论文解读 - MaskGAN:BETTER TEXT GENERATION VIA FILLING IN THE _____
1 简介
文本生成是自然语言处理中一个重要的研究领域,具有广阔的应用前景。当前主流的用来进行文本生成的模型主要是Seq2Seq模型,通常利用maximum likelihood和teacher forcing进行训练,生成文本的质量也大都通过validation perplexity来衡量。
目前的文本生成模型也存在着一些问题,其对于perplexity的优化来说效果可能很好,但却不能保证生成质量足够好的文本,因为其并没有针对输出明确定义一个损失函数来提高结果质量。而本文对此做了改变,选择用GAN的模式对生成过程进行训练。然而,传统的GAN模型无法解决自然语言处理中词向量的离散性问题,因此在这篇论文中利用强化学习中的 actor-critic 算法来训练生成器,利用最大似然和随机梯度下降来训练判别器。另外,GAN 模型中的模式崩溃和训练不稳定问题在文本生成任务下也更严重。训练不稳定会随着句子的长度增加而加重。为了避免这两个问题的影响,本文选择了对缺失词进行完形填空的生成模式,而不再让生成器来生成的完整的文本。
2 准备知识
2.1 Seq2Seq模型
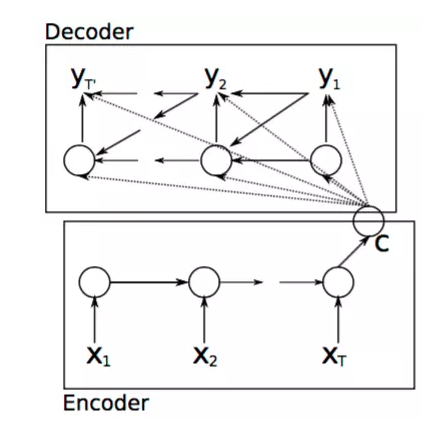
基本的Seq2Seq模型如上图所示,整个模型分为解码和编码的过程,编码的过程结束后输出一个语义向量c,之后整个解码过程根据c进行相应的学习输出。而对于解码过程,对应的是另外一个RNN网络,其隐藏层状态在t时刻的更新根据如下方程进行更新:
\]
生成的单词的条件概率可以写成:
\]
对于整个输入编码和解码的过程中,使用梯度优化算法以及最大似然条件概率为损失函数去进行模型的训练和优化:
\]
其中\(\theta\)为相应模型中的参数,\((x_n,y_n)\)是相应的输入和输出的序列。
2.2 生成对抗网络(GAN)
GAN网络包括生成器\(G_\theta(Z)\)和判别器\(D_\phi(X)\)两部分。生成器将噪音z映射到输入空间中,尽可能和真实数据相近,判别器则用来判断输入x来自真实数据的概率大小。优化目标为:
\]
其中G通过不断地学习去生成质量更好的样本来欺骗判别器D,而判别器D则通过不断地学习来分辨出由生成器G生成的数据和真实数据。
2.3 强化学习
强化学习是机器学习的一个重要分支,是多学科多领域交叉的一个产物,它的本质是解决 decision making 问题,即自动进行决策,并且可以做连续决策。
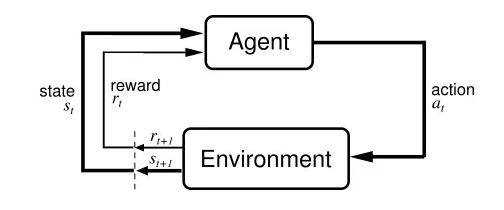
主要包含四个元素,agent,环境状态,行动,奖励, 其中智能体agent与环境environment进行交互,agent每采取一个动作a环境就会给予智能体一定的反馈reward,强化学习的目标就是获得最多的累积奖励,通过累积奖励对agent的动作进行建模,从而学习出如何在不同的状态进行不同的决策。
3 MaskGAN
\((x_t,y_t)\)是输入和目标的序列,表示被掩盖的词,\(\hat x\)表示填空后的生成序列,\(\widetilde x\)是传递给判别器的词,可能是真实词或者生成词。
