[原] KVM虚拟机网络闪断分析
背景
公司云平台的机器时常会发生网络闪断,通常在10s-100s之间。
异常情况
VM出现问题时,表现出来的情况是外部监控系统无法访问,猜测可能是由于系统假死,OVS链路问题等等。但是在出现网络问题的时候,HV统一的表现为iowait较高。
排除过程
这是一个艰难的过程,由于无法重现现场,导致只能通过一些理论手段来推测原因。
确定是否是网络原因
闪断是否由OVS造成?
在对OVS做了一段时间的压力测试后,发现并未出现网络闪断的现象,这里的压测单纯只针对OVS,压测一段时间后并未发现有异常,初步排除因OVS引起的网络问题,但是不能完全排除。是否是virtio引起的?
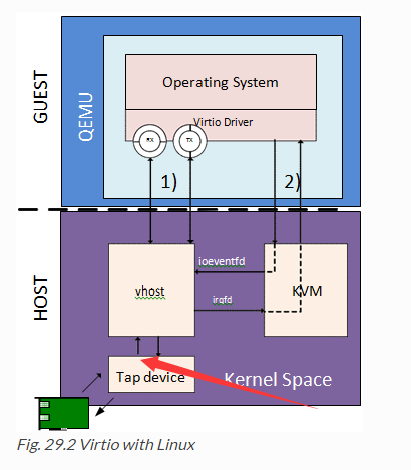
为此,我还分析了一下QEMU与VM virtio与tap之间的数据交互过程.
以下是我分析virtio与tap可能导致闪断的原因的原文
背景
最近研究了下kvm的io虚拟化,结合线上环境下,我初步认定网络丢包不是OVS导致的,应该是 vhost-net 与 tap interfaces 传输阶段导致的丢包。
证实理由
2016-03-30 18:12:39 宿主机 ip-10-21-176-234.ds.yyclouds.com 上10.25.129.117 出现过网络闪断
在宿主机上查看丢包情况:(其他vm也有相应的丢包,不过tapac3c8c7d-43网卡特别突出)
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
qbrac3c8c7d-43 1500 0 161057 0 0 0 8 0 0 0 BMRU
qvbac3c8c7d-43 1500 0 8708405804 0 432 0 11426577032 0 0 0 BMPRU
qvoac3c8c7d-43 1500 0 11426577032 0 0 0 8708405804 0 216 0 BMPRU
tapac3c8c7d-43 1500 0 11426582924 0 0 0 8707387025 0 1012779 0 BMRU
发现tapac3c8c7d-43 出现过较多丢包(TX-DRP=1012779)
tap MAC信息
tapac3c8c7d-43 Link encap:Ethernet HWaddr fe:16:3e:09:53:5e
inet6 addr: fe80::fc16:3eff:fe09:535e/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:11429067595 errors:0 dropped:0 overruns:0 frame:0
