使用MATPLOTLIB 制图(小图)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('D:\\myfiles\\study\\python\\analyse\\数据团\\城市数据团_数据分析师_体验课_课程资料\\数据资料\\地市级党委书记数据库(2000-10).csv', encoding='gbk')
# 新建变量data_age,赋值包括年份、出生年份字段内容
# 清除缺失值
data_age = data[['出生年份','党委书记姓名','年份']]
data_age_re = data_age[data_age['出生年份'].notnull()]
# 计算出整体年龄数据
df1 = 2017 - data_age_re['出生年份']
# 计算出入职年龄数据
df_yearmin = data_age_re[['党委书记姓名','年份']].groupby(data_age_re['党委书记姓名']).min()
df2 = df_yearmin['年份'].groupby(df_yearmin['年份']).count() df_yearmax = data_age_re[['党委书记姓名','年份']].groupby(data_age_re['党委书记姓名']).max()
df3 = df_yearmax['年份'].groupby(df_yearmax['年份']).count() # 专业情况:专业结构 / 专业整体情况 / 专业大类分布
# 新建变量data_major,赋值包括年份、专业等字段内容,其中1代表是,0代表否
# 清除缺失值
data_major = data[['党委书记姓名','年份','专业:人文','专业:社科','专业:理工','专业:农科','专业:医科']]
data_major_re = data_major[data_major['专业:人文'].notnull()]
# 统计每个人的专业
data_major_re['专业'] = data_major_re[['专业:人文', '专业:社科', '专业:理工', '专业:农科', '专业:医科']].idxmax(axis=1)
# 去重
data_major_st = data_major_re[['专业','党委书记姓名']].drop_duplicates()
# 计算出学历结构数据
df4 = data_major_st['专业'].groupby(data_major_st['专业']).count()
# 计算每年专业整体情况数据
df5 = pd.crosstab(data_major_re['年份'], data_major_re['专业'])
# 计算每年专业大类分布数据
df5['社科比例'] = df5['专业:社科'] / (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文'])
df5['人文比例'] = df5['专业:人文'] / (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文'])
df5['理工农医比例'] = (df5['专业:理工'] + df5['专业:医科'] + df5['专业:农科'])/ (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文']) # 年龄情况:图表绘制
# 创建一个图表,大小为12*8
fig_q2 = plt.figure(figsize = (14,12))
# 创建一个3*2的表格矩阵
ax1 = fig_q2.add_subplot(2,3,1)
ax2 = fig_q2.add_subplot(2,3,2)
ax3 = fig_q2.add_subplot(2,3,3)
ax4 = fig_q2.add_subplot(2,3,4)
ax5 = fig_q2.add_subplot(2,3,5)
ax6 = fig_q2.add_subplot(2,3,6)
# 绘制第一个表格
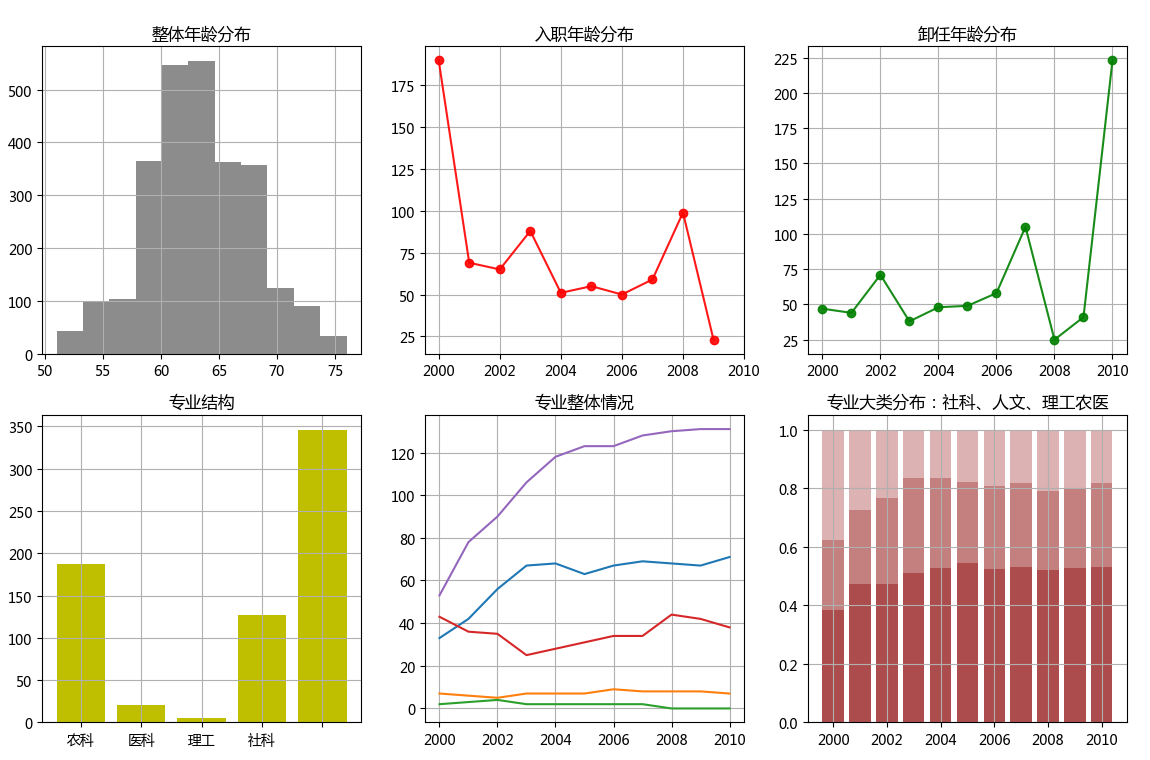
ax1.hist(df1,bins = 11,color = 'gray', alpha=0.9)
