手把手让你实现开源企业级web高并发解决方案(lvs+heartbeat+varnish+nginx+eAccelerator+memcached)
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://freeze.blog.51cto.com/1846439/677348
此文凝聚笔者不少心血请尊重笔者劳动,转载请注明出处。违法直接人肉出电话 写大街上。
http://freeze.blog.51cto.com/
个人小站刚上线
http://www.linuxwind.com
有问题还可以来QQ群89342115交流。
今儿网友朋友说:freeze黔驴技穷了,博客也不更新,也不跟网友互动了.
笔者所使用的环境为RHEL5.4 内核版本2.6.18 实现过程在虚拟机中,所用到的安装包为DVD光盘自带rpm包
装过 Development Libraries Development Tools 包组
笔者虚拟机有限,只演示单边varnish配置
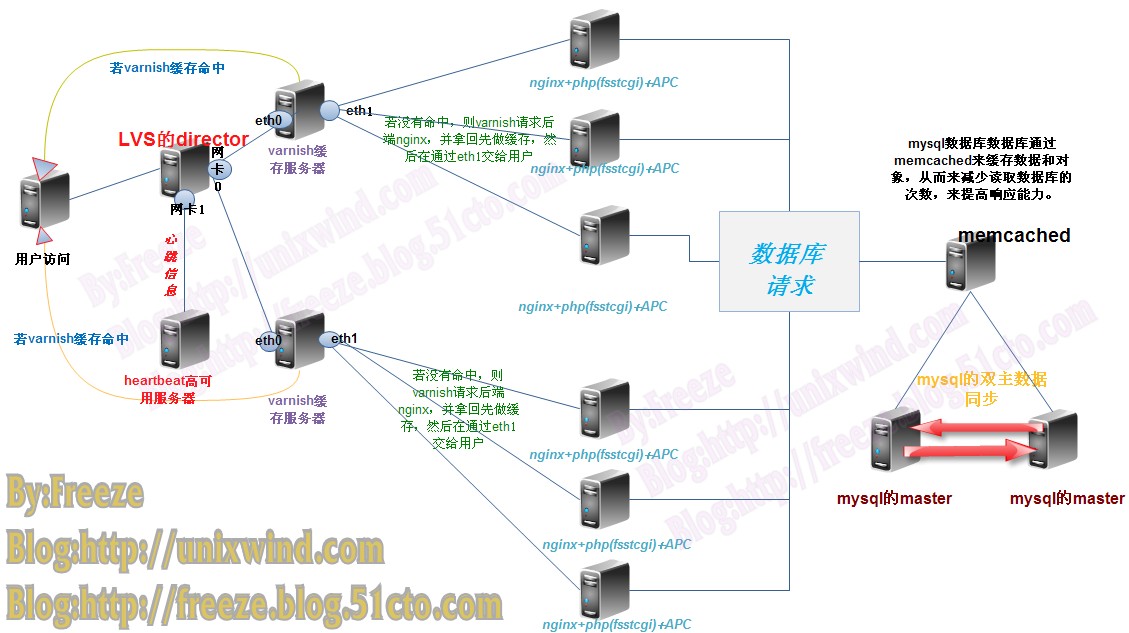
一、配置前端LVS负载均衡
笔者选用LVS的DR模型来实现集群架构,如果对DR模型不太了了解的朋友建议先去看看相关资料。
本模型实例图为:

现在director上安装ipvsadm,笔者yum配置指向有集群源所以直接用yum安装。
yum install ipvsadm

下面是Director配置:
DIP配置在接口上 172.16.100.10
VIP配置在接口别名上:172.16.100.1
varnish服务器配置:RIP配置在接口上:172.16.100.11 ;VIP配置在lo别名上
如果你要用到下面的heartbeat的ldirectord来实现资源转换,则下面的# Director配置 不用配置
- # Director配置
- ifconfig eth0 172.16.100.10/16
- ifconfig eth0:0 172.16.100.1 broadcast 172.16.100.1 netmask 255.255.255.255 up
- route add -host 172.16.100.1 dev eth0:0
- echo 1 > /proc/sys/net/ipv4/ip_forward
- # varnish服务器修改内核参数来禁止响应对VIP的ARP广播请求
- echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
- echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
- echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
- echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
- # 配置VIP
- ifconfig lo:0 172.16.100.1 broadcast 172.16.100.1 netmask 255.255.255.255 up
- # 凡是到172.16.100.1主机的一律使用lo:0响应
- route add -host 172.16.100.1 dev lo:0
- # 在Director上配置Ipvs,笔者虚拟机有限,只演示单台配置
- ipvsadm -A -t 172.16.100.1:80 -s wlc
- ipvsadm -a -t 172.16.100.1:80 -r 172.16.100.11 -g -w 2
- ipvsadm -Ln
至此,前端lvs负载均衡基本实现,下面配置高可用集群
PS:如果用ldirectord把lvs定义为资源的话,前面
二、heartbeat高可用集群
本应用模型图:

高可用则是当主服务器出现故障,备用服务器会在最短时间内代替其地位,并且保证服务不间断。
简单说明:从服务器和主服务器要有相同配置,才能在故障迁移时让无界感受不到,从而保证服务不间断运行。在你的两台机器(一台 作为主节点,另一台为从节点)上运行heartbeat, 并配置好相关的选项,最重要的是lvs资源一定要配置进去。那么开始时主节点提供lvs服务,一旦主节点崩溃,那么从节点立即接管lvs服务。
SO:
director主服务器和从服务器都有两块网卡,一块eth0是和后面varnish服务器通信,另一块eth1是彼此之间监听心跳信息和故障迁移是资源转移。笔者用的eth0是172.16.100.0网段 vip为172.16.100.1 监听心跳为eth1网卡,主从的IP分别为10.10.10.1(node1) 和10.10.10.2(node2)
修改上面模型图两台主从服务器的信息
- vim /etc/hosts
- 10.10.10.1 node1.heartbeat.com node1
- 10.10.10.2 node2.heartbeat.com node2
- #用于实现两台director节点间域名解析,此操作node1、node2相同
- vim /etc/sysconfig/network
- #设置主机名
- hostname node1.heartbeat.com
- #修改主机名使之立即生效,node2也同样修改为node2.heartbeat.com
为了安全起见,node1和node2的通信需要加密进行
- ssh-keygen -t rsa
- #生成密钥
