HDFS中高可用性HA的讲解
HDFS Using QJM
HA使用的是分布式的日志管理方式
一:概述
1.背景
如果namenode出现问题,整个HDFS集群将不能使用。
是不是可以有两个namenode呢
一个为对外服务->active
一个处于待机->standby
他们的之间共享的元数据交 nameservice
2.HDFS HA的几大中重点
1)保证两个namenode里面的内存中存储的文件的元数据同步
->namenode启动时,会读镜像文件
2)变化的记录信息同步
3)日志文件的安全性
->分布式的存储日志文件
->2n+1个,使用副本数保证安全性
->使用zookeeper监控
->监控两个namenode,当一个出现了问题,可以达到自动故障转移。
->如果出现了问题,不会影响整个集群
->zookeeper对时间同步要求比较高。
4)客户端如何知道访问哪一个namenode
->使用proxy代理
->隔离机制
->使用的是sshfence
->两个namenode之间无密码登录
5)namenode是哪一个是active
->zookeeper通过选举选出zookeeper。
->然后zookeeper开始监控,如果出现文件,自动故障转移。
二:准备
3.规划集群
namenode namenode
journalnode journalnode journalnode -->日志的分布,这是日志节点,考虑的是日志的安全性。
datanode datanode datanode
4.关闭所有的进程

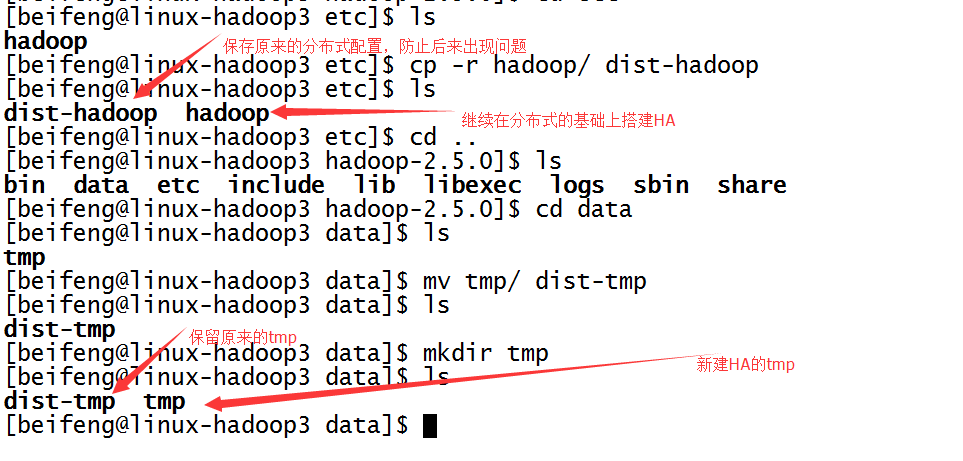
5.保存分布式的源数据,复制一份用来HDFS HA的检测。
先是第一台,先将分布式的etc/hadoop,保存为dist-hadoop,保存源数据。
同时,新建tmp。
至于第二台以及第三台,在分发之间再进行配置。
三:配置文件
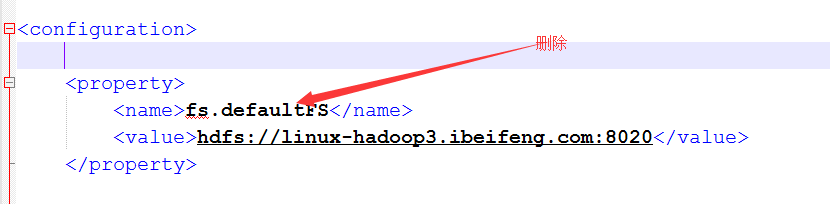
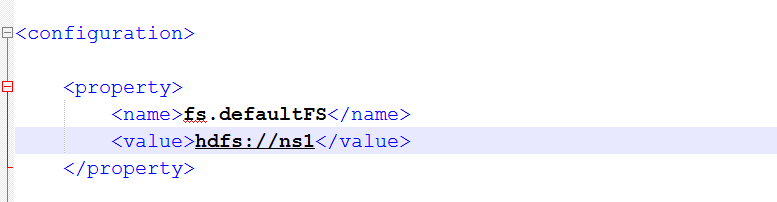
6.将core-site.xml中的文件系统删除,并添加新的文件系统
以前的是使用是配置一台,现在配置多态namenode,使用的方式是nameservices的名称的方式。
添加配置
7.配置hdfs-site.xml

