Kafka架构深入:Kafka 工作流程及文件存储机制
kafka工作流程:
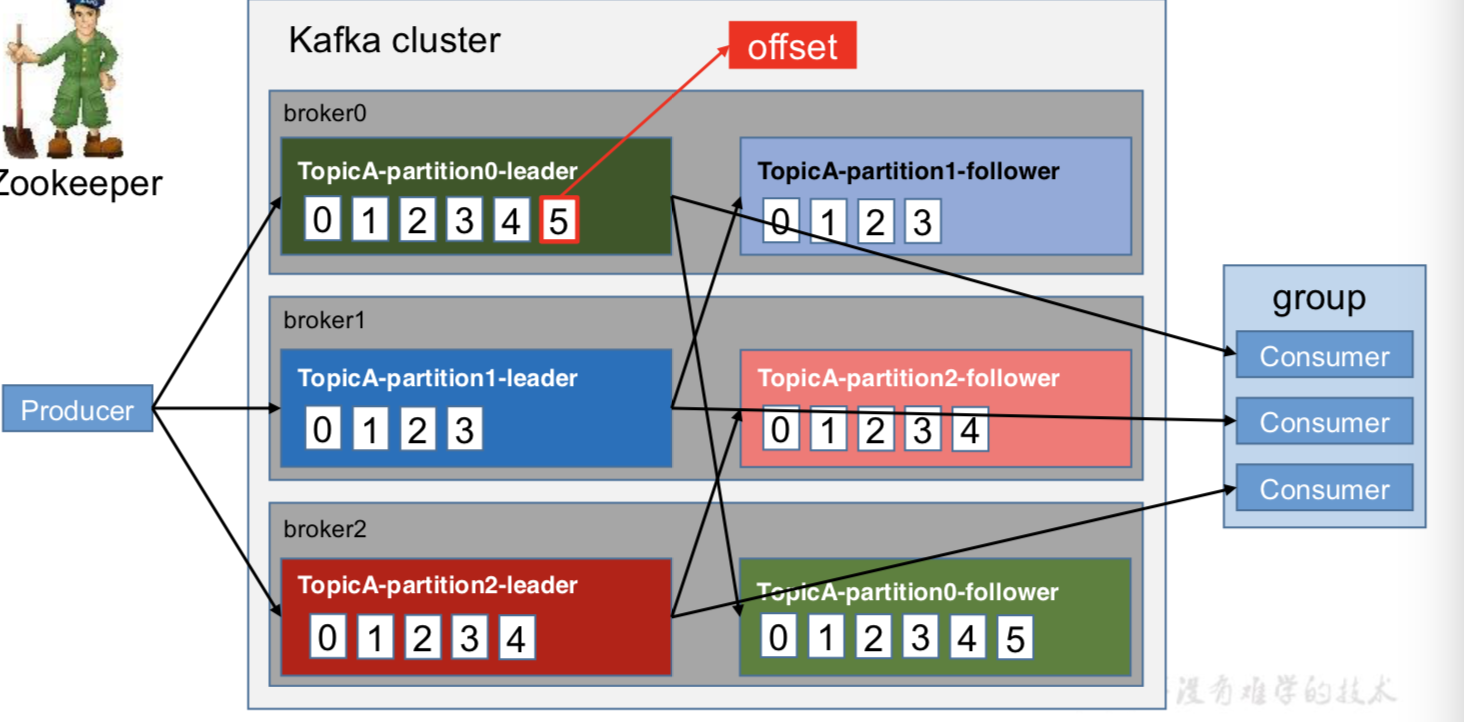
每个分区都有一个offset消费偏移量,kafka并不能保证全局有序性。
Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic 的。(文件topic_partition命名)
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文 件,该 log 文件中存储的就是 producer 生产的数据。Producer 生产的数据会被不断追加到该 log 文件末端,且每条数据都有自己的 offset。消费者组中的每个消费者,都会实时记录自己 消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。
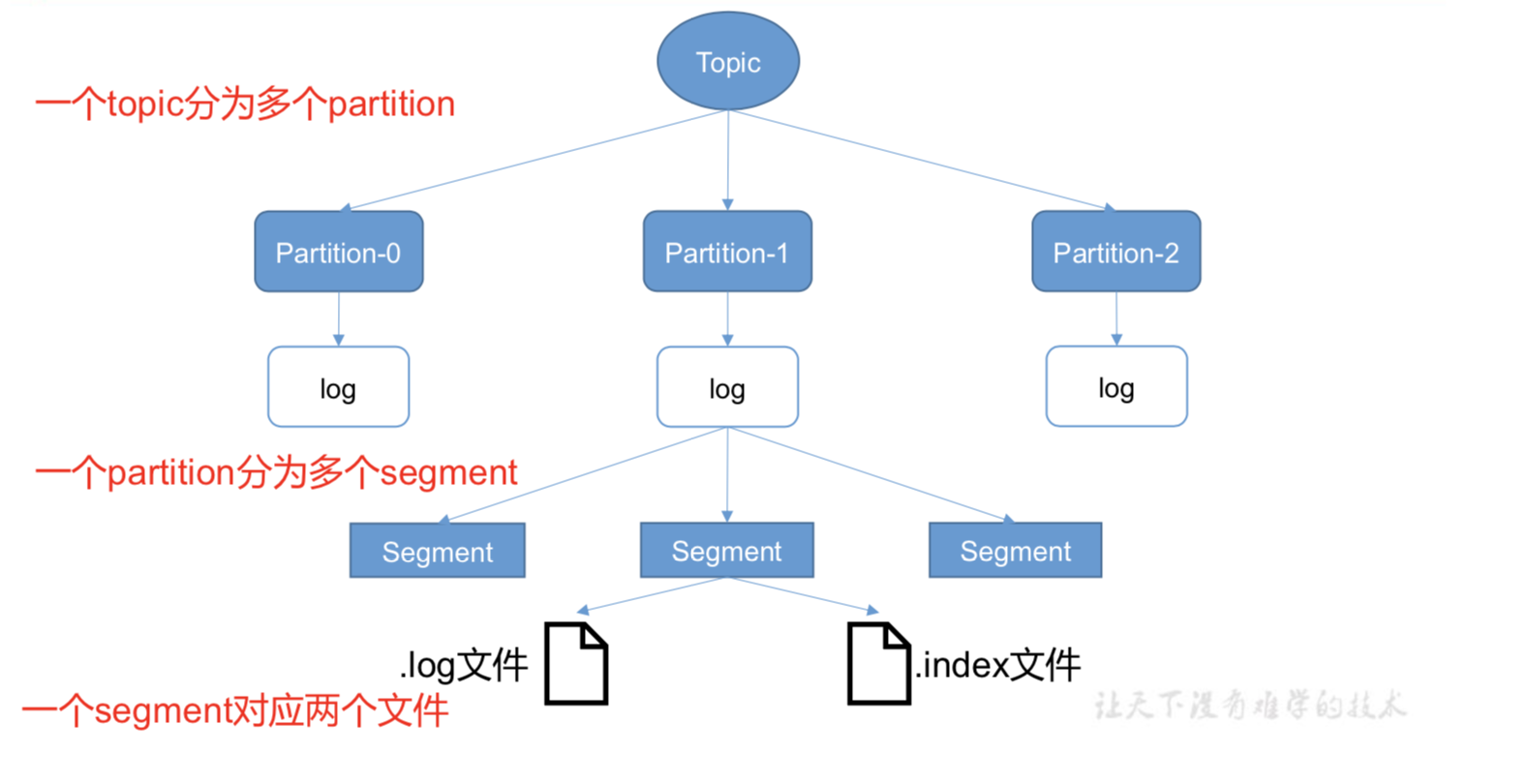