- ssh-copy-id -i .ssh/id_rsa.pub root@node2.heartbeat.com
- #将公钥复制给node2
- ssh node2 -- ifconfig
- #执行命令测试,此时应该显示node2的ip信息
准备工作完成,下面开始安装heartbeat和ldirectord
所需要的安装包为

本人直接用yum来实现,能自动解决依赖关系 ,node1和node2都需要安装
- yum localinstall -y --nogpgcheck ./*
- #安装此目录中的所有rpm包
安装后配置:
- cd /usr/share/doc/heartbeat-2.1.4
- cp authkeys /etc/ha.d/
- cp haresources /etc/ha.d/
- cp ha.cf /etc/ha.d/
- #拷贝heartbeat所需配置文件到指定目录下
- vim /etc/ha.d/ha.cf
- bcast eth1
- #定义心跳信息从那一块网卡传输
- node node1.heartbeat.com
- node node2.heartbeat.com
- #添加这两行,用于指明心跳信号传输范围
- vim /etc/ha.d/authkeys
- auth 2
- 2 sha1 [键入随机数]
- chmod 400 authkeys
- #保存退出并修改权限400
- vim /etc/ha.d/haresource
- node1.heartbeat.com 172.16.100.1/24/eth0/172.16.0.255 ldirectord::ldirectord.cf httpd
- #末行添加主节点域名,vip资源,广播地址,ldirectord资源,以及用户提供显示错误页面的httpd资源
同步配置文件到node2
- /usr/lib/heartbeat/ha_propagate
- #脚本用来同步ha.cf和authkeys文件到node2
- scp haresources node2:/etc/ha.d/
- #复制haresource到nod2
配置ldirectord,同步配置文件
- cp /usr/share/doc/heartbeat-ldirectord-2.1.4/ldirectord.cf /etc/ha.d/ldirectord.cf
- #复制ldirector的配置文件
内容如下配置
- checktimeout=5
- #当DR收不到realserver的回应,设定几秒后判定realserver当机或挂掉了,预设5秒。
- checkinterval=3
- #查询间隔,每个几秒侦测一次realserver
- autoreload=yes
- #配置文件发生改变是否自动重读
- quiescent=yes
- #静态链接,yes:表示侦测realserver宕机,将其权值至零(如果开启了persistent参数不要用yes);no:表示侦测到宕机realserver,随即将其对应条目从ipvsadm中删除。
- virtual=172.16.100.1:80
- real=172.16.100.11:80 gate 4
- fallback=127.0.0.1:80 gate #realserver全部失败,vip指向本机80端口。
- service=http
- request="test.html" #用于健康检测的url,realserver的相对路径为var/www/html目录
- receive="ok" #用于健康检测的url包含的关键字
- scheduler=wlc
- #persistent=600
- #持久链接:表示600s之内同意ip将访问同一台realserver
- protocol=tcp
- checktype=negotiate
- #检查类型:negotiate,表示DR发送请求,realserver恢复特定字符串才表示服务正常;connect,表示DR能够连线realserver即正常。
- checkport=80
启动两个节点上的heartbeat
- service heartbeat start
- ssh node2 -- 'service heartbeat start'
- #启动两节点heartbeat服务
启动后查看/var/log/messages 可以看到启动过程,并可以手动执行/usr/lib/heartbeat/下的hb_standby 来释放资源hb_takeover来争夺资源
还可以通过ipvsadm -Ln 在主节点上查看lvs的资源状态
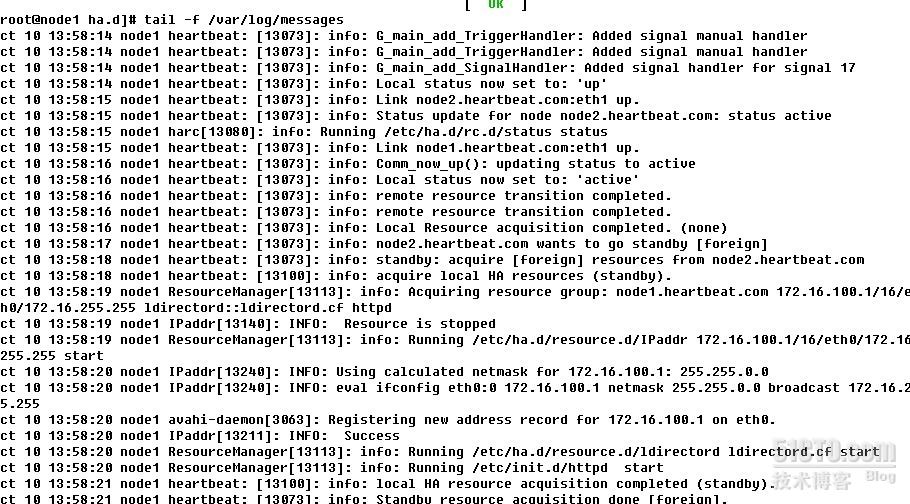

至此,带状态检测的前端集群已经布置完毕,下面就是varnish缓存服务器和后端nginx的web应用配置
三:varnish缓存服务器
有些朋友可能对varnish不太熟悉,简单做个介绍:
今天写的这篇关于Varnish的文章,已经是一篇可以完全替代Squid做网站缓存加速器的详细解决方案了。网上关于Varnish的资料很少,中文资料更是微乎其微,希望本文能够吸引更多的人研究、使用Varnish。
在我看来,使用Varnish代替Squid的理由有三点:
1、Varnish采用了“Visual Page Cache”技术,在内存的利用上,Varnish比Squid具有优势,它避免了Squid频繁在内存、磁盘中交换文件,性能要比Squid高。
2、Varnish的稳定性还不错,顺便说一句,Varnish的性能的发挥关键在于Varnish配置文档的优化.
