Spider--动态网页抓取--审查元素
# 静态网页在浏览器中展示的内容都在HTML的源码中,但主流网页使用 Javascript时,很多内容不出现在HTML的源代码中,我们需要使用动态网页抓取技术。
# Ajax: Asynchronous Javascript And XML,异步JvvaScript和 XML; 在不重新加载整个网页的情况下对网页的某部分进行更新,节省流量,速度快。
# 加大了 爬虫的难度。为解决这个问题,可以采用两种技术: 1)通过浏览器审查元素解析真实网页的地址。2)使用 Selenium模拟浏览器的方法。
# 1--通过浏览器审查元素解析真实网页的地址:
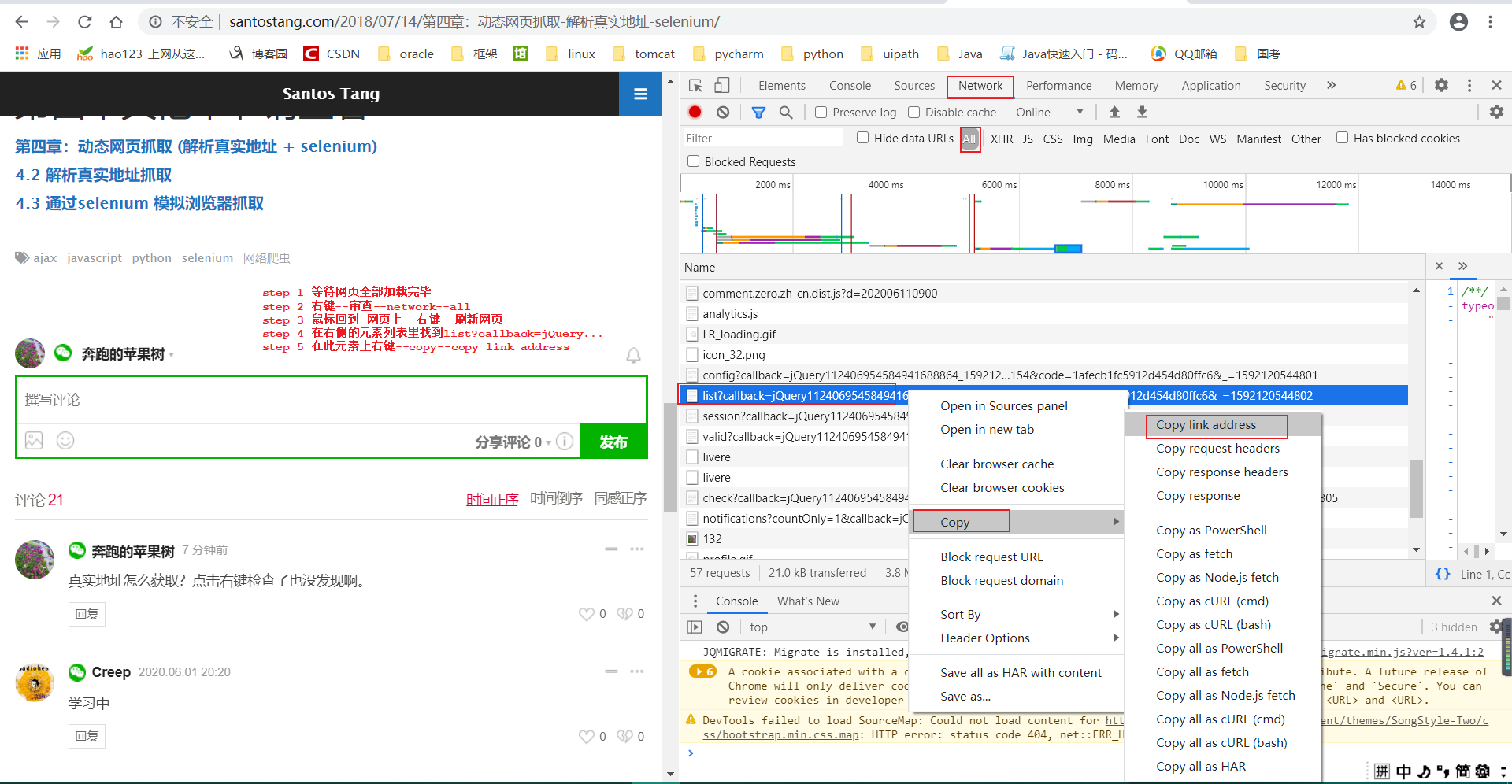
第一页和第二页最明显的区别在于 offset (虽然有其他地方也不一样,但不影响,只有 offset起决定作用),所以可以通过控制 offset来翻页。
请求头:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362
# 根据上面信息,我们将代码设计为:
import requests
url = """https://api-zero.livere.com/v1/comments/list?callback=jQuery112406954584941688864_1592120544800&limit=10&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592120544802"""
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
r = requests.get(url, headers= headers)
print (r.text)

# 只获取第一页评论:
# 解析得到的字符串r.text(即 json字符串)可以使用json库来完成解析:
import json
import requests
url = """https://api-zero.livere.com/v1/comments/list?callback=jQuery112406954584941688864_1592120544800&limit=10&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592120544802"""
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
r = requests.get(url, headers= headers)
json_data_dict=json.loads(r.text[r.text.find('{'):-2]) # 将从左大括号开始至倒数第三个字符(即将字符串末尾的括号和分号去除掉)load反序列化成字典。
# json_data_dict是一个字典嵌套字典的数据结构(字典的value是字典)。
# 其中外部字典的results键对应一个字典,该字典的parents键对应一个值是列表(列表的元素又是字典)。
comments_list=json_data_dict['results']['parents']
for comment_dict in comments_list:
print(comment_dict['content'])
