【强化学习RL】model-free的prediction和control —— MC,TD(λ),SARSA,Q-learning等
本系列强化学习内容来源自对David Silver课程的学习 课程链接http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Teaching.html
本文介绍了在model-free情况下(即不知道回报Rs和状态转移矩阵Pss'),如何进行prediction,即预测当前policy的state-value function v(s)从而得知此policy的好坏,和进行control,即找出最优policy(即求出q*(s, a),这样π*(a|s)就可以立刻知道了)。
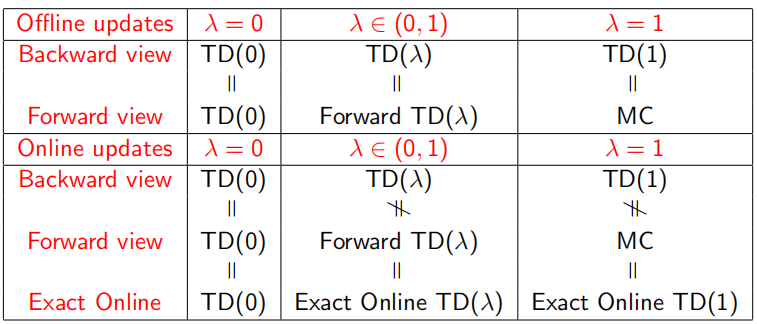
在prediction部分中,介绍了Monto Carlo(MC),TD(0),TD(λ)三种抽样(sample)估计方法,这里λ的现实意义是随机sample一个state,考虑其之后多少个state的价值。当λ=0即TD(0)时,只考虑下一个状态;λ=1 时几乎等同MC,考虑T-1个后续状态即到整个episode序列结束;λ∈(0,1)时为TD(λ),可以表示考虑后续非这两个极端状态的中间部分,即考虑后面n∈(1, T-1)个状态。同时,prediction过程又分为online update和offline update两部分,即使用当前π获得下一个状态的回报v(s')和优化policy π是否同时进行。
在control部分中,介绍了如何寻找最优策略的方法,即找到q*(s, a)。分成on-policy和off-policy两部分,即没有或者是参考了别人的策略(比如机器人通过观察人的行为提出更好的行为)。在on-policy部分,介绍了MC control、SARSA、SARSA(λ)三种方法,off-policy部分介绍了Q-learning的方法。
具体都会在下面正文介绍。
目录:
一、model-free的prediction
1. Monto Carlo(MC) Learning
2. Temporal-Difference TD(0)
3. TD(λ)
二、model-free的control
1. on-policy的Monto Carlo(MC) control
2. on-policy的Temporal-Difference(TD) Learning - SARSA和SARSA(λ)
3. off-policy的Q-learning
一、model-free的prediction
Prediction 部分的内容,全部都不涉及action。因为是衡量当前policy的好坏,只需要估计出每个状态的state-value function v(s)即可。上一文中介绍了使用Bellman Expectation Equation求得某个状态v(s)的数学期望,可以用动态规划DP进行遍历全部状态求得。但是这样的效率是非常低的,下面介绍了两种用sample采样的方法获取v(s)。
1. Monto Carlo(MC) Learning
Monto Carlo是一个经常会遇到的词,它的核心思想是从状态st出发随机采样sample至获得很多个完整序列,可以获得完整序列的实际收益,从而取平均值就是v(st)。需要注意的是,MC只能用于terminate的序列(complete)中。
在MC sample的过程中,每个状态点值函数 ,每次遍历N(s)+=1,S(s)为总回报每次S(s)+=Gt,这样当
,每次遍历N(s)+=1,S(s)为总回报每次S(s)+=Gt,这样当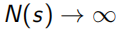 时,
