浅谈python的第三方库——pandas(二)
pandas使用小贴士
1 通过Series创建DataFrame
在pandas系列的第一篇博文中曾提到,Series可视为DataFrame的一种特例,即只有一列数据。既然如此,是否可以并列多个Series组成一个DataFrame呢?当然可以,通过这种方式创建DataFrame也称为用字典建立数据,由各列列名充当字典的键,该列数据构成的Series充当该键对应的值。示例如下:
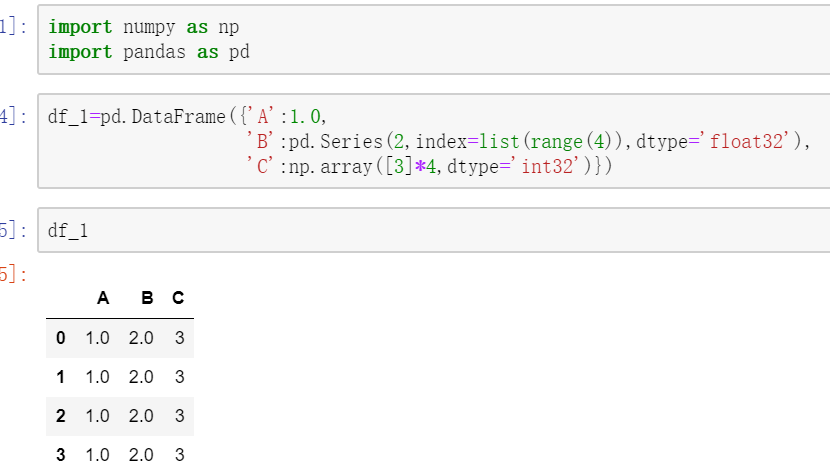
上图中,Series类型充任df_1的第二列,因为pandas默认以“0,1,2,3”形式给行列命名,本例中,列名就是字典的键,行名默认自动生成,为了与已有行名对应,在创建第二列的Series时指定了行名index=list(range(4))。
另外,numpy中的一维数组也可以起到充当DataFrame某一列数据的作用,如果给某一列赋值时只有一个值,则pandas会自动根据行的数目重复该值以补全该列。
2 查看DataFrame的常用属性
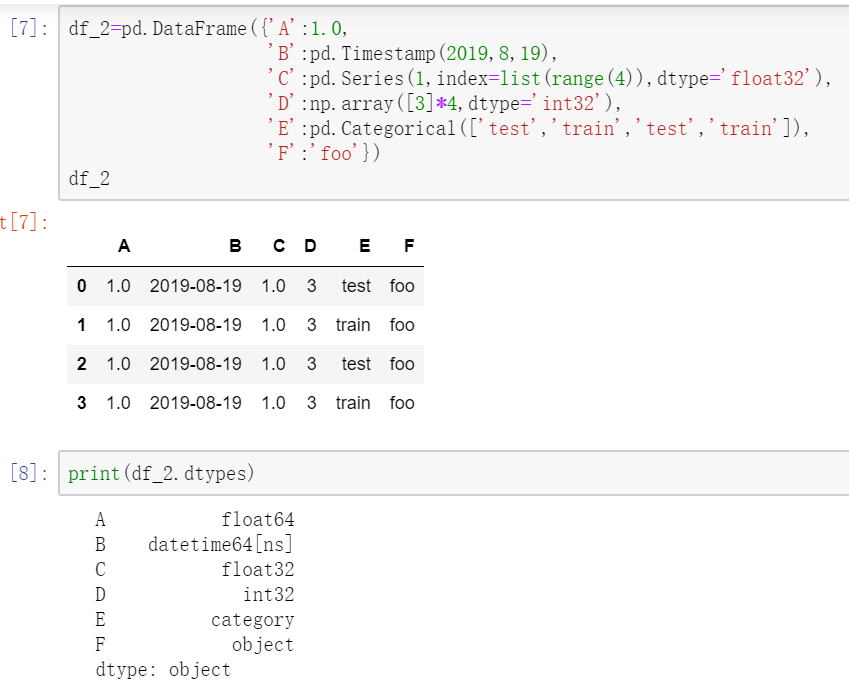
注意:下面的例子是在一个新建的df_2上演示,同样通过上一小节介绍的字典方式创建,但数据量略微大一些。
2.1 查看各列数据类型
2.2 查看行列名和具体数据

使用values方法可以直接得到和numpy中一样的多维数组形式的数据类型。
2.3 查看数据描述
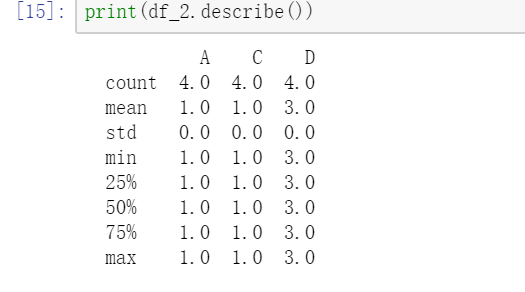
数据描述只是针对数值型数据给出某些列的统计信息。
对于pandas的一些转置、排序操作,这些方法和numpy中的方法无异,在此不再赘述。
