Elasticsearch与中文分词配置
一. elasticsearch on windows
1.下载地址:
https://www.elastic.co/cn/downloads/elasticsearch
如果浏览器下载文件慢,建议使用迅雷下载,速度很快。下载版本为7.5.2
2. 修改配置文件
下载后解压,找到config\jvm.options,分配JVM堆内存大小,原则上是分配总内存的50%给 elasticsearch,但不要超过30.5GB,原因是64位寻址会导致性能下降。将默认1g改成512m, 个人电脑当默认1g时,windows安装会出现:HeapDumpOnOutOfMemoryError

3. windows安装
打开cmd执行以下命令
E:\elasticsearch-7.5.2\bin>elasticsearch-service.bat install
4.启动服务
由于elasticsearch比较耗内存,默认安装服务设置启动方式为手动,除非真的使用windwos作为服务器, 手动启动服务后,浏览器查看:http://localhost:9200/,出现以下代表成功
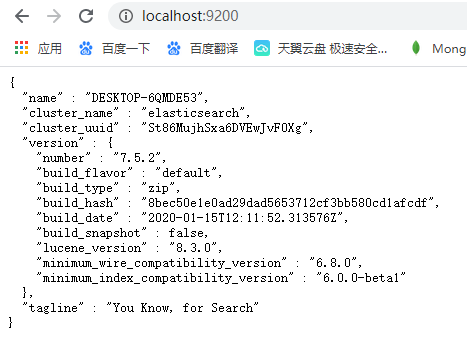
name:为集群中的节点名称,默认值为当前机器名称。
cluster_name:集群的名称,默认为elasticsearch。
查看健康状态:http://localhost:9200/_cat/health?v
查看所有索引:http://localhost:9200/_cat/indices?v
5. 其它配置
elasticsearch.yml文件
transport.port :节点与节点通信的端口,默认为9300
http.port:elasticsearch 开放的Rest接口的端口,默认为9200
network.host 默认为192.168.0.1,要设置为0.0.0.0,绑定所有本地地址,或者直接设置一个可供外网访问的地址
二. Kibana on windows
1.下载地址
https://www.elastic.co/cn/downloads/kibana
如果浏览器下载文件慢,建议使用迅雷下载,速度很快。下载版本为7.5.2
2.修改配置文件
在config\kibana.yml文件中,默认连接elasticsearch地址是:elasticsearch.hosts: ["http://localhost:9200"], 如果elasticsearch和kibana都在同一台机器,则不需要修改。
3. 启动
Kibana不同于Elasticsearch,Kibana官方并没有提供安装为系统服务的方法。在bin目录下双击kibana.bat文件。暂用控制台作为宿主。在浏览器运行http://localhost:5601/
首页右下角单击,左边的导航栏会展开,如下所示:

可以将sample flight data 飞行记录数据和sample web logs web日志记录,这二个样例数据导入,方便学习。
