hadoop的Namenode HA原理详解
为什么要Namenode HA?
1. NameNode High Availability即高可用。
2. NameNode 很重要,挂掉会导致存储停止服务,无法进行数据的读写,基于此NameNode的计算(MR,Hive等)也无法完成。
Namenode HA 如何实现,关键技术难题是什么?
1. 如何保持主和备NameNode的状态同步,并让Standby在Active挂掉后迅速提供服务,namenode启动比较耗时,包括加载fsimage和editlog(获取file to block信息),处理所有datanode第一次blockreport(获取block to datanode信息),保持NN的状态同步,需要这两部分信息同步。
2. 脑裂(split-brain),指在一个高可用(HA)系统中,当联系着的两个节点断开联系时,本来为一个整体的系统,分裂为两个独立节点,这时两个节点开始争抢共享资源,结果会导致系统混乱,数据损坏。
3. NameNode切换对外透明,主Namenode切换到另外一台机器时,不应该导致正在连接的客户端失败,主要包括Client,Datanode与NameNode的链接。
社区NN的HA架构,实现原理,各部分的实现机制,解决了哪些问题?
1. 非HA的Namenode架构,一个HDFS集群只存在一个NN,DN只向一个NN汇报,NN的editlog存储在本地目录。
2. 社区NN HA的架构
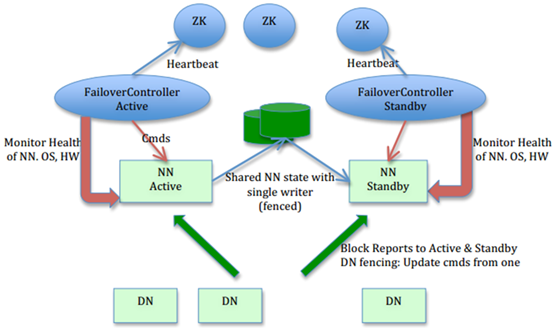
图1,NN HA架构(从社区复制)
社区的NN HA包括两个NN,主(active)与备(standby),ZKFC,ZK,share editlog。流程:集群启动后一个NN处于active状态,并提供服务,处理客户端和datanode的请求,并把editlog写到本地和share editlog(可以是NFS,QJM等)中。另外一个NN处于Standby状态,它启动的时候加载fsimage,然后周期性的从share editlog中获取editlog,保持与active的状态同步。为了实现standby在sctive挂掉后迅速提供服务,需要DN同时向两个NN汇报,使得Stadnby保存block
to datanode信息,因为NN启动中最费时的工作是处理所有datanode的blockreport。为了实现热备,增加FailoverController和ZK,FailoverController与ZK通信,通过ZK选主,FailoverController通过RPC让NN转换为active或standby。
2.关键问题:
(1) 保持NN的状态同步,通过standby周期性获取editlog,DN同时想standby发送blockreport。
(2) 防止脑裂
共享存储的fencing,确保只有一个NN能写成功。使用QJM实现fencing,下文叙述原理。
datanode的fencing。确保只有一个NN能命令DN。HDFS-1972中详细描述了DN如何实现fencing
(a) 每个NN改变状态的时候,向DN发送自己的状态和一个序列号。
(b) DN在运行过程中维护此序列号,当failover时,新的NN在返回DN心跳时会返回自己的active状态和一个更大的序列号。DN接收到这个返回是认为该NN为新的active。
(c) 如果这时原来的active(比如GC)恢复,返回给DN的心跳信息包含active状态和原来的序列号,这时DN就会拒绝这个NN的命令。
(d) 特别需要注意的一点是,上述实现还不够完善,HDFS-1972中还解决了一些有可能导致误删除block的隐患,在failover后,active在DN汇报所有删除报告前不应该删除任何block。
客户端fencing,确保只有一个NN能响应客户端请求。让访问standby nn的客户端直接失败。在RPC层封装了一层,通过FailoverProxyProvider以重试的方式连接NN。通过若干次连接一个NN失败后尝试连接新的NN,对客户端的影响是重试的时候增加一定的延迟。客户端可以设置重试此时和时间。
ZKFC的设计
1. FailoverController实现下述几个功能
(a) 监控NN的健康状态
(b) 向ZK定期发送心跳,使自己可以被选举。
(c) 当自己被ZK选为主时,active FailoverController通过RPC调用使相应的NN转换为active。
2. 为什么要作为一个deamon进程从NN分离出来
(1) 防止因为NN的GC失败导致心跳受影响。
(2) FailoverController功能的代码应该和应用的分离,提高的容错性。
