机器学习(ML)十二之编码解码器、束搜索与注意力机制
编码器—解码器(seq2seq)
在自然语言处理的很多应用中,输入和输出都可以是不定长序列。以机器翻译为例,输入可以是一段不定长的英语文本序列,输出可以是一段不定长的法语文本序列,例如
英语输入:“They”、“are”、“watching”、“.”
法语输出:“Ils”、“regardent”、“.”
当输入和输出都是不定长序列时,我们可以使用编码器—解码器(encoder-decoder)或者seq2seq模型。这两个模型本质上都用到了两个循环神经网络,分别叫做编码器和解码器。编码器用来分析输入序列,解码器用来生成输出序列。用编码器—解码器将上述英语句子翻译成法语句子的一种方法。在训练数据集中,我们可以在每个句子后附上特殊符号“<eos>”(end of sequence)以表示序列的终止。编码器每个时间步的输入依次为英语句子中的单词、标点和特殊符号“<eos>”。下图中使用了编码器在最终时间步的隐藏状态作为输入句子的表征或编码信息。解码器在各个时间步中使用输入句子的编码信息和上个时间步的输出以及隐藏状态作为输入。 我们希望解码器在各个时间步能正确依次输出翻译后的法语单词、标点和特殊符号“<eos>”。 需要注意的是,解码器在最初时间步的输入用到了一个表示序列开始的特殊符号“<bos>”(beginning of sequence)。
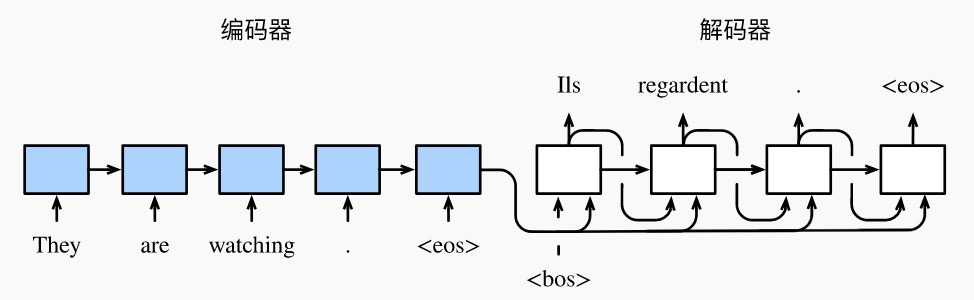
编码器

解码器

训练模型

在模型训练中,所有输出序列损失的均值通常作为需要最小化的损失函数。在上图所描述的模型预测中,我们需要将解码器在上一个时间步的输出作为当前时间步的输入。与此不同,在训练中我们也可以将标签序列(训练集的真实输出序列)在上一个时间步的标签作为解码器在当前时间步的输入。这叫作强制教学(teacher forcing)。
