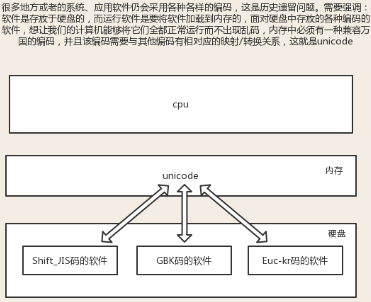
字符编码及字节串bytes类型
1 字符编码简介
ASCII码:美国人发明并使用,用1个字节(8位二进制)代表一个字符,ASCII码是其他任意编码表的子集(utf-16除外).
Unicode:包含和兼容全世界的语言,与全世界的语言都有映射关系,常用2个字节表示一个字符,1个生僻字用4个字节表示.
utf-8:可变长编码,英文用1个字节表示,汉字通常是3个字节,生僻字常用4-6个字节表示,uft-8比Unicode编码节省空间和I/O开销.
关于Unicode和utf-x格式之间的关系,可以认为utf-x是Unicode的一种特殊类型,在存取数据时,内部会自动在Unicode和utf-x之间转换.
在内存中,统一使用的都是Unicode编码(固定,集成在操作系统中),所以可以转换为任意其他国家自定义的编码(这样就不会乱码);在将数据存入硬盘时,需要将Unicode转换为一种更精准的格式,即utf-8,将数据控制在最精准和节省空间;而磁盘数据读入缓存到内存中时,则需要将utf-8转换为Unicode.
在python2.x中,默认使用ASCII编码作为字符编码;而在python3.x中,默认使用Unicode作为默认字符编码.
import sys
print(sys.getdefaultencoding())
'ascii' #python2.x默认字符编码
---------------------------------
import sys
print(sys.getdefaultencoding())
'utf-8' #python3.x默认字符编码
---------------------------------
U=u'阿凡达' #3*3=9字节,8*9=72bytes
U1=bytes(U,'utf-8')
print(U1) # 构造Unicode字符,结果是 b'\xe9\x98\xbf\xe5\x87\xa1\xe8\xbe\xbe',\x代表16进制存储,1个字符代表4byte,18*4=72bytes
1.1 字符编码和解码
两张图读懂字符编码与解码之间的关系,编码和解码对应,就不会出现乱码了,参考资料及图片来源:
https://www.cnblogs.com/f-ck-need-u/p/10185965.html
https://www.cnblogs.com/linhaifeng/articles/5950339.html
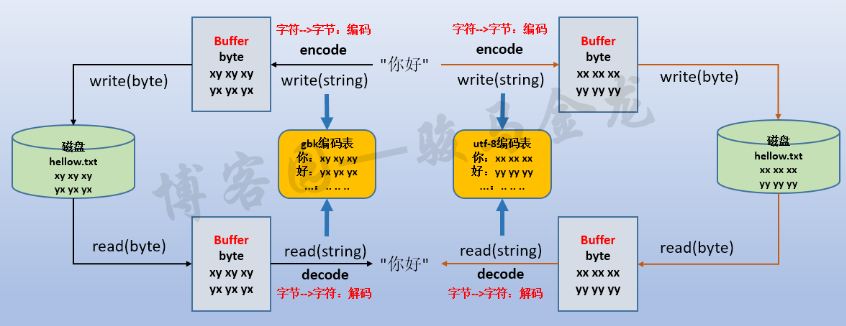
编码: str ---> bytes (encode)
解码: bytes ---> str (decode)
二进制格式的数据也常称为裸数据(raw data),str数据经过编码后得到raw data,raw data解码后得到的str.
内存中是unicode-------->encode编码保存-------->utf-8保存到磁盘(二进制)
utf-8磁盘里保存-------->decode解码缓存到内存中---------->unicode内存中
注意: 编码和解码的过程中,与软件指定的编码(字符集)也有关系,必须对应.
######################
print((set(dir(str)))-set(dir(bytes))) #字符串类型只有编码encode()方法,没有解码decode()
print((set(dir(bytes)))-set(dir(str))) #字节串类型只有解码decode()方法,没有编码encode()
--------------------
{'format', 'isdecimal', 'casefold', 'format_map', 'isidentifier', 'isnumeric', 'isprintable', 'encode'}
{'hex', 'decode', 'fromhex'}
1.2 str,bytes,bytearray类型
str:字符串类型,有序有索引,序列数据,可以迭代取值,但属于不可变类型,底层存储由一个个二进制组成,也就是bytes.python3.x中str默认是Unicode(uft-8)格式编码.
bytes:字节串类型,二进制字节数据,有序有索引,序列数据,可以迭代取值,也属于不可变类型;将字符串数据存到硬盘的的过程,实质上就是将Unicode转换为utf-8下的二进制字节这样就可以往硬盘存数据(二进制转换为十六进制存),或通过网络方式传输到其他地方.
bytearray:可变的字节串类型,属于可变的二进制数据(bytes),属于可变类型.
import sys #python3.x下查看默认字符编码为 utf-8
print(sys.getdefaultencoding()) #结果是 utf-8
----------------------------
B=b'aaa'
print(type(B),B) #构造bytes类型,需在字符串前加 b ,结果是<class 'bytes'> b'aaa'
----------------------------
B=b'aaa' # 构造bytearray类型及改值
By=bytearray(B)
print(type(By),By)
print(list(i for i in By))
By[0]=98 #改值
print(By) #By=b'baa',a子串值已改变
-------构造bytearray结果
<class 'bytearray'> bytearray(b'aaa')
[97, 97, 97]
bytearray(b'baa')
1.3 乱码的原因及解决办法
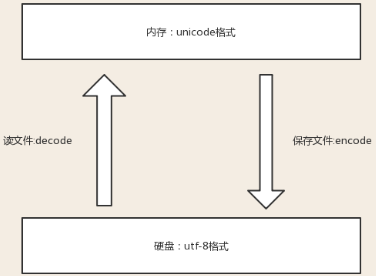
文件从内存写到硬盘的操作简称存文件,文件从硬盘读到内存的操作简称读文件.