3、通过Varnish管理端口,可以使用正则表达式快速、批量地清除部分缓存,这一点是Squid不能具备的
4. 还有一点,应该算是Varnish的缺点了吧,就是Varnish的缓存基本上在内存中,如果Varnish进程停止再启动,Varnish就会重新访问后端Web服务器,再一次进行缓存.虽然Squid性能没有Varnish高,但它停止、重启的时候,可以直接先从磁盘读取缓存数据。
varnish是一款高性能的开源HTTP加速器,挪威最大的在线报纸 Verdens Gang (http://www.vg.no) 使用3台Varnish代替了原来的12台squid,性能比以前更好。
varnish的作者Poul-Henning Kamp是FreeBSD的内核开发者之一,他认为现在的计算机比起1975年已经复杂许多。在1975年时,储存媒介只有两种:内存与硬盘。但现在计算机系统的内存除了主存外,还包括了cpu内的L1、L2,甚至有L3快取。硬盘上也有自己的快取装置,因此squid cache自行处理物件替换的架构不可能得知这些情况而做到最佳化,但操作系统可以得知这些情况,所以这部份的工作应该交给操作系统处理,这就是 Varnish cache设计架构.
现在大多数网站都抛弃了 Apache,而选择nginx是因为前者能承受的并发连接相对较低;
抛弃了 Squid,因为它在内存利用、访问速度、并发连接、清除缓存等方面不如 Varnish;
抛弃了 PHP4,因为 PHP5 处理面向对象代码的速度要比 PHP4 快,另外,PHP4 已经不再继续开发;
抛弃了 F5 BIG-IP 负载均衡交换机,F5 虽然是个好东西,但由于价格不菲,多个部门多个产品都运行在其之上,流量大、负载高,从而导致性能大打折扣;
利用 Varnish cache 减少了90%的数据库查询,解决了MySQL数据库瓶颈;
利用 Varnish cache 的内存缓存命中加快了网页的访问速度;
利用 Nginx + PHP5(FastCGI) 的胜过Apache 10倍的高并发性能,以最少的服务器数量解决了PHP动态程序访问问题;
利用 Memcached 处理实时数据读写;
利用 HAProxy 做接口服务器健康检查;
经过压力测试,每台Web服务器能够处理3万并发连接数,承受4千万PV完全没问题。
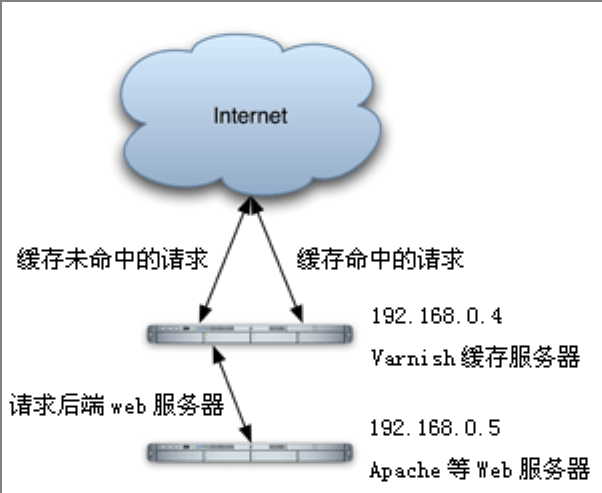
可以去varnish的官网下载最新的源码包,笔者为了便于演示,就用rpm包了,(别鄙视我)
varnish官网地址:http://www.varnish-cache.org/
我下的是最新的varnish-release-3.0-1.noarch.rpm
先rpm -ivh varnish-release-3.0-1.noarch.rpm
它的作用是给你yum生成varnish的仓库,然后你在用yum安装varnish
yum install varnish

安装好后配置文件为/etc/default.vcl
本人只实现基本功能,没有对varnish做优化,所以配置比较简单

配置完成后保存退出,需手动启动
varnishd -f /etc/varnish/default.vcl -s malloc,128m -T 127.0.0.1:2000
-f etc/varnish/default.vcl -f 指定varnishd使用哪个配置文件。
-s malloc,1G -s用来指定varnish使用的存储类型和存储容量。我使用的是 malloc 类型(malloc 是一个 C 函数,用于分配内存空间), 1G 定义多少内存被 malloced。
-T 127.0.0.1:2000 -T 指定varnish的管理端口。Varnish有一个基于文本的管理接口,启动它的话可以在不停止 varnish 的情况下来管理 varnish。您可以指定管理软件监听哪个接口。
-a 0.0.0.0:8080 指定varnish所监听所有IP发给80的http请求。如果不指定-a ,则为默认监听0.0.0.0:
ps:先配置nginx在配置varnish可以直接测试效果,本人为了演示架构层次,所以就一层一层的配置了,建议如果按我的顺序做的话,后端web服务器先用yum装上apache方便测试。varnish到此就配置成功。到此我在帮各位顺一下思路
|
目前,如果你完全按照本文章做实验,我们用了5台服务器。 一台director 它的vip为172.16.100.1 DIP为172.16.100.10 与它实现高可用的从服务器vip为172.16.100.1 DIP为 172.16.100.12 而这两台服务器都装的有heartbeat和ipvsadm 并通过ldirectord把VIP定义为资源,会自动流动,和自动添加ipvsadm分发条目 在ipvsadm中 定义的有一台varnish服务器 地址为172.16.100.11 varnish缓存服务器在做反向代理时后端是两台web服务器分别为web1和web2 IP分别为172.16.100.15和172.16.100.17 下图帮你顺下思路 |

四:nginx服务器+php+eAccelerator
(1)编译安装PHP 5.3.6所需的支持库:
- tar zxvf libiconv-1.13.1.tar.gz
- cd libiconv-1.13.1/
- ./configure --prefix=/usr/local
- make
- make install
- cd ../
- tar zxvf libmcrypt-2.5.8.tar.gz
- cd libmcrypt-2.5.8/
- ./configure
- make
- make install
- /sbin/ldconfig
- cd libltdl/
- ./configure --enable-ltdl-install