8.继续配置hdfs-site.xml
dfs.nameservices的配置

dfs.ha.namenodes.[nameservice ID]的配置
包括rpc,http的namenodde地址。

dfs.namenode.shared.edits.dir的配置
这是journalnode的地址

dfs.journalnode.edits.dir 的配置
这是journalnode的日志存储的目录
先新建目录:


dfs.client.failover.proxy.provider的配置

dfs.ha.fencing.methods的配置
使用的方式为ssh拦截

9.配置完成,在分发之前先进行的是目录的规划
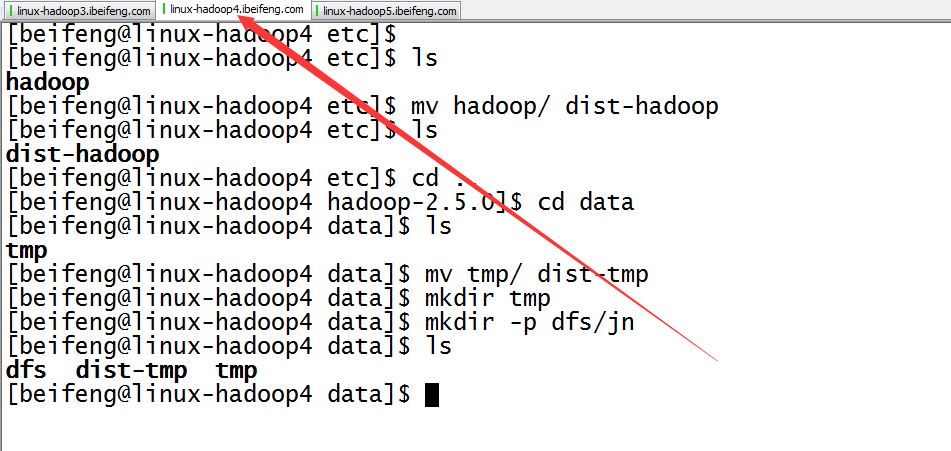
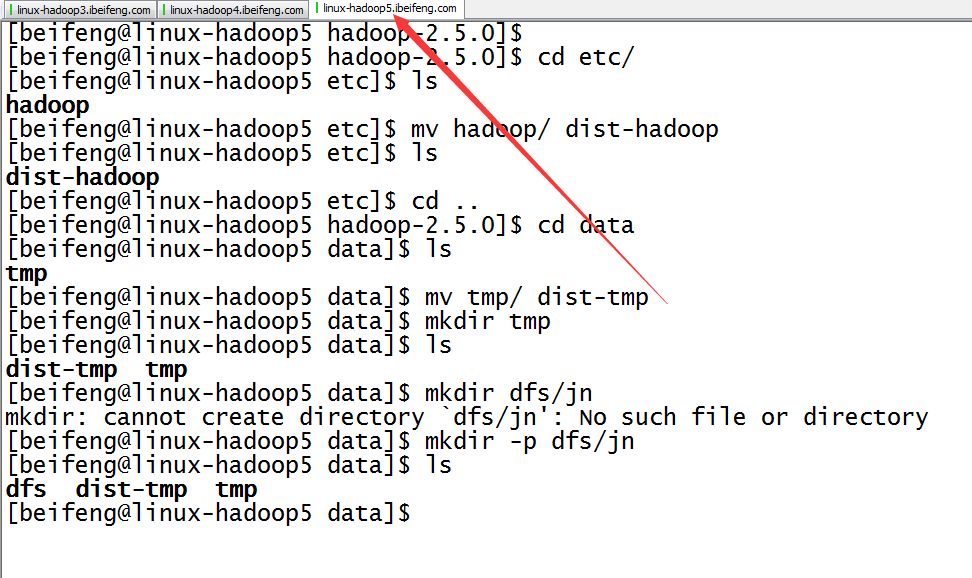
10.分发

