感知机算法(PLA)代码实现
1. 引言
在这里主要实现感知机算法(PLA)的以下几种情况:
- PLA算法的原始形式(二分类)
- PLA算法的对偶形式(二分类)
- PLA算法的作图(二维)
- PLA算法的多分类情况(包括one vs. rest 和one vs. one 两种情况)
- PLA算法的sklearn实现
为了方便起见,使用鸢尾花数据集进行PLA算法的验证。
2. 载入库和数据处理
# 载入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Perceptron
import warnings
warnings.filterwarnings("ignore")
# 设置图形尺寸
plt.rcParams["figure.figsize"] = [14, 7]
plt.rcParams["font.size"] = 14
# 载入鸢尾花数据集
iris_data = load_iris()
xdata = iris_data["data"]
ydata = iris_data["target"]
3. 感知机的原始形式
感知机的详细原理见我的前一篇博客
class model_perceptron(object):
"""
功能:实现感知机算法
参数 w:权重,默认都为None
参数 b:偏置项,默认为0
参数 alpha:学习率,默认为0.001
参数 iter_epoch:迭代轮数,默认最大为1000
"""
def __init__(self, w = None, b = 0, alpha = 0.001, max_iter_epoch = 1000):
self.w = w
self.b = b
self.alpha = alpha
self.max_iter_epoch = max_iter_epoch
def linear_model(self, X):
"""功能:实现线性模型"""
return np.dot(X, self.w) + self.b
def fit(self, X, y):
"""
功能:拟合感知机模型
参数 X:训练集的输入数据
参数 y:训练集的输出数据
"""
# 按训练集的输入维度初始化w
self.w = np.zeros(X.shape[1])
# 误分类的样本就为True
state = np.sign(self.linear_model(X)) != y
# 迭代轮数
total_iter_epoch = 1
while state.any() and (total_iter_epoch <= self.max_iter_epoch):
# 使用误分类点进行权重更新
self.w += self.alpha * y[state][0] * X[state][0]
self.b += self.alpha * y[state][0]
# 状态更新
total_iter_epoch += 1
state = np.sign(self.linear_model(X)) != y
print(f"fit model_perceptron(alpha = {self.alpha}, max_iter_epoch = {self.max_iter_epoch}, total_iter_epoch = {min(self.max_iter_epoch, total_iter_epoch)})")
def predict(self, X):
"""
功能:模型预测
参数 X:测试集的输入数据
"""
return np.sign(self.linear_model(X))
def score(self, X, y):
"""
功能:模型评价(准确率)
参数 X:测试集的输入数据
参数 y:测试集的输出数据
"""
y_predict = self.predict(X)
y_score = (y_predict == y).sum() / len(y)
return y_score
# 二分类的情况(原始形式)/ 数据集的处理与划分
X = xdata[ydata < 2]
y = ydata[ydata < 2]
y = np.where(y == 0, -1, 1)
xtrain, xtest, ytrain, ytest = train_test_split(X, y)
# 原始形式的验证
ppn = model_perceptron()
ppn.fit(xtrain, ytrain)
ppn.predict(xtest)
ppn.score(xtest, ytest)
结果显示(由于随机划分数据集,运行结果不一定和图示相同):

4. 感知机的对偶形式
class perceptron_dual(object):
"""
功能:实现感知机的对偶形式
参数 beta:每个实例点更新的次数组成的向量
参数 w:权重,默认都为None
参数 b:偏置项,默认为0
参数 alpha:学习率,默认0.001
参数 max_iter_epoch:最大迭代次数,默认为1000
"""
def __init__(self, alpha = 0.001, max_iter_epoch = 1000):
self.beta = None
self.w = None
self.b = 0
self.alpha = alpha
self.max_iter_epoch = max_iter_epoch
def fit(self, X, y):
# 实例点的数量
xnum = X.shape[0]
