SQL Server SQL性能优化之--pivot行列转换减少扫描计数优化查询语句
原文出处:http://www.cnblogs.com/wy123/p/5933734.html
先看常用的一种表结构设计方式:
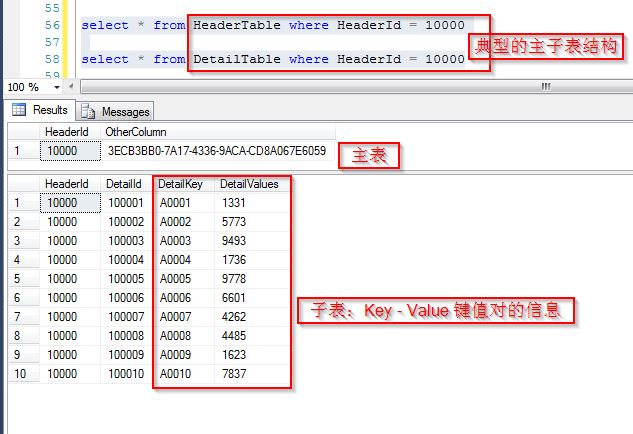
那么可能会遇到一种典型的查询方式,主子表关联,查询子表中的某些(或者全部)Key点对应的Value,横向显示(也即以行的方式显示)

这种查询方式很明显的一个却显示多次对字表查询(暂时抛开索引)
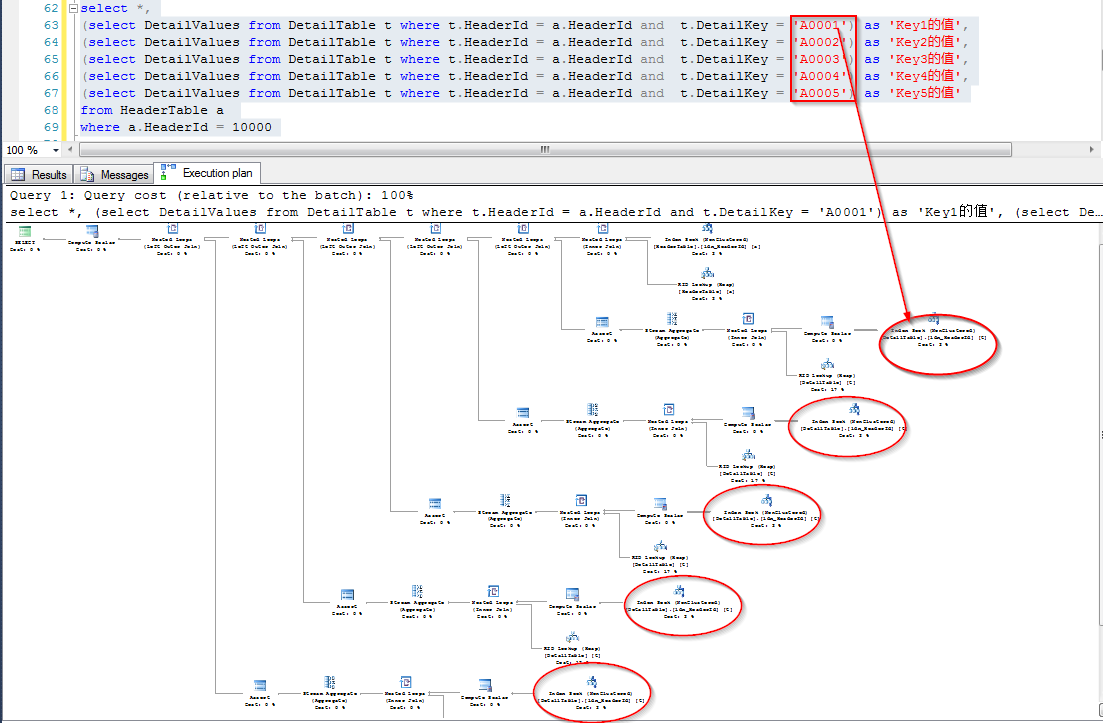
相比这种查询方式很多人都遇到过,如果子表是配置信息之类的小表的话,问题不大,如果字表数据量较大,可能就会有影响了。
这个查询目的是将”纵表”存储的结果“横向”显示,相当于横列转换的感觉了。
可以将子表的结果一次性将纵表的结果转换成横标,再跟主表连接,
然后得到一个最终一样的查询结果(格式),就能够减少子表的查询次数
这里将子表的结果“一次性将纵表的结果转换成横标”,是典型的行列转换操作
首先先看一下这里所说的一次转换成横标的这一步骤,需要借助pivot,一步一步来

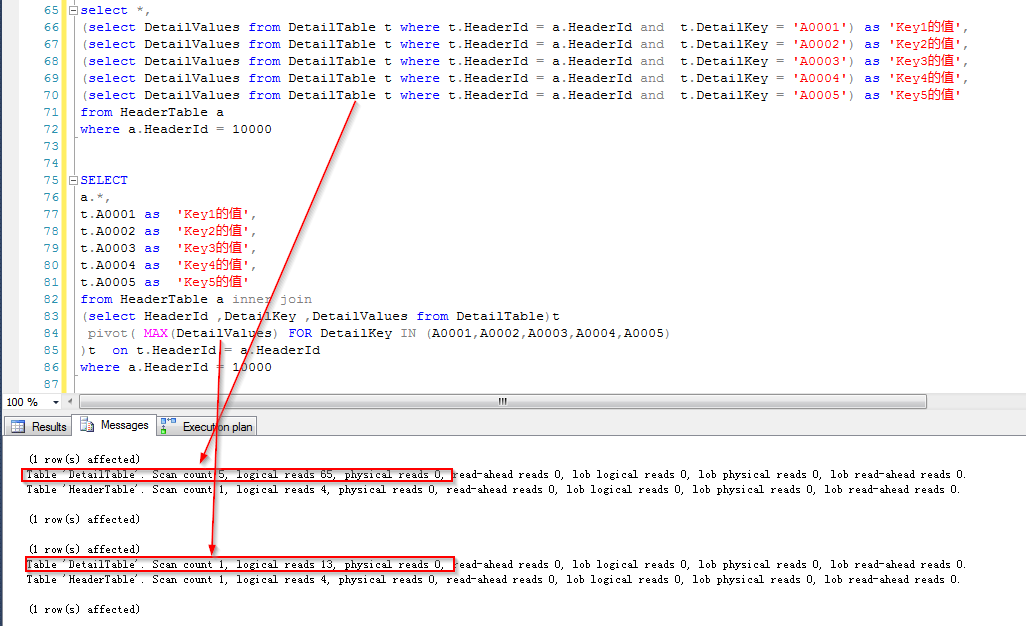
然后看跟主表join之后,两种查询方式的整体查询结果
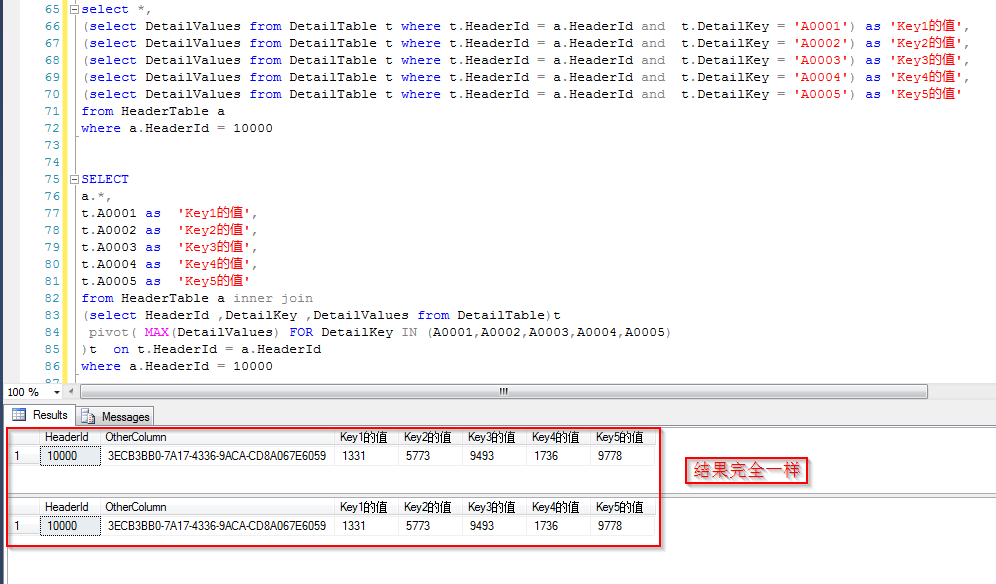
那么看一下后一种查询方式也即通过行业转换之后做join的执行计划,可以看到只对字表进行了一次查找(这里是index seek,但是暂抛开索引)
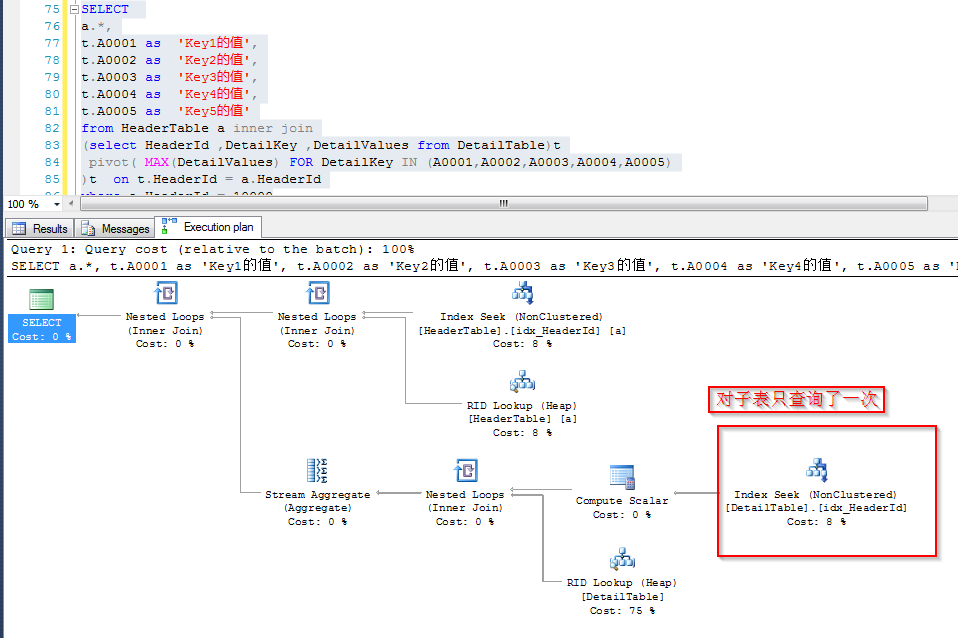
观察一下两条SQL的IO信息,可以发现,前者的Scan count是5,逻辑读是65,后者的Scan count是1,逻辑读是13,65=13*5。可见后者是一次性将表中的几个Key值读取出来的,而前者每个Key值读取一次表。
总结:
改写SQL是实现优化的思路之一,当然改写SQL技巧有很多种,本文仅对某一类典型查询提供一个改写思路,避免对一个表进行多次读取的方式来实现的查询。
通过改写一个常用的查询写法,从而实现一个等价的逻辑来减少对基表的读取次数来达到SQL优化的目的。
当然实际情况可能更加复杂,采用该思路改写的时候要注意针对SQL语句测试验证。
附上本文的测试脚本
create table HeaderTable
