【原创】Kakfa message包源代码分析
public class Message implements Serializable {
private CRC32 crc;
private short magic;
private boolean codecEnabled;
private short codecClassOrdinal;
private String key;
private String body;
}
可以看出,实现的方式是非常朴素和简单的,基本上就是由一个CRC32校验码、一个magic域、2个表明压缩类的字段以及两个表明消息的键值和消息本身的字符串组成。当与源代码中的实现方式做了比较时才发现自己的实现方式实在是too simple, sometimes naive了。在Java的内存模型中,对象保存的开销其实相当大,通常都要花费至少2倍以上的空间来保存数据(甚至更糟)。另外,随着堆数据越来越大,GC的性能下降得很多,将会变得非常缓慢。
在上面的实现中JMM会为字段进行重排以减少内存使用:
public class Message implements Serializable {
private short magic;
private short codecKlassOrdinal;
private boolean codecEnabled;
private CRC32 crc;
private String key;
private String body;
}
即使是这样,上面朴素的实现仍然需要40字节,而其中有7个字节只是为了补齐(padding)。Kafka实现的方式是使用nio.ByteBuffer来保存消息,同时依赖文件系统提供的页缓存机制,而不是依靠堆缓存。毕竟通常情况下,堆上保存的对象很有可能在os的页缓存中还保存一份,造成了资源的浪费。ByteBuffer是二进制的紧凑字节结构,而不是独立的对象,因此我们至少能够访问多一倍的可用内存。按照Kafka官网的说法,在一台32GB内存的机器上,Kafka几乎能用到28~30GB的物理内存同时还不比担心GC的糟糕性能。如果使用ByteBuffer来保存同样的消息,只需要24个字节,比起纯Java堆的实现减少了40%的空间占用,好处不言而喻。这种设计的好处还有加入了扩展的可能性。下图就是Kafka中Message的实现方式:
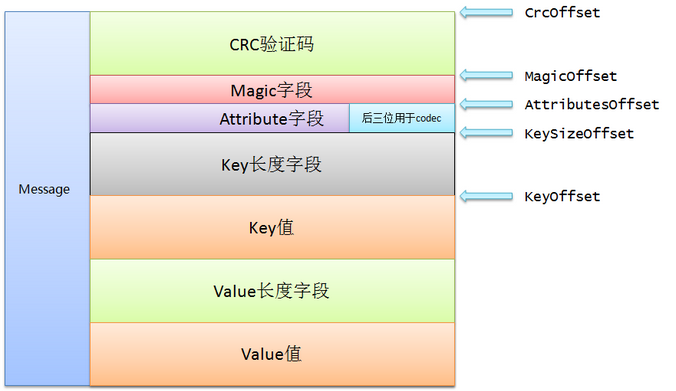
具体的域有: crc + magic + attribute + key + value,其中key + value 称为message overhead。虽然代码中起的名字都是offset,位移,但其实你可以理解为对应域在bytebuffer中的起始位移位置。由于个人是不太主张通篇把源代码贴上来的,毕竟大家都能下载到,所以这里就不全篇贴代码了。

【原创】Kakfa message包源代码分析的更多相关文章
- 【原创】Kakfa cluster包源代码分析
kafka.cluster包定义了Kafka的基本逻辑概念:broker.cluster.partition和replica——这些是最基本的概念.只有弄懂了这些概念,你才真正地使用kakfa来帮助完 ...
- 【原创】Kakfa log包源代码分析(二)
八.Log.scala 日志类,个人认为是这个包最重要的两个类之一(另一个是LogManager).以伴生对象的方式提供.先说Log object,既然是object,就定义了一些类级别的变量,比如定 ...
- 【原创】Kakfa log包源代码分析(一)
Kafka日志包是提供的是日志管理系统.主要的类是LogManager——该类负责处理所有的日志,并根据topic/partition分发日志.它还负责flush策略以及日志保存策略.Kafka日志本 ...
- 【原创】Kakfa network包源代码分析
kafka.network包主要为kafka提供网络服务,通常不包含具体的逻辑,都是一些最基本的网络服务组件.其中比较重要的是Receive.Send和Handler.Receive和Send封装了底 ...