# 初始化
self.beta = np.zeros(xnum)
# gram矩阵
gram = np.dot(X, X.T)
# 迭代条件
state = y*((self.beta * y * gram).sum(axis = 1) + self.b) <= 0
iter_epoch = 1
while state.any() and (iter_epoch <= self.max_iter_epoch):
nx = X[state][0]
ny = y[state][0]
index = (X == nx).argmax()
self.beta[index] += self.alpha
self.b += ny
# 更新条件
iter_epoch += 1
state = y*((self.beta * y * gram).sum(axis = 1) + self.b) <= 0
# 通过beta计算出w
self.w = ((self.beta * y).reshape(-1, 1) * X).sum(axis = 0)
print(f"fit perceptron_dual(alpha = {self.alpha}, total_iter_epoch = {min(self.max_iter_epoch, iter_epoch)})")
def predict(self, X):
"""
功能:模型预测
参数 X:测试集的输入数据
"""
y_predict = np.sign(X @ self.w + self.b)
return y_predict
def score(self, X, y):
"""
功能:模型评价(准确率)
参数 X:测试集的输入数据
参数 y:测试集的输出数据
"""
y_score = (self.predict(X) == y).sum() / len(y)
return y_score
# 二分类的情况(对偶形式)/ 数据集的处理与划分
X = xdata[ydata < 2]
y = ydata[ydata < 2]
y = np.where(y == 0, -1, 1)
xtrain, xtest, ytrain, ytest = train_test_split(X, y)
# 对偶形式验证
ppn = perceptron_dual()
ppn.fit(xtrain, ytrain)
ppn.predict(xtest)
ppn.score(xtest, ytest)
结果显示(由于随机划分数据集,运行结果不一定和图示相同):

5. 多分类情况—one vs. rest
假设有k个类别,ovr策略是生成k个分类器,最后选取概率最大的预测结果
class perceptron_ovr(object):
"""
功能:实现感知机的多分类情形(采用one vs. rest策略)
参数 w:权重,默认都为None
参数 b:偏置项,默认为0
参数 alpha:学习率,默认0.001
参数 max_iter_epoch:最大迭代次数,默认为1000
"""
def __init__(self, alpha = 0.001, max_iter_epoch = 1000):
self.w = None
self.b = None
self.alpha = alpha
self.max_iter_epoch = max_iter_epoch
def linear_model(self, X):
"""功能:实现线性模型"""
return np.dot(self.w, X.T) + self.b
def fit(self, X, y):
"""
功能:拟合感知机模型
参数 X:训练集的输入数据
参数 y:训练集的输出数据
"""
# 生成各分类器对应的标记
self.y_class = np.unique(y)
y_ovr = np.vstack([np.where(y == i, 1, -1) for i in self.y_class])
# 初始化w, b
self.w = np.zeros([self.y_class.shape[0], X.shape[1]])
self.b = np.zeros([self.y_class.shape[0], 1])
# 拟合各分类器,并更新相应维度的w和b
for index in range(self.y_class.shape[0]):
ppn = model_perceptron(alpha = self.alpha, max_iter_epoch = self.max_iter_epoch)
ppn.fit(X, y_ovr[index])
self.w[index] = ppn.w
self.b[index] = ppn.b
def predict(self, X):
"""
功能:模型预测
参数 X:测试集的输入数据
"""
# 值越大,说明第i维的分类器将该点分得越开,即属于该分类器的概率值越大
y_predict = self.linear_model(X).argmax(axis = 0)
# 还原原数据集的标签
for index in range(self.y_class.shape[0]):
y_predict = np.where(y_predict == index, self.y_class[index], y_predict)
return y_predict
def score(self, X, y):
"""
功能:模型评价(准确率)
参数 X:测试集的输入数据
参数 y:测试集的输出数据
"""
