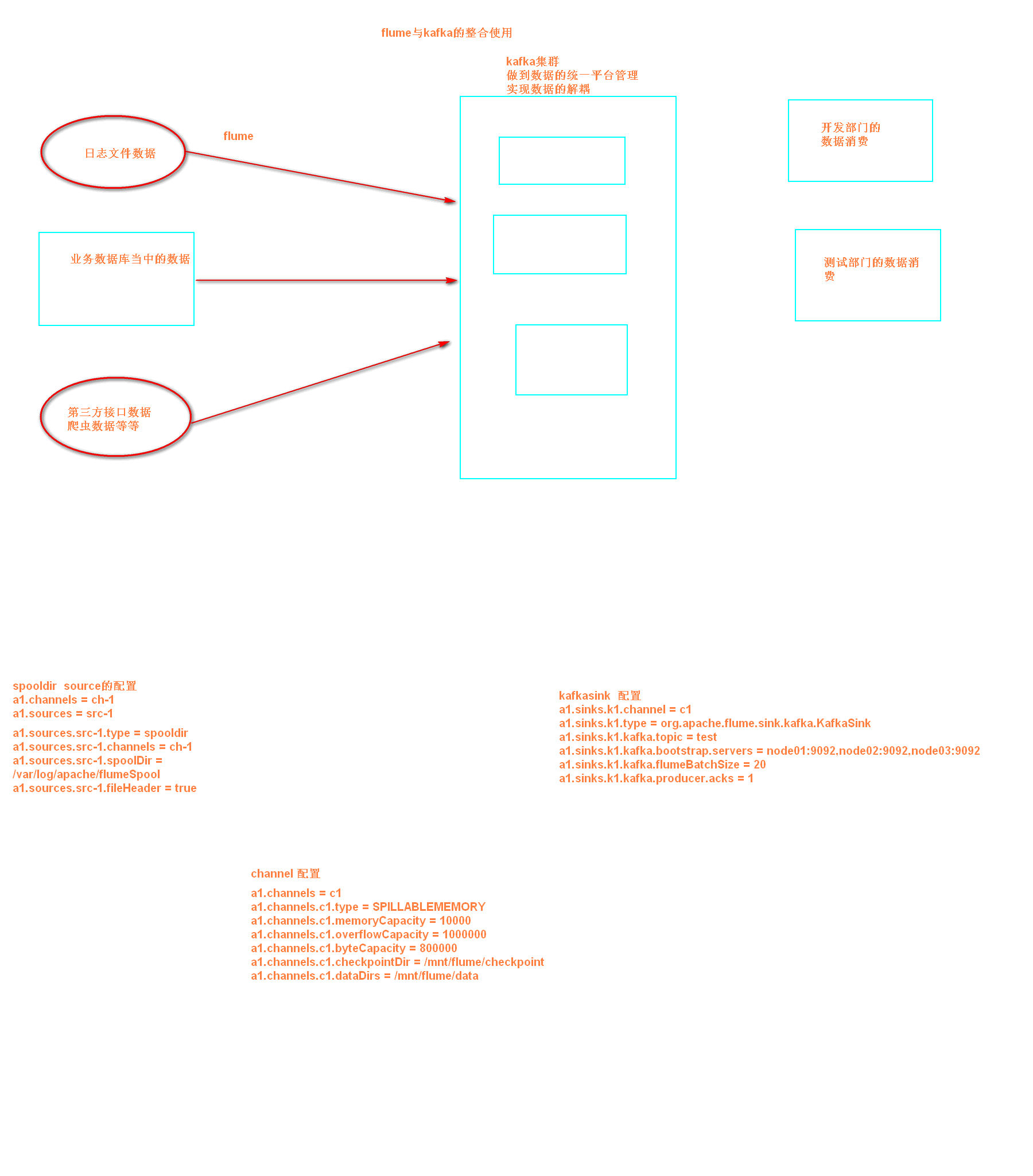
kafka和flume进行整合的日志采集的confi文件编写
配置flume.conf
为我们的source channel sink起名
a1.sources = r1
a1.channels = c1
a1.sinks = k1
指定我们的source收集到的数据发送到哪个管道
a1.sources.r1.channels = c1
指定我们的source数据收集策略
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /export/servers/flumedata
a1.sources.r1.deletePolicy = never
a1.sources.r1.fileSuffix = .COMPLETED
a1.sources.r1.ignorePattern = ^(.)*\.tmp$
a1.sources.r1.inputCharset = GBK
指定我们的channel为memory,即表示所有的数据都装进memory当中
a1.channels.c1.type = memory
指定我们的sink为kafka sink,并指定我们的sink从哪个channel当中读取数据
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = test
a1.sinks.k1.kafka.bootstrap.servers = node01:9092,node02:9092,node03:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
启动flume
bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name a1 -Dflume.root.logger=INFO,console
kafka和flume进行整合的日志采集的confi文件编写的更多相关文章
- 基于Kafka的服务端用户行为日志采集
本文来自网易云社区 作者:李勇 背景 随着互联网的不断发展,用户所产生的行为数据被越来越多的网站重视,那么什么是用户行为呢?所谓的用户行为主要由五种元素组成:时间.地点.人物.行为.行为对应的内容.为 ...
