SSD基本工作原理
SSD主要由SSD控制器,FLASH存储阵列,板上DRAM(可选),以及跟HOST接口(诸如SATA,SAS, PCIe等)组成。
SSD主控通过若干个通道(channel)并行操作多块FLASH颗粒,类似RAID0,大大提高底层的带宽。举个例子,假设主控与FLASH颗粒之间有8个通道,每个通道上挂载了一个闪存颗粒,HOST与FLASH之间数据传输速率为200MB/s。该闪存颗粒Page大小为8KB,FLASH page的读取时间为Tr=50us,平均写入时间为Tp=800us,8KB数据传输时间为Tx=40us。那么底层读取最大带宽为(8KB/(50us+40us))*8 = 711MB/s,写入最大带宽为(8KB/(800us+40us))*8 = 76MB/s。从上可以看出,要提高底层带宽,可以增加底层并行的颗粒数目,也可以选择速度快的FLASH颗粒(或者让速度慢的颗粒变快,比如MLC配成SLC使用)。
我们以8通道为例,来讲讲HOST怎么读写SSD。主控通过8通道连接8个FLASH DIE,为方便解释,这里只画了每个DIE里的一个Block,其中每个小方块表示一个Page (假设大小为4KB)。
HOST写入4KB数据

HOST继续写入16KB数据

HOST继续写入,最后整个Block都写满
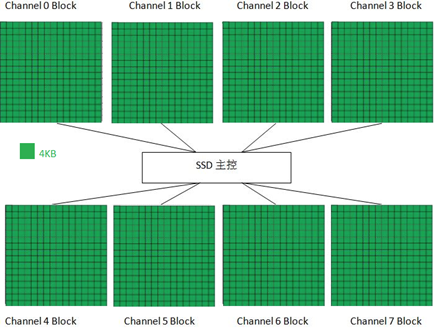
当所有Channel上的Block都写满的时候,SSD主控会挑选下一个Block以同样的方式继续写入。
HOST是通过LBA(Logical Block Address,逻辑地址块)访问SSD的,每个LBA代表着一个Sector(一般为512B大小),操作系统一般以4K为单位访问SSD,我们把HOST访问SSD的基本单元叫用户页(Host Page)。而在SSD内部,SSD主控与FLASH之间是FLASH Page为基本单元访问FLASH的,我们称FLASH Page为物理页(Physical Page)。HOST每写入一个Host Page, SSD主控会找一个Physical Page把Host数据写入,SSD内部同时记录了这样一条映射(Map)。有了这样一个映射关系后,下次HOST需要读某个Host Page 时,SSD就知道从FLASH的哪个位置把数据读取上来。

SSD内部维护了一张映射表(Map Table),HOST每写入一个Host Page,就会产生一个新的映射关系,这个映射关系会加入(第一次写)或者更改(覆盖写)Map Table;当读取某个Host Page时, SSD首先查找Map Table中该Host Page对应的Physical Page,然后再访问Flash读取相应的Host数据。