- 编码器-解码器(seq2seq)可以输入并输出不定长的序列。
- 编码器—解码器使用了两个循环神经网络。
- 在编码器—解码器的训练中,可以采用强制教学。
束搜索
在准备训练数据集时,我们通常会在样本的输入序列和输出序列后面分别附上一个特殊符号“<eos>”表示序列的终止。我们在接下来的讨论中也将沿用上一节的全部数学符号。为了便于讨论,假设解码器的输出是一段文本序列。设输出文本词典y包含特殊符号“<eos>”)的大小为|y|,输出序列的最大长度为T',所有可能的输出序列一共有O(|Y|T′)种。这些输出序列中所有特殊符号“<eos>”后面的子序列将被舍弃。
贪婪搜索

穷举搜索

束搜索
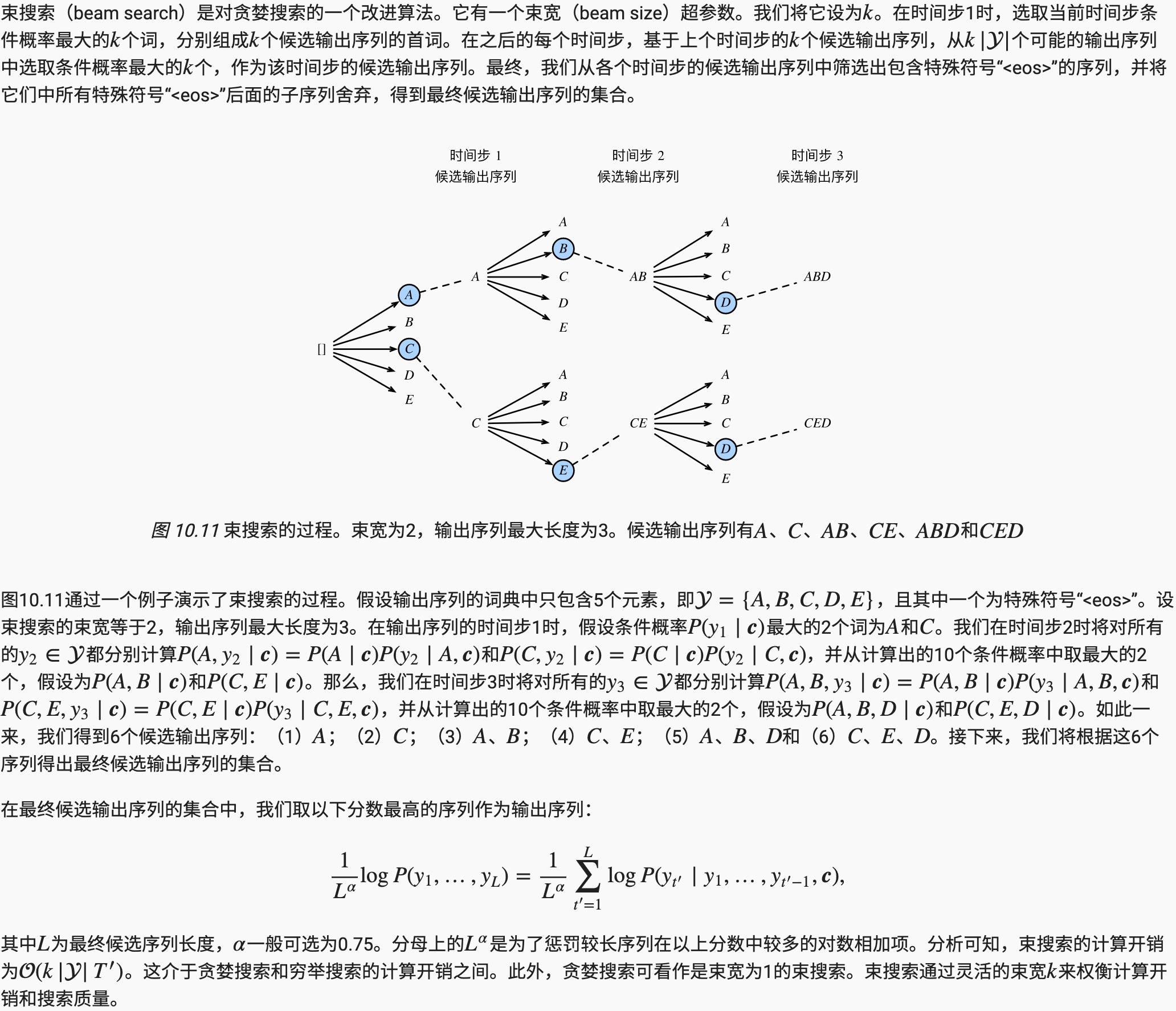
- 预测不定长序列的方法包括贪婪搜索、穷举搜索和束搜索。
- 束搜索通过灵活的束宽来权衡计算开销和搜索质量。
注意力机制
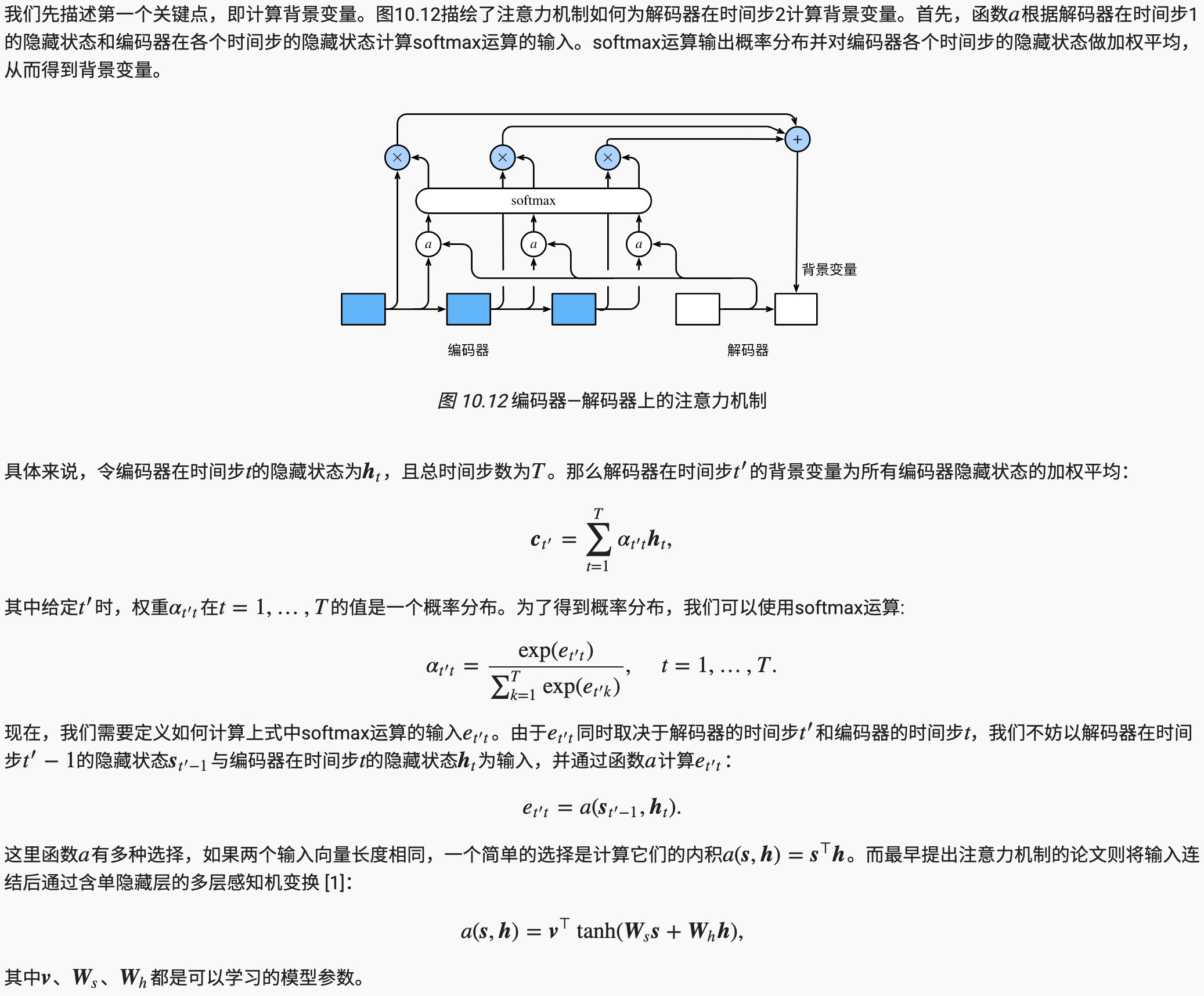
在“编码器—解码器(seq2seq)”里,解码器在各个时间步依赖相同的背景变量来获取输入序列信息。当编码器为循环神经网络时,背景变量来自它最终时间步的隐藏状态。
让我们再次思考那一节提到的翻译例子:输入为英语序列“They”“are”“watching”“.”,输出为法语序列“Ils”“regardent”“.”。不难想到,解码器在生成输出序列中的每一个词时可能只需利用输入序列某一部分的信息。例如,在输出序列的时间步1,解码器可以主要依赖“They”“are”的信息来生成“Ils”,在时间步2则主要使用来自“watching”的编码信息生成“regardent”,最后在时间步3则直接映射句号“.”。这看上去就像是在解码器的每一时间步对输入序列中不同时间步的表征或编码信息分配不同的注意力一样。这也是注意力机制的由来。
