3、MapReduce详解与源码分析
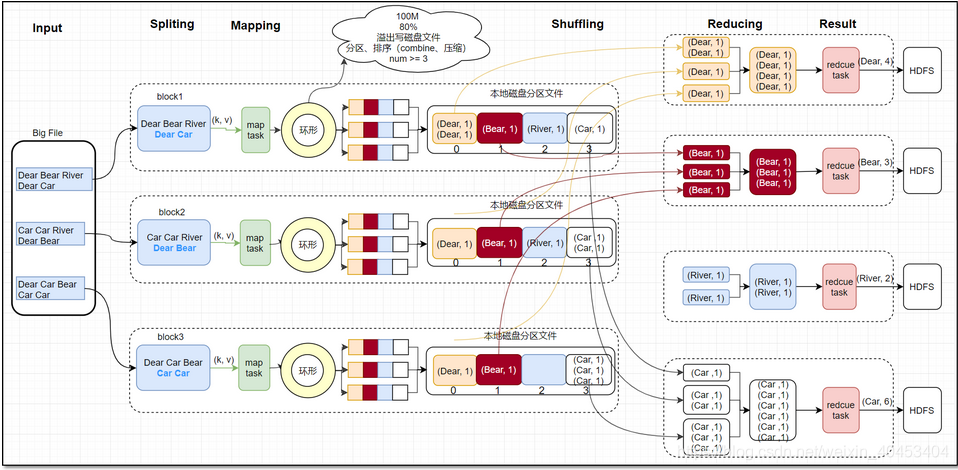
1 Split阶段
首先,接到hdf文件输入,在mapreduce中的map task开始之前,将文件按照指定的大小切割成若干个部分,每一部分称为一个split,默认是split的大小与block的大小相等,均为128MB。split大小由minSize、maxSize、blocksize决定,以wordcount代码为例,以下是main()方法
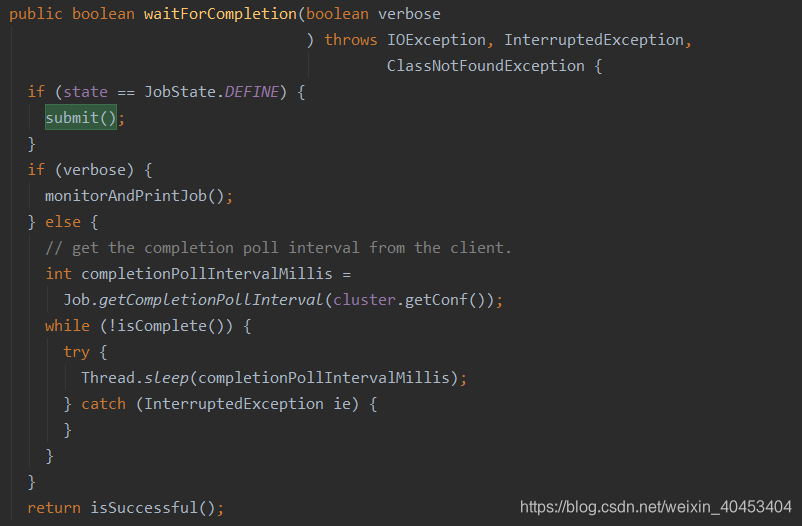
进入waitForCompletion(true)方法,进入submit()方法
找到 return submitter .submitJobInternal(Job.this, cluster);
进入,找到 int maps = writeSplits(job, submitJobDir);
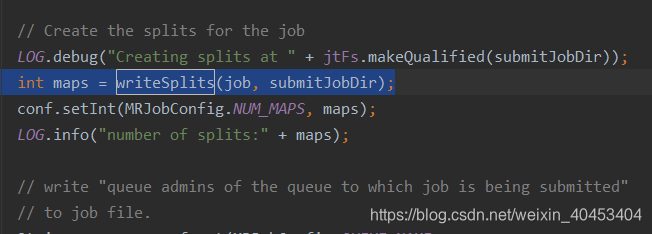
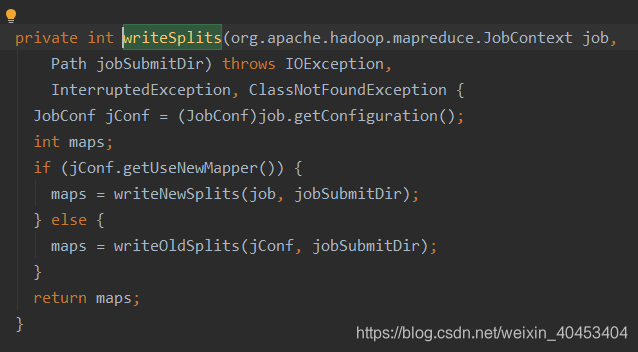
进入writeNewSplits()方法
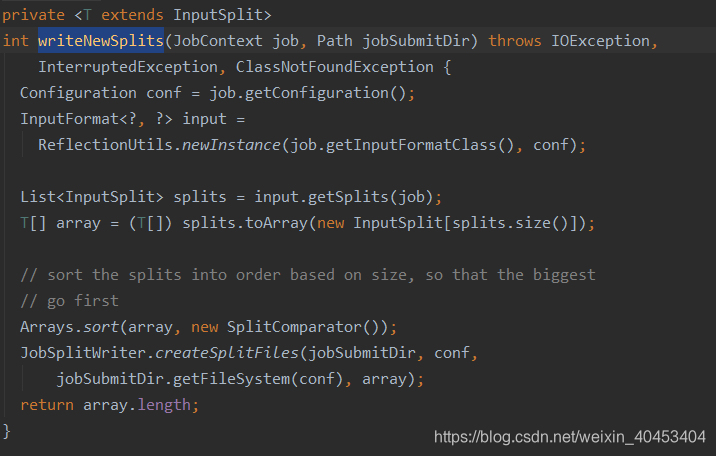
进入writeNewSplits()方法,可以看出该方法首先获取splits数组信息后,排序,将会优先处理大文件。最终返回mapper数量。这其中又分为两部分:确定切片数量 和 写入切片信息。确定切片数量的任务交由FileInputFormat的getSplits(job)完成,写入切片信息的任务交由JobSplitWriter.createSplitFiles(jobSubmitDir, conf, jobSubmitDir.getFileSystem(conf), array)方法,该方法会将切片信息和SplitMetaInfo都写入HDFS中,return