y_score = (self.predict(X) == y).sum()/len(y)
return y_score
# 多分类数据集处理
xtrain, xtest, ytrain, ytest = train_test_split(xdata, ydata)
# one vs. rest的验证
ppn = perceptron_ovr()
ppn.fit(xtrain, ytrain)
ppn.predict(xtest)
ppn.score(xtest, ytest)
结果显示(由于随机划分数据集,运行结果不一定和图示相同):

6. 多分类情况—one vs. one
假设有k个类别,生成k(k-1)/2个二分类器,最后通过多数投票来选取预测结果
from itertools import combinations
class perceptron_ovo(object):
"""
功能:实现感知机的多分类情形(采用one vs. one策略)
参数 w:权重,默认都为None
参数 b:偏置项,默认为0
参数 alpha:学习率,默认0.001
参数 max_iter_epoch:最大迭代次数,默认为1000
"""
def __init__(self, alpha = 0.001, max_iter_epoch = 1000):
self.w = None
self.b = None
self.alpha = alpha
self.max_iter_epoch = max_iter_epoch
def linear_model(self, X):
"""功能:实现线性模型"""
return np.dot(self.w, X.T) + self.b
def fit(self, X, y):
"""
功能:拟合感知机模型
参数 X:训练集的输入数据
参数 y:训练集的输出数据
"""
# 生成各分类器对应的标记(使用排列组合)
self.y_class = np.unique(y)
self.y_combine = [i for i in combinations(self.y_class, 2)]
# 初始化w和b
clf_num = len(self.y_combine)
self.w = np.zeros([clf_num, X.shape[1]])
self.b = np.zeros([clf_num, 1])
for index, label in enumerate(self.y_combine):
# 根据各分类器的标签选取数据集
cond = pd.Series(y).isin(pd.Series(label))
xdata, ydata = X[cond], y[cond]
ydata = np.where(ydata == label[0], 1, -1)
# 拟合各分类器,并更新相应维度的w和b
ppn = model_perceptron(alpha = self.alpha, max_iter_epoch = self.max_iter_epoch)
ppn.fit(xdata, ydata)
self.w[index] = ppn.w
self.b[index] = ppn.b
def voting(self, y):
"""
功能:投票
参数 y:各分类器的预测结果,接受的是元组如(1, 1, 2)
"""
# 统计分类器预测结果的出现次数
y_count = np.unique(np.array(y), return_counts = True)
# 返回出现次数最大的结果位置索引
max_index = y_count[1].argmax()
# 返回某个实例投票后的结果
y_predict = y_count[0][max_index]
return y_predict
def predict(self, X):
"""
功能:模型预测
参数 X:测试集的输入数据
"""
# 预测结果
y_predict = np.sign(self.linear_model(X))
# 还原标签(根据排列组合的标签)
for index, label in enumerate(self.y_combine):
y_predict[index] = np.where(y_predict[index] == 1, label[0], label[1])
# 列为某一个实例的预测结果,打包用于之后的投票
predict_zip = zip(*(i.reshape(-1) for i in np.vsplit(y_predict, self.y_class.shape[0])))
# 投票得到预测结果
y_predict = list(map(lambda x: self.voting(x), list(predict_zip)))
return np.array(y_predict)
def score(self, X, y):
"""
功能:模型评价(准确率)
参数 X:测试集的输入数据
参数 y:测试集的输出数据
"""
y_predict = self.predict(X)
y_score = (y_predict == y).sum() / len(y)
return y_score
# 多分类数据集处理
xtrain, xtest, ytrain, ytest = train_test_split(xdata, ydata)
# one vs. one的验证
ppn = perceptron_ovo()
ppn.fit(xtrain, ytrain)
ppn.predict(xtest)
