Kafka架构深入:Kafka 工作流程及文件存储机制
kafka工作流程:
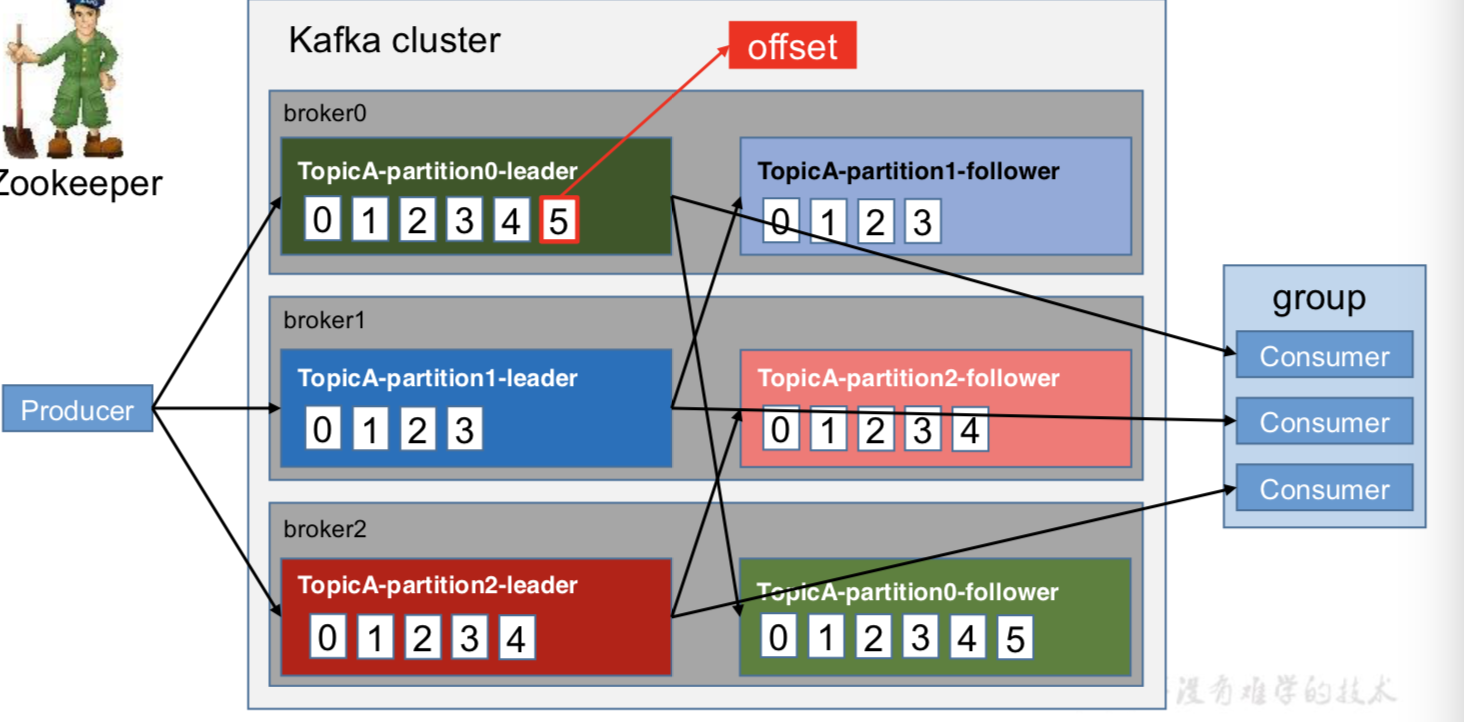
每个分区都有一个offset消费偏移量,kafka并不能保证全局有序性。
Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic 的。(文件topic_partition命名)
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文 件,该 log 文件中存储的就是 producer 生产的数据。Producer 生产的数据会被不断追加到该 log 文件末端,且每条数据都有自己的 offset。消费者组中的每个消费者,都会实时记录自己 消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。
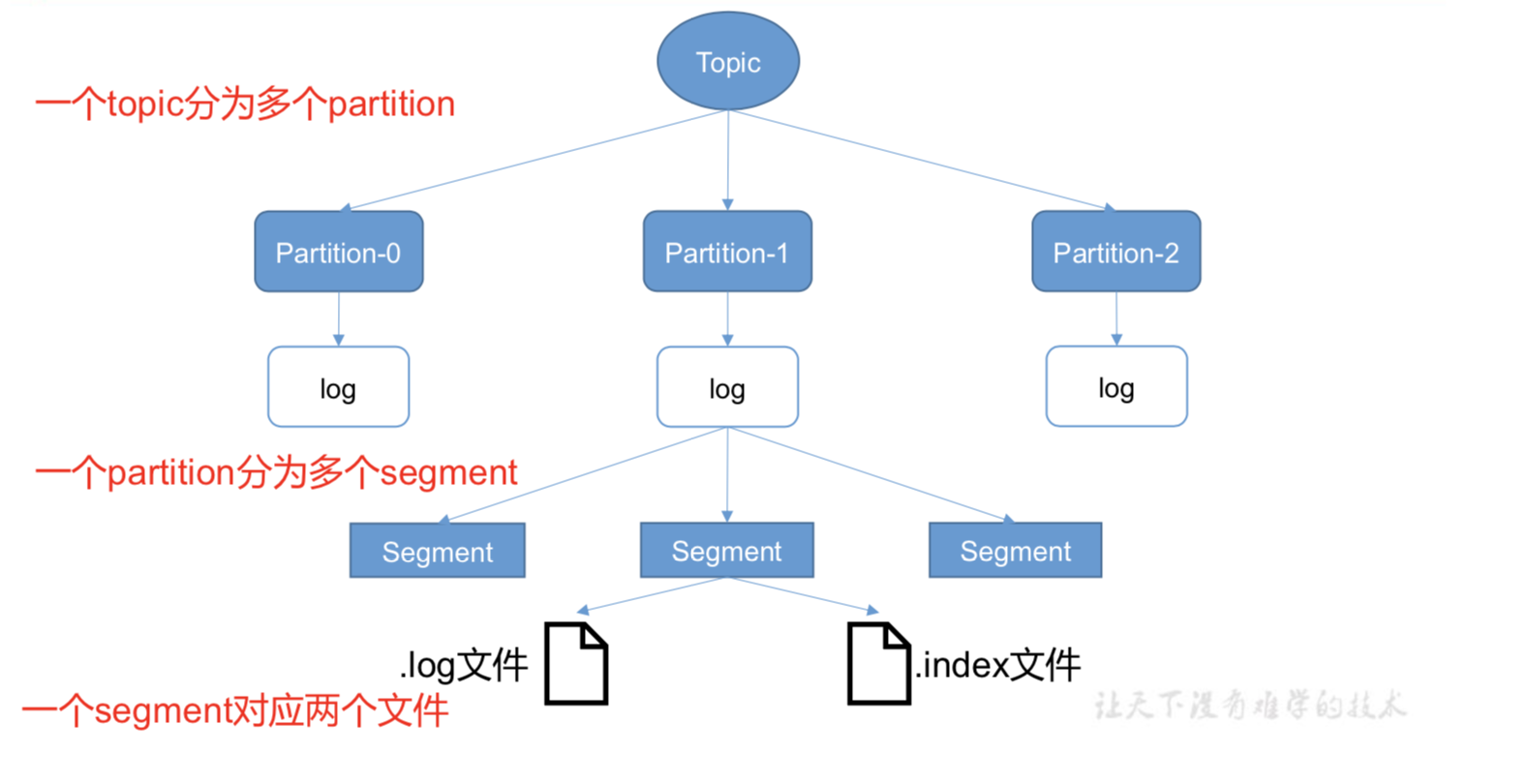