ax1.set_title('整体年龄分布')
ax1.grid(True) # 绘制第二个表格
ax2.plot(df2,color = 'r',marker = 'o',alpha=0.9)
ax2.set_title('入职年龄分布')
ax2.set_xticks(range(2000,2011,2))
ax2.grid(True) # 绘制第三个表格
ax3.plot(df3,color = 'g',marker = 'o',alpha=0.9)
ax3.set_title('卸任年龄分布')
ax3.set_xticks(range(2000,2011,2))
ax3.grid(True) # 绘制第四个表格
ax4.bar(range(len(df4)),df4,color = 'y')
ax4.set_xticklabels(['人文','农科','医科','理工','社科'])
ax4.grid(True)
ax4.set_title('专业结构') # 绘制第五个表格
ax5.plot(df5.index,df5[['专业:人文','专业:农科','专业:医科','专业:理工','专业:社科']])
ax5.grid(True)
ax5.set_title('专业整体情况') # 绘制第六个表格
ax6.bar(df5.index,df5['社科比例'],color = 'darkred',alpha=0.7)
ax6.bar(df5.index,df5['人文比例'],color = 'darkred',bottom = df5['社科比例'],alpha=0.5)
ax6.bar(df5.index,df5['理工农医比例'],color = 'darkred',bottom = df5['人文比例'] + df5['社科比例'],alpha=0.3)
ax6.grid(True)
ax6.set_title('专业大类分布:社科、人文、理工农医') plt.show()
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('D:\\myfiles\\study\\python\\analyse\\数据团\\城市数据团_数据分析师_体验课_课程资料\\数据资料\\地市级党委书记数据库(2000-10).csv', encoding='gbk')
# 新建变量data_age,赋值包括年份、出生年份字段内容
# 清除缺失值
data_age = data[['出生年份','党委书记姓名','年份']]
data_age_re = data_age[data_age['出生年份'].notnull()]
# 计算出整体年龄数据
df1 = 2017 - data_age_re['出生年份']
# 计算出入职年龄数据
df_yearmin = data_age_re[['党委书记姓名','年份']].groupby(data_age_re['党委书记姓名']).min()
df2 = df_yearmin['年份'].groupby(df_yearmin['年份']).count() df_yearmax = data_age_re[['党委书记姓名','年份']].groupby(data_age_re['党委书记姓名']).max()
df3 = df_yearmax['年份'].groupby(df_yearmax['年份']).count() # 专业情况:专业结构 / 专业整体情况 / 专业大类分布
# 新建变量data_major,赋值包括年份、专业等字段内容,其中1代表是,0代表否
# 清除缺失值
data_major = data[['党委书记姓名','年份','专业:人文','专业:社科','专业:理工','专业:农科','专业:医科']]
data_major_re = data_major[data_major['专业:人文'].notnull()]
# 统计每个人的专业
data_major_re['专业'] = data_major_re[['专业:人文', '专业:社科', '专业:理工', '专业:农科', '专业:医科']].idxmax(axis=1)
# 去重
data_major_st = data_major_re[['专业','党委书记姓名']].drop_duplicates()