四:启动
11.启动三台的日志节点

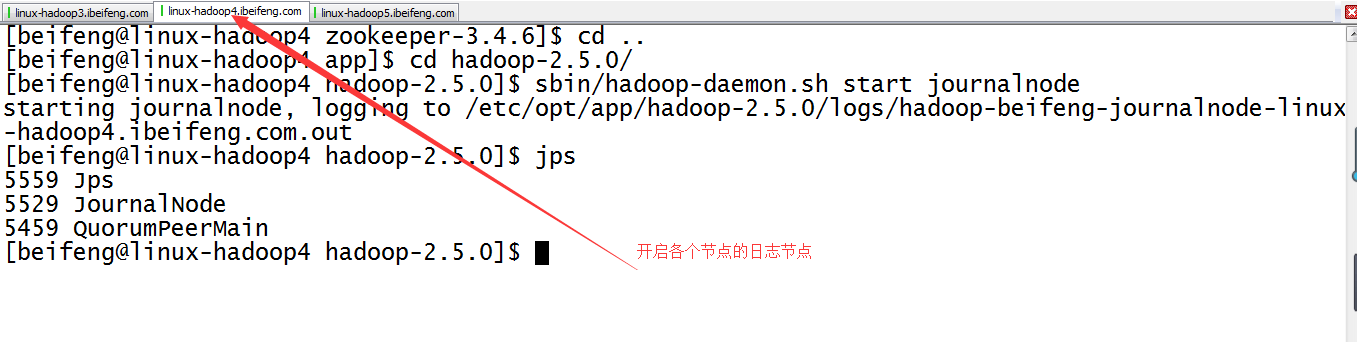
12.格式化第一台虚拟机
因为是共享数据,所以格式化一台虚拟机即可。

13.紧接着,同步元数据(在第二台上写命令)
最好是bin/hdfs namenode -help查看

14.启动namenode(两台虚拟机)