ppn.score(xtest, ytest)
结果显示(由于随机划分数据集,运行结果不一定和图示相同):

准确率一般比one vs. rest要高,但是生成的分类器多
7. sklearn实现
主要使用sklearn中的Perceptron模块,其中可以实现多分类的情况(默认采用one vs. rest)
from sklearn.linear_model import Perceptron
xtrain, xtest, ytrain, ytest = train_test_split(xdata, ydata)
ppn = Perceptron(max_iter = 1000)
ppn.fit(xtrain, ytrain)
ppn.predict(xtest)
ppn.score(xtest, ytest)
结果显示:

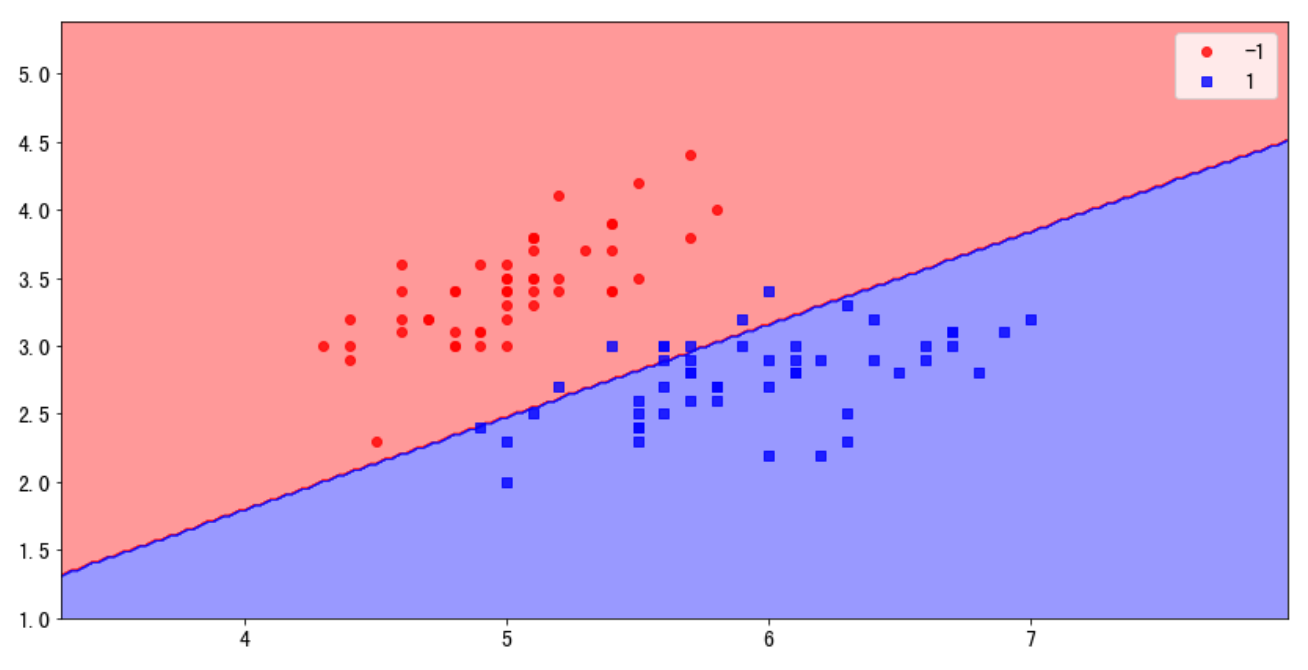
8. 感知机算法的作图
from matplotlib.colors import ListedColormap
def decision_plot(X, Y, clf, test_idx = None, resolution = 0.02):
"""
功能:画分类器的决策图
参数 X:输入实例
参数 Y:实例标记
参数 clf:分类器
参数 test_idx:测试集的index
参数 resolution:np.arange的间隔大小
"""
# 标记和颜色设置
markers = ['o', 's', 'x', '^', '>']
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(Y))])
# 图形范围
xmin, xmax = X[:, 0].min() - 1, X[:, 0].max() + 1
ymin, ymax = X[:, 1].min() - 1, X[:, 1].max() + 1
x = np.arange(xmin, xmax, resolution)
y = np.arange(ymin, ymax, resolution)
# 网格
nx, ny = np.meshgrid(x, y)
# 数据合并
xdata = np.c_[nx.reshape(-1), ny.reshape(-1)]
# 分类器预测
z = clf.predict(xdata)
z = z.reshape(nx.shape)
# 作区域图
plt.contourf(nx, ny, z, alpha = 0.4, cmap = cmap)
plt.xlim(nx.min(), nx.max())
plt.ylim(ny.min(), ny.max())
# 画点
for index, cl in enumerate(np.unique(Y)):
plt.scatter(x=X[Y == cl, 0], y=X[Y == cl, 1],
alpha=0.8, c = cmap(index),
marker=markers[index], label=cl)
# 突出测试集的点
if test_idx:
X_test, y_test = X[test_idx, :], y[test_idx]
plt.scatter(X_test[:, 0],
X_test[:, 1],
alpha=0.15,
linewidths=2,
marker='^',
edgecolors='black',
facecolors='none',
s=55, label='test set')
# 作图时的数据处理
X = xdata[ydata < 2, :2]
y = ydata[ydata < 2]
y = np.where(y == 0, -1, 1)
xtrain, xtest, ytrain, ytest = train_test_split(X, y)
ppn = model_perceptron()
ppn.fit(xtrain, ytrain)
decision_plot(X, y, ppn)
plt.legend()
结果显示:
感知机算法(PLA)代码实现的更多相关文章
- 机器学习---用python实现感知机算法和口袋算法(Machine Learning PLA Pocket Algorithm Application)
之前在<机器学习---感知机(Machine Learning Perceptron)>一文中介绍了感知机算法的理论知识,现在让我们来实践一下. 有两个数据文件:data1和data2,分 ...
- 机器学习算法--Perceptron(感知机)算法
感知机: 假设输入空间是\(\chi\subseteq R^n\),输出空间是\(\gamma =\left( +1,-1\right)\).输入\(\chi\in X\)表示实例的特征向量,对应于输 ...
- DeepLearning tutorial(3)MLP多层感知机原理简介+代码详解
本文介绍多层感知机算法,特别是详细解读其代码实现,基于python theano,代码来自:Multilayer Perceptron,如果你想详细了解多层感知机算法,可以参考:UFLDL教程,或者参 ...
- 机器学习笔记(一)· 感知机算法 · 原理篇
这篇学习笔记强调几何直觉,同时也注重感知机算法内部的动机.限于篇幅,这里仅仅讨论了感知机的一般情形.损失函数的引入.工作原理.关于感知机的对偶形式和核感知机,会专门写另外一篇文章.关于感知机的实现代码 ...