- make
- make install
- cd ../../
- tar zxvf mhash-0.9.9.9.tar.gz
- cd mhash-0.9.9.9/
- ./configure
- make
- make install
- cd ../
- ln -s /usr/local/lib/libmcrypt.la /usr/lib/libmcrypt.la
- ln -s /usr/local/lib/libmcrypt.so /usr/lib/libmcrypt.so
- ln -s /usr/local/lib/libmcrypt.so.4 /usr/lib/libmcrypt.so.4
- ln -s /usr/local/lib/libmcrypt.so.4.4.8 /usr/lib/libmcrypt.so.4.4.8
- ln -s /usr/local/lib/libmhash.a /usr/lib/libmhash.a
- ln -s /usr/local/lib/libmhash.la /usr/lib/libmhash.la
- ln -s /usr/local/lib/libmhash.so /usr/lib/libmhash.so
- ln -s /usr/local/lib/libmhash.so.2 /usr/lib/libmhash.so.2
- ln -s /usr/local/lib/libmhash.so.2.0.1 /usr/lib/libmhash.so.2.0.1
- ln -s /usr/local/bin/libmcrypt-config /usr/bin/libmcrypt-config
- tar zxvf mcrypt-2.6.8.tar.gz
- cd mcrypt-2.6.8/
- /sbin/ldconfig
- ./configure
- make
- make install
- cd ../
cd php-5.3.6
./configure --prefix=/usr/local/php-fcgi --enable-fpm --with-config-file-path=/usr/local/php-fcgi/etc --enable-zend-multibyte --with-libxml-dir=/usr/local/libxml2 --with-gd --with-jpeg-dir --with-png-dir --with-bz2 --with-freetype-dir --with-iconv-dir --with-zlib-dir --with-curl --with-mhash --with-openssl --enable-bcmath --with-mcrypt=/usr/local/libmcrypt --enable-sysvsem --enable-inline-optimization --enable-soap --enable-gd-native-ttf --enable-ftp --enable-mbstring --enable-exif --disable-debug --disable-ipv6
make
make install
cp php.ini-production /usr/local/php-fcgi/etc/php.ini
mkdir /usr/local/php-fcgi/ext
编译安装PHP5扩展模块
- 修改php.ini文件
- 手工修改:
- 查找/usr/local/php/etc/php.ini中的extension_dir = "./"
- 修改为
- extension_dir = "/usr/local/php-fcgi/lib/php/extensions/no-debug-non-zts-20090626"
- 增加以下几行
- extension = "memcache.so"
- 再查找output_buffering = Off 修改为 On
- 再查找 ;cgi.fix_pathinfo=0 去掉“;”号,防止Nginx文件类型错误解析漏洞。
- (6)配置eAccelerator加速PHP:
- mkdir -p /usr/local/eaccelerator_cache
- vi /usr/local/php-fcgi/etc/php.ini
- 跳到配置文件的最末尾,加上以下配置信息:
- [eaccelerator]
- zend_extension="/usr/local/php-fcgi/lib/php/extensions/no-debug-non-zts-20090626eaccelerator.so"
- eaccelerator.shm_size="64"
- eaccelerator.cache_dir="/usr/local/eaccelerator_cache"
- eaccelerator.enable="1"
- eaccelerator.optimizer="1"
- eaccelerator.check_mtime="1"
- eaccelerator.debug="0"
- eaccelerator.filter=""
- eaccelerator.shm_max="0"
- eaccelerator.shm_ttl="3600"
- eaccelerator.shm_prune_period="3600"
- eaccelerator.shm_only="0"
- eaccelerator.compress="1"
- eaccelerator.compress_level="9"
创建www用户和组,以及虚拟主机使用的目录:
- /usr/sbin/groupadd www
- /usr/sbin/useradd -g www www
- mkdir -p /web