log中存的是实际数据,默认存储7天。
xxxxx.log文件
xxxxx.index文件
log.segment.bytes=1073741824 (1G)
1、当超过1G,会再建一个新的xxxxxxxxx.log数据文件。(一个segment)
2、如何在文件中快速定位到消费者需要的数据(xxxxx.index文件)
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位 效率低下,Kafka 采取了分片和索引机制,将每个 partition 分为多个 segment。每个 segment 对应两个文件——“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名 规则为:topic 名称+分区序号。例如,first 这个 topic 有三个分区,则其对应的文件夹为 first- 0,first-1,first-2。
index 和 log 文件以当前 segment 的第一条消息的 offset 命名。下图为 index 文件和 log 文件的结构示意图。
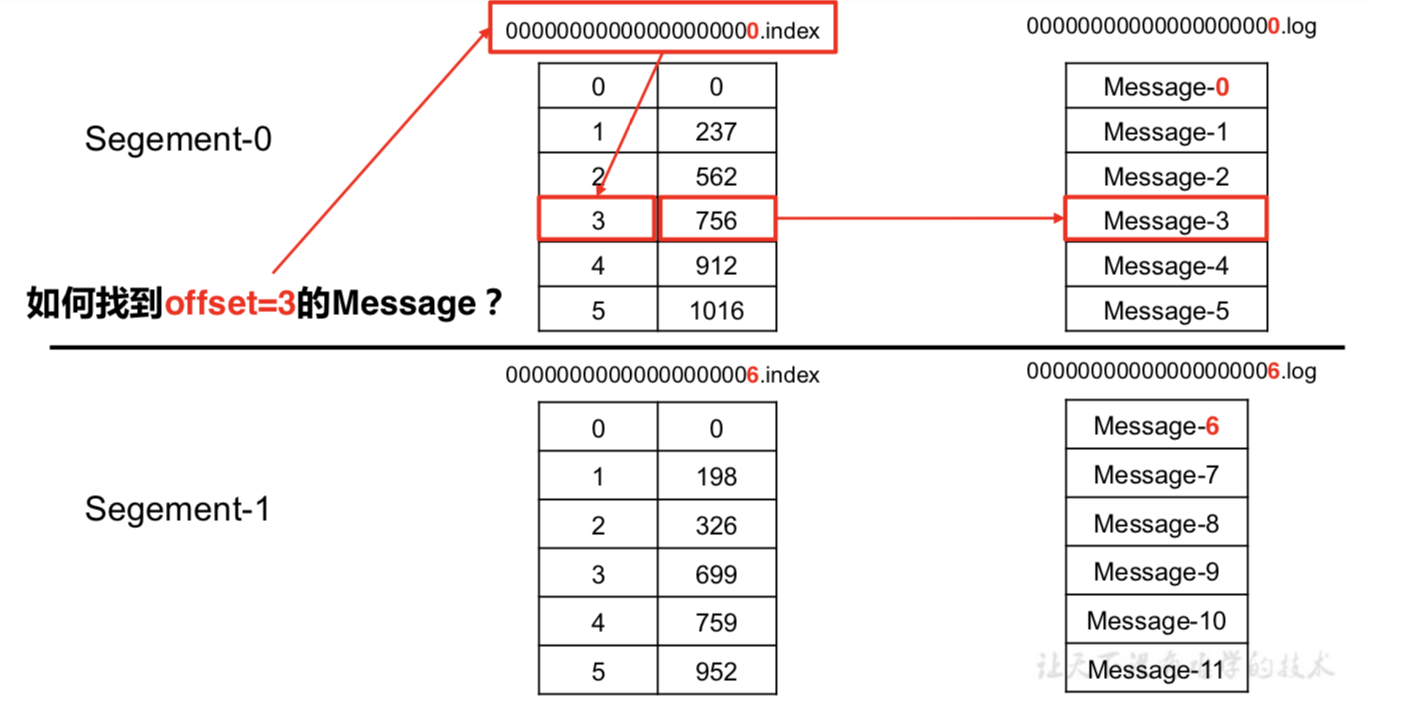
“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元 数据指向对应数据文件中 message 的物理偏移地址。 (先通过二分查找,找到消息在某个xxxx.log文件,再去xxxx.index去找消息开头在log中的物理偏移地址)
index文件中每项数据大小一样,不仅存储了每条messge的起始位置,还有每条消息的大小:上图未画出。 利用起始位置+消息大小,读取整个消息
Kafka架构深入:Kafka 工作流程及文件存储机制的更多相关文章
- 深入了解Kafka【二】工作流程及文件存储机制
1.Kafka工作流程 Kafka中的消息以Topic进行分类,生产者与消费者都是面向Topic处理数据. Topic是逻辑上的概念,而Partition是物理上的概念,每个Partition分为多个 ...
