Java实现敏感词过滤
敏感词、文字过滤是一个网站必不可少的功能,如何设计一个好的、高效的过滤算法是非常有必要的。前段时间我一个朋友(马上毕业,接触编程不久)要我帮他看一个文字过滤的东西,它说检索效率非常慢。我把它程序拿过来一看,整个过程如下:读取敏感词库、如果HashSet集合中,获取页面上传文字,然后进行匹配。我就想这个过程肯定是非常慢的。对于他这个没有接触的人来说我想也只能想到这个,更高级点就是正则表达式。但是非常遗憾,这两种方法都是不可行的。当然,在我意识里没有我也没有认知到那个算法可以解决问题,但是Google知道!
DFA简介
在实现文字过滤的算法中,DFA是唯一比较好的实现算法。DFA即Deterministic Finite Automaton,也就是确定有穷自动机,它是是通过event和当前的state得到下一个state,即event+state=nextstate。下图展示了其状态的转换

在这幅图中大写字母(S、U、V、Q)都是状态,小写字母a、b为动作。通过上图我们可以看到如下关系
a b b
S -----> U S -----> V U -----> V
在实现敏感词过滤的算法中,我们必须要减少运算,而DFA在DFA算法中几乎没有什么计算,有的只是状态的转换。
参考文献:http://www.iteye.com/topic/336577
Java实现DFA算法实现敏感词过滤
在Java中实现敏感词过滤的关键就是DFA算法的实现。首先我们对上图进行剖析。在这过程中我们认为下面这种结构会更加清晰明了。

同时这里没有状态转换,没有动作,有的只是Query(查找)。我们可以认为,通过S query U、V,通过U query V、P,通过V query U P。通过这样的转变我们可以将状态的转换转变为使用Java集合的查找。
诚然,加入在我们的敏感词库中存在如下几个敏感词:日本人、日本鬼子、毛.泽.东。那么我需要构建成一个什么样的结构呢?
首先:query 日 ---> {本}、query 本 --->{人、鬼子}、query 人 --->{null}、query 鬼 ---> {子}。形如下结构:
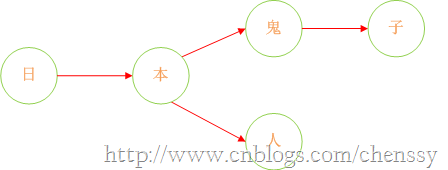
下面我们在对这图进行扩展:
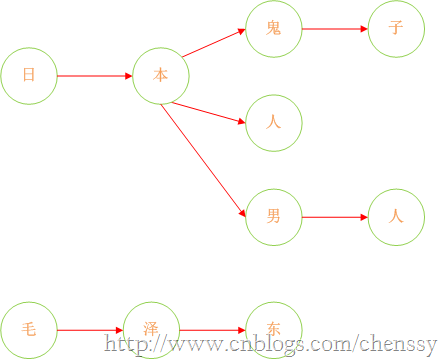
这样我们就将我们的敏感词库构建成了一个类似与一颗一颗的树,这样我们判断一个词是否为敏感词时就大大减少了检索的匹配范围。比如我们要判断日本人,根据第一个字我们就可以确认需要检索的是那棵树,然后再在这棵树中进行检索。
但是如何来判断一个敏感词已经结束了呢?利用标识位来判断。
所以对于这个关键是如何来构建一棵棵这样的敏感词树。下面我已Java中的HashMap为例来实现DFA算法。具体过程如下:
日本人,日本鬼子为例
1、在hashMap中查询“日”看其是否在hashMap中存在,如果不存在,则证明已“日”开头的敏感词还不存在,则我们直接构建这样的一棵树。
跳至3。
2、如果在hashMap中查找到了,表明存在以“日”开头的敏感词,设置hashMap = hashMap.get("日"),跳至1,依次匹配“本”、“人”。
3、判断该字是否为该词中的最后一个字。若是表示敏感词结束,设置标志位isEnd = 1,否则设置标志位isEnd = 0;

程序实现如下:
/**
* 读取敏感词库,将敏感词放入HashSet中,构建一个DFA算法模型:<br>
* 中 = {
* isEnd = 0
* 国 = {<br>
* isEnd = 1
* 人 = {isEnd = 0
* 民 = {isEnd = 1}
* }
* 男 = {
* isEnd = 0
* 人 = {
* isEnd = 1
* }
* }
* }
* }
* 五 = {
* isEnd = 0
* 星 = {
* isEnd = 0
* 红 = {
* isEnd = 0
* 旗 = {
* isEnd = 1
* }
* }
* }
* }
* @author chenming
* @date 2014年4月20日 下午3:04:20
* @param keyWordSet 敏感词库
* @version 1.0
*/
@SuppressWarnings({ "rawtypes", "unchecked" })
private void addSensitiveWordToHashMap(Set<String> keyWordSet) {
sensitiveWordMap = new HashMap(keyWordSet.size()); //初始化敏感词容器,减少扩容操作
String key = null;
Map nowMap = null;
Map<String, String> newWorMap = null;
//迭代keyWordSet
Iterator<String> iterator = keyWordSet.iterator();
while(iterator.hasNext()){
key = iterator.next(); //关键字
nowMap = sensitiveWordMap;
for(int i = 0 ; i < key.length() ; i++){
char keyChar = key.charAt(i); //转换成char型
Object wordMap = nowMap.get(keyChar); //获取<span style="color: rgb(0,0,255)">if</span>(wordMap != <span style="color: rgb(0,0,255)">null</span>){ <span style="color: rgb(0,128,0)">//</span><span style="color: rgb(0,128,0)">如果存在该key,直接赋值</span>
nowMap =<span style="color: rgb(0,0,0)"> (Map) wordMap;
}
</span><span style="color: rgb(0,0,255)">else</span>{ <span style="color: rgb(0,128,0)">//</span><span style="color: rgb(0,128,0)">不存在则,则构建一个map,同时将isEnd设置为0,因为他不是最后一个</span>
newWorMap = <span style="color: rgb(0,0,255)">new</span> HashMap<String,String><span style="color: rgb(0,0,0)">();
newWorMap.put(</span>"isEnd", "0"); <span style="color: rgb(0,128,0)">//</span><span style="color: rgb(0,128,0)">不是最后一个</span>