15.启动三台了datanode

16.观看两台的启动状态
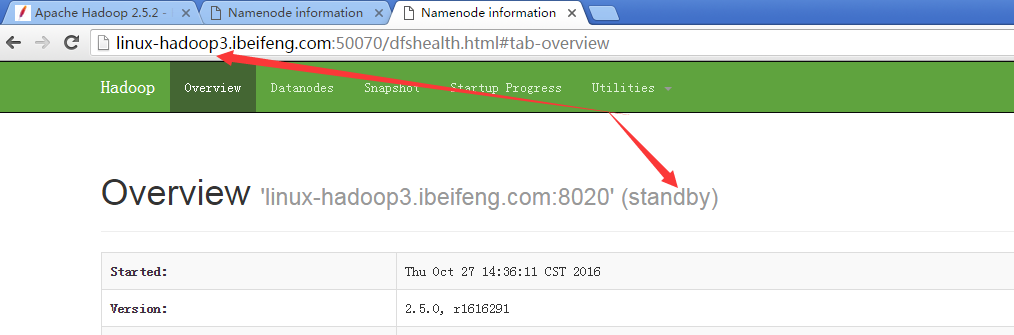
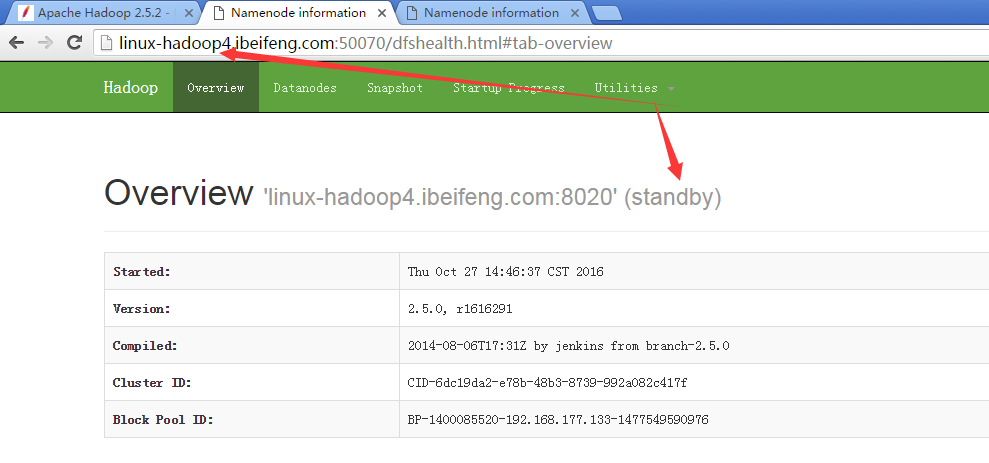
17.强制切换状态
1)、查找帮助命令,属于bin/hdfs haadmin
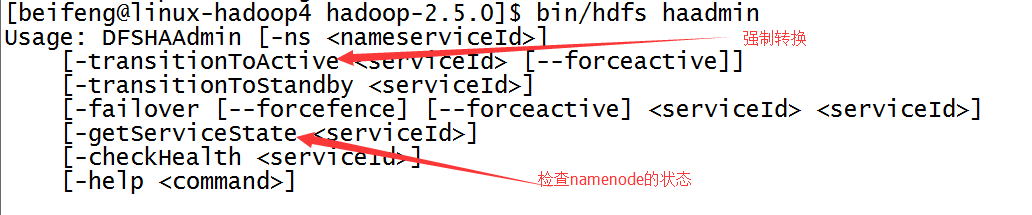
2)、具体命令

