linux2.6.24内核源代码分析(2)——扒一扒网络数据包在链路层的流向路径之一
在2.6.24内核中链路层接收网络数据包出现了两种方法,第一种是传统方法,利用中断来接收网络数据包,适用于低速设备;第二种是New Api(简称NAPI)方法,利用了中断+轮询的方法来接收网络数据包,是linux为了接收高速的网络数据包而加入的,适用于告诉设备,现在大多数NIC都兼容了这个方法。
今天我的任务是扒一扒网络数据包在传统方法也就是低速路径中如何传入链路层以及如何将其发送给上层网络层的。下面先来看看这条低速路径的简略示意图:
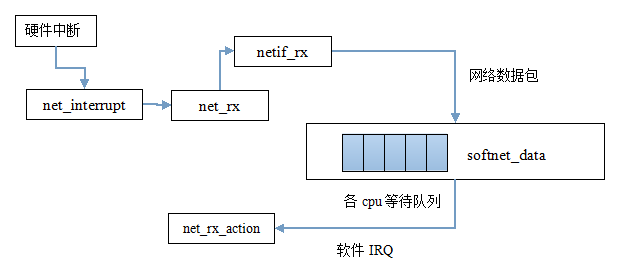
//当产生硬件中断时,此中断处理例程被调用.例程确定该中断是否是由接收到的分组引发的,如果是则调用net_rx
static irqreturn_t net_interrupt(int irq, void *dev_id)
{
struct net_device *dev = dev_id;
struct net_local *np;
int ioaddr, status;
int handled = ; ioaddr = dev->base_addr; np = netdev_priv(dev);
status = inw(ioaddr + ); if (status == )
goto out;
handled = ; if (status & RX_INTR) {
/* 调用此函数来获取数据包!!!!!! */
net_rx(dev);
}
#if TX_RING
if (status & TX_INTR) {
/* 此出代码为发送数据包的过程,我以后会扒它 */
net_tx(dev);
np->stats.tx_packets++;
netif_wake_queue(dev);
}
#endif
if (status & COUNTERS_INTR) { np->stats.tx_window_errors++;
}
out:
return IRQ_RETVAL(handled);
}
static void
net_rx(struct net_device *dev)
{
struct net_local *lp = netdev_priv(dev);
int ioaddr = dev->base_addr;
int boguscount = ; do {
int status = inw(ioaddr);
int pkt_len = inw(ioaddr); if (pkt_len == )
break; if (status & 0x40) {
lp->stats.rx_errors++;
if (status & 0x20) lp->stats.rx_frame_errors++;
if (status & 0x10) lp->stats.rx_over_errors++;
if (status & 0x08) lp->stats.rx_crc_errors++;
if (status & 0x04) lp->stats.rx_fifo_errors++;
} else { struct sk_buff *skb; lp->stats.rx_bytes+=pkt_len;
//调用dev_alloc_skb来分配一个sk_buff实例
//还记得我上一篇文章扒的这个结构体吗?
skb = dev_alloc_skb(pkt_len);
if (skb == NULL) {
printk(KERN_NOTICE "%s: Memory squeeze, dropping packet.\n",
dev->name);
lp->stats.rx_dropped++;
break;
}
//设置skb关联的网络设备
skb->dev = dev; /*将得到的数据拷贝到sk_buff的data处 */
memcpy(skb_put(skb,pkt_len), (void*)dev->rmem_start,
pkt_len); insw(ioaddr, skb->data, (pkt_len + ) >> );
//接着调用netif_rx!!!!!
netif_rx(skb);
dev->last_rx = jiffies;
lp->stats.rx_packets++;
lp->stats.rx_bytes += pkt_len;
}
} while (--boguscount); return;
}
int netif_rx(struct sk_buff *skb)
{
struct softnet_data *queue;
unsigned long flags; if (netpoll_rx(skb))
return NET_RX_DROP; if (!skb->tstamp.tv64)
net_timestamp(skb);//设置分组到达时间 /*
* The code is rearranged so that the path is the most
* short when CPU is congested, but is still operating.
*/
local_irq_save(flags);
//得到cpu的等待队列!!!!
queue = &__get_cpu_var(softnet_data);
__get_cpu_var(netdev_rx_stat).total++;
if (queue->input_pkt_queue.qlen <= netdev_max_backlog) {
if (queue->input_pkt_queue.qlen) {
enqueue:
dev_hold(skb->dev);
//将skb加到等待队列的输入队列队尾!!!!!