nowMap.put(keyChar, newWorMap);
nowMap = newWorMap;
}</span><span style="color: rgb(0,0,255)">if</span>(i == key.length() - 1<span style="color: rgb(0,0,0)">){
nowMap.put(</span>"isEnd", "1"); <span style="color: rgb(0,128,0)">//</span><span style="color: rgb(0,128,0)">最后一个</span>
}
}
}
}
运行得到的hashMap结构如下:
{五={星={红={isEnd=0, 旗={isEnd=1}}, isEnd=0}, isEnd=0}, 中={isEnd=0, 国={isEnd=0, 人={isEnd=1}, 男={isEnd=0, 人={isEnd=1}}}}}
敏感词库我们一个简单的方法给实现了,那么如何实现检索呢?检索过程无非就是hashMap的get实现,找到就证明该词为敏感词,否则不为敏感词。过程如下:假如我们匹配“中国人民万岁”。
1、第一个字“中”,我们在hashMap中可以找到。得到一个新的map = hashMap.get("")。
2、如果map == null,则不是敏感词。否则跳至3
3、获取map中的isEnd,通过isEnd是否等于1来判断该词是否为最后一个。如果isEnd == 1表示该词为敏感词,否则跳至1。
通过这个步骤我们可以判断“中国人民”为敏感词,但是如果我们输入“中国女人”则不是敏感词了。
/**
* 检查文字中是否包含敏感字符,检查规则如下:<br>
* @author chenming
* @date 2014年4月20日 下午4:31:03
* @param txt
* @param beginIndex
* @param matchType
* @return,如果存在,则返回敏感词字符的长度,不存在返回0
* @version 1.0
*/
@SuppressWarnings({ "rawtypes"})
public int CheckSensitiveWord(String txt,int beginIndex,int matchType){
boolean flag = false; //敏感词结束标识位:用于敏感词只有1位的情况
int matchFlag = 0; //匹配标识数默认为0
char word = 0;
Map nowMap = sensitiveWordMap;
for(int i = beginIndex; i < txt.length() ; i++){
word = txt.charAt(i);
nowMap = (Map) nowMap.get(word); //获取指定key
if(nowMap != null){ //存在,则判断是否为最后一个
matchFlag++; //找到相应key,匹配标识+1
if("1".equals(nowMap.get("isEnd"))){ //如果为最后一个匹配规则,结束循环,返回匹配标识数
flag = true; //结束标志位为true
if(SensitivewordFilter.minMatchTYpe == matchType){ //最小规则,直接返回,最大规则还需继续查找
break;
}
}
}
else{ //不存在,直接返回
break;
}
}
if(matchFlag < 2 && !flag){
matchFlag = 0;
}
return matchFlag;
}
在文章末尾我提供了利用Java实现敏感词过滤的文件下载。下面是一个测试类来证明这个算法的效率和可靠性。
public static void main(String[] args) {
SensitivewordFilter filter = new SensitivewordFilter();
System.out.println("敏感词的数量:" + filter.sensitiveWordMap.size());
String string = "太多的伤感情怀也许只局限于饲养基地 荧幕中的情节,主人公尝试着去用某种方式渐渐的很潇洒地释自杀指南怀那些自己经历的伤感。"
+ "然后法.轮.功 我们的扮演的角色就是跟随着主人公的喜红客联盟 怒哀乐而过于牵强的把自己的情感也附加于银幕情节中,然后感动就流泪,"
+ "难过就躺在某一个人的怀里尽情的阐述心扉或者手机卡复制器一个人一杯红酒一部电影在夜三.级.片 深人静的晚上,关上电话静静的发呆着。";
System.out.println("待检测语句字数:" + string.length());
long beginTime = System.currentTimeMillis();
Set<String> set = filter.getSensitiveWord(string, 1);
long endTime = System.currentTimeMillis();
System.out.println("语句中包含敏感词的个数为:" + set.size() + "。包含:" + set);
System.out.println("总共消耗时间为:" + (endTime - beginTime));
}
运行结果:

从上面的结果可以看出,敏感词库有771个,检测语句长度为184个字符,查出6个敏感词。总共耗时1毫秒。可见速度还是非常可观的。
下面提供两个文档下载:
Desktop.rar(http://pan.baidu.com/s/1o66teGU)里面包含两个Java文件,一个是读取敏感词库(SensitiveWordInit),一个是敏感词工具类(SensitivewordFilter),里面包含了判断是否存在敏感词(isContaintSensitiveWord(String txt,int matchType))、获取敏感词(getSensitiveWord(String txt , int matchType))、敏感词替代(replaceSensitiveWord(String txt,int matchType,String replaceChar))三个方法。
敏感词库:http://pan.baidu.com/s/1pJoGhVP
申明:本文中的敏感词全部都是用于测试
Java实现敏感词过滤的更多相关文章
- Java实现敏感词过滤(转)
敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有必要的.前段时间我一个朋友(马上毕业,接触编程不久)要我帮他看一个文字过滤的东西,它说检索效率非常慢.我把它程序拿过来 ...
