Spark SQL入门用法与原理分析
Spark SQL是为了让开发人员摆脱自己编写RDD等原生Spark代码而产生的,开发人员只需要写一句SQL语句或者调用API,就能生成(翻译成)对应的SparkJob代码并去执行,开发变得更简洁
注意:本文全部基于SparkSQL1.6
参考:http://spark.apache.org/docs/1.6.0/
一. API
Spark SQL的API方案:3种
SQL
the DataFrames API
the Datasets API.
但会使用同一个执行引擎
the same execution engine is used
(一)数据转为Dataframe
1、(半)格式化数据(HDFS文件)
SQLContext sqlContext = new org.apache.spark.sql.SQLContext(sc)
// Parquet files are self-describing so the schema is preserved.文件格式自带描述性
DataFrame df= sqlContext.read().parquet("people.parquet");
//SQLContext.read().json() on either an RDD of String, or a JSON file. not a typical JSON file(见下面的小实验)
DataFrame df = sqlContext.read().json("/testDir/people.json");
Load默认是parquet格式,通过format指定格式
DataFrame df = sqlContext.read().load("examples/src/main/resources/users.parquet");
DataFrame df = sqlContext.read().format("json").load("main/resources/people.json");
旧API 已经被废弃
DataFrame df2 =sqlContext.jsonFile("/xxx.json");
DataFrame df2 =sqlContext.parquetFile("/xxx.parquet");
2、RDD数据
SQLContext sqlContext = new org.apache.spark.sql.SQLContext(sc)
a. 通过类 利用JAVA类的反射机制
已有:JavaRDD<Person> people
DataFrame df= sqlContext.createDataFrame(people, Person.class);
b. 通过schema转换RDD
已有:StructType schema = DataTypes.createStructType(fields);
和JavaRDD<Row> rowRDD
DataFrame df= sqlContext.createDataFrame(rowRDD, schema);
3、 Hive数据(HDFS文件在数据库中的表(schema) 对应关系)