- chmod +w /web
- chown -R www:www /web
创建php-fpm配置文件
- cd/usr/local/php-fcgi/etc/
- cp php-fpm.conf.default php-fpm.conf
- vim !$
- #取消下面3行前的分号
- pm.start_servers = 20
- pm.min_spare_servers = 5
- pm.max_spare_servers = 35
启动php-cgi进程,监听127.0.0.1的9000端口,
- ulimit -SHn 65535
- /usr/local/php/sbin/php-fpm start
安装Nginx 1.1.3
(1)安装Nginx所需的pcre库:
- tar zxvf pcre-8.10.tar.gz
- cd pcre-8.10/
- ./configure
- make && make install
- cd ../
(2)安装Nginx
- tar zxvf nginx-1.1.3.tar.gz
- cd nginx-1.1.3/
- ./configure --user=www \
- --group=www \
- --prefix=/usr/local/nginx \
- --with-http_stub_status_module \
- --with-http_ssl_module
- make && make install
- cd ../
(3)创建Nginx日志目录
- mkdir -p /web/logs
- chmod +w /web/logs
- chown -R www:www /web/logs
(4)创建Nginx配置文件
在/usr/local/nginx/conf/目录中创建nginx.conf文件:
- rm -f /usr/local/nginx/conf/nginx.conf
- vi /usr/local/nginx/conf/nginx.conf
输入以下内容:
|
user www www; worker_processes 8; ## 根据自己的CPU来决定到底应该是多少 #Specifies the value for maximum file descriptors that can be opened by this process. events http client_max_body_size 8m; keepalive_timeout 60; fastcgi_connect_timeout 300; gzip on; #limit_zone crawler $binary_remote_addr 10m; server #limit_conn crawler 20; location ~ .*\.(php|php5)?$ location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$ location ~ .*\.(js|css)?$ location /status { log_format access '$remote_addr - $remote_user [$time_local] "$request" ' access_log /web/logs/access.log access; |
②、在/usr/local/nginx/conf/目录中创建.conf文件:
- vi /usr/local/nginx/conf/fcgi.conf
输入以下内容:
|
fastcgi_param GATEWAY_INTERFACE CGI/1.1; |
(5)启动Nginx
- ulimit -SHn 65535
- /usr/local/nginx/sbin/nginx
(6)配置开机自动启动Nginx + PHP
- vim /etc/rc.local
在末尾增加以下内容:
|
ulimit -SHn 65535 |
启动后用浏览器测试,能出PHP则配置成功

到这里,前端的应用基本就算完成了,接下来就是数据库了
五、mysql数据库+memcached
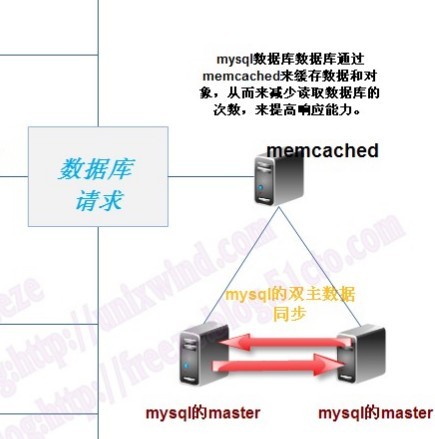
首先需要弄清一些概念
|
Memcache是什么? Memcached又是什么? 那PHP中的Memcache是什么? 简单的说一句话:Memcached 是一个服务(运行在服务器上的程序,监听某个端口),Memcache 是 一套访问Memcached的api。 两者缺一不可,不然无法正常运行。Memcache能在多台服务器上发挥很好的作用,同台服务器上用APC或Xcache效率是很可观的。 |
一、memcache
PHP 如何作为 memcached 客户端
有两种方法可以使 PHP 作为 memcached 客户端,调用 memcached 的服务进行对象存取操作。
第一种,PHP 有一个叫做 memcache 的扩展,Linux 下编译时需要带上 –enable-memcache[=DIR] 选项,编译完成后
并在php.ini配置文件中有这一项,而且库文件也有此文件
extension = "memcache.so"
除此之外,还有一种方法,可以避开扩展、重新编译所带来的麻烦,那就是直接使用 php-memcached-client。
二、memcached 服务端安装
首先是下载 memcached 了,目前最新版本是 v1.4.8,直接从官方网站即可下载到除此之外,memcached 用到了libevent,

- # tar -xzf libevent-1ast.1a.tar.gz
- # cd libevent-1.1a
- # ./configure --prefix=/usr
- # make
- # make install
- # cd ..