一张Map Table有多大呢?这里假设我们有一个256GB的SSD,以4KB Host Page为例,那么一共有约 64M(256GB/4KB)个Host Page,也就意味着SSD需要有64M大小的Map Table。Map Table中的每个Entry存储的就是物理地址(Physical Page Address),假设其为4Byte (32 bits) ,那么整个Map Table的大小为64M*4B = 256MB。
对绝大多数SSD,我们可以看到上面都有板载DRAM,其主要作用就是用来存储这张映射表。也有例外,比如基于Sandforce主控的SSD,它并不支持板载DRAM,那么它的映射表存在哪里呢?SSD工作时,它的绝大部分映射是存储在FLASH里面,还有一部分存储在片上RAM上。当HOST需要读取一笔数据时,对有板载DRAM的SSD来说,只要查找DRAM当中的映射表,获取到物理地址后访问FLASH从而得到HOST数据.这期间只需要访问一次FLASH;而对Sandforce的SSD来说,它首先看看该Host Page对应的映射关系是否在RAM内,如果在,那好办,直接根据映射关系读取FLASH;如果该映射关系不在RAM内,那么它首先需要把映射关系从FLASH里面读取出来,然后再根据这个映射关系读取Host数据,这就意味着相比有DRAM的SSD,它需要读取两次FLASH才能把HOST数据读取出来,底层有效带宽减半。对HOST随机读来说,由于片上RAM有限,映射关系Cache命中(映射关系在片上RAM)的概率很小,所以对它来说,基本每次读都需要访问两次FLASH,所以我们可以看到基于Sandforce主控的SSD随机读取性能是不太理想的。
继续回到之前的SSD写操作。当整个SSD写满后,从用户角度来看,如果想写入新的数据,则必须删除一些数据,然后腾出空间再写。用户在删除和写入数据的过程中,会导致一些Block里面的数据变无效或者变老。如下图所示(绿色小方块代表有效数据,红色小方块代表无效数据):

Block中的数据变老或者无效,是指没有任何映射关系指向它们,用户不会访问到这些FLASH空间,它们被新的映射关系所取代。比如有一个Host Page A,开始它存储在FLASH空间的X,映射关系为A->X。后来,HOST重写了该Host Page,由于FLASH不能覆盖写,SSD内部必须寻找一个没有写过的位置写入新的数据,假设为Y,这个时候新的映射关系建立:A->Y,之前的映射关系解除,位置X上的数据变老失效,我们把这些数据叫垃圾数据。
随着HOST的持续写入,FLASH存储空间慢慢变小,直到耗尽。如果不及时清除这些垃圾数据,HOST就无法写入。SSD内部都有垃圾回收机制,它的基本原理是把几个Block中的有效数据(非垃圾数据,上图中的绿色小方块表示的)集中搬到一个新的Block上面去,然后再把这几个Block擦除掉,这样就产生新的可用Block了。

上图中,Block x上面有效数据为A,B,C,Block y上面有效数据为D,E,F,G,红色方块为无效数据。垃圾回收机制就是先找一个未写过的可用Block z,然后把Block x和Block y的有效数据搬移到Block z上面去,这样Block x和Block y上面就没有任何有效数据,可以擦除变成两个可用的Block。

一块刚买的SSD,你会发现写入速度很快,那是因为一开始总能找到可用的Block来进行写入。但是,随着你对SSD的使用,你会发现它会变慢。原因就在于SSD写满后,当你需要写入新的数据,往往需要做上述的垃圾回收:把若干个Block上面的有效数据搬移到某个Block,然后擦掉原先的Block,然后再把你的Host数据写入。这比最初单纯的找个可用的Block来写耗时多了,所以速度变慢也就可以理解了。
还是以上图为例。假设HOST要写入4KB数据 (H) ,由于当前可用Block过少,SSD开始做垃圾回收。从上图可以看出,对Block x来说,它需要把Page A,B,C的数据读出并写入到Block z,然后Block x擦除用于HOST数据写入。从Host角度,它只写了4KB数据,但从SSD内部来说,它实际写入了4个Page(Page A, B, C写入Block z,4KB数据H写入到Block x)。

2008年,Intel公司和SiliconSystems公司(2009 年被西部数字收购)第一次提出了写入放大(Write Application)并在公开稿件里用到这个术语。