TX packets:8709318110 errors:0 dropped:1012779 overruns:0 carrier:0
collisions:0 txqueuelen:500
RX bytes:2695286604414 (2.6 TB) TX bytes:1171426033029 (1.1 TB)
VM eth0 MAC信息
eth0 Link encap:Ethernet HWaddr FA:16:3E:09:53:5E
inet addr:10.25.129.117 Bcast:10.25.131.255 Mask:255.255.252.0
inet6 addr: fe80::f816:3eff:fe09:535e/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:8709294638 errors:0 dropped:0 overruns:0 frame:0
TX packets:11429037291 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1171422605901 (1.0 TiB) TX bytes:2695279473603 (2.4 TiB)
宿主机上的tap 就是 虚拟机eth0 网卡. 其对应的mac地址一样,且eth0网卡没有统计到丢包,而tap统计到丢包, 这是因为virtio-vhostnet是异步的,vm并不知道数据丢失。这里是最重要的判断依据
neutron 计算节点虚拟网卡结构图
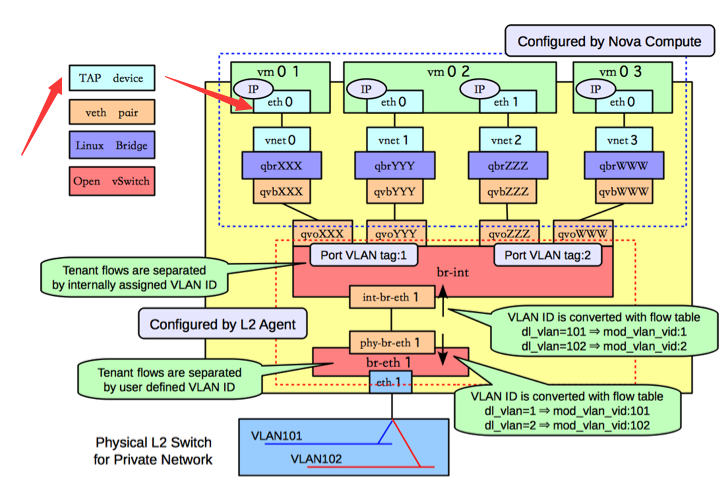
结合vhost-net数据流程,可以看到tap TX对应到的是tap发送数据到vhost-net的过程。(下图的tun与vhost-net之间)
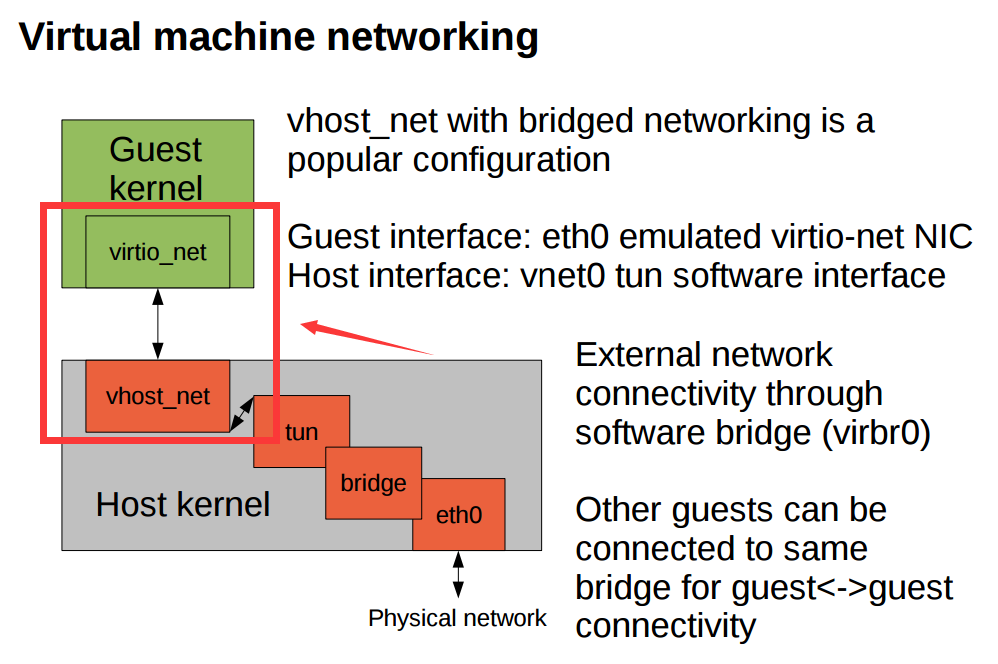
可能导致丢包的原因
TX-DROP 丢包,怀疑是系统负载增加时,vhost-net处理不过来, 导致tap tx 队列满以至发送drop.
可能的解决方案
增加tap tx队列,目前队列为 500, 增加为1000
参考
tap丢包现象
Neutron计算节点网络架构
KVM Troubleshooting
Vhost overview
经过实际分析,然而实际情况并不是这样的
当时在考虑是否将虚拟机的多队列打开,这样就不会出现某一个vCPU在处理virtio event事件的时候(类似于软中断处理)无法响应的情况.
为什么不是tap queue队列导致?
发现网络闪断的机器丢包数达到1012779,发生在大概20s的时间内,也就是说,即使队列增加到5000,也会出现丢包,根本原因不在队列大小。之下而上的排查,是否是vm内部导致?