18.结果
1)、

2)、
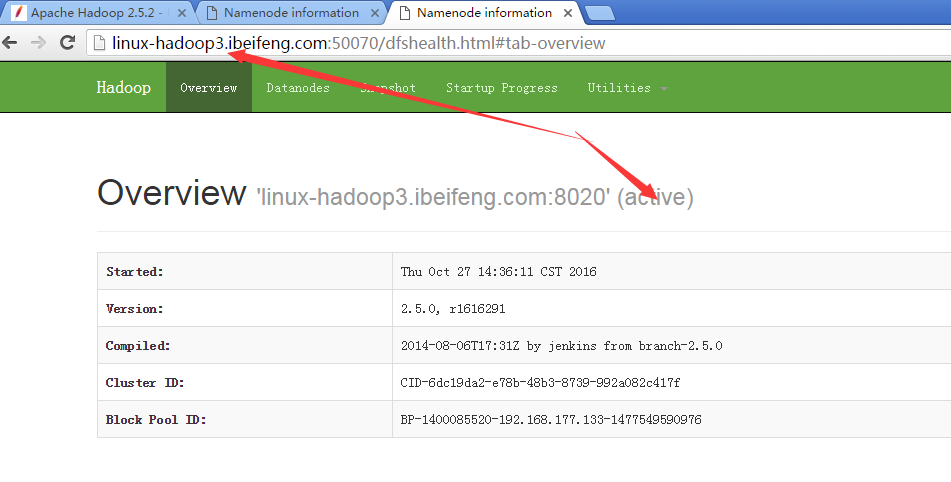
五:再次测试
19.在HDFS上新建目录并上传文件

20.杀死第一台的namenode,进行测试

21.将avtove的状态切换到第二台

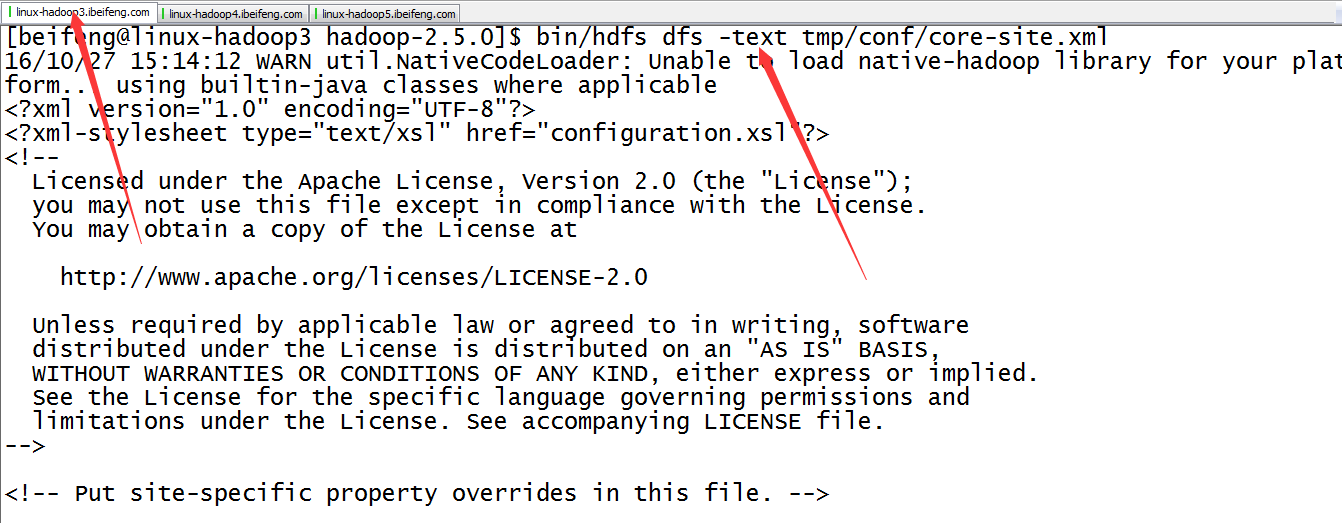
22.看第一台是否可以观看hdfs中的文件
如果可以,说明,HA发挥作用了。
因为这时proxy提供的接口变成nn2.
六:自动故障转移
前提:关闭所有的进程。
依赖:zookeeper的监控,组件为:ZKFC。
启动以后都是standby,选举一个active。
规划:
namenode namenode
ZKFC ZKFC
journalnode journalnode journalnode
datanode datanode datanode
23.配置core-site.xml
添加zookeeper的服务,包括主机名和端口号。