仍然以循环神经网络为例,注意力机制通过对编码器所有时间步的隐藏状态做加权平均来得到背景变量。解码器在每一时间步调整这些权重,即注意力权重,从而能够在不同时间步分别关注输入序列中的不同部分并编码进相应时间步的背景变量。
计算背景变量
矢量化计算

更新隐藏状态
现在我们描述第二个关键点,即更新隐藏状态。以门控循环单元为例,在解码器中我们可以对“门控循环单元(GRU)”一节中门控循环单元的设计稍作修改,从而变换上一时间步t′−1的输出yt′−1、隐藏状态st′−1和当前时间步t′的含注意力机制的背景变量ct′。解码器在时间步:math:t’的隐藏状态为
发展
本质上,注意力机制能够为表征中较有价值的部分分配较多的计算资源。这个有趣的想法自提出后得到了快速发展,特别是启发了依靠注意力机制来编码输入序列并解码出输出序列的变换器(Transformer)模型的设计。变换器抛弃了卷积神经网络和循环神经网络的架构。它在计算效率上比基于循环神经网络的编码器—解码器模型通常更具明显优势。含注意力机制的变换器的编码结构在后来的BERT预训练模型中得以应用并令后者大放异彩:微调后的模型在多达11项自然语言处理任务中取得了当时最先进的结果。不久后,同样是基于变换器设计的GPT-2模型于新收集的语料数据集预训练后,在7个未参与训练的语言模型数据集上均取得了当时最先进的结果 [4]。除了自然语言处理领域,注意力机制还被广泛用于图像分类、自动图像描述、唇语解读以及语音识别。
- 可以在解码器的每个时间步使用不同的背景变量,并对输入序列中不同时间步编码的信息分配不同的注意力。
- 广义上,注意力机制的输入包括查询项以及一一对应的键项和值项。
- 注意力机制可以采用更为高效的矢量化计算。
机器学习(ML)十二之编码解码器、束搜索与注意力机制的更多相关文章