log中存的是实际数据,默认存储7天。
xxxxx.log文件
xxxxx.index文件
log.segment.bytes=1073741824 (1G)
1、当超过1G,会再建一个新的xxxxxxxxx.log数据文件。(一个segment)
2、如何在文件中快速定位到消费者需要的数据(xxxxx.index文件)
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位 效率低下,Kafka 采取了分片和索引机制,将每个 partition 分为多个 segment。每个 segment 对应两个文件——“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名 规则为:topic 名称+分区序号。例如,first 这个 topic 有三个分区,则其对应的文件夹为 first- 0,first-1,first-2。
index 和 log 文件以当前 segment 的第一条消息的 offset 命名。下图为 index 文件和 log 文件的结构示意图。
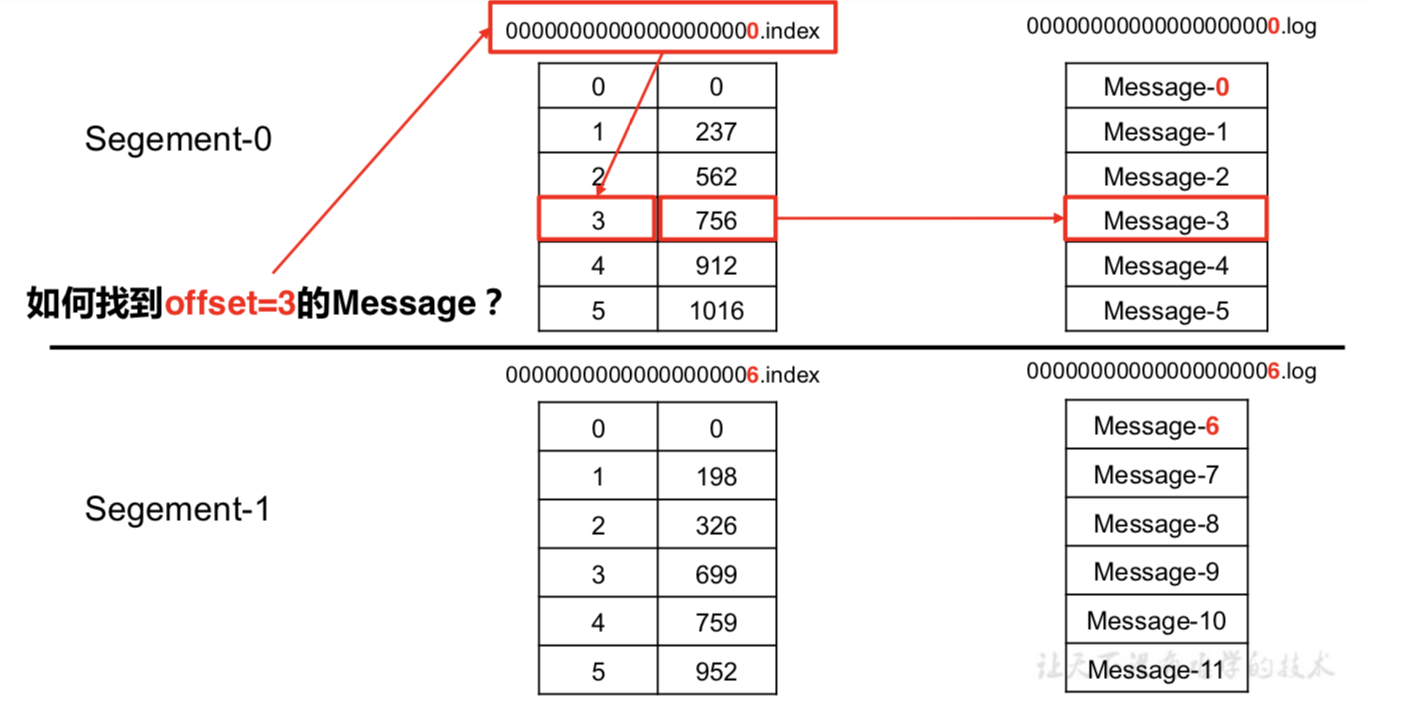
“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元 数据指向对应数据文件中 message 的物理偏移地址。 (先通过二分查找,找到消息在某个xxxx.log文件,再去xxxx.index去找消息开头在log中的物理偏移地址)
index文件中每项数据大小一样,不仅存储了每条messge的起始位置,还有每条消息的大小:上图未画出。 利用起始位置+消息大小,读取整个消息
Kafka架构深入:Kafka 工作流程及文件存储机制的更多相关文章
- 深入了解Kafka【二】工作流程及文件存储机制
1.Kafka工作流程 Kafka中的消息以Topic进行分类,生产者与消费者都是面向Topic处理数据. Topic是逻辑上的概念,而Partition是物理上的概念,每个Partition分为多个 ...