HiveContext sqlContext = new org.apache.spark.sql.hive.HiveContext(sc);
DataFrame df = sqlContext.sql("select count(*) from wangke.wangke where ns_date=20161224");
sqlContext.refreshTable("my_table")
//(if configured,sparkSQL caches metadata)
sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)");
sqlContext.sql("LOAD DATA LOCAL INPATH 'resources/kv1.txt' INTO TABLE src");
Row[] results = sqlContext.sql("FROM src SELECT key, value").collect();
4、特殊用法
DataFrame df = sqlContext.sql("SELECT * FROM parquet.`main/resources/users.parquet`");
//查询临时表people
DataFrame teenagers = sqlContext.sql("SELECT name FROMpeople WHERE age >= 13 AND age <= 19")
(二)、Dataframe使用
1、展示
df.show();
df.printSchema();
2、过滤选择
df.select("name").show();
df.select(df.col("name"), df.col("age").plus()).show();
df.filter(df.col("age").gt()).show();
df.groupBy("age").count().show();
3、写文件
df.select("name", "favorite_color").write().save("namesAndFavColors.parquet");
df.select("name", "age").write().format("parquet").save("namesAndAges.parquet");
df.write().parquet("people.parquet");
4、注册临时表
df.registerTempTable("people");
之后就可以用SQL在上面去查了
DataFrame teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
5、保存Hive表
When working with a HiveContext, DataFrames can also be saved as persistent tables using the saveAsTable command
只有HiveContext生成的Dataframe才能调用saveAsTable去持久化hive表