- 感知机算法及BP神经网络
简介:感知机在1957年就已经提出,可以说是最为古老的分类方法之一了.是很多算法的鼻祖,比如说BP神经网络.虽然在今天看来它的分类模型在很多数时候泛化能力不强,但是它的原理却值得好好研究.先学好感知机 ...
- Python实现各种排序算法的代码示例总结
Python实现各种排序算法的代码示例总结 作者:Donald Knuth 字体:[增加 减小] 类型:转载 时间:2015-12-11我要评论 这篇文章主要介绍了Python实现各种排序算法的代码示 ...
- 10个经典的C语言面试基础算法及代码
10个经典的C语言面试基础算法及代码作者:码农网 – 小峰 原文地址:http://www.codeceo.com/article/10-c-interview-algorithm.html 算法是一 ...
- 经典面试题(二)附答案 算法+数据结构+代码 微软Microsoft、谷歌Google、百度、腾讯
1.正整数序列Q中的每个元素都至少能被正整数a和b中的一个整除,现给定a和b,需要计算出Q中的前几项, 例如,当a=3,b=5,N=6时,序列为3,5,6,9,10,12 (1).设计一个函数void ...
- php四种排序算法实现代码
分享php排序的四种算法与代码. 冒泡:function bubble_sort($arr){ $num = count($arr); for($i=0;$i<$num;$i++){ for($ ...
随机推荐
- Haproxy/LVS负载均衡实现+keepalived实现高可用
haproxy+keepalived 集群高可用集群转发 环境介绍 #内核版本 Ubuntu 18.04.4 LTS \n \l 107-Ubuntu SMP Thu Jun 4 11:27:52 U ...
- 宝贝,来,满足你,二哥告诉你学 Java 应该买什么书?
(这次的标题是不是有点皮,对模仿好朋友 guide 哥的,我也要皮一皮) 高尔基说过,对吧?宝贝们,"书籍是人类进步的阶梯",不管学什么,买几本心仪的书读一读,帮助还是非常大的.尽 ...
- 10w行级别数据的Excel导入优化记录
需求说明 项目中有一个 Excel 导入的需求:缴费记录导入 由实施 / 用户 将别的系统的数据填入我们系统中的 Excel 模板,应用将文件内容读取.校对.转换之后产生欠费数据.票据.票据详情并存储 ...
- "Celsius=5/9*(Fahrenheit-32)" and "Celsius=5*(Fahrenheit-32)/9 "
The reason for multiplying by 5 and dividing by 9 instead of just multiplying by 5/9 is that in C, a ...
- 内存疯狂换页!CPU怒批操作系统
内存访问瓶颈 我是CPU一号车间的阿Q,前一阵子我们厂里发生了一件大喜事,老板拉到了一笔投资,准备扩大生产规模. 不过老板挺抠门的,拉到了投资也不给我们涨点工资,就知道让我们拼命干活,压榨我们的劳动力 ...
- Redis 6.0 访问控制列表ACL说明
背景 在Redis6.0之前的版本中,登陆Redis Server只需要输入密码(前提配置了密码 requirepass )即可,不需要输入用户名,而且密码也是明文配置到配置文件中,安全性不高.并且应 ...
- WordPress教程之如何批量删除未引用(无用)的TAG标签
WordPress文章与标签的关系 在WordPress中添加标签是非常方便的,只需要在写文章时在侧栏标签处添加一下就会自动在后台增加标签(所以你是不是也跟缙哥哥一样每篇文章都增加标签呢),不像分类目 ...
- 好看css搜索框样式_分享8款纯CSS搜索框
最简单实用的CSS3搜索框样式,纯CSS效果无需任何javascript,其中部分搜索框在点击的时候有动画特效,搜索框的应用也是比较普通的,效果如下: 设计网站大全https://www.wode00 ...
- FocusBI:《商业智能7B理论模型》创造者
<商业智能7B理论模型>专门为培养企业级BI人才<如何一个人完成BI项目,成为企业级BI人才>课程而创造,历经我7年的商业智能项目实施工作和经验的提炼与总结,分别深入在甲方公司 ...
- 洛谷 P4408 [NOI2003]逃学的小孩
题目传送门 题目描述 Chris家的电话铃响起了,里面传出了Chris的老师焦急的声音:“喂,是Chris的家长吗?你们的孩子又没来上课,不想参加考试了吗?”一听说要考试,Chris的父母就心急如焚, ...