- java jvm学习笔记十二(访问控制器的栈校验机制)
欢迎装载请说明出处:http://blog.csdn.net/yfqnihao 本节源码:http://download.csdn.net/detail/yfqnihao/4863854 这一节,我们 ...
- SIGAI机器学习第二十二集 AdaBoost算法3
讲授Boosting算法的原理,AdaBoost算法的基本概念,训练算法,与随机森林的比较,训练误差分析,广义加法模型,指数损失函数,训练算法的推导,弱分类器的选择,样本权重削减,实际应用. AdaB ...
- ES[7.6.x]学习笔记(十二)高亮 和 搜索建议
ES当中大部分的内容都已经学习完了,今天呢算是对前面内容的查漏补缺,把ES中非常实用的功能整理一下,在以后的项目开发中,这些功能肯定是对你的项目加分的,我们来看看吧. 高亮 高亮在搜索功能中是十分重要 ...
- 第二十二篇:C++中的多态机制
前言 封装性,继承性,多态性是面向对象语言的三大特性.其中封装,继承好理解,而多态的概念让许多初学者感到困惑.本文将讲述C++中多态的概念以及多态的实现机制. 什么是多态? 多态就是多种形态,就是许多 ...
- 剑指Offer(二十二):从上往下打印二叉树
剑指Offer(二十二):从上往下打印二叉树 搜索微信公众号:'AI-ming3526'或者'计算机视觉这件小事' 获取更多算法.机器学习干货 csdn:https://blog.csdn.net/b ...
- 剑指Offer(三十二):把数组排成最小的数
剑指Offer(三十二):把数组排成最小的数 搜索微信公众号:'AI-ming3526'或者'计算机视觉这件小事' 获取更多算法.机器学习干货 csdn:https://blog.csdn.net/b ...