- Kafka与RocketMq文件存储机制对比
一个商业化消息队列的性能好坏,其文件存储机制设计是衡量一个消息队列服务技术水平和最关键指标之一. 开头问题 kafka文件结构和rocketMQ文件结构是什么样子?特点是什么? 一.目录结构 Kafk ...
- kafka知识体系-kafka设计和原理分析-kafka文件存储机制
kafka文件存储机制 topic中partition存储分布 假设实验环境中Kafka集群只有一个broker,xxx/message-folder为数据文件存储根目录,在Kafka broker中 ...
- Kafka文件存储机制及partition和offset
转载自: https://yq.aliyun.com/ziliao/65771 参考: Kafka集群partition replication默认自动分配分析 如何为kafka选择合适的p ...
- Kafka文件存储机制及offset存取
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka文件存储机制那些事
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka 文件存储机制那些事 - 美团技术团队
出处:https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html 自己总结: Kafka 文件存储机制_结构图:https://ww ...
- kafka学习之-文件存储机制
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- 转】 Kafka文件存储机制那些事
原博文出自于:http://tech.meituan.com/kafka-fs-design-theory.html 感谢! Kafka是什么 Kafka是最初由Linkedin公司开发,是一个 ...
随机推荐
- macvlan几种模式
vepa模式:各个子设备直接无法直接通信(可以通过支持端口聚合的交换机通信),可以和外部通信. private模式:和vepa模式类似,各个子设备之间无法通信,即使通过支持端口聚合的交换机也不能. b ...
- 多测师讲解selenium _a标签定位()_高级讲师肖sir
shift+ctrl+c 快捷键 调出元素
- 关于.netMVC 出现@ViewBag 出现错误(波浪红线)的解决方法
解决vs2015.vs2013解决mvc5 viewbag问题 1.关闭vs2015或者vs2013 打开我的电脑或者文件夹 2.打开我的电脑 在地址栏输入 %UserProfile%\AppData ...
- .NET 5.0 RC2 发布,正式版即将在 11 月 .NET Conf 大会上发布
原文:http://dwz.win/ThX 作者:Richard 翻译:精致码农-王亮 说明:本译文舍弃了少许我实在不知道如何翻译但又不是很重要的语句. 今天(10月13日)我们发布了 .NET 5. ...
- day33 Pyhton 常用模块03
一.正则表达式: 1.元字符 . 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线 \s 匹配任意的空白符 \d 匹配数字 \n 匹配一个换行符 \t 匹配一个制表符 \b 匹配一个单词的结尾 ...
- LCA树上倍增求法
1.LCA LCA就是最近公共祖先(Least common ancestor),x,y的LCA记为z=LCA(x,y),满足z是x,y的公共祖先中深度最大的那一个(即离他们最近的那一个)qwq 2. ...
- Android Jetpack从入门到精通(深度好文,值得收藏)
前言 即学即用Android Jetpack系列Blog的目的是通过学习Android Jetpack完成一个简单的Demo,本文是即学即用Android Jetpack系列Blog的第一篇. 记得去 ...
- 经验分享:计算机 web 浏览器——访问剪切板图片
有时候,我们希望能访问用户的剪切板,来实现一些方便用户的功能:但是另一方面,剪切板里的数据对用户来说又是非常隐私的,所以浏览器在获取信息方面有安全限制,同时也提供访问接口. 当我们需要实现在富文本 ...
- centos8环境判断当前操作系统是否虚拟机或容器
一,阿里云ECS的centos环境 1,执行systemd-detect-virt [root@yjweb ~]# systemd-detect-virt kvm 说明阿里云的ecs是在一个kvm环境 ...
- python 爬虫可视化函数,可以先看看要爬取的数据是否存在
import requests url = "http://www.spbeen.com" headers = { "User-Agent":"tes ...