(3) 使得主备选举成为可插拔式的插件。
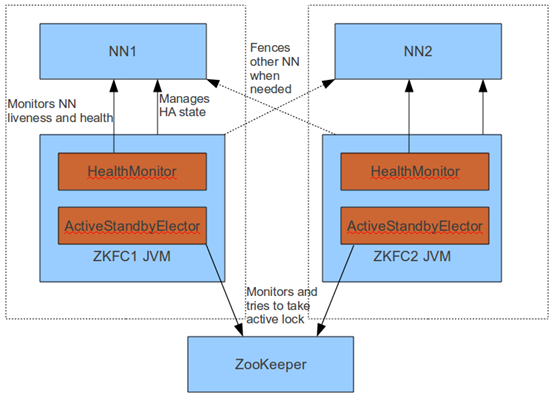
图2 FailoverController架构(从社区复制)
3. FailoverController主要包括三个组件,
(1) HealthMonitor 监控NameNode是否处于unavailable或unhealthy状态。当前通过RPC调用NN相应的方法完成。
(2) ActiveStandbyElector 管理和监控自己在ZK中的状态。
(3) ZKFailoverController 它订阅HealthMonitor 和ActiveStandbyElector 的事件,并管理NameNode的状态。
QJM的设计
- Namenode记录了HDFS的目录文件等元数据,客户端每次对文件的增删改等操作,Namenode都会记录一条日志,叫做editlog,而元数据存储在fsimage中。为了保持Stadnby与active的状态一致,standby需要尽量实时获取每条editlog日志,并应用到FsImage中。这时需要一个共享存储,存放editlog,standby能实时获取日志。这有两个关键点需要保证, 共享存储是高可用的,需要防止两个NameNode同时向共享存储写数据导致数据损坏。
- 是什么,Qurom Journal Manager,基于Paxos(基于消息传递的一致性算法)。这个算法比较难懂,简单的说,Paxos算法是解决分布式环境中如何就某个值达成一致,(一个典型的场景是,在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点都执行相同的操作序列,那么他们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个"一致性算法"以保证每个节点看到的指令一致)
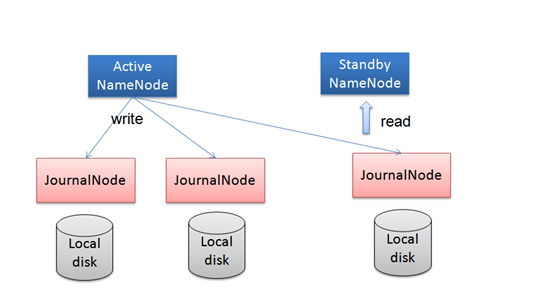
图3 QJM架构
- 如何实现,
(1) 初始化后,Active把editlog日志写到2N+1上JN上,每个editlog有一个编号,每次写editlog只要其中大多数JN返回成功(即大于等于N+1)即认定写成功。
(2) Standby定期从JN读取一批editlog,并应用到内存中的FsImage中。
(3) 如何fencing: NameNode每次写Editlog都需要传递一个编号Epoch给JN,JN会对比Epoch,如果比自己保存的Epoch大或相同,则可以写,JN更新自己的Epoch到最新,否则拒绝操作。在切换时,Standby转换为Active时,会把Epoch+1,这样就防止即使之前的NameNode向JN写日志,也会失败。
(4) 写日志:
(a) NN通过RPC向N个JN异步写Editlog,当有N/2+1个写成功,则本次写成功。
(b) 写失败的JN下次不再写,直到调用滚动日志操作,若此时JN恢复正常,则继续向其写日志。
(c) 每条editlog都有一个编号txid,NN写日志要保证txid是连续的,JN在接收写日志时,会检查txid是否与上次连续,否则写失败。
(5) 读日志:
(a) 定期遍历所有JN,获取未消化的editlog,按照txid排序。
(b) 根据txid消化editlog。
(6) 切换时日志恢复机制
(a) 主从切换时触发
(b) 准备恢复(prepareRecovery),standby向JN发送RPC请求,获取txid信息,并对选出最好的JN。
(c) 接受恢复(acceptRecovery),standby向JN发送RPC,JN之间同步Editlog日志。
(d) Finalized日志。即关闭当前editlog输出流时或滚动日志时的操作。
(e) Standby同步editlog到最新
(7) 如何选取最好的JN
(a) 有Finalized的不用in-progress
(b) 多个Finalized的需要判断txid是否相等
(c) 没有Finalized的首先看谁的epoch更大
(d) Epoch一样则选txid大的。
最后大家也可以去看看这篇文章中的HA的结构图!学习笔记 Hadoop的job提交过程,shuffle过程以及HA机制的实现
hadoop的Namenode HA原理详解的更多相关文章
- Namenode HA原理详解(脑裂)
转自:http://blog.csdn.net/tantexian/article/details/40109331 Namenode HA原理详解 社区hadoop2.2.0 release版本开始 ...