# 真实地址怎么获取?点击右键检查了也没发现啊。
# 学习中
# 一起学习
# 一句话,给我爬!!!!
# 为什么不多放几个回帖
# 哎,还要多少啊。
# 我不知道要多少帖子才能翻篇啊,你们没有买他的书吗
# 我要疯了。作者拜托你能不能改一下啊
# 一页到底能装多少回帖啊?
# 好累啊
# 获取两页评论:
import json
import requests
def get_comments(page_num):
global comments_list
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
url='https://api-zero.livere.com/v1/comments/list?callback=jQuery1124042695935490813275_1592128347126&limit=10&offset='\
+page_num+\
'&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592128347133'
r = requests.get(url, headers= headers)
json_data_dict=json.loads(r.text[r.text.find('{'):-2]) # 将从左大括号开始至倒数第三个字符(即将字符串末尾的 ');'括号和分号去除掉)load反序列化成字典。
# json_data_dict是一个字典嵌套字典的数据结构(字典的value是字典)。
# 其中外部字典的results键对应一个字典,该字典的parents键对应一个值是列表(列表的元素又是字典)。
comments_list.extend(json_data_dict['results']['parents']) # 列表
if __name__=='__main__':
comments_list=[]
for page_num in range(1,3):
get_comments(str(page_num))
for comment_dict in comments_list:
print(comment_dict['content'])
真实地址怎么获取?点击右键检查了也没发现啊。
# 学习中
# 一起学习
# 一句话,给我爬!!!!
# 为什么不多放几个回帖
# 哎,还要多少啊。
# 我不知道要多少帖子才能翻篇啊,你们没有买他的书吗
# 我要疯了。作者拜托你能不能改一下啊
# 一页到底能装多少回帖啊?
# 好累啊
# 还不够哦
# 如果这样违反了你的规定,请原谅,我也是没有办法,只能帮你把水灌上
# 不然好多代码我没有办法去按照你书上的内容操作。很郁闷
# 主人可能忘记爬虫的跟帖必须要翻过两页才能测试啊
# 是不是要10页才翻篇
# 我要追加多少评论才够两页呢
# 为什么我能看到评论呢??
# 学习
# 不是
# 我是第一个来的吗?
# 回顾:
# 1)--代码在 IDE里的换行:
a='aaaaaaaaaaaaaaaaaaaaabbbbbbccc\
ggggg'
print(a) # aaaaaaaaaaaaaaaaaaaaabbbbbbcccggggg
b='aaaaaaaaaaaaaaaaaaaaabbbbbbccc'\
+\
'ggggg'
print(b) # aaaaaaaaaaaaaaaaaaaaabbbbbbcccggggg
# 2)--在输出里换行,换行符是字符串本身的一部分:
c='aaaaaaaaaaaaaaaaaaaaabbbbbbccc\nggggg'
print(c)
# aaaaaaaaaaaaaaaaaaaaabbbbbbccc
# ggggg
i=True
if\
i==True:
print('haha')
Spider--动态网页抓取--审查元素的更多相关文章
- python网络爬虫-动态网页抓取(五)
动态抓取的实例 在开始爬虫之前,我们需要了解一下Ajax(异步请求).它的价值在于在与后台进行少量的数据交换就可以使网页实现异步更新. 如果使用Ajax加载的动态网页抓取,有两种方法: 通过浏览器审查 ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- 面向初学者的Python爬虫程序教程之动态网页抓取
目的是对所有注释进行爬网. 下面列出了已爬网链接.如果您使用AJAX加载动态网页,则有两种方式对其进行爬网. 分别介绍了两种方法:(如果对代码有任何疑问,请提出改进建议)解析真实地址爬网示例是参考链接 ...