24.配置hdfs-site.xml
添加自动故障转移的使能。

25.分发

26.确定关闭所有的进程
这一步是开始的基础。
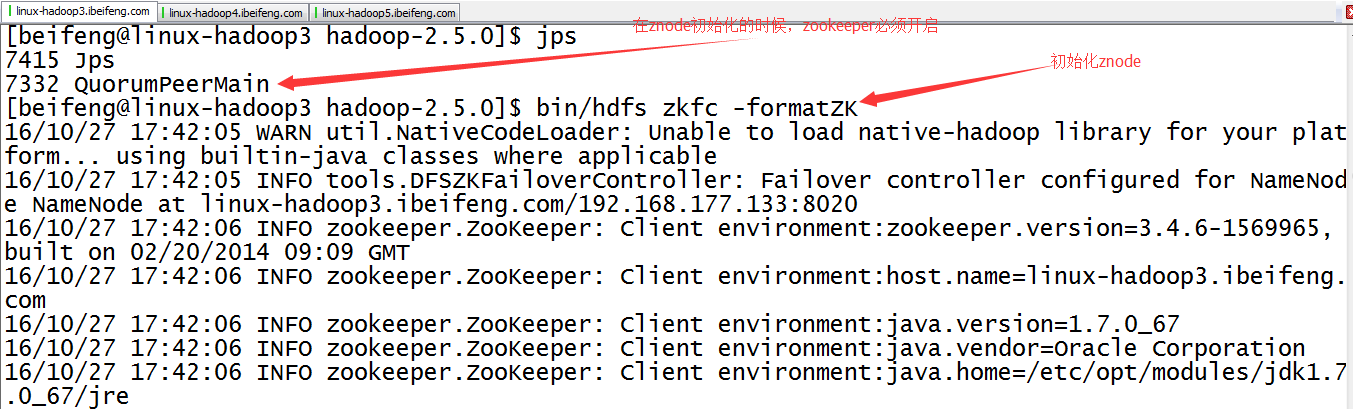
26.开启三台的zookeeper服务
先开启监控。

27.初始化HA在zookeeper中的状态bin/hdfs zkfc -formatZK
在zookepper上创建znode节点。
27.观察成功与否
进入zookeeper目录
命令:bin/zkCli.sh