在上面例子中,Host写了4KB数据,闪存写了4个4KB数据,所以上面例子中写放大为4。
对空盘来说,写放大一般为1,即Host写入多少数据,写入FLASH也是多少数据量。在Sandforce控制器出来之前,写放大最小值为1。但是由于Sandforce内部具有压缩模块,它能对Host写入的数据进行实时压缩,然后再把它们写入到NAND。举个例子,HOST写入8KB数据,经压缩后,数据变为4KB,如果这个时候还没有垃圾回收,那么写放大就只有0.5。Intel之前说写放大不可能小于1,但Sandforce打破了这个说法。
说完写放大,再谈谈预留空间(OP, Over Provisioning)。
假设一个SSD,底下所有FLASH容量为256GB,开放给用户使用也是256GB,那么问题就来了。想象一个场景,HOST持续写满整个SSD,接着删除一些文件,写入新的文件数据,试问新的数据能写入吗?在SSD底层,如果要写入新的数据,必须要有可用的空闲Block,但由于之前256GB空间已经被HOST数据占用了,根本就没有空闲Block来写你的数据。不对,你刚才不是删了一些数据吗?你可以垃圾回收呀。不错,但问题来了,在上面介绍垃圾回收的时候,我们需要有Block z来写回收来的有效数据,我们这个时候连Block z都找不到,谈什么垃圾回收?所以,最后是用户写失败。
上面这个场景至少说明了一点,SSD内部需要预留空间(需要有自己的小金库,不能工资全部上缴),这部分空间HOST是看不到的。这部分预留空间,不仅仅用以做垃圾回收,事实上,SSD内部的一些系统数据,也需要预留空间来存储,比如前面说到的映射表(Map Table),比如SSD固件,以及其它的一些SSD系统管理数据。
一般从HOST角度来看,1GB= 1,000,000,000Byte,从底层FLASH角度,1GB=1*1024*1024*1024Byte。256GB FLASH 为256*2^30 Byte,而一般说的256GB SSD 容量为256*10^9 Byte,这样,天然的有(256*2^30-256*^9)/(256*^9) = 7.37%的OP。
如果把256GB Flash容量的SSD配成240GB的,那么它的OP是多大呢?
(256*2^30-240*10^9)/(240*10^9) = 14.5%
除了满足基本的使用要求外,OP变大有什么坏处或者好处呢?坏处很显然,用户能使用的SSD容量变小。那么好处呢?
回到垃圾回收原理来。