- Kafka与RocketMq文件存储机制对比
一个商业化消息队列的性能好坏,其文件存储机制设计是衡量一个消息队列服务技术水平和最关键指标之一. 开头问题 kafka文件结构和rocketMQ文件结构是什么样子?特点是什么? 一.目录结构 Kafk ...
- kafka知识体系-kafka设计和原理分析-kafka文件存储机制
kafka文件存储机制 topic中partition存储分布 假设实验环境中Kafka集群只有一个broker,xxx/message-folder为数据文件存储根目录,在Kafka broker中 ...
- Kafka文件存储机制及partition和offset
转载自: https://yq.aliyun.com/ziliao/65771 参考: Kafka集群partition replication默认自动分配分析 如何为kafka选择合适的p ...
- Kafka文件存储机制及offset存取
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka文件存储机制那些事
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka 文件存储机制那些事 - 美团技术团队
出处:https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html 自己总结: Kafka 文件存储机制_结构图:https://ww ...
- kafka学习之-文件存储机制
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- 转】 Kafka文件存储机制那些事
原博文出自于:http://tech.meituan.com/kafka-fs-design-theory.html 感谢! Kafka是什么 Kafka是最初由Linkedin公司开发,是一个 ...
随机推荐
- HTTP 【一文看清所有概念】
HTTP 标头 HTTP 1.1 的标头主要分为四种,通用标头.实体标头.请求标头.响应标头,现在我们来对这几种标头进行介绍 通用标头 HTTP 通用标头之所以这样命名,是因为与其他三个类别不同,它们 ...
- pycharm2018.3.5 下载激活(windows平台)
软件下载: 百度网盘下载 提取码: 73p7 激活操作: 1.下载jar包 JetbrainsCrack-4.2-release-enc.jar 链接:https://pan.baidu.com/s/ ...
- switch host 切换本地host
百度网盘提取地址 提取码: 753r 下载后放到软件目录即可使用
- HTML DOM Document的实际应用
HTML文档中可以使用以下属性和方法: 属性 / 方法 描述 document.activeElement 返回当前获取焦点元素 document.addEventListener() 向文档添加句柄 ...
- 2020年的UWP(2)——In Process App Service
最早的时候App Service被定义为一种后台服务,类似于极简版的Windows Service.App Service作为Background Task在宿主UWP APP中运行,向其他UWP A ...
- .Net Core 3.0 MVC 中使用 SqlSugar ORM框架
介绍 SqlSugar 是一款简单易用的ORM ,在国内市场占有率也比较高, 在今年10月份官网改版后 提供了完整的服务,让您的项目没有后顾之忧 下载地址 :https://github.com/s ...
- readcf: option RunAsUser: unknown user smmsp发送邮件失败问题
今天使用mail命令发送邮件时,发送不了,错误信息如下: /etc/mail/submit.cf: line 432: readcf: option RunAsUser: unknown user s ...
- 今天 1024,为了不 996,Lombok 用起来以及避坑指南
Lombok简介.使用.工作原理.优缺点 Lombok 项目是一个 Java 库,它会自动插入编辑器和构建工具中,Lombok 提供了一组有用的注解,用来消除 Java 类中的大量样板代码. 目录 L ...
- 【CF1436B】Prime Square 题解
原题链接 题意简介 要求构造一个由不大于 1e5 的非负数构成的正方形矩阵,矩阵的每个元素不是质数,但每一行.每一列的数字的和都是质数. 思路分析 看到样例二,我们知道数字可以重复. 于是,我们很容易 ...
- Spring boot ConditionalOnClass原理解析
Spring boot如何自动加载 对于Springboot的ConditionalOnClass注解一直非常好奇,原因是我们的jar包里面可能没有对应的class,而使用ConditionalOnC ...