- 【原创】Kakfa common包源代码分析
初一看common包的代码吓了一跳,这么多scala文件!后面仔细一看大部分都是Kafka自定义的Exception类,简直可以改称为kafka.exceptions包了.由于那些异常类的名称通常都定 ...
- 【原创】Kakfa api包源代码分析
既然包名是api,说明里面肯定都是一些常用的Kafka API了. 一.ApiUtils.scala 顾名思义,就是一些常见的api辅助类,定义的方法包括: 1. readShortString: 从 ...
- 【原创】Kakfa metrics包源代码分析
这个包主要是与Kafka度量相关的. 一.KafkaTimer.scala 对代码块的运行进行计时.仅提供一个方法: timer——在运行传入函数f的同时为期计时 二.KafkaMetricsConf ...
- 【原创】Kakfa serializer包源代码分析
这个包很简单,只有两个scala文件: decoder和encoder,就是提供序列化/反序列化的服务.我们一个一个说. 一.Decoder.scala 首先定义了一个trait: Decoder[T ...
- 【原创】kafka producer源代码分析
Kafka 0.8.2引入了一个用Java写的producer.下一个版本还会引入一个对等的Java版本的consumer.新的API旨在取代老的使用Scala编写的客户端API,但为了兼容性 ...
随机推荐
- CocoSocket开源下载与编写经验分享
CocoSocket分享 cocos2dx 3.1都出了,但依然没有发现与它原生的SOCKET支持,于是,这几天在家,手工撸了一个. 目前版本对IOS,ANDROID,WINDOWS支持良好.且为异步 ...
- Spring-Context之九:在bean定义中使用继承
定义bean时有个abstract属性,可以设置为true或false,默认为false. 1 2 3 4 <bean id="animal" class="Ani ...
- 消息队列-rabbitMQ
消息队列两个用处:服务间解耦,缓解压力(削峰平谷),以前用过ZMQ.狼厂内部的NMQ,现在接触了java开源的kafka和RabbitMQ.目前先不求甚解,有个大概的认识. RabbitMQ的安装和入 ...
- Redis学习笔记~是时候为Redis实现一个仓储了,RedisRepository来了
回到目录 之前写了不少关于仓储的文章,所以,自己习惯把自己叫仓储大叔,上次写的XMLRepository得到了大家的好评,也有不少朋友给我发email,进行一些知识的探讨,今天主要来实现一个Redis ...
- Redis学习笔记~关于空间换时间的查询案例
回到目录 空间与时间 空间换时间是在数据库中经常出现的术语,简单说就是把查询需要的条件进行索引的存储,然后查询时为O(1)的时间复杂度来快速获取数据,从而达到了使用空间存储来换快速的时间响应!对于re ...
- Linux初学 - head,tail,grep,sed,yum,find
head 查看文件头部 -n 指定查看行数 默认10行 tail 查看文件尾部 n 指定查看行数 默认10行 Grep 命令 用法大全 . 参数: -I :忽略大小写 -c :打印匹配的行数 -l : ...
- AngularJS快速入门01-基础
记得第一次听说AngularJS这项很赞的Web的前端技术,那时还是2014年,年中时我们我的一个大牛兄弟当时去面试时,被问到了是否熟悉该技术,当时他了解和使用的技术比较多.我们询问他面试情况时,他给 ...
- Nodejs从有门道无门菜鸟起飞教程。
这是一篇菜鸟教程,这是一篇菜鸟教程,如果你是菜鸟到话. 简单来说Nodejs并不是一门新的语言,但是它可以让我们的JS运行在服务器端,在服务器端写JS代码并且输入输出,也就是说以后要是有人问你JS是不 ...
- CSS实现水平垂直同时居中的5种思路
× 目录 [1]水平对齐+行高 [2]水平+垂直对齐 [3]margin+垂直对齐[4]absolute[5]flex 前面的话 水平居中和垂直居中已经单独介绍过,本文将介绍水平垂直同时居中的5种思路 ...
- Android属性动画之ObjectAnimator
相信对于Android初学者,对于Android中的动画效果一定很感兴趣,今天为大家总结一下刚刚学到的属性动画案例. 首先和一般的Android应用一样,我们先建一个工程,为了方便,我们的布局文件中就 ...