(三)、直接SQL操作
sqlContext.sql("create table xx.tmp like xx.xx");
sqlContext.sql("insert into table xx.tmp partition(day=20160816) select * from xx.xx where day=20160816");
sqlContext.sql("insert overwrite table xx.xx partition(day=20160816) select * from xx.tmp where day=20160816");
二. 原理
将上面的所有操作总结为如下图:
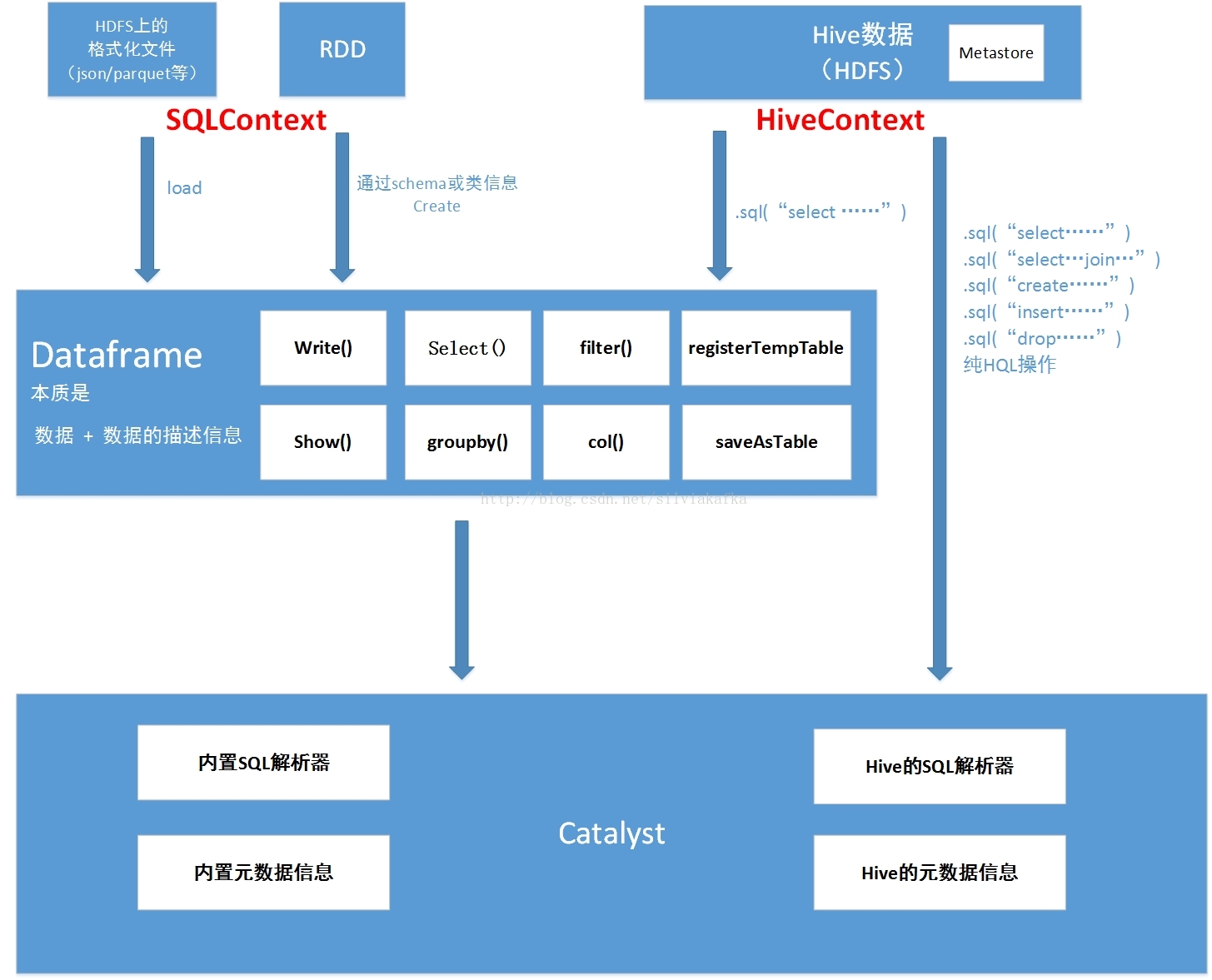
Dataframe本质是 数据 + 数据的描述信息(结构元信息)
所有的上述SQL及dataframe操作最终都通过Catalyst翻译成spark程序RDD操作代码
sparkSQL前身是shark,大量依赖Hive项目的jar包与功能,但在上面的扩展越来越难,因此出现了SparkSQL,它重写了分析器,执行器 脱离了对Hive项目的大部分依赖,基本可以独立去运行,只用到两个地方:
1.借用了hive的词汇分析的jar即HiveQL解析器
2.借用了hive的metastore和数据访问API即hiveCatalog
也就是说上图的左半部分的操作全部用的是sparkSQL本身自带的内置SQL解析器解析SQL进行翻译,用到内置元数据信息(比如结构化文件中自带的结构元信息,RDD的schema中的结构元信息)
右半部分则是走的Hive的HQL解析器,还有Hive元数据信息
因此左右两边的API调用的底层类会有不同
SQLContext使用:
简单的解析器(scala语言写的sql解析器)【比如:1.在半结构化的文件里面使用sql查询时,是用这个解析器解析的,2.访问(半)结构化文件的时候,通过sqlContext使用schema,类生成Dataframe,然后dataframe注册为表时,registAsTmpTable 然后从这个表里面进行查询时,即使用的简单的解析器,一些hive语法应该是不支持的,有待验证)】
simpleCatalog【此对象中存放关系(表),比如我们指定的schema信息,类的信息,都是关系信息】
HiveContext使用:
HiveQL解析器【支持hive的hql语法,如只有通过HiveContext生成的dataframe才能调用saveAsTable操作】
hiveCatalog(存放数据库和表的元数据信息)
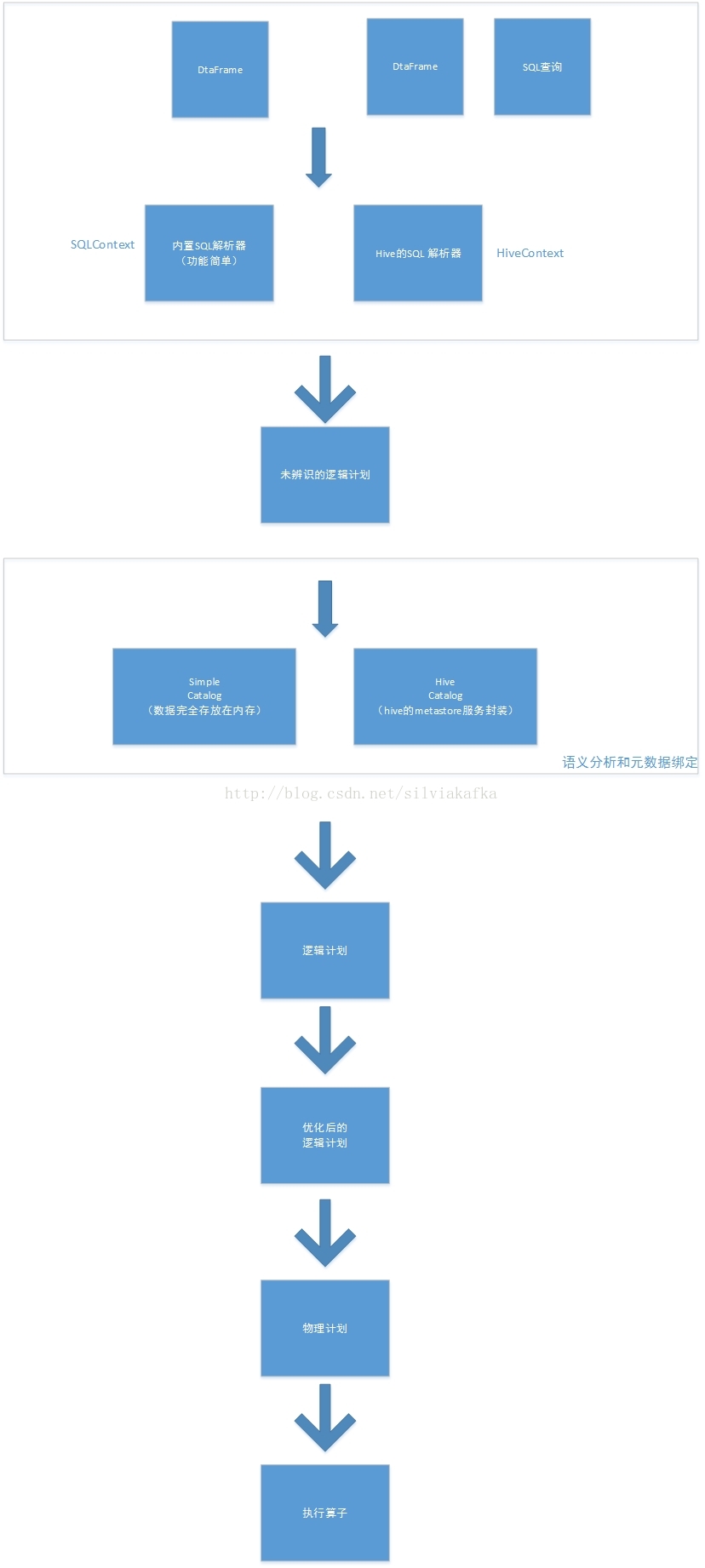
三. Catalyst
所有的SQL操作最终都通过Catalyst翻译成spark程序代码
四. 文件小实验(关于sparkSQL使用json的坑)
SQLContext sqlContext = new SQLContext(sc);
DataFrame df = sqlContext.read().json("/testDir/people.json");
将json文件放在文件系统中,一直无法找到