时,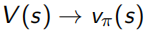 ,所求的平均值V(s)就接近真实值Vπ(s)。在获得完整序列的过程中,很可能会遇到环,即一个状态点经过多次,对此MC有两种处理方法,first step(只在第一次经过时N(s)+=1)和every step(每次经过这个点都N(s)+=1)。
,所求的平均值V(s)就接近真实值Vπ(s)。在获得完整序列的过程中,很可能会遇到环,即一个状态点经过多次,对此MC有两种处理方法,first step(只在第一次经过时N(s)+=1)和every step(每次经过这个点都N(s)+=1)。
V(s)可以看做所有经过s的回报Gt取平均值产生,但是平均值计算不仅可以求和再除法,还可以通过在已有的平均值上加一点差值获得,就是下面左式的形式。但这样来看,需要一直维护一个N(s)计数器,真正优化时只需要知道一个优化的方向即可,所以用一个(0,1)常数α来代替1/N(St),即下面右式的形式。 α的现实意义是一个遗忘系数,即不需要对所有sample出的序列都记得很清楚。

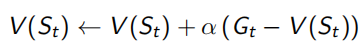
2. Temporal-Difference TD(0)
Monto Carlo采样有一个很明显的缺点,就是必须要sample出完整的序列才能观测出这个序列得到的回报是多少。但是TD(0)这种方法就不需要,它利用Bellman Equation,当前状态收益只和及时回报Rt+1和下一状态收益有关(如下式),红色部分为TD target,α右边括号内为TD error。所以TD(0)只sample出下一个状态点St+1,用已有的policy计算出Rt+1和V(St+1),这种用已知来做估计的方法叫做bootstrapping,而MC是观测的实际值,是没有bootstrapping的。由于只需要sample出下一个状态,所以可以用于non-terminate序列中(incomplete)。
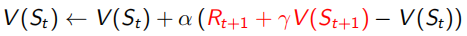
同MC比较,TD(0)采用已有policy预测出TD error,和MC的实际值相比有更大的偏差,但是TD(0)只需要sample出下一个状态序列而不是MC的完整序列,所以TF(0)预测获得的方差比MC小。
具体对v(s)的计算举例如下,进行8次sample,不考虑discount factor γ,下图获得的V(A)和V(B)分别是什么?
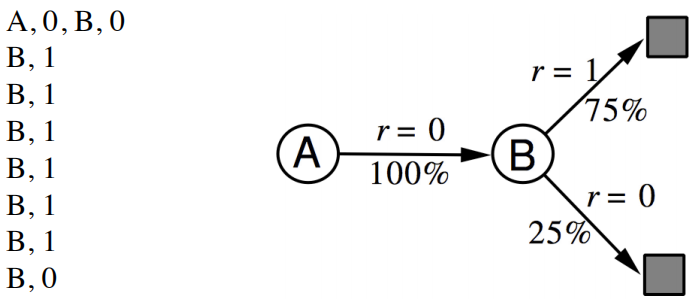
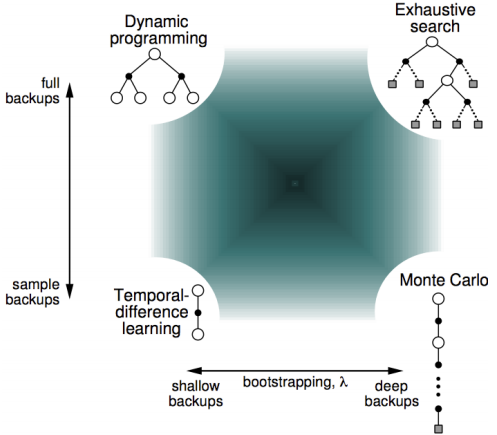
可以看出,无论是TD还是MC,v(B)都是取平均值计算出来的0.75,但是通过MC算出的V(A)是0,TD(0)算出来的是0.75。这一点来看,TD算法更能够利用Markov特性,但是只sample下一个状态点,所以比MC更shallow一些。下图显示了计算期望全部遍历的动态规划DP算法,sample采样下一个状态TD(0)算法,和sample出完整序列T-1个状态的MC算法相互间的关系,但是在1和T-1之间的诸多点,也可以sample考虑,这就是更一般的表达TD(λ)。
3. TD(λ)
这里λ是一个∈[0,1]的实数,它决定了需要采样之后的多少个状态点n,n从1到无穷大的简略表达如下,但是如何用一个实数λ来控制n呢?这里用了一个加权系数的表达,∑λ^n = 1/(1-λ),所以右式的∑=1,并且λ=0时,与TD(0)的函数表达相同。
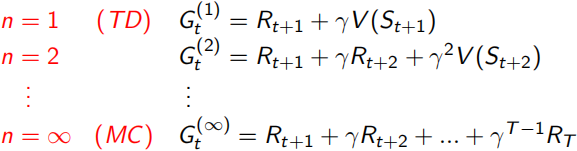