28.启动sbin/start-dfs.sh
前两台虚拟机会出现DFZKFailoverController。
如果没有开启DFZKFailoverController,可以手动开启,命令是sbin/hadoop-daemon.sh start zkfc。
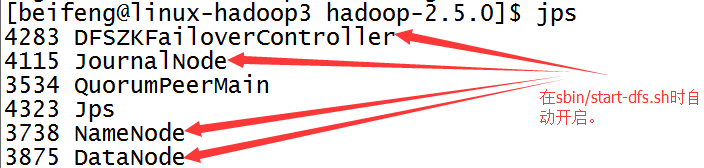
七:简单检测
29.展示前两台的虚拟机状态
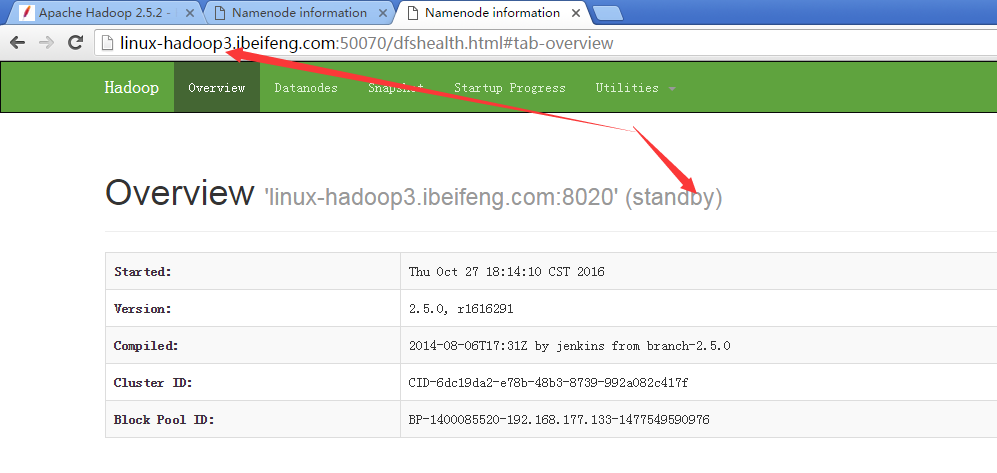
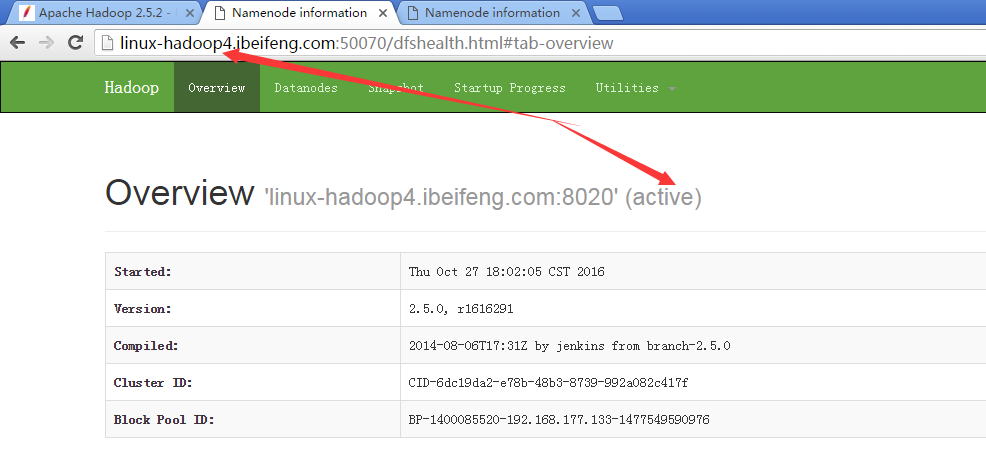
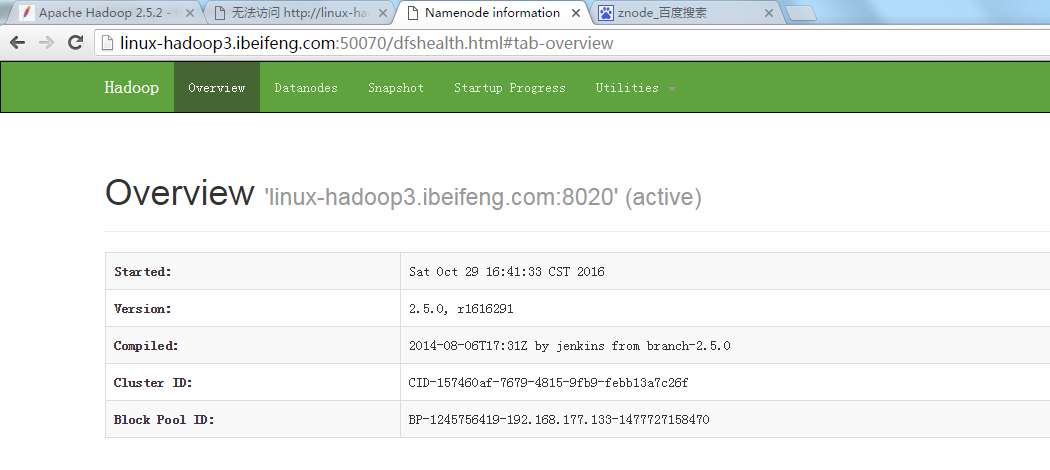
30.杀死第二台的虚拟机