- # tar -xzf memcached-last.tar.gz
- # cd memcached
- # ./configure --prefix=/usr
- # make
- # make install
安装完成后需要启动
参数说明:-m 指定使用多少兆的缓存空间;-p 指定要监听的端口; -u 指定以哪个用户来运行
接下来是要安装php的memcache模块与memcached通信修改php.ini
- 找到session.save_handler,并设为 session.save_handler = memcache,把session.save_path前面的分号去掉,并设置为 session.save_path = “tcp://127.0.0.1:11211″
- session.save_handler = memcache
- session.save_path = “tcp://172.16.100.50:11211″ #memcached所在服务器地址
- 或者某个目录下的 .htaccess :
- php_value session.save_handler “memcache”
- php_value session.save_path “tcp://172.16.100.50:11211″ #memcached所在服务器地址
- 再或者在某个一个应用中:
修改完后,重启php和nginx
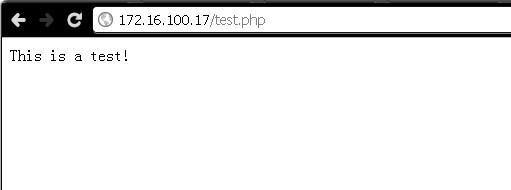
之后编辑个测试页面test.php
- <?php
- error_reporting(E_ALL);
- $memcache = new Memcache;
- $memcache->connect('172.16.100.17', 11211) or die("Could not connect");
- $memcache->set('key', 'This is a test!', 0, 60);
- $val = $memcache->get('key');
- echo $val;
- ?>
通过web浏览器访问成功图示如下:
至此,基本配置都已经完成,下面需要安装出来mysql,整个架构就基本实现了。
笔者在这里就不演示mysql的主主架构了,虚拟机真不够用了。给出一个二进制mysql的教程。
绿色二进制包安装MySQL 5.5.15
①:安装过程
- ## 为MySQL建立用户和组
- groupadd -g 3306 mysql
- useradd -g mysql -u 3306 -s /sbin/nologin -M mysql
- ## 二进制安装方式
- tar xf mysql-5.5.15-linux2.6-i686.tar.gz -C /usr/local
- ln -sv /usr/local/mysql-5.5.15-linux.2.6-i686 /usr/local/mysql
- mkdir /mydata ## 创建数据保存目录
- chown -R mysql:mysql /mydata/
- cd /usr/local/mysql
- scripts/mysql_install_db --user=mysql --datadir=/mydata/data
- chown -R root .
- ## 加入启动脚本
- cp support-files/mysql.server /etc/init.d/mysqld
- chkconfig --add mysqld
- ##修改配置文件
- cp support-files/my-large.cnf /etc/my.cnf
- ## 加入mySQL命令
- export PATH=$PATH:/usr/local/mysql/bin
- ## 定义头文件
- ln -sv /usr/local/mysql/include /usr/include/mysql
- ldconfig
②:配置过程
|
vim /etc/my.cnf |
|
vim /etc/profile 在里面加入: |
|
vim /etc/ld.so.conf.d/mysql.conf 写入 |
③:启用过程
- service mysqld start
- cd /root/lnmp
|
输入以下SQL语句,创建一个具有root权限的用户(admin)和密码(12345678): |
PS:
php在编译的时候要支持上mysql,如果是php和mysql分离开来,最好yum装上php-mysql和mysql-devel包 然后再编译带上with-mysql
varnish在实现方向代理负载均衡的时候要定义为组的结构,还要定义出动作的触发条件。
memcached 的缓存对象要设置合理,不然反而会减慢效率。
nginx在优化时要结合机器的硬件,切勿网上直接copy。
另外附加一份优化的文档,还望对各位有帮助:
- (1)Nginx的优化
- 一般来说nginx 配置文件中对优化比较有作用的为以下几项:
- worker_processes 8;
- nginx 进程数,建议按照cpu 数目来指定,一般为它的倍数。
- worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000 00100000 01000000 10000000;
- 为每个进程分配cpu,上例中将8 个进程分配到8 个cpu,当然可以写多个,或者将一个进程分配到多个cpu。
- worker_rlimit_nofile 102400;
- 这个指令是指当一个nginx 进程打开的最多文件描述符数目,理论值应该是最多打开文件数(ulimit -n)与nginx 进程数相除,但是nginx 分配请求并不是那么均匀,所以最好与ulimit-n 的值保持一致。
- use epoll;
- 使用epoll 的I/O 模型,这个不用说了吧。
- worker_connections 102400;
- 每个进程允许的最多连接数, 理论上每台nginx 服务器的最大连接数为worker_processes*worker_connections。
- keepalive_timeout 60;
- keepalive 超时时间。
- client_header_buffer_size 4k;
- 客户端请求头部的缓冲区大小,这个可以根据你的系统分页大小来设置,一般一个请求头的大小不会超过1k,不过由于一般系统分页都要大于1k,所以这里设置为分页大小。分页大小可以用命令getconf PAGESIZE 取得。
- open_file_cache max=102400 inactive=20s;
- 这个将为打开文件指定缓存,默认是没有启用的,max 指定缓存数量,建议和打开文件数一致,inactive 是指经过多长时间文件没被请求后删除缓存。
- open_file_cache_valid 30s;
- 这个是指多长时间检查一次缓存的有效信息。
- open_file_cache_min_uses 1;
- open_file_cache 指令中的inactive 参数时间内文件的最少使用次数,如果超过这个数字,文件描述符一直是在缓存中打开的,如上例,如果有一个文件在inactive 时间内一次没被使用,它将被移除。
- (2)关于内核参数的优化:请修改文件/etc/sysctl.conf