再看一下这张图。回收Block x,上面有3个有效Page,需要读写3个Page完成整个Block的回收;而回收Block y时,则需要读写4个有效Page。两者相比,显然回收Block x比回收Block y快一些。说明一个简单的道理:一个Block上有效的数据越少(垃圾数据越多),则回收速度越快。
256GB FLASH配成256GB的SSD (OP = 7.37%), 意味着256*10^9的有效数据写到 256*2^30的空间,每个Block上面的平均有效数据率可以认为是256*10^9/256*2^30 = 93.1%。
如果配成240GB的SSD,则意味着240*10^9的有效数据写到256*2^30的空间,每个Block的平均有效数据率为240*10^9/256*2^30 = 87.3%。
OP越大,每个Block平均有效数据率越小,因此我们可以得出的结论:OP越大,垃圾回收越快,写放大越小。这就是OP大的好处。
写放大越小,意味着写入同样多的HOST数据,写入到FLASH中的数据越少,也就意味着FLASH损耗越小。FLASH都是有一定寿命的,它是用P/E数 (Program/Erase Count)来衡量的。(关于FLASH基础知识,请参考《闪存基础》)。如果SSD集中对某几个Block进行擦写,那么这几个Block很快就寿命耗尽。比如在用户空间,有些数据是频繁需要更新的,那么这些数据所在Block就需要频繁的进行擦写,这些Block的寿命就可能很快的耗尽。相反,有些数据用户是很少更新的,比如一些只读文件,那么这些数据所在的Block擦写的次数就很少。随着用户对SSD的使用,就会形成一些Block有很高的PE数,而有些Block的PE数却很低的。这不是我们想看到的,我们希望所有Block的PE数都应该差不多,就是这些Block被均衡的使用。在SSD内部,有一种叫磨损平衡(Wear Leveling,WL)的机制来保证这点。
WL有两种算法:动态WL和静态WL。所谓动态WL,就是在使用Block进行擦写操作的时候,优先挑选PE 数低的;所谓静态WL,就是把长期没有修改的老数据(如前面提到的只读文件数据)从PE数低的Block当中搬出来,然后找个PE 数高的Block进行存放,这样,之前低PE数的Block就能拿出来使用。
下面这张图诠释了无WL,动态WL和静态WL下的FLASH耐久度的区别 (假设每个Block最大PE数为10,000):(图片来自http://www.pceva.com.cn/topic/crucialssd/images/6/006.jpg)
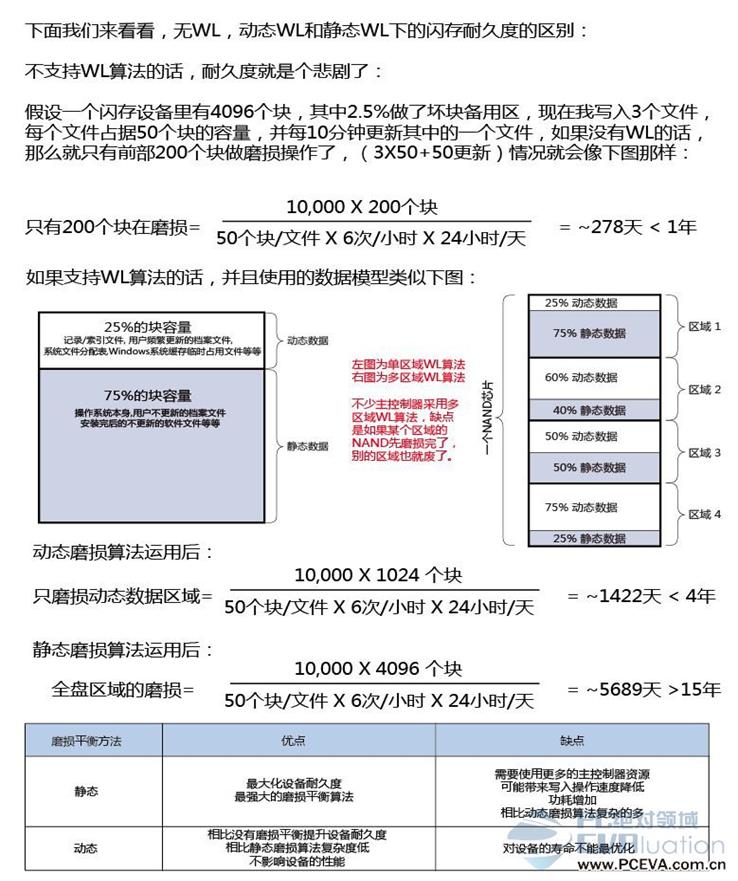
可见,使不使用WL,以及使用何种WL算法,对SSD的寿命影响是很大的。
小结:本文介绍了SSD的一些基本原理,包括SSD底层FLASH阵列的实现,Host Page与Physical Page的映射及映射表,垃圾回收机制,写放大,OP和Wear Leveling等。虽然市面上有各种各样的SSD,但它们内部这些基本的东西都是相通的。理解了这些东西,就等于拥有了一把通向SSD世界的钥匙。
转自:http://www.360doc.com/content/17/0411/11/41875488_644636812.shtml
SSD基本工作原理的更多相关文章
- [转帖]SSD的工作原理、GC和TRIM、写入放大以及性能评测
SSD的工作原理.GC和TRIM.写入放大以及性能评测 https://blog.csdn.net/scaleqiao/article/details/50511279 SSD的物理结构和工作原理 ...
- NAND闪存颗粒结构及工作原理
NAND闪存是一种电压元件,靠其内存电压来存储数据,现在我们就来谈谈它的结构及工作原理. 闪存的内部存储结构是金属-氧化层-半导体-场效晶体管(MOSFET),里面有一个浮置栅极(Floating G ...
- 关系型数据库工作原理-高速缓存(翻译自Coding-Geek文章)
本文翻译自Coding-Geek文章:< How does a relational database work>. 原文链接:http://coding-geek.com/how-dat ...
- NameNode和SecondaryNameNode工作原理剖析
NameNode和SecondaryNameNode工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode中的元数据是存储在那里的? 1>.首先,我 ...
- RabbitMQ系列(二)深入了解RabbitMQ工作原理及简单使用