array.length;返回的是map任务数,默认map的数量是: default_num = total_size / block_size;
实际的mapper数量就是输入切片的数量,而切片的数量又由使用的输入格式决定,默认为TextInputFormat,该类为FileInputFormat的子类。确定切片数量的任务交由FileInputFormat的getSplits(job)完成。FileInputFormat继承自抽象类InputFormat,该类定义了MapReduce作业的输入规范,其中的抽象方法List getSplits(JobContext context)定义了如何将输入分割为InputSplit,不同的输入有不同的分隔逻辑,而分隔得到的每个InputSplit交由不同的mapper处理,因此该方法的返回值确定了mapper的数量。
2 Map阶段
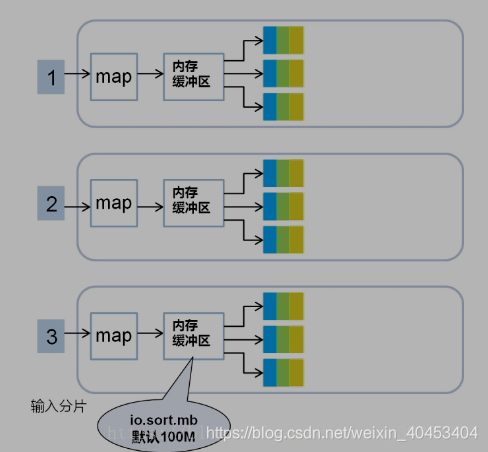
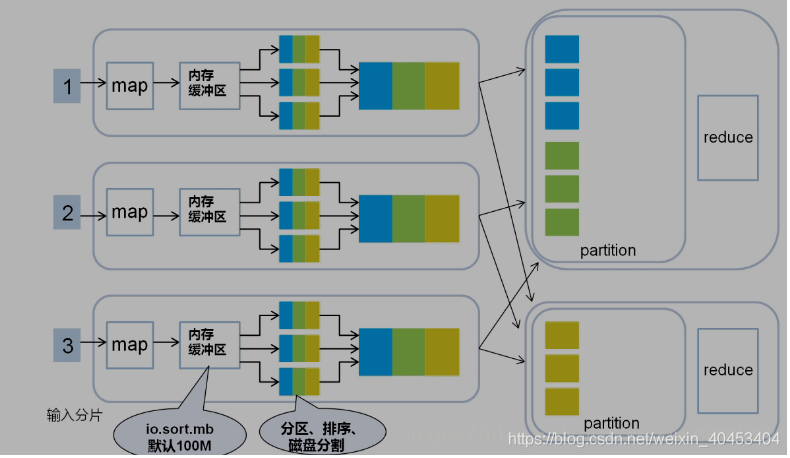
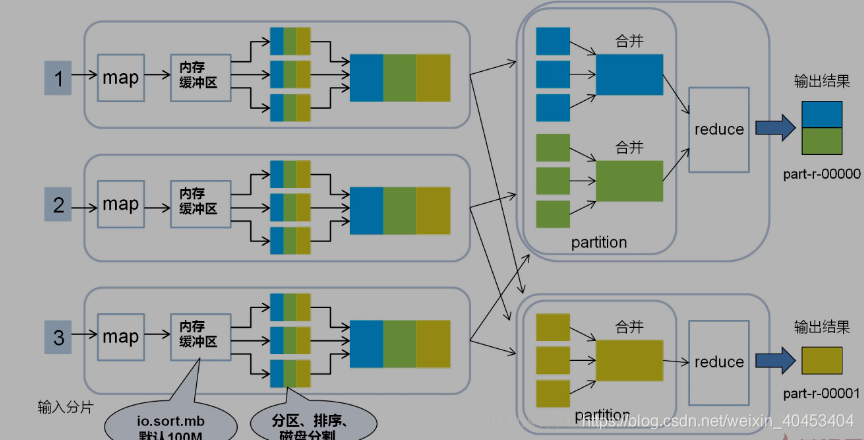
每个map task都有一个内存缓冲区, map的输出结果先写到内存中的环形缓冲区,缓冲区为100M,不断的向缓冲区力写数据,当达到80M时,需要将缓冲区中的数据以一个临时文件的方式存到磁盘,当整个map task结束后再对磁盘中这个map task所产生的所有临时文件做合并,生成最终的输出文件。最后,等待reduce task来拉取数据。当然,如果map task的结果不大,能够完全存储到内存缓冲区,且未达到内存缓冲区的阀值,那么就不会有写临时文件到磁盘的操作,也不会有后面的合并。在写入的过程中会进行分区、排序、combine操作。