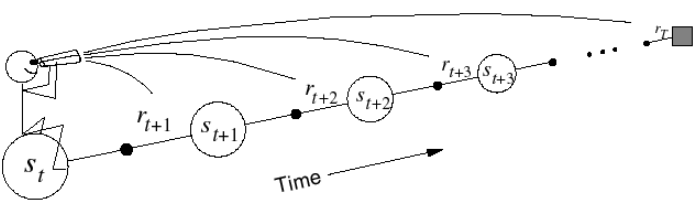
这里TD的sample分成了forward-view(下图左)和backward-view(下图右)两部分。forward-view就是刚刚叙述的往后sample n个状态点,backward是在sample的过程中,每一步都更新地维护一个Eligibility Trace,成为最后对平均值更新的权重。

这里的Eligibility Trace(下面左式),类似于青蛙跳井,每跳一下会升高,不跳的话就逐渐掉下去,既结合了frequency heuristic(跳几下),又结合了recency heuristic(什么时候跳的)。而这里的“跳”,就相当于经过状态所求点s,这样backward-view的值函数更新就可以写成下面右式的形式。当λ=0时,只有在经过s时Et(s)才为1,下面右式 结果同TD(0)表达相同;当λ=0时,整个序列中的每一个状态点有eligibility trace值会被考虑,可以看做MC。

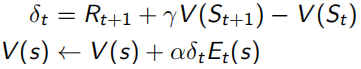
当序列环境是offline update时,即所有sample过程中不改变policy,forward-view和backward-view相同(见下式,左边可以化简到右边的形式),并且TD error可以化为λ-error的形式。
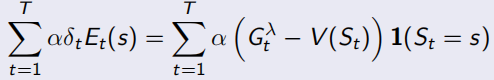
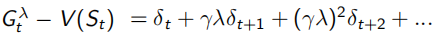
同时,TD(1)完全等同于MC。下面式子可以看出,λ=1时,Et(s)=γ^t-k,连续的TD error求和,为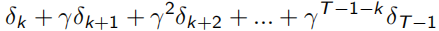 ,即可看作一直sample出完整序列T-1的MC error。
,即可看作一直sample出完整序列T-1的MC error。
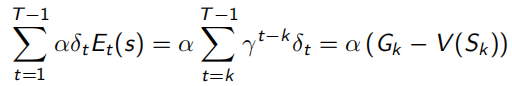
当序列环境是online update时,即边sample边优化policy,backward-view就会一直累积一个error,如下,所以如果访问s多次,这个error就会变得很大。
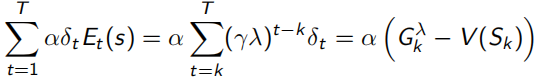
总结的一个表格如下:
二、model-free的control
因为是model-free的,没有状态转移矩阵P的相关值,所以求的是action-value function q(s, a)
1. on-policy的Monto Carlo(MC) control
留着坑,明天填。。。
【强化学习RL】model-free的prediction和control —— MC,TD(λ),SARSA,Q-learning等的更多相关文章
- 深度学习-强化学习(RL)概述笔记
强化学习(Reinforcement Learning)简介 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予 ...
- 【强化学习RL】必须知道的基础概念和MDP
本系列强化学习内容来源自对David Silver课程的学习 课程链接http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Teaching.html 之前接触过RL ...
- DRL强化学习:
IT博客网 热点推荐 推荐博客 编程语言 数据库 前端 IT博客网 > 域名隐私保护 免费 DRL前沿之:Hierarchical Deep Reinforcement Learning 来源: ...