31.结果
这时,第一台虚拟机变成active。
HDFS中高可用性HA的讲解的更多相关文章
- 032 HDFS中高可用性HA的讲解
HDFS Using QJM HA使用的是分布式的日志管理方式 一:概述 1.背景 如果namenode出现问题,整个HDFS集群将不能使用. 是不是可以有两个namenode呢 一个为对外服务-&g ...
- Hadoop(HDFS,YARN)的HA集群安装
搭建Hadoop的HDFS HA及YARN HA集群,基于2.7.1版本安装. 安装规划 角色规划 IP/机器名 安装软件 运行进程 namenode1 zdh-240 hadoop NameNode ...
- HDFS 和YARN HA 简介
HDFS: 基础架构 1.NameNode(Master) 1)命名空间管理:命名空间支持对HDFS中的目录.文件和块做类似文件系统的创建.修改.删除.列表文件和目录等基本操作. 2)块存储管理. 使 ...
- hue上配置HA的hdfs文件(注意,HA集群必须这样来配置才能访问hdfs文件系统)
按照正常方式配置,发现无论如何也访问不了hdfs文件系统,因为我们是HA的集群,所以不能按照如下配置 将其改为 除此之外,还需要配置hdfs文件的 接着要去hadoop的目录下启动httpfs.sh ...
- HDFS与YARN HA部署配置文件
core-site.xml <!--Yarn 需要使用 fs.defaultFS 指定NameNode URI --> <property> <name>fs.de ...
- HDFS概述(5)————HDFS HA
HA With QJM 目标 本指南概述了HDFS高可用性(HA)功能以及如何使用Quorum Journal Manager(QJM)功能配置和管理HA HDFS集群. 本文档假设读者对HDFS集群 ...
- 使用QJM构建HDFS HA架构(2.2+)
转载自:http://blog.csdn.net/a822631129/article/details/51313145 本文主要介绍HDFS HA特性,以及如何使用QJM(Quorum Journa ...
- 第6章 HDFS HA配置
目录 6.1 hdfs-site.xml文件配置 6.2 core-site.xml文件配置 6.3 启动与测试 6.4 结合ZooKeeper进行自动故障转移 在Hadoop 2.0.0之前,一个H ...
- 使用QJM实现HDFS的HA配置
使用QJM实现HDFS的HA配置 1.背景 hadoop 2.0.0之前,namenode存在单点故障问题(SPOF,single point of failure),如果主机或进程不可用时,整个集群 ...
随机推荐
- AppleWatch开发教程之Watch应用对象新增内容介绍以及编写运行代码
AppleWatch开发教程之Watch应用对象新增内容介绍以及编写运行代码 添加Watch应用对象时新增内容介绍 Watch应用对象添加到创建的项目中后,会包含两个部分:Watch App 和 Wa ...
- Javascript history pushState onpopstate方法做AJAX SEO
参考MDN: https://developer.mozilla.org/zh-CN/docs/DOM/Manipulating_the_browser_history https://develop ...
- C#可以获取Excel文件中Sheet的名字
C#可以获取Excel文件中Sheet的名字吗 C#可以获取Excel文件中Sheet的名字吗 我试过WPS的表格可以 可以 要代码么 百度都有 [深圳]Milen(99696619) 14:13: ...
- intro.js 页面引导简单用法
下载地址:http://pan.baidu.com/share/link?shareid=1894002026&uk=1829018343 <!DOCTYPE HTML PUBLIC & ...
- 【BZOJ】1043: [HAOI2008]下落的圆盘(计算几何基础+贪心)
http://www.lydsy.com/JudgeOnline/problem.php?id=1043 唯一让我不会的就是怎么求圆的周长并QAAQ... 然后发现好神!我们可以将圆弧变成$[0, 2 ...
- Linux命令总结_文件查找之grep
1.grep命令 grep一般格式为:grep [选项]基本正则表达式[文件]这里基本正则表达式可为字符串,字符串或变量应该用双引号,模式匹配用单引号 选项: -c 只输出匹配行的计数 -i 不区 ...
- IplImage 与 QImage 相互转换
在使用Qt和OpenCV编程时,对于它们各自的图像类QImage和IplImage难以避免的需要互相之间的转换,下面我们就来看它们的相互转换. 1. QImage 转换为 IplImage IplIm ...
- hdu-acm steps Max sum
/*求最大字段和,d[i]表示已 i 结尾(字段和中包含 i )在 a[1..i] 上的最大和,d[i]=(d[i-1]+a[i]>a[i])?d[i-1]+a[i]:a[i];max = {d ...
- MySQL的show语句大全
常用的MySQL show 语句列举如下: 1.show databases ; // 显示mysql中所有数据库的名称 2.show tables [from database_name]; // ...
- hdu1078 记忆化搜索
/* hdu 1078 QAQ记忆化搜索 其实还是搜索..因为里面开了一个数组这样可以省时间 (dp[x][y]大于0就不用算了直接返回值) */ #include<stdio.h> #i ...