3 设定条件选取数据
前一篇博文提到用行列名、行列位置以及二者混合的方式选取数据,其实还有一种通过给定条件选择数据的方法。
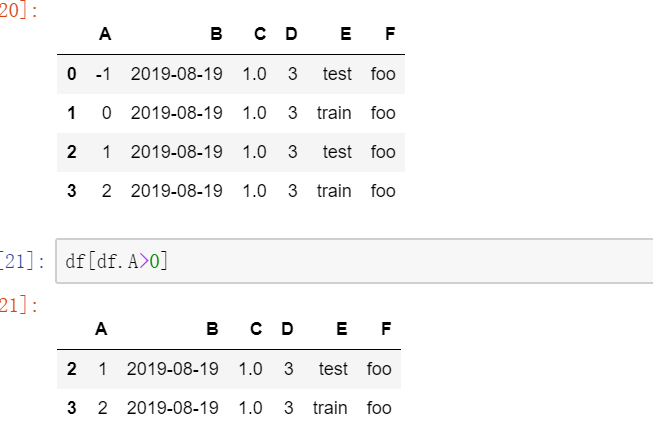
上图中,设置条件选择A列中大于零的值,然后将其所在的行抽取出来组成新的DataFrame。
当然,也可以在设定条件的同时,指定所要选取的列。

本期到此结束,后面将继续介绍pandas的常用操作。
浅谈python的第三方库——pandas(二)的更多相关文章
- 浅谈python的第三方库——pandas(一)
pandas作为python进行数据分析的常用第三方库,它是基于numpy创建的,使得运用numpy的程序也能更好地使用pandas. 1 pandas数据结构 1.1 Series 注:由于pand ...
- 浅谈python的第三方库——pandas(终)
作为pandas系列的最终章,本文引出一个数据"复制"问题. 示例如下: 从上图中可以看到:我们对data_pd做了删除一行的操作,但是这并没有改变变量data_pd在内存中的值, ...
- 浅谈python的第三方库——pandas(三)
令笔者对pandas印象最为深刻的一件事,就是在pandas中已经内置了很多数据导入导出方法,然而本人并不了解,在一次小项目的工作中曾手写了一个从excel表格导入数据到DataFrame的pytho ...
- 浅谈python的第三方库——numpy(一)
python作为广受欢迎的一门编程语言,其中很重要的一个原因便是它可以使用很多第三方库. 对第三方库的理解,在笔者看来就是一些python爱好者和专门的研发机构,为满足某一特定应用领域的需要,使用py ...