(
HeaderId int ,
OtherColumn varchar(50)
) create table DetailTable
(
HeaderId int,
DetailId int identity(1,1),
DetailKey varchar(50),
DetailValues int
) declare @i int = 0
while @i<1000000
begin
insert into HeaderTable values (@i,NEWID())
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0001',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0002',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0003',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0004',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0005',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0006',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0007',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0008',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0009',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0010',RAND()*10000)
set @i=@i+1
end create index idx_HeaderId on HeaderTable(HeaderId) create index idx_HeaderId on DetailTable(HeaderId) create index idx_DetailKey on DetailTable(DetailKey) select *,
(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0001') as 'Key1的值',
(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0002') as 'Key2的值',
(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0003') as 'Key3的值',
(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0004') as 'Key4的值',
(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0005') as 'Key5的值'
from HeaderTable a
where a.HeaderId = 10000 SELECT
a.*,
t.A0001 as 'Key1的值',
t.A0002 as 'Key2的值',
t.A0003 as 'Key3的值',
t.A0004 as 'Key4的值',
t.A0005 as 'Key5的值'
from HeaderTable a inner join
(select HeaderId ,DetailKey ,DetailValues from DetailTable)t
pivot( MAX(DetailValues) FOR DetailKey IN (A0001,A0002,A0003,A0004,A0005)
)t on t.HeaderId = a.HeaderId
where a.HeaderId = 10000
SQL Server SQL性能优化之--pivot行列转换减少扫描计数优化查询语句的更多相关文章
- SQL Server数据库性能优化之SQL语句篇【转】
SQL Server数据库性能优化之SQL语句篇http://www.blogjava.net/allen-zhe/archive/2010/07/23/326927.html 近期项目需要, 做了一 ...
- 最有效地优化 Microsoft SQL Server 的性能
为了最有效地优化 Microsoft SQL Server 的性能,您必须明确当情况不断变化时,性能将在哪些方面得到最大程度的改进,并集中分析这些方面.否则,在这些问题上您可能花费大量的时间和精力 ...