- Java实现敏感词过滤 - IKAnalyzer中文分词工具
IKAnalyzer 是一个开源的,基于java语言开发的轻量级的中文分词工具包. 官网: https://code.google.com/archive/p/ik-analyzer/ 本用例借助 I ...
- Java实现敏感词过滤 - DFA算法
Java实现DFA算法进行敏感词过滤 封装工具类如下: 使用前需对敏感词库进行初始化: SensitiveWordUtil.init(sensitiveWordSet); package cn.swf ...
- 转:Java实现敏感词过滤
敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有必要的.前段时间我一个朋友(马上毕业,接触编程不久)要我帮他看一个文字过滤的东西,它说检索效率非常慢.我把它程序拿过来 ...
- java实现敏感词过滤(DFA算法)
小Alan在最近的开发中遇到了敏感词过滤,便去网上查阅了很多敏感词过滤的资料,在这里也和大家分享一下自己的理解. 敏感词过滤应该是不用给大家过多的解释吧?讲白了就是你在项目中输入某些字(比如输入xxo ...
- Java实现敏感词过滤代码
原文:http://www.open-open.com/code/view/1445762764148 import java.io.BufferedReader; import java.io.Fi ...
- java类敏感词过滤类
package com.fpx.pcs.prealert.process.service.impl; import java.util.HashMap;import java.util.HashSet ...
- 敏感词过滤的算法原理之DFA算法
参考文档 http://blog.csdn.net/chenssy/article/details/26961957 敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有 ...
- java敏感词过滤
敏感词过滤在网站开发必不可少.一般用DFA,这种比较好的算法实现的. 参考链接:http://cmsblogs.com/?p=1031 一个比较好的代码实现: import java.io.IOExc ...
随机推荐
- C# System.Timers.Timer的一些小问题?
比如设置间隔时间是 1000msSystem.Timers.Timer mytimer = new System.Timers.Timer(1000);问题若响应函数执行的时间超过了 1000 ms, ...
- java连接Oracle数据库
Oracle数据库先创建一个表和添加一些数据 1.先在Oracle数据库中创建一个student表: create table student ( id ) not null primary key, ...
- nginx搭建高性能流媒体技术
一. 系统环境 系统版本: CentOS 5.8x86_64 Nginx版本: Nginx-1.4.2.tar.gz Yamdi版本:Yamdi-1.9.tar.gz 二. 自动化安装 #!/bin/ ...
- C/C++编译链接过程详解
有些人写C/C++(以下假定为C++)程序,对unresolved external link或者duplicated external simbol的错误信息不知所措(因为这样的错误信息不能定位到某 ...
- img 是内联元素
图片是内联元素 ,同时是内联替换元素(替换元素是能设置宽和高的) 取消图片的magin display:block;(一般初始化标签中会把图片设置成块状) replaced element <i ...
- android开源系列之——xUtils 开源库
http://blog.csdn.net/lijunhuayc/article/details/40585607
- Python 类的命名空间
Python中类的定义其实就是执行代码块: class cc: a=0 print '+++++', print a 会直接执行print语句而不是在实例化cc时执行.执行后会生成对应的类的命名空间. ...
- 【Thinking in Java】Java Callable的使用
Callable<>和Runable类似,都是用于Java的并发执行. 唯一的区别是,Runable的run方法的返回是void,而Callable的call方法是有返回值的. call方 ...
- React的Diff算法
使用React或者RN开发APP如果不知道Diff算法的话简直是说不过去啊.毕竟"知其然,知其所以然"这句老话从远古喊到现代了. 以下内容基本是官网文章的一个总结.压缩.这次要谦虚 ...
- uva-327
题意:给出一个C语言加减法表达式,求出这个表达式的最终结构,以及各个变量的值,每个变量保证至出现一次,保证输入的字符串合法: 输入:一串包含+.-和小写的26个英文字母: 输出:表达式的结果,以及表达 ...