在左边的导航栏Dev Tools 中,可以调用 elasticsearch api 来进行操作,如下所示:

4.kibana其它配置
4.1 kibana.yml修改为中文
#i18n.locale: "en"
i18n.locale: "zh-CN"
三.分析器安装
IK 是中文分析器中比较有名的,分词包括两种: ik_smart和ik_max_word。二种区别在于提取词项的粒度,前者提取的粒度最粗,后者最细。elsaticsearch默认并不支持ik,需要安装。版本与elsaticsearch保持一致,这里下载v7.5.2。下载 地址:https://github.com/medcl/elasticsearch-analysis-ik/releases elasticsearch-analysis-ik-7.5.2.zip
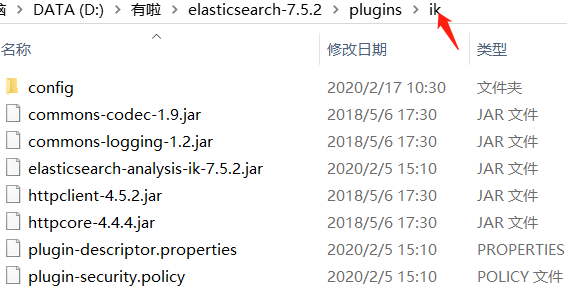
在plugins下,新建一个ik文件夹,解压放入,重启ES,如下所示:
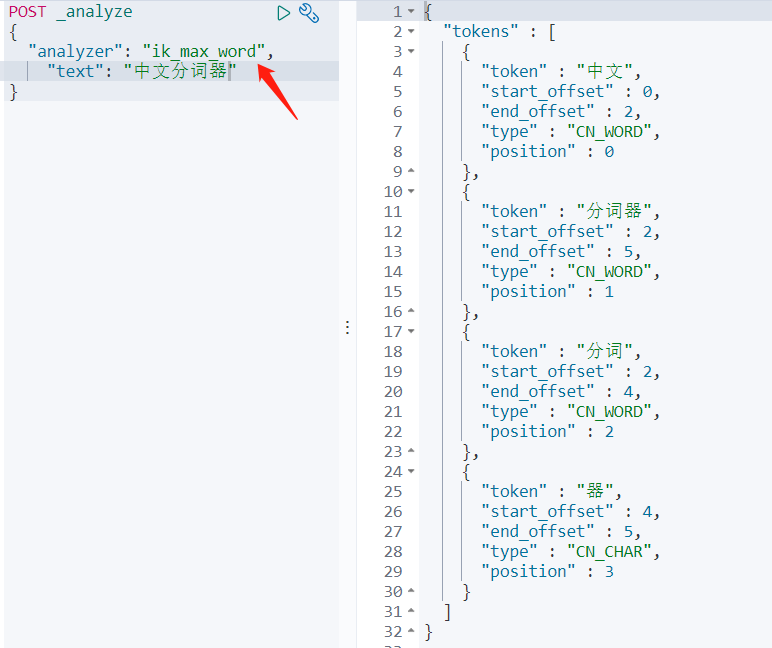
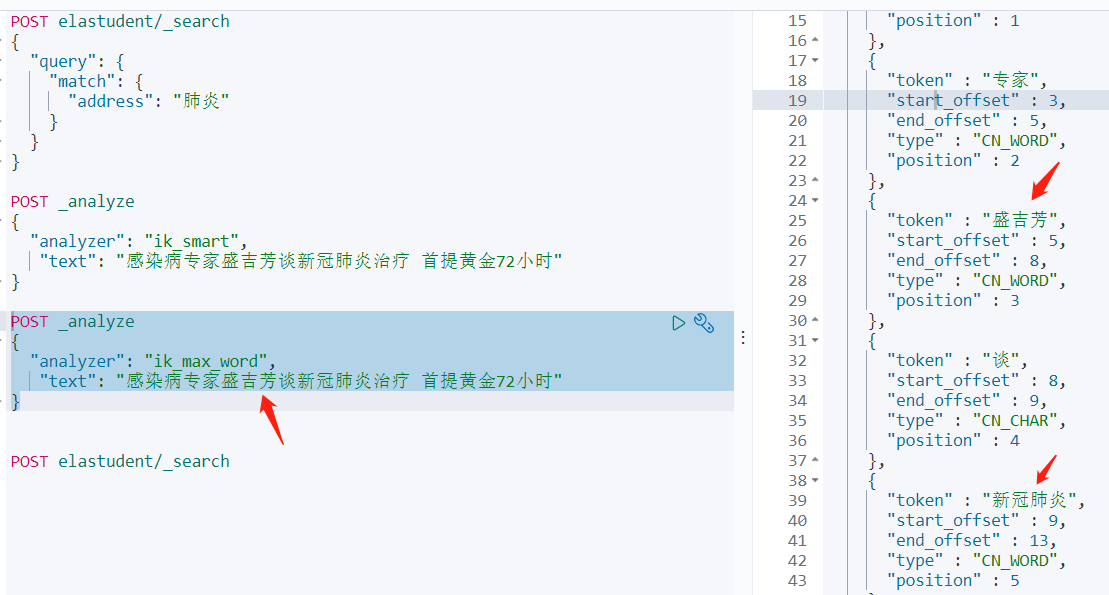
(打开kibana的Dev Tools测试)IK中文分析器测试,ik_max_word测试如下:
IK中文分析器测试,ik_smart测试如下:

四.IK扩展词典
3.1 本地配置自定义词典
如下图,先建一个txt文件,文本格式为 UTF8 编码,重命名为mydict.dic文件,添加自定义词典

将dic新文件路径配置到IKAnalyzer.cfg.xml中,如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
置后,重启es服务,再使用分词器测试如下所示:
五.IK热更新词库
官方给出建议:可以将需自动更新的热词放在一个 UTF-8 编码的 .txt 文件里,放在 nginx 或其他简易 http server 下,当 .txt 文件修改时,http server 会在客户端请求该文件时自动返回相应的 Last-Modified 和 ETag。可以另外做一个工具来从业务系统提取相关词汇,并更新这个 .txt 文件。
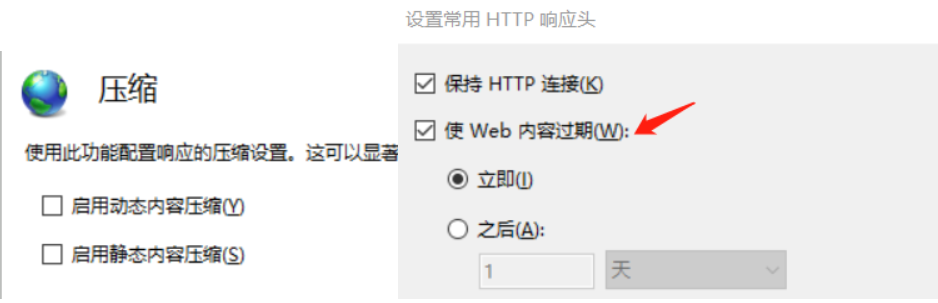
下面使用iis作为http服务器,新建一个站点,站点下有一个hotword.txt 文件,应用池托管为v 4.0经典模式。去掉压缩不然lk程序监视器读取不到。 再就是设置http响应头,因为该 http 请求需要返回两个头部(header),一个是 Last-Modified,一个是 ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。配图如下所示:
将服务器txt文件路径配置到IKAnalyzer.cfg.xml中,如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<!--<entry key="ext_dict"></entry>-->