原来它是从HDFS里面取数据的
sc.textFile("/testDir/people.txt")也是默认从HDFS中读
注意这个路径,最开始的斜杠很重要
如果没有,则是相对路径,前面会自动加上user和用户名的路径
hdfs://10.67.1.98:9000/user/wangke/testDir/people.txt
创建了一个合法的json文件放在了HDFS下
尝试其API,发现一直报错
org.apache.spark.sql.AnalysisException: Cannot resolve column name "age" among (_corrupt_record);
原因(很坑很坑)
1. 不能写成合法的json数据
[
{
"name": "Michael",
"age":
},
{
"name": "Andy",
"age":
},
{
"name": "justin",
"age":
}
]
这个是标准的,spark不识别,呵呵呵
改:
{
"name": "Michael",
"age": } {
"name": "Andy",
"age": }{
"name": "justin",
"age":
}
依然报错
http://www.aboutyun.com/thread-12312-1-1.html
2. Json数据不能换行
{"name": "Michael","age": }
{"name": "Andy","age": }
{"name": "justin","age": }
原因:
Note that the file that is offered as a json file is not a typical JSON file. Each line must contain a separate, self-contained valid JSON object. As a consequence, a regular multi-line JSON file will most often fail.
. val jsonRdd= sc.textFile('your_json_file')
. jsonRdd.map(line => )
五. SparkSQL整体架构(前端+后端)
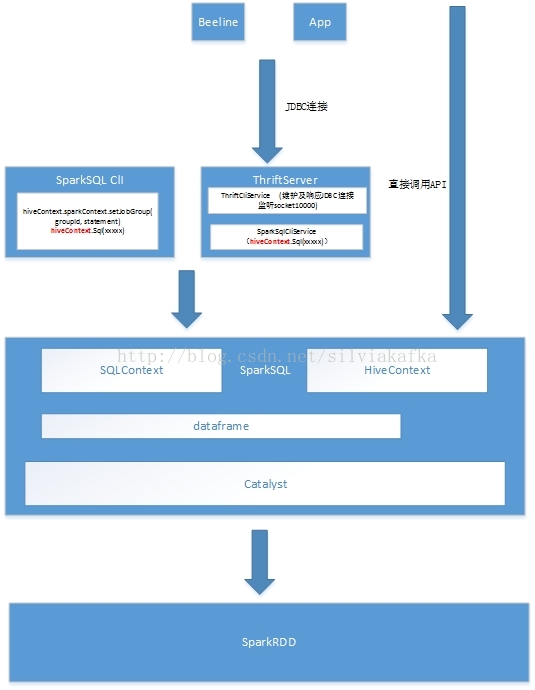
thriftserver作为一个前端,它其实只是主要分为两大块:
1.维护与用户的JDBC连接
2.通过HiveContext的API提交用户的HQL查询
Spark SQL入门用法与原理分析的更多相关文章
- spark sql 入门
package cn.my.sparksql import cn.my.sparkStream.LogLevel import org.apache.spark.{SparkConf, SparkCo ...
- Spark SQL概念学习系列之Spark SQL入门
前言 第1章 为什么Spark SQL? 第2章 Spark SQL运行架构 第3章 Spark SQL组件之解析 第4章 深入了解Spark SQL运行计划 第5章 测试环境之搭建 第6章 ...