环形缓冲区:是使用指针机制把内存中的地址首尾相接形成一个存储中间数据的缓存区域,默认100MB;80M阈值,20M缓冲区,是为了解决写入环形缓冲区数据的速度大于写出到spill文件的速度是数据的不丢失;Spill文件:spill文件是环形缓冲区到达阈值后写入到磁盘的单个文件.这些文件在map阶段计算结束时,会合成分好区的一个merge文件供给给reduce任务抓取;spill文件过小的时候,就不会浪费io资源合并merge;默认情况下3个以下spill文件不合并;对于在环形缓冲区中的数据,最终达不到80m但是数据已经计算完毕的情况,map任务将会调用flush将缓冲区中的数据强行写出spill文件。
经过map类处理后,输出到内存缓冲区(默认大小100M),超过一定大小后,文件溢写到磁盘上,按照key分类
按照key合并成大文件,减少网络开销
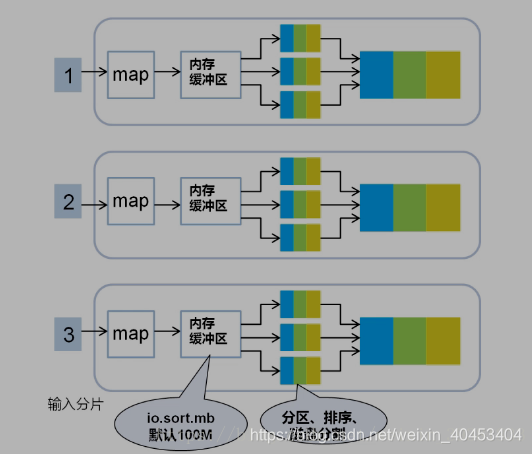
2.1分区
看一下MapReduce自带的分区器HashPartitioner
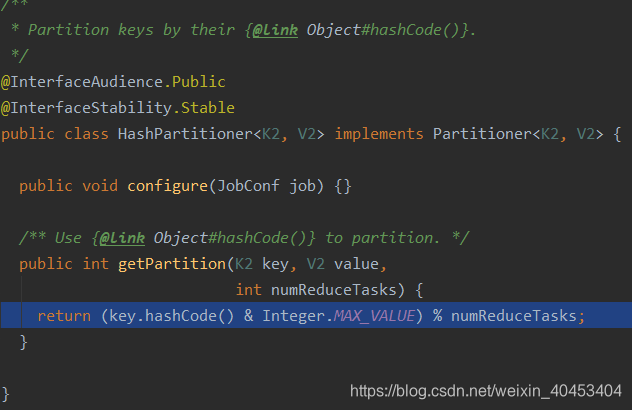
假设有听个reduce任务,则分区的计算如下:

2.2排序
在对map结果进行分区之后,对于落在相同的分区中的键值对,要进行排序。
3 Shuffle阶段
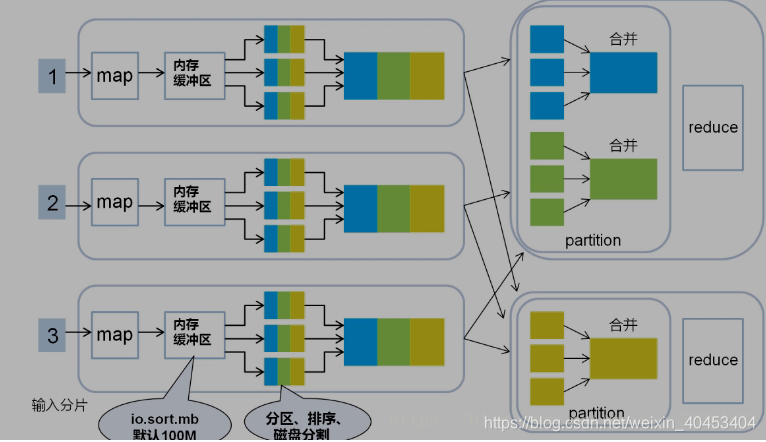
Shuffle过程是MapReduce的核心,描述着数据从map task输出到reduce task输入的这段过程。reducetask根据自己的分区号,去各个maptask分区机器上取相应的结果分区数据,reducetask会将这些文件再进行合并(归并排序)。