<!--用户可以在这里配置自己的扩展停止词字典-->
<!--<entry key="ext_stopwords"></entry>-->
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://localhost:8088/hotword.txt</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords"></entry>-->
</properties>
hotword.txt配置如下所示: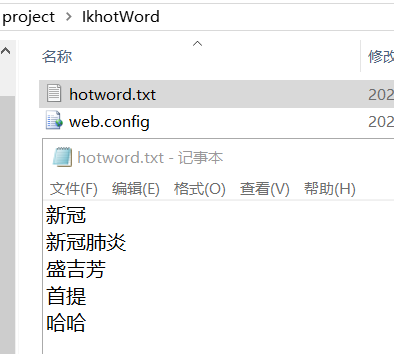
重启es服务器,在Log/elasticsearch.log中可以看到加载的词列表,如下所示:
[--18T10::,][INFO ][o.w.a.d.Monitor ] [DESKTOP-D49T1S2] try load config from D:\有啦\elasticsearch-7.5.\plugins\ik\config\IKAnalyzer.cfg.xml
[--18T10::,][INFO ][o.w.a.d.Monitor ] [DESKTOP-D49T1S2] [Dict Loading] http://localhost:8088/hotword.txt
[--18T10::,][INFO ][o.w.a.d.Monitor ] [DESKTOP-D49T1S2] 新冠
[--18T10::,][INFO ][o.w.a.d.Monitor ] [DESKTOP-D49T1S2] 新冠肺炎
[--18T10::,][INFO ][o.w.a.d.Monitor ] [DESKTOP-D49T1S2] 盛吉芳
[--18T10::,][INFO ][o.w.a.d.Monitor ] [DESKTOP-D49T1S2] 首提
[--18T10::,][INFO ][o.w.a.d.Monitor ] [DESKTOP-D49T1S2] 哈哈
[--18T10::,][INFO ][o.w.a.d.Monitor ] [DESKTOP-D49T1S2] reload ik dict finished.
测试分词,如下所示:

参考文献
Elasticsearch与中文分词配置的更多相关文章
- 为Elasticsearch添加中文分词,对比分词器效果
http://keenwon.com/1404.html Elasticsearch中,内置了很多分词器(analyzers),例如standard (标准分词器).english(英文分词)和chi ...
- 为Elasticsearch添加中文分词
Elasticsearch的中文分词很烂,所以我们需要安装ik.首先从github上下载项目,解压: cd /tmp wget https://github.com/medcl/elasticsear ...