模型基于Seq2Seq框架,对于一个离散的句子序列\(x = (x_1,x_2,...,x_T)\),通过0/1的掩码序列\(m = (m_1,m_2,....,m_T)\)当\(m_t\)是0时,\(x_t\)被替换为空白词,\(m_t\)为1时不变,这样掩码后的序列用\(m_x\)表示。
3.1 Generator
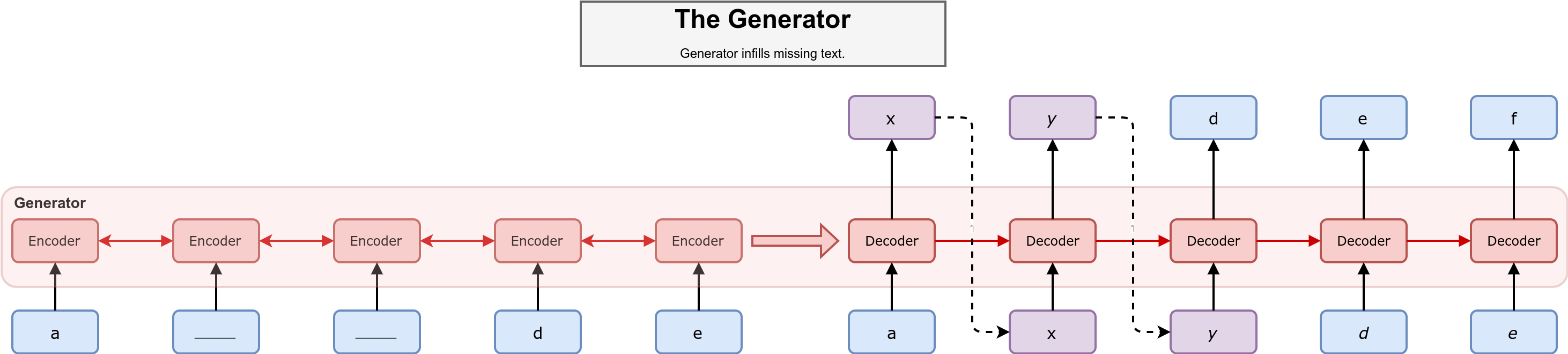
生成器模型如上图所示,采用Seq2Seq框架,其中蓝色的单元为已知的单词,紫色的单元为需要进行推断的单词,虚线的部分是基于生成器的概率分布进行采样的过程。在编码器部分读入掩码后的序列\(m(x)\),其中被掩盖的部分我们用下划线来表示。在解码器部分则是通过编码器的隐藏状态来推断被掩盖部分的单词:
\]
然后根据概率分布:
\]
进行采样操作,从而获得在t时刻的生成结果。在上图的例子中,生成器应当按照字母表的顺序来对序列进行填空。
由于自然语言处理任务中分布式词向量的离散性,不能直接使用GAN模型来完成生成器的训练,因此本文引入了强化学习的方法,将生成单词视为智能体的动作,判别器对于生成器的评价作为奖励,通过Policy Gradient方法来对生成器模型进行训练:
= \Bbb{E}_{\hat x_t\sim G}[\sum_{t=1}^T (\sum_{t=1}^T \gamma_sr_s-b_t)\nabla_{\theta}log(G_{\theta}(\hat x_t))]
\]
其中generator的目标就是使生成的结果从discriminator得到的最终的回报最大。\(G_\theta\)代表计算生成的\(\hat x_t\)概率的函数,\(R_t\)代表 discriminator 给在当前状态下采取动作\(\hat {x_t}\)得到的长期回报,\(b_t\)是为了防止强化学习训练过程中梯度的方差过大,给回报值增加一个baseline。其中\(R_t = \sum_{s=t}^T\gamma^sr^s\),\(R_t\)以及\(b_t\)是通过蒙特卡罗采样计算得到的。
3.2 Discriminator
discriminator 采用的结构和generator是一致的,都是seq2seq的形式, 只不过在每个时间步输出一个标量的概率:
\]
由此我们可以设定出对生成器模型的奖励:
\]
并以该奖励完成对生成器模型部分的训练过程。
而判别器部分的训练方式与传统的seq2seq的训练方式一致,均是采用maximum likelihood作为目标。它的输入是masked sequence 和 filled-in sequence,根据这两个判断t时刻的词是否为ground-truth。其训练目标如下:
\]
3.3 算法

4 总结
本文使用了GAN和强化学习方法Actor-Critic结合的方式来进行文本的生成,相对于之前SeqGAN的工作确实有很大的提升,可以产生具有更好质量的文本。而使用完型填空的方式来进行文本生成,有助于来缓解GAN学习中的模式崩溃问题,稳定GAN的训练过程。
论文解读 - MaskGAN:BETTER TEXT GENERATION VIA FILLING IN THE _____的更多相关文章
- CVPR2020论文解读:OCR场景文本识别
CVPR2020论文解读:OCR场景文本识别 ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network∗ 论文 ...
