【Python3爬虫】反反爬之解决前端反调试问题
一、前言
在我们爬取某些网站的时候,会想要打开 DevTools 查看元素或者抓包分析,但按下 F12 的时候,却出现了下面这一幕:

此时网页暂停加载,也就没法运行代码了,直接中断掉了,难道这就能阻止我们爬取了?不存在的,还是会有解决方案的。至于怎么做,请慢慢往下看。
二、调试
我们在了解代码的功能的时候,一般使用 JavaScript 调试工具(例如 DevTools)通过设置断点的方式来中断或阻止脚本代码的执行,而断点也是代码调试中最基本的了。
在 Chrome 中打开 DevTools,切换到 Source 选项,找到 JS 文件并打开,左下角有一个“{}”代表格式化文件,可以更方便地查看代码。然后就是设置断点了,找到可能出现问题的地方打上断点,再刷新页面,就可以直接鼠标移动到相关变量名或者方法上面查看它的值。如果想在运行到断点位置执行其它逻辑,可以直接在console区域运行相关脚本。
三、反调试
反调试就是在打开 DevTools 的时候,就会出现“Paused in debugger”,这个 debugger 导致我们无法调试 JS。
在反调试中,有时候会将函数进行重定义,并且改变其行为,就会将某些信息隐藏起来或者改变其中的一部分信息。
除了进行重定义,有的会进行混淆,例如使用语法树,还有的会进行加密,例如"_0x5219a6"这样的变量名,能很好地隐藏信息。
四、示例1
1.问题分析
一种简单的反调试措施是通过在代码中添加 debugger 实现,通过 debugger 阻止非法用户调试代码,让其陷入死循环,甚至有的还会使用匿名函数,例如:
setInterval(function() {debugger}, 100);
打开 DevTools 时就会出现“Paused in debugger”,网页也就加载中断了。
2.解决方案
这种问题解决起来还是很容易的,总结起来就是四个字:禁止断点。
在 Source 页面右侧按钮找到“Deactivate breakpoints”,或者使用快捷键 Ctrl + F8,如下图:

除了这种解决方案,还可以找到 debugger 那一行,然后右键选择“Never pause here”,就会出现一盒黄色的箭头,如下图:
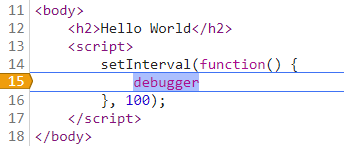
设置完之后,继续运行代码就行了。
不过这种方案和代码的编写风格有关系,例如下面这种情况,设置“Never pause here”就没用了。
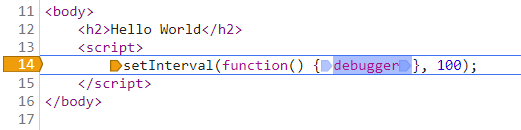
五、示例2
1.问题分析
复杂一点的反调试措施就不是直接在代码中加入 debugger 了,而是将其隐藏起来,这样就不会很轻易地被人发现了,例如下面这段代码:
function t() {try {var a = ["r", "e", "g", "g", "u", "b", "e", "d"].reverse().join("");! function e(n) {(1 !== ("" + n / n).length || 0 === n) && function() {}.constructor(a)(),e(++n)}(0)} catch (a) {setTimeout(t, 500)}}
这段代码首先是设置变量 a 表示字符串“debugger”,然后使用 constructor() 来实现调用 debugger 方法,再使用 setTimeout 实现每0.5秒中断一次。
2.解决方案
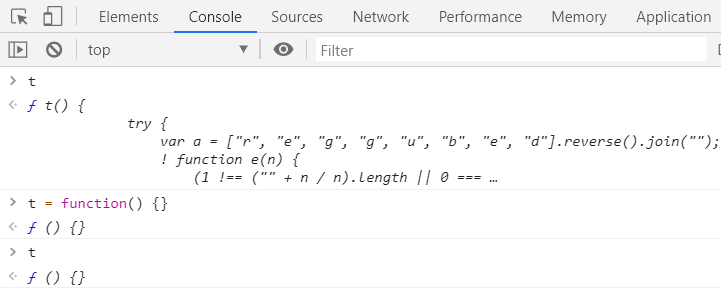
将反调试具名函数重新定义一遍,然后重新打开 DevTools,就能进行调试了。对于上面的例子,可以在控制台中输入以下内容:
t = function() {}
通过下面的截图可以发现我们确实已经修改了对于 t 的定义,因而也就不会进入 debugger 了:
【Python3爬虫】反反爬之解决前端反调试问题的更多相关文章
- 【Python3爬虫】突破反爬之应对前端反调试手段
一.前言 在我们爬取某些网站的时候,会想要打开 DevTools 查看元素或者抓包分析,但按下 F12 的时候,却出现了下面这一幕: 此时网页暂停加载,自动跳转到 Source 页面并打开了一个 ...