# 计算出学历结构数据
df4 = data_major_st['专业'].groupby(data_major_st['专业']).count()
# 计算每年专业整体情况数据
df5 = pd.crosstab(data_major_re['年份'], data_major_re['专业'])
# 计算每年专业大类分布数据
df5['社科比例'] = df5['专业:社科'] / (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文'])
df5['人文比例'] = df5['专业:人文'] / (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文'])
df5['理工农医比例'] = (df5['专业:理工'] + df5['专业:医科'] + df5['专业:农科'])/ (df5['专业:理工'] + df5['专业:医科'] + df5['专业:社科'] + df5['专业:农科'] + df5['专业:人文']) # 年龄情况:图表绘制
# 创建一个图表,大小为12*8
fig_q2 = plt.figure(figsize = (14,12))
# 创建一个3*2的表格矩阵
ax1 = fig_q2.add_subplot(2,3,1)
ax2 = fig_q2.add_subplot(2,3,2)
ax3 = fig_q2.add_subplot(2,3,3)
ax4 = fig_q2.add_subplot(2,3,4)
ax5 = fig_q2.add_subplot(2,3,5)
ax6 = fig_q2.add_subplot(2,3,6)
# 绘制第一个表格
ax1.hist(df1,bins = 11,color = 'gray', alpha=0.9)
ax1.set_title('整体年龄分布')
ax1.grid(True) # 绘制第二个表格
ax2.plot(df2,color = 'r',marker = 'o',alpha=0.9)
ax2.set_title('入职年龄分布')
ax2.set_xticks(range(2000,2011,2))
ax2.grid(True) # 绘制第三个表格
ax3.plot(df3,color = 'g',marker = 'o',alpha=0.9)
ax3.set_title('卸任年龄分布')
ax3.set_xticks(range(2000,2011,2))
ax3.grid(True) # 绘制第四个表格
ax4.bar(range(len(df4)),df4,color = 'y')
ax4.set_xticklabels(['人文','农科','医科','理工','社科'])
ax4.grid(True)
ax4.set_title('专业结构') # 绘制第五个表格
ax5.plot(df5.index,df5[['专业:人文','专业:农科','专业:医科','专业:理工','专业:社科']])
ax5.grid(True)
ax5.set_title('专业整体情况') # 绘制第六个表格
ax6.bar(df5.index,df5['社科比例'],color = 'darkred',alpha=0.7)
ax6.bar(df5.index,df5['人文比例'],color = 'darkred',bottom = df5['社科比例'],alpha=0.5)
ax6.bar(df5.index,df5['理工农医比例'],color = 'darkred',bottom = df5['人文比例'] + df5['社科比例'],alpha=0.3)
ax6.grid(True)
ax6.set_title('专业大类分布:社科、人文、理工农医') plt.show()
使用MATPLOTLIB 制图(小图)的更多相关文章
- 使用MATPLOTLIB 制图(散点图,热力图)
import numpy as np import pandas as pd import matplotlib.pyplot as plt data = pd.read_csv('D:\\myfil ...