- Alink漫谈(二十二) :源码分析之聚类评估
Alink漫谈(二十二) :源码分析之聚类评估 目录 Alink漫谈(二十二) :源码分析之聚类评估 0x00 摘要 0x01 背景概念 1.1 什么是聚类 1.2 聚类分析的方法 1.3 聚类评估 ...
- 【腾讯Bugly干货分享】腾讯验证码的十二年
本文来自于腾讯bugly开发者社区,未经作者同意,请勿转载,原文地址:http://dev.qq.com/topic/581301b146dfb1456904df8d Dev Club 是一个交流移动 ...
- Web 前端开发精华文章推荐(HTML5、CSS3、jQuery)【系列二十二】
<Web 前端开发精华文章推荐>2014年第一期(总第二十二期)和大家见面了.梦想天空博客关注 前端开发 技术,分享各类能够提升网站用户体验的优秀 jQuery 插件,展示前沿的 HTML ...
随机推荐
- python利用sift和surf进行图像配准
1.SIFT特征点和特征描述提取(注意opencv版本) 高斯金字塔:O组L层不同尺度的图像(每一组中各层尺寸相同,高斯函数的参数不同,不同组尺寸递减2倍) 特征点定位:极值点 特征点描述:根据不同b ...
- 自动将本地文件保存到GitHub
前言 只有光头才能变强. 文本已收录至我的GitHub精选文章,欢迎Star:https://github.com/ZhongFuCheng3y/3y 这篇文章主要讲讲如何自动将本地文件保存到GitH ...
- 从数组中取出n个不同的数组成子集 y 使 x = Σy
/** * 尝试获取arr子集 y 使 x=Σy * @param {Array} arr * @param {number} x * @param {Array} res */ f ...
- acmPush模块示例demo
感谢论坛版主 马浩川 的分享. 模块介绍: 阿里移动推送(Alibaba Cloud Mobile Push)是基于大数据的移动智能推送服务,帮助App快速集成移动推送的功能,在实现高效.精确.实时 ...
- cogs 619. [金陵中学2007] 传话 Tarjan强连通分量
619. [金陵中学2007] 传话 ★★ 输入文件:messagez.in 输出文件:messagez.out 简单对比时间限制:1 s 内存限制:128 MB [问题描述] 兴趣小 ...
- Greedy Gift Givers 贪婪的送礼者 USACO 模拟
1002: 1.1.2 Greedy Gift Givers 贪婪的送礼者 时间限制: 1 Sec 内存限制: 128 MB提交: 9 解决: 9[提交] [状态] [讨论版] [命题人:外部导入 ...
- MQ如何解决消息的顺序问题和消息的重复问题?
一.摘要 分布式消息系统作为实现分布式系统可扩展.可伸缩性的关键组件,需要具有高吞吐量.高可用等特点.而谈到消息系统的设计,就回避不了两个问题: 1.消息的顺序问题 2.消息的重复问题 二.关键特性以 ...
- electron教程(番外篇二): 使用TypeScript版本的electron, VSCode调试TypeScript, TS版本的ESLint
我的electron教程系列 electron教程(一): electron的安装和项目的创建 electron教程(番外篇一): 开发环境及插件, VSCode调试, ESLint + Google ...
- 想玩转JAVA高并发,这些概念你必须懂!
我们在找工作时,经常在招聘信息上看到有这么一条:有构建大型互联网服务及高并发等经验,你第一时间想到的是媒体常说的双十一吗?带着问题,我们一起思考技术…. 高并发高并发 它是互联网分布式系统架构设计中必 ...
- 【python系统学习06】一张图看懂列表并学会操作
点击跳转-原文地址 数据类型 - 列表(list) 「目录:」 一张图了解列表 列表是什么 列表长啥样 语法格式 代码示例 格式特征 列表定义 列表操作 - 提取单个:偏移量 什么是偏移量 偏移量提取 ...