- python3爬虫-快速入门-爬取图片和标题
直接上代码,先来个爬取豆瓣图片的,大致思路就是发送请求-得到响应数据-储存数据,原理的话可以先看看这个 https://www.cnblogs.com/sss4/p/7809821.html impo ...
- python3 爬虫教学之爬取链家二手房(最下面源码) //以更新源码
前言 作为一只小白,刚进入Python爬虫领域,今天尝试一下爬取链家的二手房,之前已经爬取了房天下的了,看看链家有什么不同,马上开始. 一.分析观察爬取网站结构 这里以广州链家二手房为例:http:/ ...
- python3爬虫-使用requests爬取起点小说
import requests from lxml import etree from urllib import parse import os, time def get_page_html(ur ...
- 【Python3 爬虫】14_爬取淘宝上的手机图片
现在我们想要使用爬虫爬取淘宝上的手机图片,那么该如何爬取呢?该做些什么准备工作呢? 首先,我们需要分析网页,先看看网页有哪些规律 打开淘宝网站http://www.taobao.com/ 我们可以看到 ...
- 【Python3爬虫】我爬取了七万条弹幕,看看RNG和SKT打得怎么样
一.写在前面 直播行业已经火热几年了,几个大平台也有了各自独特的“弹幕文化”,不过现在很多平台直播比赛时的弹幕都基本没法看的,主要是因为网络上的喷子还是挺多的,尤其是在观看比赛的时候,很多弹幕不是喷选 ...
- python3 [爬虫实战] selenium 爬取安居客
我们爬取的网站:https://www.anjuke.com/sy-city.html 获取的内容:包括地区名,地区链接: 安居客详情 一开始直接用requests库进行网站的爬取,会访问不到数据的, ...
- python3爬虫-通过requests爬取图虫网
import requests from fake_useragent import UserAgent from requests.exceptions import Timeout from ur ...
- 【Python3 爬虫】17_爬取天气信息
需求说明 到网站http://lishi.tianqi.com/kunming/201802.html可以看到昆明2018年2月份的天气信息,然后将数据存储到数据库. 实现代码 #-*-coding: ...
随机推荐
- uni-app原生导航栏使用iconfont图标
在 iconfont 将图标下载之后,会有一个 .ttf 后缀的文件 把它放进 static 文件夹里 然后打开在iconfont下载的 demo_index.html 文件 选择 Unicode ...
- Getting started with the basics of programming exercises_5
1.编写函数,把由十六进制数字组成的字符串转换为对应的整型值 编写函数htoi(s),把由十六进制数字组成的字符串(包含可选的前缀0x或0X)转换为与之等价的整型值.字符串中允许包含的数字包括:0~9 ...
- Android Studio(八):Android Studio设置教程
Android Studio相关博客: Android Studio(一):介绍.安装.配置 Android Studio(二):快捷键设置.插件安装 Android Studio(三):设置Andr ...
- iptables禁止QQ端口
#iptables -D FORWARD -p udp --dport 8000 -j REJECT
- iptables禁止ssh端口
只允许在192.168.62.1上使用ssh远程登录,从其它计算机上禁止使用ssh #iptables -A INPUT -s 192.168.62.1 -p tcp --dport 22 -j AC ...
- KMP未优化模板、
要理解KMP最重要的一点就是防止重复的回溯. !!!很重要!!!很重要!!!很重要 要了解KMP可以去:http://www.cnblogs.com/dolphin0520/archive/2011/ ...
- 彻底解决tensorflow:ImportError: Could not find 'cudart64_90.dll' tensorflow安装
今天装tensorflow-gpu出现了很多问题 1.pip install tensorflow-gpu下载过慢 解决办法可查看 Python机器学习常用模块 2.安装完tensorflow以后,运 ...
- [转]ECMAScript 2016,2017 和 2018 中所有新功能的示例
很难追踪 JavaScript(ECMAScript)中的新功能. 想找到有用的代码示例更加困难. 因此,在本文中,我将介绍 TC39 已完成 ES2016,ES2017 和 ES2018(最终草案) ...
- 如何让索引只能被一个SQL使用
有个徒弟问我,要创建一个索引,去优化一个SQL,但是创建了索引之后其他 SQL 也要用 这个索引,其他SQL慢死了,要优化的SQL又快.遇到这种问题咋搞? 一般遇到这种问题还是很少的.处理的方法很多. ...
- 2019-1-4-win10-uwp-win2d-CanvasVirtualControl-与-CanvasAnimatedControl
title author date CreateTime categories win10 uwp win2d CanvasVirtualControl 与 CanvasAnimatedControl ...