Affinity Propagation Demo1学习
利用AP算法进行聚类:
首先导入需要的包:
from sklearn.cluster import AffinityPropagation
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
生成一组数据:
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=300, centers=centers, cluster_std=0.5, random_state=0)
以上代码包括3个类簇的中心点以及300个以这3个点为中心的样本点。
接下来要利用AP算法对这300个点进行聚类。
af = AffinityPropagation(preference=-50).fit(X) # preference采用负的欧氏距离
cluster_centers_indices = af.cluster_centers_indices_
labels = af.labels_ # 样本标签
n_clusters_ = len(cluster_centers_indices) # 类簇数
打印各种评价指标分数:
print('估计的类簇数: %d' % n_clusters_)
print('Homogeneity: %0.3f' % metrics.homogeneity_score(labels_true, labels))
print('Completeness: %0.3f' %metrics.completeness_score(labels_true, labels))
print('V-measure: %0.3f' %metrics.v_measure_score(labels_true, labels))
print('Adjusted Rand Index:%0.3f' %metrics.adjusted_rand_score(labels_true, labels))
print('Adjusted Mutual Information:%0.3f'%metrics.adjusted_mutual_info_score(labels_true, labels))
print('Silhouette Coefficient:%0.3f' %metrics.silhouette_score(X, labels, metric='sqeuclidean')) # sqeuclidean欧式距离平方
可视化聚类结果:
导入画图需要的包:
import matplotlib.pyplot as plt
from itertools import cycle
plt.close('all')
plt.figure(1)
plt.clf() # 清除当前图的所有信息
colors = cycle('bgrcmykbgrcmykbgrcmykbgrcmyk')
close()方法介绍【可忽略】
close方法简介: matplotlib.pyplot.close(*args) --- Close a figure window.
close() by itself closes the current figure close(fig) closes the Figure instance fig close(num) closes the figure number num close(name) where name is a string, closes figure with that label close('all') closes all the figure windows
for k, col in zip(range(n_clusters_),colors):
class_members = labels == k;
print('k:',k)
print('labels:',labels)
print('cls_member--------',class_members)
cluster_center = X[cluster_centers_indices[k]]
print('cluster_center:', cluster_center)
# 画样本点
plt.plot(X[class_members, 0], X[class_members, 1], col + '.')
# 画中心点
plt.plot(cluster_center[0], cluster_center[1], 'o',
markeredgecolor='k', markersize=28)
# 划线
for x in X[class_members]:
plt.plot([cluster_center[0], x[0]], [cluster_center[1], x[1]], col) plt.title('Estimated number of clusters:%d' %n_clusters_)
plt.show()# 显示图
运行结果:
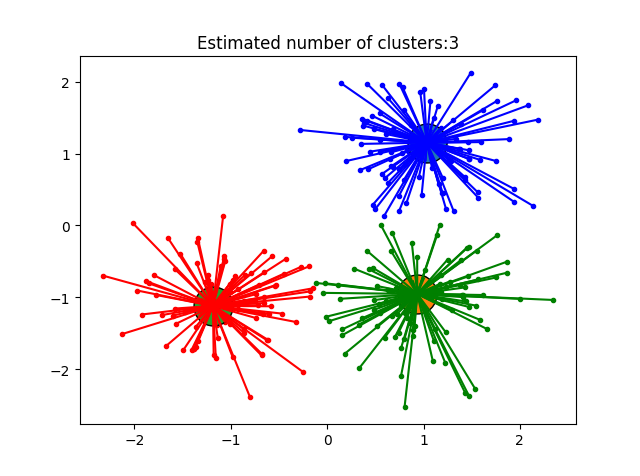
完整代码:
print(__doc__) from sklearn.cluster import AffinityPropagation
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs # #################################################
# generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=300, centers=centers, cluster_std=0.5, random_state=0) # #######################################################
# Compute Affinity Propagation
af = AffinityPropagation(preference=-50).fit(X) # preference采用负的欧氏距离
cluster_centers_indices = af.cluster_centers_indices_
labels = af.labels_ # 样本标签 n_clusters_ = len(cluster_centers_indices) # 类簇数 print('估计的类簇数: %d' % n_clusters_)
print('Homogeneity: %0.3f' % metrics.homogeneity_score(labels_true, labels))
print('Completeness: %0.3f' %metrics.completeness_score(labels_true, labels))
print('V-measure: %0.3f' %metrics.v_measure_score(labels_true, labels))
print('Adjusted Rand Index:%0.3f' %metrics.adjusted_rand_score(labels_true, labels))
print('Adjusted Mutual Information:%0.3f'%metrics.adjusted_mutual_info_score(labels_true, labels))
print('Silhouette Coefficient:%0.3f' %metrics.silhouette_score(X, labels, metric='sqeuclidean')) # sqeuclidean欧式距离平方 # ##########################################################
# Plot result
import matplotlib.pyplot as plt
from itertools import cycle plt.close('all')
plt.figure(1)
plt.clf()
colors = cycle('bgrcmykbgrcmykbgrcmykbgrcmyk')
for k, col in zip(range(n_clusters_),colors):
class_members = labels == k;
print('k:',k)
print('labels:',labels)
print('cls_member--------',class_members) cluster_center = X[cluster_centers_indices[k]]
print('cluster_center:', cluster_center)
plt.plot(X[class_members, 0], X[class_members, 1], col + '.')
plt.plot(cluster_center[0], cluster_center[1], 'o',
markeredgecolor='k', markersize=28) # 划线
for x in X[class_members]:
plt.plot([cluster_center[0], x[0]], [cluster_center[1], x[1]], col) plt.title('Estimated number of clusters:%d' %n_clusters_)
plt.show()
Affinity Propagation Demo1学习的更多相关文章
- Affinity Propagation Demo2学习【可视化股票市场结构】
这个例子利用几个无监督的技术从历史报价的变动中提取股票市场结构. 使用报价的日变化数据进行试验. Learning a graph structure 首先使用sparse inverse(相反) c ...