- Namenode HA原理详解
社区hadoop2.2.0 release版本开始支持NameNode的HA,本文将详细描述NameNode HA内部的设计与实现. 为什么要Namenode HA? 1. NameNode High ...
- hadoop2—namenode—HA原理详解
在hadoop1中NameNode存在一个单点故障问题,也就是说如果NameNode所在的机器发生故障,那么整个集群就将不可用(hadoop1中有个SecorndaryNameNode,但是它并不是N ...
- linux高可用集群(HA)原理详解(转载)
一.什么是高可用集群 高可用集群就是当某一个节点或服务器发生故障时,另一个 节点能够自动且立即向外提供服务,即将有故障节点上的资源转移到另一个节点上去,这样另一个节点有了资源既可以向外提供服务.高可用 ...
- linux高可用集群(HA)原理详解
高可用集群 一.什么是高可用集群 高可用集群就是当某一个节点或服务器发生故障时,另一个节点能够自动且立即向外提供服务,即将有故障节点上的资源转移到另一个节点上去,这样另一个节点有了资源既可以向外提供服 ...
- HDFS体系结构(NameNode、DataNode详解)
hadoop项目地址:http://hadoop.apache.org/ NameNode.DataNode详解 (一)分布式文件系统概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配 ...
- Hadoop 新 MapReduce 框架 Yarn 详解
Hadoop 新 MapReduce 框架 Yarn 详解: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ Ap ...
- Hadoop 发行版本 Hortonworks 安装详解(一) 准备工作
一.前言 目前Hadoop发行版非常多,所有这些发行版均是基于Apache Hadoop衍生出来的,之所以有这么多的版本,完全是由Apache Hadoop的开源协议决定的:任何人可以对其进行修改,并 ...
- LVS原理详解(3种工作方式8种调度算法)--老男孩
一.LVS原理详解(4种工作方式8种调度算法) 集群简介 集群就是一组独立的计算机,协同工作,对外提供服务.对客户端来说像是一台服务器提供服务. LVS在企业架构中的位置: 以上的架构只是众多企业里面 ...
随机推荐
- Buffer的重要属性 position/limit/capacity
1 package nio; 2 3 import java.nio.IntBuffer; 4 5 /** 6 * Buffer的重要属性 position/limit/capacity 7 * po ...
- TurtleBot3 Waffle (tx2版华夫)(12)建图-hector建图
1)[Remote PC] 启动roscore $ roscore 2)[TurBot3] 启动turbot3 $ roslaunch turbot3_bringup minimal.launch 3 ...
- 前端学习总结之——HTML
近期在找工作参加面试,想总结一下学过的东西,也会持续更新遇到的新问题.盲点. 什么是HTML? 超文本标记语言(英语:HyperText Markup Language,简称:HTML),由尖括号包围 ...
- python后端开发面试总结
网络协议 通信计算机双方必须共同遵从的一组约定,只有遵守这个约定,计算机之间才能相互通信交流 TCP / IP TCP/IP(传输控制协议/网际协议)是指能够在多个不同网络间实现信息传输的协议簇.TC ...
- linux下如何看系统日志及Out Of Memery
1.一个Out Of Memery(OOM)导致的崩溃. linux系统经常会由于资源的问题导致自己的程序莫名被杀掉,可以从linux的系统日志中找到答案: vi /var/log/message - ...
- 【剑指 Offer】12.矩阵中的路径
题目描述 请设计一个函数,用来判断在一个矩阵中是否存在一条包含某字符串所有字符的路径.路径可以从矩阵中的任意一格开始,每一步可以在矩阵中向左.右.上.下移动一格. 如果一条路径经过了矩阵的某一格,那么 ...
- 计算机考研复试真题 N阶楼梯上楼问题
题目描述 N阶楼梯上楼问题:一次可以走两阶或一阶,问有多少种上楼方式.(要求采用非递归) 输入描述: 输入包括一个整数N,(1<=N<90). 输出描述: 可能有多组测试数据,对于每组数据 ...
- Netty入门一:服务端应用搭建 & 启动过程源码分析
最近周末也没啥事就学学Netty,同时打算写一些博客记录一下(写的过程理解更加深刻了) 本文主要从三个方法来呈现:Netty核心组件简介.Netty服务端创建.Netty启动过程源码分析 如果你对Ne ...
- wpf 中用 C# 代码创建 PropertyPath ,以对间接目标进行 Storyboard 动画.
如图,一个 Rectangle 一个 Button ,点击按钮时要通过动画完成对 Rectangle填充色的渐变动画. Xaml: 1 <Window 2 x:Class="WpfAp ...
- binlog-do-db
如果只是对一个数据库设置,其实没有效果的,其他数据还是会记录binlog的 binlog-ignore-db =database b binlog日志里面将不会记录database b的所有相关的操 ...