__skb_queue_tail(&queue->input_pkt_queue, skb);
local_irq_restore(flags);
return NET_RX_SUCCESS;
}
//NAPI调度函数,我以后将扒!
napi_schedule(&queue->backlog);
goto enqueue;
} __get_cpu_var(netdev_rx_stat).dropped++;
local_irq_restore(flags); kfree_skb(skb);
return NET_RX_DROP;
}
接下来就到了net_rx_action了

static void net_rx_action(struct softirq_action *h)
{
struct list_head *list = &__get_cpu_var(softnet_data).poll_list;
unsigned long start_time = jiffies;
int budget = netdev_budget;
void *have; local_irq_disable(); while (!list_empty(list)) {
struct napi_struct *n;
int work, weight; if (unlikely(budget <= || jiffies != start_time))
goto softnet_break; local_irq_enable(); n = list_entry(list->next, struct napi_struct, poll_list); have = netpoll_poll_lock(n); weight = n->weight; work = ;
if (test_bit(NAPI_STATE_SCHED, &n->state))
//此时poll函数指针指向默认的process_backlog!!!!重要!!!!!!!!!!!!!!!
work = n->poll(n, weight);
WARN_ON_ONCE(work > weight); budget -= work; local_irq_disable(); if (unlikely(work == weight)) {
if (unlikely(napi_disable_pending(n)))
__napi_complete(n);
else
list_move_tail(&n->poll_list, list);
} netpoll_poll_unlock(have);
}
out:
local_irq_enable(); #ifdef CONFIG_NET_DMA
/*
* There may not be any more sk_buffs coming right now, so push
* any pending DMA copies to hardware
*/
if (!cpus_empty(net_dma.channel_mask)) {
int chan_idx;
for_each_cpu_mask(chan_idx, net_dma.channel_mask) {
struct dma_chan *chan = net_dma.channels[chan_idx];
if (chan)
dma_async_memcpy_issue_pending(chan);
}
}
#endif return; softnet_break:
__get_cpu_var(netdev_rx_stat).time_squeeze++;
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
goto out;
}
如果大家不明白上面的n->poll为什么指向了process_backlog,那我们来看一下n的定义:struct napi_struct *n。关键是搞懂napi_struct结构体

结构体中的poll函数指针指向轮询函数,在传统方法(就是我今天介绍的方法)下内核将poll填写为默认的process_backlog函数而在NAPI方法下内核则会填写相应的轮询函数
static int process_backlog(struct napi_struct *napi, int quota)
{
int work = ;
//得到cpu的等待队列
struct softnet_data *queue = &__get_cpu_var(softnet_data);
unsigned long start_time = jiffies; napi->weight = weight_p;
do {
struct sk_buff *skb;
struct net_device *dev; local_irq_disable();
//在等待队列的输入队列中移除一个sk_buff!!!!!
skb = __skb_dequeue(&queue->input_pkt_queue);
if (!skb) {
__napi_complete(napi);
local_irq_enable();
break;
} local_irq_enable(); dev = skb->dev;
//调用此函数处理分组!!!!
netif_receive_skb(skb);
dev_put(dev);
} while (++work < quota && jiffies == start_time); return work;
}
int netif_receive_skb(struct sk_buff *skb)
{
struct packet_type *ptype, *pt_prev;
struct net_device *orig_dev;
int ret = NET_RX_DROP;
__be16 type; ……
……
type = skb->protocol;
list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type)&], list) {
if (ptype->type == type &&
(!ptype->dev || ptype->dev == skb->dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
} if (pt_prev) {
/*调用函数指针func将skb传送至网络层!!!
*pt_prev为packet_type指针,
*在分组传递过程中内核会根据protocol填写func,
*func被填写为向网络层传递skb的函数
*/
ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
} else {
kfree_skb(skb);
/* Jamal, now you will not able to escape explaining
* me how you were going to use this. :-)
*/
ret = NET_RX_DROP;
} out:
rcu_read_unlock();
return ret;
}
linux2.6.24内核源代码分析(2)——扒一扒网络数据包在链路层的流向路径之一的更多相关文章
- linux2.6.24内核源代码分析(1)——扒一扒sk_buff
最近研究了linux内核的网络子系统上的网络分组的接收与发送的流程,发现这个叫sk_buff的东西无处不在,内核利用了这个结构来管理分组,在各个层中传递这个结构,因此sk_buff可以说是linux内 ...
- Suse环境下编译linux-2.6.24内核
Suse环境下编译linux-2.6.24内核 1.下载linux-2.6.24内核源码: https://mirrors.edge.kernel.org/pub/linux/kernel/v2.6/ ...