所有相同key的数据汇集到一个partition
将相同的key value汇聚到一起, 但不计算
4 Reduce阶段
reduce阶段分三个步骤:
抓取,合并,排序
1 reduce 任务会创建并行的抓取线程(fetcher)负责从完成的map任务中获取结果文件,是否完成是通过rpc心跳监听,通过http协议抓取;默认是5个抓取线程,可调,为了是整体并行,在map任务量大,分区多的时候,抓取线程调大;
2 抓取过来的数据会先保存在内存中,如果内存过大也溢出,不可见,不可调,但是单位是每个merge文件,不会切分数据;每个merge文件都会被封装成一个segment的对象,这个对象控制着这个merge文件的读取记录操作,有两种情况出现:在内存中有merge数据 •在溢写之后存到磁盘上的数据 •通过构造函数的区分,来分别创建对应的segment对象
3 这种segment对象会放到一个内存队列中MergerQueue,对内存和磁盘上的数据分别进行合并,内存中的merge对应的segment直接合并,磁盘中的合并与一个叫做合并因子的factor有关(默认是10)
4 排序问题,MergerQueue继承轮换排序的接口,每一个segment 是排好序的,而且按照key的值大小逻辑(和真的大小没关系);每一个segment的第一个key都是逻辑最小,而所有的segment的排序是按照第一个key大小排序的,最小的在前面,这种逻辑总能保证第一个segment的第一个key值是所有key的逻辑最小文件合并之后,最终交给reduce函数计算的,是MergeQueue队列,每次计算的提取数据逻辑都是提取第一个segment的第一个key和value数据,一旦segment被调用了提取key的方法,MergeQueue队列将会整体重新按照最小key对segment排序,最终形成整体有序的计算结果;