- Spark SQL概念学习系列之Spark SQL入门(八)
前言 第1章 为什么Spark SQL? 第2章 Spark SQL运行架构 第3章 Spark SQL组件之解析 第4章 深入了解Spark SQL运行计划 第5章 测试环境之搭建 第6章 ...
- Spark SQL入门案例之人力资源系统数据处理
通过该案例,给出一个比较完整的.复杂的数据处理案例,同时给出案例的详细解析. 人力资源系统的管理内容组织结构图 1) 人力资源系统的数据库与表的构建. 2) 人力资源系统的数据的加载. 3) 人力资源 ...
- spark sql 基本用法
一.通过结构化数据创建DataFrame: publicstaticvoid main(String[] args) { SparkConf conf = new SparkConf() .se ...
- Spark2.x(六十二):(Spark2.4)共享变量 - Broadcast原理分析
之前对Broadcast有分析,但是不够深入<Spark2.3(四十三):Spark Broadcast总结>,本章对其实现过程以及原理进行分析. 带着以下几个问题去写本篇文章: 1)dr ...
- 【原创 Hadoop&Spark 动手实践 9】Spark SQL 程序设计基础与动手实践(上)
[原创 Hadoop&Spark 动手实践 9]SparkSQL程序设计基础与动手实践(上) 目标: 1. 理解Spark SQL最基础的原理 2. 可以使用Spark SQL完成一些简单的数 ...
- Spark SQL Catalyst源代码分析Optimizer
/** Spark SQL源代码分析系列*/ 前几篇文章介绍了Spark SQL的Catalyst的核心运行流程.SqlParser,和Analyzer 以及核心类库TreeNode,本文将具体解说S ...
- 第五篇:Spark SQL Catalyst源码分析之Optimizer
/** Spark SQL源码分析系列文章*/ 前几篇文章介绍了Spark SQL的Catalyst的核心运行流程.SqlParser,和Analyzer 以及核心类库TreeNode,本文将详细讲解 ...
随机推荐
- PHP 图片 平均分割
$filename = 'D://WWW/1.jpg'; $p = 5; // Get new sizes list($width, $height) = getimagesize($filename ...
- .net 取得类的属性、方法、成员及通过属性名取得属性值
//自定义的类 model m = new model(); //取得类的Type实例 //Type t = typeof(model); //取得m的Type实例 Type t = m.GetTyp ...
- 题目1013:开门人和关门人(结构体自定义cmp排序)
题目链接:http://ac.jobdu.com/problem.php?pid=1013 详解链接:https://github.com/zpfbuaa/JobduInCPlusPlus 参考代码: ...
- sencha touch 我的公用类myUtil(废弃 仅参考)
/*公共类*/ Ext.define('myUtil', { statics: { //store公用加载方法 storeLoadById: function (id) { var store = E ...
- [转载]几个有趣的Linux命令
本文给大家介绍几个有趣的Linux命令. 1. pv 命令 有时候我们在电影屏幕上看到一些字幕一个个匀速显示出来,像有人在边敲键盘,边显示一样.Linux上的pv命令可以实现这种效果. 默认情况下 ...
- Gym 101915G Robots
G. Robots time limit per test 5.0 s memory limit per test 256 MB input standard input output standar ...
- Windows下Visual Studio 2013编译Lua 5.2.3
1.创建一个Visual C++的Empty Project,如果需要支持Windows XP将Platform Toolset设置为Visual Studio 2013 - Windows XP ( ...
- cJson 创建 读取
关于c语言操作json,cjson还挺好用,许多操作已经帮开发员封装好了,使用起来很方便.资源下载地址为:http://sourceforge.net/projects/cjson/在test.c文件 ...
- 23种设计模式之单例模式(Singleton)
单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类称为单例类,它提供全局访问的方法. public class SingleTon { private static Si ...
- jenkins Email-ext plugin插件中Pre-send Script设置说明
在使用jenkins Email-ext plugin发送邮件时,项目中使用了SVN去同步,发现每次有同步,都会发送邮件,现只想SVN只更新,不发送邮件通知,这就要在Pre-send中做修改 看看官网 ...