- [Reinforcement Learning] 强化学习介绍
随着AlphaGo和AlphaZero的出现,强化学习相关算法在这几年引起了学术界和工业界的重视.最近也翻了很多强化学习的资料,有时间了还是得自己动脑筋整理一下. 强化学习定义 先借用维基百科上对强化 ...
- temporal credit assignment in reinforcement learning 【强化学习 经典论文】
Sutton 出版论文的主页: http://incompleteideas.net/publications.html Phd 论文: temporal credit assignment i ...
- Reinforcement Learning 的那点事——强化学习(一)
引言 最近实验室的项目需要用到强化学习的有关内容,就开始学习起强化学习了,这里准备将学习的一些内容记录下来,作为笔记,方便日后忘记了好再方便熟悉,也可供大家参考.该篇为强化学习开篇文章,主要概括一些有 ...
- 强化学习论文(Scalable agent alignment via reward modeling: a research direction)
原文地址: https://arxiv.org/pdf/1811.07871.pdf ======================================================== ...
- EnforceLearning-被动强化学习
前言: 画图挺好:深度学习进阶之路-从迁移学习到强化学习 专家系统给出了知识节点和规则,使用粒度描述准确性,依靠分解粒度解决矛盾,并反馈知识和推理规则更新.专家系统与机器学习有本质区别,但从机器学习的 ...
- 【转载】 “强化学习之父”萨顿:预测学习马上要火,AI将帮我们理解人类意识
原文地址: https://yq.aliyun.com/articles/400366 本文来自AI新媒体量子位(QbitAI) ------------------------------- ...
随机推荐
- tensorflow在文本处理中的使用——辅助函数
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- 51nod 1287加农炮
1287 加农炮 题目来源: Codility 基准时间限制:1 秒 空间限制:131072 KB 分值: 40 难度:4级算法题 一个长度为M的正整数数组A,表示从左向右的地形高度.测试一种加农炮 ...
- Weblogic/WAS之Full GC监控与计算
在网上看到关于内存回收机制,同大家一起分析探讨.堆内存划分为Eden.Survivor 和 Tenured/Old 空间,如下图所示: Minor GC 会清理年轻代的内存,Major GC 是清理老 ...
- 【转】Elasticsearch学习笔记
一.常用术语 索引(Index).类型(Type).文档(Document) 索引Index是含有相同属性的文档集合.索引在ES中是通过一个名字来识别的,且必须是英文字母小写,且不含中划线(-):可类 ...
- Struts2 类型转换(易百教程)
在HTTP请求中的一切都被视为一个String由协议.这包括数字,布尔值,整数,日期,小数和一切.每一件事情是一个字符串,将根据HTTP.然而,Struts类可以有任何数据类型的属性.Struts的自 ...
- Google 浏览器设置打开超链接到新窗口标签页
一.windows 按住Ctrl + 鼠标点击,在新窗口打开,停留在当前页面: 按住Ctrl + Shift + 鼠标点击,在新窗口打开,停留在新窗口: 登录Google账号,管理Google账号, ...
- Ubuntu常用命令大全 以及 PHP+MySQL代码部署在Linux(Ubuntu)上注意事项
PHP+MySQL代码部署在Linux(Ubuntu)上注意事项 https://cloud.tencent.com/developer/article/1024187 Ubuntu常用命令大全 ht ...
- java面试-反射
1.什么是反射?有什么优缺点? 反射就是动态加载对象,并对对象进行剖析.在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法.对于任意一个对象,都能够调用它的任意一个方法.这种动态获取信 ...
- $splay$学习总结$QwQ$
省选之前就大概搞了下$splay$,然后因为时间不太够就没写总结了,,,然后太久没用之后现在一回想感觉跟没学过一样了嘤嘤嘤 所以写个简陋的总结,,,肥肠简陋,只适合$gql$复习用,不建议学习用 然后 ...
- 1053 住房空置率 (20 分)C语言
在不打扰居民的前提下,统计住房空置率的一种方法是根据每户用电量的连续变化规律进行判断.判断方法如下: 在观察期内,若存在超过一半的日子用电量低于某给定的阈值 e,则该住房为"可能空置&quo ...