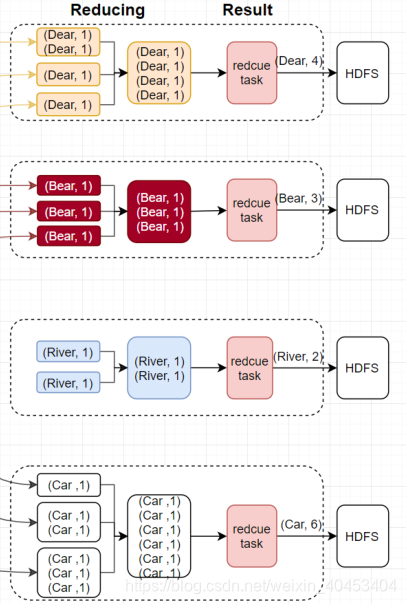
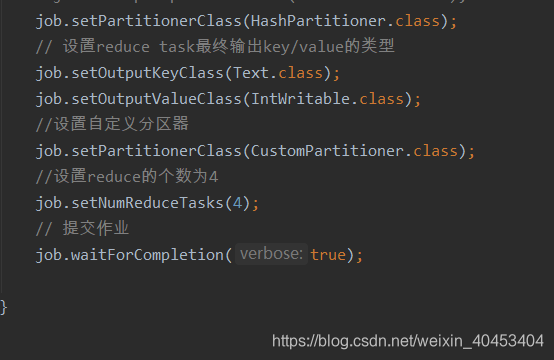
partition 、Reduce、输出文件数量相等
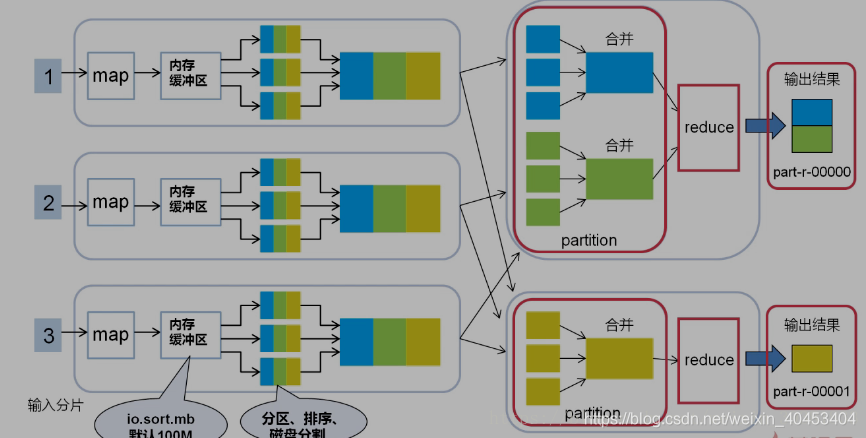
Reduce任务数量
在大数据量的情况下,如果只设置1个Reduce任务,其他节点将被闲置,效率底下 所以将Reduce设置成一个较大的值(max:72).调节Reduce任务数量的方法 一个节点的Reduce任务数并不像Map任务数那样受多个因素制约
通过参数调节mapred.reduce.tasks(在配置文件中)
在代码中调用job.setNumReduceTasks(int n)方法(在code中)
3、MapReduce详解与源码分析的更多相关文章
- Android应用AsyncTask处理机制详解及源码分析
1 背景 Android异步处理机制一直都是Android的一个核心,也是应用工程师面试的一个知识点.前面我们分析了Handler异步机制原理(不了解的可以阅读我的<Android异步消息处理机 ...
- Java SPI机制实战详解及源码分析
背景介绍 提起SPI机制,可能很多人不太熟悉,它是由JDK直接提供的,全称为:Service Provider Interface.而在平时的使用过程中也很少遇到,但如果你阅读一些框架的源码时,会发现 ...
- Spring Boot启动命令参数详解及源码分析
使用过Spring Boot,我们都知道通过java -jar可以快速启动Spring Boot项目.同时,也可以通过在执行jar -jar时传递参数来进行配置.本文带大家系统的了解一下Spring ...