- 【抓取】6-DOF GraspNet 论文解读
[抓取]6-DOF GraspNet 论文解读 [注]:本文地址:[抓取]6-DOF GraspNet 论文解读 若转载请于明显处标明出处. 前言 这篇关于生成抓取姿态的论文出自英伟达.我在读完该篇论 ...
- CVPR2020论文解读:CNN合成的图片鉴别
CVPR2020论文解读:CNN合成的图片鉴别 <CNN-generated images are surprisingly easy to spot... for now> 论文链接:h ...
- 点云配准的端到端深度神经网络:ICCV2019论文解读
点云配准的端到端深度神经网络:ICCV2019论文解读 DeepVCP: An End-to-End Deep Neural Network for Point Cloud Registration ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(下)
自监督学习(Self-Supervised Learning)多篇论文解读(下) 之前的研究思路主要是设计各种各样的pretext任务,比如patch相对位置预测.旋转预测.灰度图片上色.视频帧排序等 ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(上)
自监督学习(Self-Supervised Learning)多篇论文解读(上) 前言 Supervised deep learning由于需要大量标注信息,同时之前大量的研究已经解决了许多问题.所以 ...
- 论文解读丨表格识别模型TableMaster
摘要:在此解决方案中把表格识别分成了四个部分:表格结构序列识别.文字检测.文字识别.单元格和文字框对齐.其中表格结构序列识别用到的模型是基于Master修改的,文字检测模型用到的是PSENet,文字识 ...
- 论文解读(SDNE)《Structural Deep Network Embedding》
论文题目:<Structural Deep Network Embedding>发表时间: KDD 2016 论文作者: Aditya Grover;Aditya Grover; Ju ...
- 人工智能论文解读精选 | PRGC:一种新的联合关系抽取模型
NLP论文解读 原创•作者 | 小欣 论文标题:PRGC: Potential Relation and Global Correspondence Based Joint Relational ...
随机推荐
- Angluar2 项目搭建
一 使用 Angular CLI 官方脚手架 1.安装 cli npm install -g @angular/cli 2.创建工作空间和初始应用 ng new my-app 二 tsLint 代码格 ...
- 多测师讲解_007 hashlib练习
#Hash,译做"散列",也有直接音译为"哈希"的.把任意长度的输入,通过某种hash算法,变换成固定长度的输出,该输出就是散列值,也称摘要值.该算法就是哈希函 ...
- 爬虫之Selenium
简介 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如 ...
- 习题3-3 数数字(Digit Counting , ACM/ICPC Danang 2007, UVa1225)
#include<stdio.h> #include<string.h> int main() { char s[100]; scanf("%s",s); ...
- super函数
Python面向对象中super用法与MRO机制:https://www.cnblogs.com/chenhuabin/p/10058594.html python 中 super函数的使用:http ...
- composer 阿里云加速 转
阿里云 Composer 全量镜像 本镜像与 Packagist 官方实时同步,推荐使用最新的 Composer 版本. 最新版本: 1.10.8 下载地址: https://mirrors.aliy ...
- linux(centos8):使用namespace做资源隔离
一,namespace是什么? namespace 是 Linux 内核用来隔离内核资源的方式. 它是对全局系统资源的封装隔离, 处于不同 namespace 的进程拥有独立的全局系统资源, 改变一个 ...
- Python核心编程之生成器
生成器 1. 什么是生成器 大家知道通过列表生成式(不知道的可自行百度一下),我们可以直接创建一个列表,但是,受内存限制,列表内容肯定是有限的.比如我们要创建一个包含100万个元素的列表,这100万个 ...
- 基于risc-v架构cpu
一.定义: CPU ,全称为中央处理器单元,简称为处理器,是一个不算年轻的概念 早在 20 世纪60 年代便己诞生了第一款 CPU请注意区分"处理器"和"处理器核& ...
- Stream(二)
public class Test { /* * Stream接口: * 实现类 * IntStream * DoubleStream * LongStream * * 一.创建Stream * 1. ...