- AP(affinity propagation)研究
待补充…… AP算法,即Affinity propagation,是Brendan J. Frey* 和Delbert Dueck于2007年在science上提出的一种算法(文章链接,维基百科) 现 ...
- Affinity Propagation Algorithm
The principle of Affinity Propagation Algorithm is discribed at above. It is widly applied in many f ...
- Affinity Propagation
1. 调用方法: AffinityPropagation(damping=0.5, max_iter=200, convergence_iter=15, copy=True, preference=N ...
- AP聚类算法(Affinity propagation Clustering Algorithm )
AP聚类算法是基于数据点间的"信息传递"的一种聚类算法.与k-均值算法或k中心点算法不同,AP算法不需要在运行算法之前确定聚类的个数.AP算法寻找的"examplars& ...
- knn/kmeans/kmeans++/Mini Batch K-means/Affinity Propagation/Mean Shift/层次聚类/DBSCAN 区别
可以看出来除了KNN以外其他算法都是聚类算法 1.knn/kmeans/kmeans++区别 先给大家贴个简洁明了的图,好几个地方都看到过,我也不知道到底谁是原作者啦,如果侵权麻烦联系我咯~~~~ k ...
- [Python] 机器学习库资料汇总
声明:以下内容转载自平行宇宙. Python在科学计算领域,有两个重要的扩展模块:Numpy和Scipy.其中Numpy是一个用python实现的科学计算包.包括: 一个强大的N维数组对象Array: ...
- 【转帖】Python在大数据分析及机器学习中的兵器谱
Flask:Python系的轻量级Web框架. 1. 网页爬虫工具集 Scrapy 推荐大牛pluskid早年的一篇文章:<Scrapy 轻松定制网络爬虫> Beautiful Soup ...
- python数据挖掘领域工具包
原文:http://qxde01.blog.163.com/blog/static/67335744201368101922991/ Python在科学计算领域,有两个重要的扩展模块:Numpy和Sc ...
随机推荐
- ThinkPHP5——接入腾讯云短信API
接入腾讯云短信API相当简单,最重要的是第一次使用腾讯云短信的话有100条免费短信可以测试,对于开发人员是足够了,下面我就教大家接入腾讯云短信. 第一步:准备工作 首先要在腾讯云短信申请短信签名与短信 ...
- 【转】【e周美文】优秀博客上榜推荐
Everybody,本周的博客推荐开始啦,记住,有好的博客可要给小活推荐一下哦. 7.19日 博客推荐 Android权限列表作者:@大漠落日 链接:http://my.eoe.cn/1103623/ ...
- 【Java并发基础】并发编程领域的三个问题:分工、同步和互斥
前言 可以将Java并发编程抽象为三个核心问题:分工.同步和互斥. 这三个问题的产生源自对性能的需求.最初时,为提高计算机的效率,当IO在等待时不让CPU空闲,于是就出现了分时操作系统也就出现了并发. ...
- phpstudy nginx设置CORS跨域不起作用的可能解决方法
今天搞了半天的跨域问题,想通过nginx配置跨域,希望以后本地调试程序都不用为这件事烦心.无非就是设置几个请求头: add_header Access-Control-Allow-Origin *; ...
- Unity 基于Cinemachine计算透视摄像机在地图中的移动范围
Unity中Cinemachine的基础功能介绍可详见之前写的博客: https://www.cnblogs.com/koshio0219/p/11820654.html 本篇的重点是讨论,在给定规则 ...
- python检查是奇数还是偶数
检查的依据:奇数除2余1:偶数除2无余数 num = int(input("请输入一个整数:")) if num % 2 == 1: print(num,"是奇数&quo ...
- 定时器之Quart.net(1)
第一步:Install-Package Quartz namespace ProjectEdb { class Program { static void Main(string[] args) { ...
- python爬虫——scrapy的使用
本文中的知识点: 安装scrapy scrapy的基础教程 scrapy使用代理 安装scrapy 由于小哥的系统是win7,所以以下的演示是基于windows系统.linux系统的话,其实命令都一样 ...
- Linux 编程题
1. 产生一个进程树,父进程有2个子进程,这2个子进程分别又有2个子进程,每个进程休眠5秒后退出,并在退出前打印自己的进程id号. # include<stdio.h> # include ...
- 史上最简约的vi教程,复制和粘贴
上一篇博客,讲了"新手"如何"入门"vi,解决了"两眼一抹黑"的情况.知道在vi下如何进行基本的操作,如部署在Linux下的项目,修改配置文 ...