- net.ipv4.tcp_max_tw_buckets = 6000
- timewait 的数量,默认是180000。
- net.ipv4.ip_local_port_range = 1024 65000
- 允许系统打开的端口范围。
- net.ipv4.tcp_tw_recycle = 1
- 启用timewait 快速回收。
- net.ipv4.tcp_tw_reuse = 1
- 开启重用。允许将TIME-WAIT sockets 重新用于新的TCP 连接。
- net.ipv4.tcp_syncookies = 1
- 开启SYN Cookies,当出现SYN 等待队列溢出时,启用cookies 来处理。
- net.core.somaxconn = 262144
- web 应用中listen 函数的backlog 默认会给我们内核参数的net.core.somaxconn 限制到128,而nginx 定义的NGX_LISTEN_BACKLOG 默认为511,所以有必要调整这个值。
- net.core.netdev_max_backlog = 262144
- 每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
- net.ipv4.tcp_max_orphans = 262144
- 系统中最多有多少个TCP 套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,孤儿连接将即刻被复位并打印出警告信息。这个限制仅仅是为了防止简单的DoS 攻击,不能过分依靠它或者人为地减小这个值,更应该增加这个值(如果增加了内存之后)。
- net.ipv4.tcp_max_syn_backlog = 262144
- 记录的那些尚未收到客户端确认信息的连接请求的最大值。对于有128M 内存的系统而言,缺省值是1024,小内存的系统则是128。
- net.ipv4.tcp_timestamps = 0
- 时间戳可以避免序列号的卷绕。一个1Gbps 的链路肯定会遇到以前用过的序列号。时间戳能够让内核接受这种“异常”的数据包。这里需要将其关掉。
- net.ipv4.tcp_synack_retries = 1
- 为了打开对端的连接,内核需要发送一个SYN 并附带一个回应前面一个SYN 的ACK。也就是所谓三次握手中的第二次握手。这个设置决定了内核放弃连接之前发送SYN+ACK 包的数量。
- net.ipv4.tcp_syn_retries = 1
- 在内核放弃建立连接之前发送SYN 包的数量。
- net.ipv4.tcp_fin_timeout = 1
- 如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2 状态的时间。对端可以出错并永远不关闭连接,甚至意外当机。缺省值是60 秒。2.2 内核的通常值是180 秒,你可以按这个设置,但要记住的是,即使你的机器是一个轻载的WEB 服务器,也有因为大量的死套接字而内存溢出的风险,FIN- WAIT-2 的危险性比FIN-WAIT-1 要小,因为它最多只能吃掉1.5K 内存,但是它们的生存期长些。
- net.ipv4.tcp_keepalive_time = 30
- 当keepalive 起用的时候,TCP 发送keepalive 消息的频度。缺省是2 小时。
- (3)关于FastCGI 的几个指令:
- fastcgi_cache_path /usr/local/nginx/fastcgi_cache levels=1:2 keys_zone=TEST:10m inactive=5m;
- 这个指令为FastCGI 缓存指定一个路径,目录结构等级,关键字区域存储时间和非活动删除时间。
- fastcgi_connect_timeout 300;
- 指定连接到后端FastCGI 的超时时间。
- fastcgi_send_timeout 300;
- 向FastCGI 传送请求的超时时间,这个值是指已经完成两次握手后向FastCGI 传送请求的超时时间。
- fastcgi_read_timeout 300;
- 接收FastCGI 应答的超时时间,这个值是指已经完成两次握手后接收FastCGI 应答的超时时间。
- fastcgi_buffer_size 4k;
- 指定读取FastCGI 应答第一部分需要用多大的缓冲区,一般第一部分应答不会超过1k,由于页面大小为4k,所以这里设置为4k。
- fastcgi_buffers 8 4k;
- 指定本地需要用多少和多大的缓冲区来缓冲FastCGI 的应答。
- fastcgi_busy_buffers_size 8k;
- 这个指令我也不知道是做什么用,只知道默认值是fastcgi_buffers 的两倍。
- fastcgi_temp_file_write_size 8k;
- 在写入fastcgi_temp_path 时将用多大的数据块,默认值是fastcgi_buffers 的两倍。
- fastcgi_cache TEST
- 开启FastCGI 缓存并且为其制定一个名称。个人感觉开启缓存非常有用,可以有效降低CPU 负载,并且防止502 错误。
- fastcgi_cache_valid 200 302 1h;
- fastcgi_cache_valid 301 1d;
- fastcgi_cache_valid any 1m;
- 为指定的应答代码指定缓存时间,如上例中将200,302 应答缓存一小时,301 应答缓存1 天,其他为1 分钟。
- fastcgi_cache_min_uses 1;
- 缓存在fastcgi_cache_path 指令inactive 参数值时间内的最少使用次数,如上例,如果在5 分钟内某文件1 次也没有被使用,那么这个文件将被移除。
- fastcgi_cache_use_stale error timeout invalid_header http_500;
- 不知道这个参数的作用,猜想应该是让nginx 知道哪些类型的缓存是没用的。
写了2天,终于完成这篇架构了,可能还有很多细节不够完善,但主要展示的部分都已完成了,linux的精髓就是把很多小的软件组合成一个庞大的项目,各尽其能。
感谢google,感谢马哥,还应感谢反贼和远飏博客中的一些思路。
有问题还望多多交流。
此文凝聚笔者不少心血请尊重笔者劳动,转载请注明出处。违法直接人肉出电话 写大街上。
http://freeze.blog.51cto.com/
个人小站刚上线
http://www.linuxwind.com
有问题还可以来QQ群89342115交流。
转自:http://freeze.blog.51cto.com/1846439/684498
手把手让你实现开源企业级web高并发解决方案(lvs+heartbeat+varnish+nginx+eAccelerator+memcached)的更多相关文章
- 【高并发解决方案】8、Nginx/LVS/HAProxy负载均衡软件的优缺点详解
PS:Nginx/LVS/HAProxy是目前使用最广泛的三种负载均衡软件,本人都在多个项目中实施过,参考了一些资料,结合自己的一些使用经验,总结一下. 一般对负载均衡的使用是随着网站规模的提升根据不 ...
