSI服务
iscsi 服务器端设置 安装target包 yum install scsi-target-utils.x86_64 创建测试裸磁盘 dd if=/dev/zero of=/iSCSIdisk/20 ...
- DRAM三种刷新方式(转载)
设DRAM中电容的电荷每2ms就会丢失,所以2ms内必须对其补充.补充电荷是按行来进行的,为了[全部]内存都能保住电荷,必须对[所有]的行都得补充. 假设刷新1行的时间为0.5μs(刷新时间是等于存取 ...
- Django的下载及命令
安装 命令行 pip3 install django==1.11.11 测试是否安装成功 django-admin 创建django项目 django-admin startproject 项目名称( ...
- AOV图与拓扑排序&AOE图与关键路径
AOV网:所有的工程或者某种流程可以分为若干个小的工程或阶段,这些小的工程或阶段就称为活动.若以图中的顶点来表示活动,有向边表示活动之间的优先关系,则这样活动在顶点上的有向图称为AOV网. 拓扑排序算 ...
- 学习笔记(1):零基础掌握 Python 入门到实战-列表与元祖到底该用哪个?(二)...
立即学习:https://edu.csdn.net/course/play/26676/338778?utm_source=blogtoedu 列表不能通过增加索引增加元素 可以使用list中的app ...