- Linux内核源代码分析方法
Linux内核源代码分析方法 一.内核源代码之我见 Linux内核代码的庞大令不少人"望而生畏",也正由于如此,使得人们对Linux的了解仅处于泛泛的层次.假设想透析Linux ...
- 《LINUX3.0内核源代码分析》第二章:中断和异常 【转】
转自:http://blog.chinaunix.net/uid-25845340-id-2982887.html 摘要:第二章主要讲述linux如何处理ARM cortex A9多核处理器的中断.异 ...
- Linux内核--网络栈实现分析(六)--应用层获取数据包(上)
本文分析基于内核Linux 1.2.13 原创作品,转载请标明http://blog.csdn.net/yming0221/article/details/7541907 更多请看专栏,地址http: ...
- 捕获网络数据包并进行分析的开源库-WinPcap
什么是WinPcap WinPcap是一个基于Win32平台的,用于捕获网络数据包并进行分析的开源库. 大多数网络应用程序通过被广泛使用的操作系统元件来访问网络,比如sockets. 这是一种简单的 ...
- Linux内核中网络数据包的接收-第一部分 概念和框架
与网络数据包的发送不同,网络收包是异步的的.由于你不确定谁会在什么时候突然发一个网络包给你.因此这个网络收包逻辑事实上包括两件事:1.数据包到来后的通知2.收到通知并从数据包中获取数据这两件事发生在协 ...
- 网络数据包分析 网卡Offload
http://blog.nsfocus.net/network-packets-analysis-nic-offload/ 对于网络安全来说,网络传输数据包的捕获和分析是个基础工作,绿盟科技研 ...
- Linux内核网络数据包处理流程
Linux内核网络数据包处理流程 from kernel-4.9: 0. Linux内核网络数据包处理流程 - 网络硬件 网卡工作在物理层和数据链路层,主要由PHY/MAC芯片.Tx/Rx FIFO. ...
随机推荐
- web前端基础——jQuery编程进阶
1 jQuery本质 jQuery不是一门独立的语言,它是JavaScript的一个类库或框架.jQuery的核心思想就是:选取元素,对其操作.很多时候写jQuery代码的关键就是怎样设计合适的选择器 ...
- 题目一:一张纸的厚度大约是0.08mm,对折多少次之后能达到珠穆朗玛峰的高度(8848.13米)?
题目一:一张纸的厚度大约是0.08mm,对折多少次之后能达到珠穆朗玛峰的高度(8848.13米)? //一张纸的厚度大约是0.08mm,对折多少次之后能达到珠穆朗玛峰的高度(8848.13米 doub ...
- 在ArcGIS空间数据库中增加点数据的方法
1.新建一个mxd(ArcMAP)文件 2.从ArcCatalog中把要编辑的图层拖到ArcMAP中 3.从ArcCatalog中拖一个参照图层到ArcMAP中,比如临沂市的县级区划图 4.打开Edi ...
- Bootstrap3.0入门学习系列规划[持续更新]
详情请看http://aehyok.com/Blog/Detail/5.html 个人网站地址:aehyok.com QQ 技术群号:206058845,验证码为:aehyok 本文文章链接:http ...
- 【转】javascript运行机制之this详解
this是面向对象语言中一个重要的关键字,理解并掌握该关键字的使用对于我们代码的健壮性及优美性至关重要.而javascript的this又有区别于Java.C#等纯面向对象的语言,这使得this更加扑 ...
- mac os x用macport安装redis
一.Redis简要介绍 Redis是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语言的API.从2010年3月15日起,Redis的 ...
- android 常用类
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/38965311,本文出自[张鸿洋的博客] 打开大家手上的项目,基本都会有一大批的辅 ...
- 关于css布局的几篇文章
这可能是史上最全的CSS自适应布局总结 (http://www.cnblogs.com/qieguo/p/5421252.html) 使用 CSS 弹性框 (https://developer.moz ...
- EF 5.0 帮助类
EF 5.0 帮助类 加入命名空间: using System; using System.Data; using System.Data.Entity; using System.Data.Enti ...
- word2007无法执行语言识别
步驟1:取消“啟用自動語言檢測”在“審閱”選項卡上的“校對”組中,單擊“設置語言”(一個圖標,看起來類似於前麵帶有複選標記的地球).取消“自動檢測語言”複選框.步驟2:取消“鍵入入時檢查拚寫”到Wor ...