- 针对web高并发量的处理
针对web高并发量的处理 针对高并发量的处理 一个老生常谈的话题了 至于需要运维支持的那些cdn.负载均衡神马的就不赘述了 你们都懂的 虫子在此博文只讲一些从程序角度出发的一些不错的解决方案. 至于从 ...
- 高并发解决方案--负载均衡(HTTP,DNS,反向代理服务器)(解决大流量,高并发)
高并发解决方案--负载均衡(HTTP,DNS,反向代理服务器)(解决大流量,高并发) 一.总结 1.什么是负载均衡:当一台服务器的性能达到极限时,我们可以使用服务器集群来提高网站的整体性能.那么,在服 ...
- PHP面试(二):程序设计、框架基础知识、算法与数据结构、高并发解决方案类
一.程序设计 1.设计功能系统——数据表设计.数据表创建语句.连接数据库的方式.编码能力 二.框架基础知识 1.MVC框架基本原理——原理.常见框架.单一入口的工作原理.模板引擎的理解 2.常见框架的 ...
- 关于SQL SERVER高并发解决方案
现在大家都比较关心的问题就是在多用户高并发的情况下,如何开发系统,这对我们程序员来说,确实是值得研究,最近找工作面试时也经常被问到,其实我早有去关心和了解这类问题,但一直没有总结一下,导致面试时无法很 ...
- 2.高并发教程-基础篇-之nginx+mysql实现负载均衡和读写分离
技巧提示:mysql读写分离搭建好之后,配合nginx的负载均衡,可以高效的mysql的集群性能,同时免去麻烦的query分流.比如,sever1收到的请求就专门链接slave1从mysql读取数据, ...
- java并发编程与高并发解决方案
下面是我对java并发编程与高并发解决方案的学习总结: 1.并发编程的基础 2.线程安全—可见性和有序性 3.线程安全—原子性 4.安全发布对象—单例模式 5.不可变对象 6.线程封闭 7.线程不安全 ...
- JAVA系统架构高并发解决方案 分布式缓存 分布式事务解决方案
JAVA系统架构高并发解决方案 分布式缓存 分布式事务解决方案
- web 高并发分析
<高并发Web系统的设计与优化>的读后感 一口气看完了<高并发Web系统的设计与优化>,感觉受益匪浅,作者从高并发开始讨论问题,并逐步给出了非常有建设性的想法和建议,是值得我们 ...
随机推荐
- github开源库(一)
http://www.open-open.com/lib/view/open1388317199516.html 1.ActionBarSherlock ActionBarSherlock应该算得上是 ...
- Loss is its own Reward: Self-Supervision for Reinforcement Learning
作者用action, reward, state等当做lalbel,进行有监督训练.
- Linux强制杀进程命令行工具
需求, 有时候我们会有手动启动程序, 但是又在后台, 没有像服务那样有start, 和stop的程序, 这时候需要用强制杀进程方式 涉及工具, awk, sed, xargs, kill 需求一: 已 ...
- 高通 mixer_paths.xml 音频配置文件 初始化过程
记录一下高通音频配置文件mixer_paths.xml初始化过程.参考代码基于Android O. hardware/qcom/audio/hal/audio_hw.c struct audio_mo ...
- 第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- Java如何比较两个数组?
在Java中,如何比较两个数组? 示例 以下示例使用equals方法来检查两个数组是否相等. package com.yiibai; import java.util.*; public class ...
- mysql limit分页查询效率
对于有大数据量的mysql表来说,使用LIMIT分页存在很严重的性能问题. 查询从第1000000之后的30条记录: SQL代码1:平均用时6.6秒 SELECT * FROM `cdb_posts` ...
- C# byte[]保存成文件
string path = Server.MapPath(@"\a.pdf"); FileStream fs = new FileStream(path, FileMode.Cre ...
- linux中find命令
1.使用name选项: 文件名选项是find命令最常用的选项,要么单独使用该选项,要么和其他选项一起使用. 可以使用某种文件名模式来匹配文件,记住要用引号将文件名模式引起来. 不管当前路径是什么,如果 ...
- ngx-bootstrap学习笔记(一)-popover
前言 这月做了个ng2模块,其中有个校验功能,当校验不通过时给出提示,项目中使用jQuery实现,今天才发现ngx-bootstrap已经有现成功能了,且可封装成通用组件放入shareModule,使 ...