- 浅谈python的第三方库——numpy(终)
本文作为numpy系列的总结篇,继续介绍numpy中常见的使用小贴士 1 手动转换矩阵规格 转换矩阵规格,就是在保持原矩阵的元素数量和内容不变的情况下,改变原矩阵的行列数目.比如,在得到一个5x4的矩 ...
- 浅谈python的第三方库——numpy(二)
前一期博文中,初步探索了numpy中矩阵的几种运算操作,本文将展示numpy矩阵的元素抽取与合并操作. 1 元素抽取 在我们使用矩阵的时候,有时需要提取出矩阵的某些位置上的元素单独研究,这时就需要熟悉 ...
- 浅谈python的第三方库——numpy(三)
numpy库中矩阵的常用方法 1 矩阵转置 从上图可以看出:使用方法a.T可以将矩阵a转置. 2 均值与方差 注意:方法a.mean()会对矩阵a的所有元素求均值,a.var()也是考虑矩阵a的所有元 ...
- python重要第三方库pandas加载数据(详解)
Pandas数据加载 关注公众号"轻松学编程"了解更多. pandas提供了一些用于将表格型数据读取为DataFrame对象的函数,其中read_csv和read_table这两个 ...
- 浅谈python中selenium库调动webdriver驱动浏览器的实现原理
最近学web自动化时用到selenium库,感觉很神奇,遂琢磨了一下,写了点心得. 当我们输入以下三行代码并执行时,会发现新打开了一个浏览器窗口并访问了百度首页,然而这是怎么做到的呢? from se ...
随机推荐
- svg图片在vue脚手架vue-cli怎么使用
第一种 使用vue2-svg-icon npm install vue2-svg-icon --save-dev` 下载之后在mian.js引入 名字可以随便起,这里我起icon 引入svg资源 这时 ...
- 注册并加入dn42网络的方法
简介 https://dn42.net/howto/Getting-started 注册要求: 一个24小时运行的linux/BSD设备 该设备必须支持创建隧道,例如GRE,OpenVpn,IPSec ...
- JSP&Servlet学习笔记----第1/2章
HTML(HyperText Markup Language):超文本标记语言 HTTP(HyperText Transfer Protocol):超文本传输协议 URL(Uniform Resour ...
- Git的指令
一,访问本地Git 上一节我们已学会了如何注册GitHub和安装Git 现在先打开电脑终端或Git Bash,首先和Git打个招呼,输入Git 二.新建文件/进入文件夹 mkdir + 文件名 ...
- 最小生成树(一)kruskal
今天写一篇关于最小生成树的番外篇,以前写最小生成树总是用的prim,关于kruskal只是知道一些原理,一直也没有时间去学,今天偶然看了一些并查集,才想起了这个算法 会想起刚刚(预)学过的数据结构,来 ...
- phpstorm+xmapp post不能传值
https://blog.csdn.net/apple_wheat/article/details/72937035 问题的原因在于: PhpStorm默认使用的是自带的内部服务器,却不使用XAMPP ...
- Django表单Form类对空值None的替换
最近在写项目的时候用到Form,发现这个类什么都好,就是有些空值的默认赋值真是很不合我胃口. 查阅资料.官方文档后发现并没有设置该值的方式.于是,便开始了我的踩坑之路...... 不过现在完美解决了, ...
- k8s系列---EFK日志系统
文章拷于:http://blog.itpub.net/28916011/viewspace-2216748/ 用于自己备份记录错误 一个完整的k8s集群,应该包含如下六大部分:kube-dns.i ...
- Nginx 十大优化 与 防盗链
Nginx是俄罗斯人编写的十分轻量级的HTTP服务器,Nginx,它的发音为“engine X”,是一个高性能的HTTP和反向代理服务器,同时也是一个IMAP/POP3/SMTP 代理服务器.Ngin ...
- FastDFS 配置文件 tracker.conf
FastDFS 版本5.05 配置文件分为三部分 控制器:tracker.conf存储器:storage.conf 客户端:client.conf 文件位置:/etc/fdfs 基本配置(基础配置 ...