- java+phantomjs实现动态网页抓取
1.下载地址:http://phantomjs.org/download.html 2.java代码 public void getHtml(String url) { HTML="&quo ...
- Spider_基础总结5--动态网页抓取--元素审查--json--字典
# 静态网页在浏览器中展示的内容都在HTML的源码中,但主流网页使用 Javascript时,很多内容不出现在HTML的源代码中,此时仍然使用 # requests+beautifulsoup是不能够 ...
- 动态网页爬取例子(WebCollector+selenium+phantomjs)
目标:动态网页爬取 说明:这里的动态网页指几种可能:1)需要用户交互,如常见的登录操作:2)网页通过JS / AJAX动态生成,如一个html里有<div id="test" ...
- Python爬虫之三种网页抓取方法性能比较
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块. 1. 正则表达式 如果你对正则表达式还不熟悉,或是需要一些提 ...
- 网页抓取小工具(IE法)
网页抓取小工具(IE法)—— 吴姐 http://club.excelhome.net/thread-1095707-1-1.html 用IE提取网页资料的好处在于:所见即所得,网页上能看到的信息一般 ...
- find_elements后点击不了抓取的元素
1.莫名其妙抓不到元素,要去看句柄,是不是没有切换 h=driver.current_window_handle nh=driver.window_handles for i in nh: if i! ...
随机推荐
- java 反射之静态and动态代理
首先说一下我们什么情况下使用代理? (1)设计模式中有一个设计原则是开闭原则,是说对修改关闭对扩展开放,我们在工作中有时会接手很多前人的代码,里面代码逻辑让人摸不着头脑(sometimes the c ...
- intellij idea如何解决javax.servlet.http不存在
正确的解决方法是:对项目名右键,选中Open Mudule Settings--选择左侧的Modules,选择右边的Dependencies--然后点击右侧边栏的绿色"+"号,点击 ...
- day26 Pyhton 复习re模块和序列化模块
# re # 正则表达式 # 元字符 # 量词 # 贪婪匹配与惰性匹配 # 元字符量词 # 元字符量词? 在量词规范内,遇到一个x就停下来 # .*?x (.如果是第一个元素,那么它一定会从第一个元素 ...
- CentOS 7系统常见快捷键操作方式
快捷键操作方式 Linux系统中一些常见的快捷方式,可有效提高操作效率,在某些时刻也能避免操作失误带来的问题. 最有用的快捷键 序号 快捷键 官方说明 掌握程度 01 Tab 命令或路径等的补全键 移 ...
- 【编程学习】浅谈哈希表及用C语言构建哈希表!
哈希表:通过key-value而直接进行访问的数据结构,不用经过关键值间的比较,从而省去了大量处理时间. 哈希函数:选择的最主要考虑因素--尽可能避免冲突的出现 构造哈希函数的原则是: ①函数本身便于 ...
- 为什么大部分的程序员学编程,都会选择从C语言开始?
软件行业经过几十年的发展,编程语言的种类已经越来越多了,而且很多新的编程语言已经在这个领域从开始的默默无闻到如今风风火火,整个编程语言朝着集成化方向发展,这样会导致很多的初学者选择上不像以前那么单一了 ...
- 扫描仪扫描文件处理-Photoshop批处理弹出色阶设置框解决
为什么我录制动作明明设置的有色阶,最后批处理的时候仍然弹出了色阶设置框? 出现问题原因可能是你在录入设置色阶动作的时候,是彩色图片或者灰阶中的一种,而批处理的时候遇到了另外一种色彩模式.所以动作中 ...
- js实现自定义弹窗
众所周知,浏览器自带的原生弹窗很不美观,而且功能比较单一,绝大部分时候我们都会按照设计图自定义弹窗或者直接使用注入layer的弹窗等等.前段时间在慕课网上看到了一个自定义弹窗的实现,自己顺便就学习尝试 ...
- logstash 过滤filter
logstash过滤器插件filter详解及实例 1.logstash过滤器插件filter 1.1.grok正则捕获 grok是一个十分强大的logstash filter插件,他可以通过正则解 ...
- centos8安装php7.4
一,下载php7.4 1,官方网站: https://www.php.net/ 2,下载 [root@yjweb source]# wget https://www.php.net/distribut ...