- 【转载】Android应用AsyncTask处理机制详解及源码分析
[工匠若水 http://blog.csdn.net/yanbober 转载烦请注明出处,尊重分享成果] 1 背景 Android异步处理机制一直都是Android的一个核心,也是应用工程师面试的一个 ...
- 线程池底层原理详解与源码分析(补充部分---ScheduledThreadPoolExecutor类分析)
[1]前言 本篇幅是对 线程池底层原理详解与源码分析 的补充,默认你已经看完了上一篇对ThreadPoolExecutor类有了足够的了解. [2]ScheduledThreadPoolExecut ...
- SpringMVC异常处理机制详解[附带源码分析]
目录 前言 重要接口和类介绍 HandlerExceptionResolver接口 AbstractHandlerExceptionResolver抽象类 AbstractHandlerMethodE ...
- Hadoop RCFile存储格式详解(源码分析、代码示例)
RCFile RCFile全称Record Columnar File,列式记录文件,是一种类似于SequenceFile的键值对(Key/Value Pairs)数据文件. 关键词:Reco ...
- ArrayList用法详解与源码分析
说明 此文章分两部分,1.ArrayList用法.2.源码分析.先用法后分析是为了以后忘了查阅起来方便-- ArrayList 基本用法 1.创建ArrayList对象 //创建默认容量的数组列表(默 ...
- [转]SpringMVC拦截器详解[附带源码分析]
目录 前言 重要接口及类介绍 源码分析 拦截器的配置 编写自定义的拦截器 总结 前言 SpringMVC是目前主流的Web MVC框架之一. 如果有同学对它不熟悉,那么请参考它的入门blog:ht ...
随机推荐
- CBAM(Convolutional Block Attention Module)使用指南
转自知乎 这货就是基于 SE-Net [5]中的 Squeeze-and-Excitation module 来进行进一步拓展 具体来说,文中把 channel-wise attention 看成是教 ...
- ThinkPHP5.1学习笔记 数据库操作
数据库 参见<Thinkphp5.1完全开发手册>学习 Mirror王宇阳 数据库连接 ThinkPHP采用内置抽象层对数据库操作进行封装处理:且基于PDO模式,可以适配各种数据库. 数据 ...
- MySQL8.0关系数据库基础教程(三)-select语句详解
1 查询指定字段 在 employee 表找出所有员工的姓名.性别和电子邮箱. SELECT 表示查询,随后列出需要返回的字段,字段间逗号分隔 FROM 表示要从哪个表中进行查询 分号为语句结束符 这 ...
- Go语言实现:【剑指offer】扑克牌顺子
该题目来源于牛客网<剑指offer>专题. LL今天心情特别好,因为他去买了一副扑克牌,发现里面居然有2个大王,2个小王(一副牌原本是54张_)-他随机从中抽出了5张牌,想测测自己的手气 ...
- Elemetary OS deepin-wine 版 微信 和 企业微信 输入框字体显示异常解决
Elemetary OS deepin-wine 版 微信 和 企业微信 输入框字体显示异常解决 最近体验了Elementary OS 这个系统, 话说我之前都是用的Manjora 的各个桌面版, 突 ...
- python中的PYC文件是什么?
1. Python是一门解释型语言吗? 我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存在.如果是解释型语言 ...
- urllib 模块 - module urllib
urllib 模块 - urllib module 获取 web 页面, html = urllib.request.urlopen("http://www.zzyzz.top/" ...
- ELK-图示nginx中ip的地理位置
一.环境准备: ELK stack 环境一套 geolite数据库文件 二.下载geolite数据库(logstash机器上解压,logstash需调用): geolite官网:https://dev ...
- PHP 安装扩展步骤
一般来说php安装扩展需要几下几个步骤 1.下载扩展包 比如 pdo_mysql.tar.gz (如果不想下载,可以到php安装目录,(类似php-5.3.3/ext/)的ext文件中找 ...
- 11种常用css样式之鼠标、列表和尺寸样式学习
鼠标cursor常见样式crosshair;/*十字形状*/cursor:pointer;/*小手形状*/cursor:wait;/*等待形状*/cursor:text;/*默认 文本形状*/curs ...