乱码的原因:
1)存文件时就已经乱码(编辑的字符和编辑器设定保存的字符编码不一致)
2)存文件时不乱码而读文件时乱码(存时的文件字符编码和读时编辑器设定的字符编码不对应)
解决乱码的办法: 字符按照什么标准而编码的,就要按照什么标准解码,即编码和解码对应.
1.4 python文件头指定字符编码
为了避免乱码,在python文件中指定解释器和文件头也是一种方法,文件头指定的编码必须跟python文件存储时用的编码一致.
#!/usr/bin/env python <===指定解释器(限linux)
# -*- coding: utf-8 -*- <===指定字符编码(等同于#coding:utf-8)来将数据读入内存,由python解释器解释执行用的字符编码
字符编码及字节串bytes类型的更多相关文章
- 对于Python中的字节串bytes和字符串以及转义字符的新的认识
事情的起因是之前同学叫我帮他用Python修改一个压缩包的二进制内容用来做fuzz,根据他的要求,把压缩包test.rar以十六进制的方式打开,每次修改其中一个十六进制字符串并保存为一个新的rar用来 ...
- encode_utf8 把字符编码成字节 微信例子
##µ¼Èë encode_json decode_json use JSON qw/encode_json decode_json/; print "1111111111111111-\$ ...
- encode_utf8 把字符编码成字节 decode_utf8解码UTF-8到字符
encode_utf8 $octets = encode_utf8($string); Equivalent to "$octets = encode("utf8", $ ...
- 字符编码 and 字节和字符串转换(待补充)
ascii用一个字节(8位二进制)代表一个字符 Unicode常用2个字节(16位二进制)代表一个字符,生僻字需要用四个字节 汉字中已经超出了ASCII编码的范围,用Unicode, Unicode兼 ...
- Python中的字符串与字符编码
本节内容: 前言 相关概念 Python中的默认编码 Python2与Python3中对字符串的支持 字符编码转换 一.前言 Python中的字符编码是个老生常谈的话题,同行们都写过很多这方面的文章. ...
- Python【第三篇】文件操作、字符编码
一.文件操作 文件操作分为三个步骤:文件打开.操作文件.关闭文件,但是,我们可以用with来管理文件操作,这样就不需要手动来关闭文件. 实现原理: import contextlib @context ...
- 【转】Python中的字符串与字符编码
[转]Python中的字符串与字符编码 本节内容: 前言 相关概念 Python中的默认编码 Python2与Python3中对字符串的支持 字符编码转换 一.前言 Python中的字符编码是个老生常 ...
- 补充:bytes类型以及字符编码转换
内容转自小猿圈链接:https://book.apeland.cn/details/41/ 定义 bytes类型是指一堆字节的集合,在python中以b开头的字符串都是bytes类型 b'\xe5\x ...
- python集合、字符编码、bytes与二进制
集合 用括号表示{ },可以包含多个元素,用逗号分割 用途 用于关系运算 集合特点 1.每个元素是不可变类型 2.没有重复的元素 3.无序 应用 1.set去重 set(names)的功能是将列表转换 ...
随机推荐
- OpenGL ES for Android 环境搭建
在Android上运行OpenGL ES程序需要用到GLSurfaceView控件,GLSurfaceView继承自SurfaceView并实现了GLThread,通过OpenGL ES进行绘制. O ...
- spring boot配置spring-data-jpa的时候报错CannotCreateTransactionException: Could not open JPA EntityManager for transaction; nested exception is java.lang.NoSuchMethodError
org.springframework.transaction.CannotCreateTransactionException: Could not open JPA EntityManager f ...
- python+win32--com实现excel自动化
import win32com APP_TYPE = 'Excel.Application' xlBlack,xlRed,xlGray,xlBlue = 1,3,15,41 xlBreakFull ...
- Java反射的常见用法
反射的常见用法有三类,第一类是“查看”,比如输入某个类的属性方法等信息,第二类是“装载“,比如装载指定的类到内存里,第三类是“调用”,比如通过传入参数,调用指定的方法. 1 查看属性的修饰符.类型和名 ...
- c# 三种计算程序运行时间的方法
三种计算c#程序运行时间的方法第一种:利用 System.DateTime.Now // example1: System.DateTime.Now method DateTime dt1 = Sys ...
- 从头学pytorch(二十二):全连接网络dense net
DenseNet 论文传送门,这篇论文是CVPR 2017的最佳论文. resnet一文里说了,resnet是具有里程碑意义的.densenet就是受resnet的启发提出的模型. resnet中是把 ...
- python day01学习
1.python语言 # 89年 龟叔2.python的特点 # 优点 : 简明 简单 跨平台性好 # 缺点 : 慢 -执行速度相对其他语言慢 # 编程语言的分类: # 编译型语言: c c++ j ...
- mysql常用语句及实题训练
基本语句操作 创建数据库: create database database-name 1 删除数据库: drop database database-name 1 修改数据名: RENAME DAT ...
- fgets汉字问题
#include<stdio.h> #include <stdlib.h> #define N 10 int main(int argc, char *argv[]) { FI ...
- Codeforces_334_C
http://codeforces.com/problemset/problem/334/C 求不能凑整n,和最小,数量最多的数量. #include<iostream> #include ...