在打开了VM的内核日志后,发现闪断时候都会出现如下堆栈信息:
Apr 22 20:17:01 snapshot kernel: BUG: soft lockup - CPU#9 stuck for 67s! [mongod:58233]
Apr 22 20:17:01 snapshot kernel: [<ffffffff81052268>] ? flush_tlb_others_ipi+0x128/0x130
Apr 22 20:17:01 snapshot kernel: [<ffffffff810522e6>] ? native_flush_tlb_others+0x76/0x90
Apr 22 20:17:01 snapshot kernel: [<ffffffff8105240e>] ? flush_tlb_page+0x5e/0xb0
Apr 22 20:17:01 snapshot kernel: [<ffffffff8114e467>] ? do_wp_page+0x2f7/0x920
Apr 22 20:17:01 snapshot kernel: [<ffffffff8114eef9>] ? __do_fault+0x469/0x530
Apr 22 20:17:01 snapshot kernel: [<ffffffff8114f28d>] ? handle_pte_fault+0x2cd/0xb00
Apr 22 20:17:01 snapshot kernel: [<ffffffff81169e19>] ? alloc_page_interleave+0x89/0x90
Apr 22 20:17:01 snapshot kernel: [<ffffffff810516b7>] ? pte_alloc_one+0x37/0x50
Apr 22 20:17:01 snapshot kernel: [<ffffffff8114fcea>] ? handle_mm_fault+0x22a/0x300
Apr 22 20:17:01 snapshot kernel: [<ffffffff8104d0d8>] ? __do_page_fault+0x138/0x480
Apr 22 20:17:01 snapshot kernel: [<ffffffff8144a21b>] ? sys_recvfrom+0x16b/0x180
Apr 22 20:17:01 snapshot kernel: [<ffffffff81041e98>] ? pvclock_clocksource_read+0x58/0xd0
Apr 22 20:17:01 snapshot kernel: [<ffffffff81040f2c>] ? kvm_clock_read+0x1c/0x20
Apr 22 20:17:01 snapshot kernel: [<ffffffff81040f39>] ? kvm_clock_get_cycles+0x9/0x10
Apr 22 20:17:01 snapshot kernel: [<ffffffff810a9af7>] ? getnstimeofday+0x57/0xe0
Apr 22 20:17:01 snapshot kernel: [<ffffffff8152ffde>] ? do_page_fault+0x3e/0xa0
Apr 22 20:17:01 snapshot kernel: [<ffffffff8152d395>] ? page_fault+0x25/0x30
看到,大部分情况下,是由于mongod进程引起,偶尔会有其他进程。
让我们来回忆(了解)下Mongodb的存储原理
Mongodb 使用到了系统的 mmap 系统调用来完成进程内部的内存与磁盘的关联,在一个比较大的操作的时候,比如扫表,会出现物理内存不够用的情况,这个时候会mmap出来的内存会频繁的产生内存与磁盘之间的交换,具体表现为产生很多的缺页中断。
好了,到这里,慢慢的有点眉目了,大概情况是由于vCPU soft lockup导致。
为什么cpu lockup 会导致网络闪断?
先说说cpu soft lockup, 在内核调度的过程中,会对每一个调度的cpu的当前进程的上下文做一个时间戳,有一个watchdog会用来reporting这个时间戳,当进程被调度出去后,watch dog发现cpu的时间戳时间大于配置时间,比如10s,就会记录这个soft lockup。
那就是说,这个概率事件发生在,当前的lockup的cpu,正好是处理virtio event的cpu,此时网络发生中断,外部系统无法访问。是什么原因导致了 cpu soft lockup ?
首先简要的了解下缺页中断,以及tlb
堆栈请从下往上看,谢谢.
[] ? page_fault+0x25/0x30 访问到了一个不在tlb表记录的内存?怎么办,产生一个缺页中断
[] ? do_page_fault+0x3e/0xa0 中断处理过程
[] ? kvm_clock_read+0x1c/0x20 // 以下步骤为获取时间戳
[] ? kvm_clock_get_cycles+0x9/0x10
[] ? getnstimeofday+0x57/0xe0
算了,让我们直接跳到最后吧
[] ? flush_tlb_others_ipi+0x128/0x130
[] ? native_flush_tlb_others+0x76/0x90
[] ? flush_tlb_page+0x5e/0xb0
[] ? do_wp_page+0x2f7/0x920
[] ? __do_fault+0x469/0x530
[] ? handle_pte_fault+0x2cd/0xb00
在完成了缺页中断处理后,系统要做的工作是刷新TLB表,这里不仅要刷新自己当前CPU的TLB,还要刷新其他CPU的TLB。
[] ? flush_tlb_others_ipi+0x128/0x130 系统调用,会向其他CPU发送(ipi) Inter-processor interrupt

在通过CPU 核间中断(ipi)通知其他CPU的时候,会不断的阻塞等待其他CPU完成flush操作,主要体现在cpu_relax()函数阻塞。
在虚拟化环境中,有可能在发送ipi的时候,其他的vCPU(体现在HV就是一个线程)被调度,此时的vCPU不处于online模式,不会对此ipi做中断响应,于是发起ipi的vCPU就会阻塞。
此BUG后来在3.2.7后被reporting,后面的版本修复。

加上了对是否vCPU online的判断。 所以对于此soft lockup事件,我们建议使用3.2.7版本以后的内核。
总结
KVM环境下,VM请使用3.2.7以后版本的内核,呵呵哒
[原] KVM虚拟机网络闪断分析的更多相关文章
- KVM虚拟机网络闪断分析
https://www.cnblogs.com/Bozh/p/5484838.html 背景 公司云平台的机器时常会发生网络闪断,通常在10s-100s之间. 异常情况 VM出现问题时,表现出来的情况 ...