深入了解RabbitMQ工作原理及简单使用 RabbitMQ系列文章 RabbitMQ在Ubuntu上的环境搭建 深入了解RabbitMQ工作原理及简单使用 RabbitMQ交换器Exchange介绍 ...
- 深入解读RabbitMQ工作原理及简单使用
RabbitMQ系列目录 RabbitMQ在Ubuntu上的环境搭建 深入解读RabbitMQ工作原理及简单使用 Rabbit的几种工作模式介绍与实践 Rabbit事务与消息确认 Rabbit集群搭建 ...
- 关系型数据库工作原理-快速缓存(翻译自Coding-Geek文章)
本文翻译自Coding-Geek文章:< How does a relational database work>. 原文链接:http://coding-geek.com/how-dat ...
- 深入了解RabbitMQ工作原理及简单使用
深入了解RabbitMQ工作原理及简单使用 RabbitMQ系列文章 RabbitMQ在Ubuntu上的环境搭建 深入了解RabbitMQ工作原理及简单使用 RabbitMQ交换器Exchange介绍 ...
- 菜鸟学Struts2——Struts工作原理
在完成Struts2的HelloWorld后,对Struts2的工作原理进行学习.Struts2框架可以按照模块来划分为Servlet Filters,Struts核心模块,拦截器和用户实现部分,其中 ...
随机推荐
- android 桌面小工具(Widget)开发教程
刚学做了哥Widget,感觉不错哦,先来秀下效果(用朋友手机截的图) 这个Widget会每隔5秒钟自动切换内容和图片,图片最好使用小图,大图会导致你手机桌面(UI)线程卡顿 教程开始: 1.首先创建一 ...
- [Git] Undo a commit that has already been pushed to the remote repository
If we pushed our changes already to the remote repository we have to pay attention to not change the ...
- Discuz! X3安装第三方主题出现:对不起,您安装的不是正版应用..的解决方法
discuz 社区在更新到3.0以上后,增加了对插件的版本检测,在安装时,可能会出现:“对不起,您安装的不是正版应用,安装程序无法继续执行”的提示,要解决这个其实挺容易的,找到以下文件: /sourc ...
- 【高德地图Android SDK】视频教学
前两天参加了高德在北航举办的公开课,感觉非常不错.完成老师布置的作业之后,还顺利地拿到了高德开发者认证证书!! 现在来跟大家分享一下,如何快速学习[高德地图Android SDK]的开发.一天包会!连 ...
- spring-boot 实现文件上传下载
@Controller public class FileUploadCtrl { @Value("${file.upload.dir}") private String path ...
- javascript constrator and prototype
揭开js之constructor属性的神秘面纱 在js里面当new了一个对象时,这中间发生了什么? MDN - new运算符 当代码 new foo(...) 执行时: 一个新对象被创建.它继承自fo ...
- 升级Linux内核导致vmware无法使用(vmnet模块无法编译)解决方式
近期将ubuntu升级到了14.04,出现了vmware无法启动的情况. 详细表现为:每次启动的时候都会弹出一个VMWare Kernel Module Updater的对话框,要求依据当前内核版本号 ...
- hdu4403A very hard Aoshu problem 线段树
//给一个长度为大于2小于15的字符串 //在当中间加'+'或'='使得其成为一个等式的方法的个数 //枚举等号位置.暴力搜索加号加的位置 #include<cstdio> #includ ...
- 转 VB ListView控件各种操作详解
Private Sub Form_Load() ListView1.ListItems.Clear '清空列表 ListView1.ColumnHeaders.Clear '清空列表头 ListVie ...
- Mongostat 2.6详解
Mongostat C:\Users\John>Mongostat connected to: 127.0.0.1 insert query update delete getmore comm ...