- 使用matplotlib 制图(柱状图、箱型图)
柱状图: import pandas as pd import matplotlib.pyplot as plt data = pd.read_csv('D:\\myfiles\\study\\pyt ...
- 【转】matplotlib制图——图例legend
转自:https://www.cnblogs.com/alimin1987/p/8047833.html import matplotlib.pyplot as pltimport numpy as ...
- 012 pandas与matplotlib结合制图
这里以后再补充. 1.折线图
- Matplotlib基本使用简介
目录 Matplotlib基本使用简介 1. Matplotlib简介 2. Matplotlib操作简介 Matplotlib基本使用简介 1. Matplotlib简介 Matplotlib是 ...
- Matplotlib 学习笔记
注:该文是上了开智学堂数据科学基础班的课后做的笔记,主讲人是肖凯老师. 数据绘图 数据可视化的原则 为什么要做数据可视化? 为什么要做数据可视化?因为可视化后获取信息的效率高.为什么可视化后获取信息的 ...
- Python图表绘制:matplotlib绘图库入门
matplotlib 是Python最著名的绘图库,它提供了一整套和matlab相似的命令API,十分适合交互式地行制图.而且也可以方便地将它作为绘图控件,嵌入GUI应用程序中. 它的文档相当完备,并 ...
- matplotlib库的常用知识
看看matplotlib是什么? matplotlib是python上的一个2D绘图库,它可以在夸平台上边出很多高质量的图像.综旨就是让简单的事变得更简单,让复杂的事变得可能.我们可以用matplot ...
- python 绘图工具 matplotlib 入门
转自: http://www.cnblogs.com/kaituorensheng/p/3440273.html matplotlib 是python最著名的绘图库,它提供了一整套和matlab相似的 ...
随机推荐
- IntelliJ IDEA 2017激活
最新更新: 在激活Jetbrains旗下任意产品的时候选择激活服务器 填入以下地址便可成功激活 http://idea.liyang.io 点击help→Register→License sever ...
- Selenium(ThoughtWorks公司开发的web自动化测试工具)
Selenium也是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7.8.9).Mozilla Firefox.Mozill ...
- Ribbon Status Bar
https://documentation.devexpress.com/#WindowsForms/CustomDocument2498 官方文档说明 A Ribbon Status Bar (Ri ...
- TensorFlow学习线路
如何高效的学习 TensorFlow 代码? 或者如何掌握TensorFlow,应用到任何领域? 作者:黄璞链接:https://www.zhihu.com/question/41667903/ans ...
- spring cloud 知识点
优秀的介绍资料: 资料 地址 spring cloud 中文网 https://springcloud.cc/ spring cloud 介绍 https://www.jianshu.com/p/74 ...
- 3种web会话管理方式:基于server端session方式、cookie-based方式、token-based方式
出处:http://www.cnblogs.com/lyzg/p/6067766.html
- CommonsChunkPlugin知识点
CommonsChunkPlugin 的作用就是提取代码中的公共模块,然后将公共模块打包到一个独立的文件中去,以便在其它的入口和模块中使用. 多个 html共用一个js文件(chunk),可用Comm ...
- LOJ 164 【清华集训2015】V——线段树维护历史最值
题目:http://uoj.ac/problem/164 把操作改成形如 ( a,b ) 表示加上 a 之后对 b 取 max 的意思. 每个点维护当前的 a , b ,还有历史最大的 a , b 即 ...
- bzoj1799(洛谷4127)同类分布(月之谜)
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=1799 https://www.luogu.org/problemnew/show/P4127 ...
- Oracle-EXP-00011 表不存在
Oracle-EXP-00011 表不存在 点我,点我~