- Sql Server CPU 性能排查及优化的相关 Sql
Sql Server CPU 性能排查及优化的相关 Sql 语句,非常好的SQL语句,记录于此: --Begin Cpu 分析优化的相关 Sql --使用DMV来分析SQL Server启动以来累计使 ...
- Sql Server数据库性能优化之索引
最近在做SQL Server数据库性能优化,因此复习下一索引.视图.存储过程等知识点.本篇为索引篇,知识整理来源于互联网. 索引加快检索表中数据的方法,它对数据表中一个或者多个列的值进行结构排序,是数 ...
- 对SQL Server SQL语句进行优化的10个原则
1.使用索引来更快地遍历表. 缺省情况下建立的索引是非群集索引,但有时它并不是最佳的.在非群集索引下,数据在物理上随机存放在数据页上.合理的索引设计要建立在对各种查询的分析和预测上.一般来说:①.有大 ...
- SQL Server 2008性能故障排查(四)——TempDB
原文:SQL Server 2008性能故障排查(四)--TempDB 接着上一章:I/O TempDB: TempDB是一个全局数据库,存储内部和用户对象还有零食表.对象.在SQLServer操作过 ...
- SQL Server 2008性能故障排查(三)——I/O
原文:SQL Server 2008性能故障排查(三)--I/O 接着上一章:CPU瓶颈 I/O瓶颈(I/O Bottlenecks): SQLServer的性能严重依赖I/O子系统.除非你的数据库完 ...
- SQL Server 2008性能故障排查(二)——CPU
原文:SQL Server 2008性能故障排查(二)--CPU 承接上一篇:SQL Server 2008性能故障排查(一)--概论 说明一下,CSDN的博客编辑非常不人性化,我在word里面都排好 ...
- SQL Server 2008性能故障排查(一)——概论
原文:SQL Server 2008性能故障排查(一)--概论 备注:本人花了大量下班时间翻译,绝无抄袭,允许转载,但请注明出处.由于篇幅长,无法一篇博文全部说完,同时也没那么快全部翻译完,所以按章节 ...
随机推荐
- 2016huasacm暑假集训训练五 J - Max Sum
题目链接:http://acm.hust.edu.cn/vjudge/contest/126708#problem/J 题意:求一段子的连续最大和,只要每个数都大于0 那么就会一直增加,所以只要和0 ...
- 一些值得练习的github项目
简单粗暴,一晚上用 node.Vue 写个联机五子棋 https://github.com/ccforward/cc/issues/51 Vue2.0实现简易豆瓣电影webApp https://gi ...
- Web方式预览Office/Word/Excel/pdf文件解决方案
最近在做项目时需要在Web端预览一些Office文件,经过在万能的互联网上一番搜索确定并解决了. 虽然其中碰到的一些问题已经通过搜索和自己研究解决了,但是觉得有必要将整个过程记录下来,以方便自己以后查 ...
- 使用nmap工具查询局域网某个网段正在使用的ip地址
linux下nmap工具可扫描局域网正在使用的ip地址 查询局域网某网段正在使用的ip地址: nmap -sP .* 以上命令,将打印10.10.70.*/24网络所有正在使用的ip地址
- 一个基于Orchard的开源CRM --coevery简介
Coevery是开源的.NET Web平台项目,力争打造一个开放而鲁棒的CRM系统,采用Orchard架构,并使用AngularJS改善页面体验.作为一个后发优势的CRM 产品,Coevery 具有一 ...
- UI控件(UIAlertController)
@implementation ViewController - (void)viewDidLoad { [super viewDidLoad]; UIButton *_button = [UIBut ...
- 我所理解的RESTful Web API [设计篇]
<我所理解的RESTful Web API [Web标准篇]>Web服务已经成为了异质系统之间的互联与集成的主要手段,在过去一段不短的时间里,Web服务几乎清一水地采用SOAP来构建.构建 ...
- Java中迭代器
任何容器类,都必须有某种方法可以插入元素并将它们再次取回,毕竟,持有事物是容器最基本的工作,对于List,add()是出入元素的方法之一,而get()是取出元素的方法之一. 如果从更高层的角度思考,会 ...
- Docker学习笔记
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化.容器是完全使用沙箱机制,相互之间不会有任何 ...
- java IO流 之 其他流
一.内存操作流(ByteArrayInputStream.ByteArrayOutputStream) (一). public class ByteArrayInputStream extends ...