- 【自定义IK词典】Elasticsearch之中文分词器插件es-ik的自定义词库
Elasticsearch之中文分词器插件es-ik 针对一些特殊的词语在分词的时候也需要能够识别 有人会问,那么,例如: 如果我想根据自己的本家姓氏来查询,如zhouls,姓氏“周”. 如 ...
- Elasticsearch之中文分词器插件es-ik(博主推荐)
前提 什么是倒排索引? Elasticsearch之分词器的作用 Elasticsearch之分词器的工作流程 Elasticsearch之停用词 Elasticsearch之中文分词器 Elasti ...
- 沉淀再出发:ElasticSearch的中文分词器ik
沉淀再出发:ElasticSearch的中文分词器ik 一.前言 为什么要在elasticsearch中要使用ik这样的中文分词呢,那是因为es提供的分词是英文分词,对于中文的分词就做的非常不好了 ...
- 为 Elasticsearch 添加中文分词,对比分词器效果
转自:http://keenwon.com/1404.html 为 Elasticsearch 添加中文分词,对比分词器效果 Posted in 后端 By KeenWon On 2014年12月12 ...
- Elasticsearch之中文分词器插件es-ik的自定义热更新词库
不多说,直接上干货! 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- Solr5.5.1 IK中文分词配置与使用
前言 用过Lucene.net的都知道,我们自己搭建索引服务器时和解决搜索匹配度的问题都用到过盘古分词.其中包含一个词典. 那么既然用到了这种国际化的框架,那么就避免不了中文分词.尤其是国内特殊行业比 ...
- 如何给Elasticsearch安装中文分词器IK
安装Elasticsearch安装中文分词器IK的步骤: 1. 停止elasticsearch 2.2的服务 2. 在以下地址下载对应的elasticsearch-analysis-ik插件安装包(版 ...
随机推荐
- Huffman树及其编码(STL array实现)
这篇随笔主要是Huffman编码,构建哈夫曼树有各种各样的实现方法,如优先队列,数组构成的树等,但本质都是堆. 这里我用数组来存储数据,以堆的思想来构建一个哈弗曼树,并存入vector中,进而实现哈夫 ...
- C++ | C++ 概览 基础知识 | 01
一.基本概念 1.1 类型.变量和算术运算 1.2 常量 1.3 检验和循环 1.4 指针,数组和循环 二.用户自定义类型 2.1 结构 2.2 类 2.3 枚举 三.模块化 3.1 分离编译 3.2 ...
- Nginx在Centos 7中配置开机启动
1.创建脚本 # vi /etc/init.d/nginx #!/bin/bash # nginx Startup script for the Nginx HTTP Server # it is v ...
- RabbitMQ入门(二)工作队列
在文章RabbitMQ入门(一)之Hello World,我们编写程序通过指定的队列来发送和接受消息.在本文中,我们将会创建工作队列(Work Queue),通过多个workers来分配耗时任务. ...
- 如何通过Java8的方式去统计程序执行时间?
代码如下所示 import java.time.Duration; import java.time.Instant; import java.util.concurrent.TimeUnit; pu ...
- Java数组合并方法学习。
参考博客: https://blog.csdn.net/liu_005/article/details/72760392 https://blog.csdn.net/jaycee110905/arti ...
- 60 个让程序员崩溃的瞬间,太TM真实了
前方高能!笑死人不偿命系列~ 表演即将开始,吃东西的请停下来,不然你会后悔的 1. 公司实习生找 Bug 2. 在调试时,将断点设置在错误的位置 3. 当我有一个很棒的调试想法时 4. 偶然间看到自己 ...
- ugui制作伸缩菜单
制作一个类似与这种格式的菜单,可以伸缩滑动的.今天正好项目需要用到类似功能,所以尝试了一下,做出如下的效果 虽然只是一个思路,但是可以扩展.声明一个object物体,为but,通过GetCompone ...
- NOde.js的安装和简介
1.nodejs的安装 1.1 检测nodejs的版本 node -v (version:版本) 1.2 path配置nodejs 的环境变量(当前版本都是自动安装配置环境变量)指令: path 1. ...
- ios--->const 用法总结
const 用法总结 宏.变量.常量区分 宏:只是在预处理器里进行文本替换,没有类型,不做任何类型检查,编译器可以对相同的字符串进行优化.只保存一份到 .rodata 段.甚至有相同后缀的字符串也可以 ...