- CentOS 6.9下KVM虚拟机网络Bridge(网桥)方式与NAT方式详解(转)
摘要:KVM虚拟机网络配置的两种方式:NAT方式和Bridge方式.Bridge方式的配置原理和步骤.Bridge方式适用于服务器主机的虚拟化.NAT方式适用于桌面主机的虚拟化. NAT的网络结构图: ...
- 故障分析:网络闪断引发的ServiceStack.Redis死锁问题
背景说明 某天生产环境发生进程的活跃线程数过高的预警问题,且一天两个节点分别出现相同预警.此程序近一年没出现过此类预警,事出必有因,本文就记录下此次根因分析的过程. 监控看到的线程数变化情况: 初步的 ...
- KVM虚拟机网络
某一天,我的QEMU/KVM虚拟机在打开的时候,出现了以下错误: 查看default配置状态(命令是sudo virsh net-list -all,注意sudo,管理员用户登录的当我没说): 上图是 ...
- KVM虚拟机网络基础及优化说明
一个完整的数据包从虚拟机到物理机的路径是: 虚拟机--QEMU虚拟网卡--虚拟化层--内核网桥--物理网卡 KVM的网络优化方案,总的来说,就是让虚拟机访问物理网卡的层数更少,直至对物理网卡的单独占领 ...
- KVM虚拟机网络配置 Bridge方式,NAT方式
https://blog.csdn.net/hzhsan/article/details/44098537/
- [云上天气预报-有时有闪电]2月3日23:00-4:00阿里云SLB升级期间网络会闪断
大家好,2月3日23:00-2月4日4:00,阿里云将对SLB(负载均衡)进行升级,在升级期间,SLB会有约4-8次的网络闪断.由此给您带来麻烦,望谅解! 阿里云官方公告内容如下: 尊敬的用户: 您好 ...
- [原] KVM 虚拟化原理探究(5)— 网络IO虚拟化
KVM 虚拟化原理探究(5)- 网络IO虚拟化 标签(空格分隔): KVM IO 虚拟化简介 前面的文章介绍了KVM的启动过程,CPU虚拟化,内存虚拟化原理.作为一个完整的风诺依曼计算机系统,必然有输 ...
- [原]CentOS7.2部署KVM虚拟机
前段时间学习了关于PostGis.OSM数据以及Mapnik相关内容,接下来将利用假期重点学习PostgreSQL-XL和瓦片服务器集群技术,因此先把环境搭好.计划采用KVM来充分利用家里不太宽裕的“ ...
随机推荐
- 【.net 深呼吸】细说CodeDom(3):命名空间
在上一篇文章中,老周介绍了表达式和语句,尽管老周没有把所有的内容都讲一遍,但相信大伙至少已经掌握基本用法.在本文中,咱们继续探讨 CodeDom 方面的奥秘,这一次咱们聊聊命名空间. 在开始之前,老周 ...
- 完美判断iframe是否加载完成
var iframe = document.createElement("iframe"); iframe.style.width = "265px"; ifr ...
- shell变量
定义变量 定义变量时,变量名不加美元符号($),如: variableName="value" 注意,变量名和等号之间不能有空格,这可能和你熟悉的所有编程语言都不一样.同时,变量名 ...
- Android Ormlite 学习笔记2 -- 主外键关系
以上一篇为例子,进行主外键的查询 定义Users.java 和 Role.java Users -- Role 关系为:1对1 即父表关系 Role -- Users 关系为:1对多 即子表关系 下面 ...
- MAC Osx PHP安装指导
php.ini的位置 Mac OS X中没有默认的php.ini文件,但是有对应的模版文件php.ini.default,位于/private/etc/php.ini.default 或者说 /etc ...
- node中子进程同步输出
管道 通过"child_process"模块fork出来的子进程都是返回一个ChildProcess对象实例,ChildProcess类比较特殊无法手动创建该对象实例,只能使用fo ...
- trigger事件模拟
事件模拟trigger 在操作DOM元素中,大多数事件都是用户必须操作才会触发事件,但有时,需要模拟用户的操作,来达到效果. 需求:页面初始化时触发搜索事件并获取input控件值,并打印输出(效果图如 ...
- SNMP简单网络管理协议
声明:以下内容是学习谌玺老师视频整理出来(http://edu.51cto.com/course/course_id-861.html) SNMP(Simple Network Management ...
- Android事件分发机制浅谈(一)
---恢复内容开始--- 一.是什么 我们首先要了解什么是事件分发,通俗的讲就是,当一个触摸事件发生的时候,从一个窗口到一个视图,再到一个视图,直至被消费的过程. 二.做什么 在深入学习android ...
- charles工具抓包教程(http跟https)
1.下载charles 可以去charles官网下载,下载地址:http://www.charlesproxy.com/download/ 根据自己的操作系统下载对应的版本,然后进行安装,然后打 ...