- Filebeat7 Kafka Gunicorn Flask Web应用程序日志采集
本文的内容 如何用filebeat kafka es做一个好用,好管理的日志收集工具 放弃logstash,使用elastic pipeline gunicron日志格式与filebeat/es配置 ...
- Flume+Kafka+storm的连接整合
Flume-ng Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume的文档可以看http://flume.apache.org/FlumeUserGuide.html ...
- 基于Flume+LOG4J+Kafka的日志采集架构方案
本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说 ...
- 【采集层】Kafka 与 Flume 如何选择--转自悟性的博文
[采集层]Kafka 与 Flume 如何选择 收藏 悟性 发表于 2年前 阅读 23167 收藏 16 点赞 4 评论 1 摘要: Kafka, Flume 采集层 主要可以使用Flume, Kaf ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- 日志采集框架Flume
前言 在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集.结果数据导出.任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop生态体系中 ...
- 日志采集框架 Flume
日志采集框架 Flume 1 概述 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到H ...
- Flume日志采集框架的使用
文章作者:foochane 原文链接:https://foochane.cn/article/2019062701.html Flume日志采集框架 安装和部署 Flume运行机制 采集静态文件到h ...
随机推荐
- Vue 指令大全
准备开始本章要给大家带来的内容是相关Vue中的组件以及一系列常用属性.本章合适人群囊括了除已有开发经验人员以外的小白新手,从how.why.what三个角度来让大家理解并使用该技术历史介绍angula ...
- foreach循环的跳出
由于foreach循环中不像for循环可以直接通过return或break来终止当前循环,不过这里可以借助try...catch...来完成var arr = [1,2,3,4,5,6,7,8,9,1 ...
- Delphi 左键代替右键
Delphi 左键代替右键: var Pt: TPoint; begin GetCursorPos(Pt); PopupMenu1.Popup(Pt.X, Pt.Y); end;
- Java——类的成员之五:内部类
3.6 类的成员之五:内部类 3.6.1 静态内部类 ①静态内部类可以等同看做静态变量. ②内部类重要的作用:可以访问外部类中私有的数据. ③静态内部类可以直接访问外部类的静态数据,无法直接访问成员. ...
- SCP-bzoj-1054
项目编号:bzoj-1054 项目等级:Safe 项目描述: 戳这里 特殊收容措施: 直接状压BFS即可,我实现的比较渣..复杂度O(45*216). 附录: #include <bits/st ...
- 使用gulp管理sass文件
前提是npm和ruby已经安装好 1. 新建文件夹myproject,cd进入文件夹 再npm init 初始化 2.npm install gulp --save-dev 为项目添加gulp,并将g ...
- LInux文件基础知识和文件目录操作(系统调用函数方式)
1.进程是处于活动状态的程序,某个用户通过操作系统运行程序所产生的进程代表着该用户的行为.如果用户不具备访问某个目录和文件的权限,那么该用户的进程也不能访问. 2.Linux系统中文件安全机制是通过给 ...
- 搭建单机版spark
二.下载软件 JDK,Scala,SBT,Maven 版本信息如下: JDK jdk-7u79-linux-x64.gz Scala scala-2.10.5.tgz 三.解压上述文件并进行环境变量配 ...
- HDU 6665 Calabash and Landlord (分类讨论)
2019 杭电多校 8 1009 题目链接:HDU 6665 比赛链接:2019 Multi-University Training Contest 8 Problem Description Cal ...
- centos7下jenkins升级
systemctl stop jenkins cd cd /usr/lib/jenkins/ mv jenkins.war jenkins.war.bac rz #上传下载好的最新jinkens.wa ...