pandas练习(二)------ 数据过滤与排序
数据过滤与排序------探索2012欧洲杯数据
相关数据见(github)
步骤1 - 导入pandas库
import pandas as pd
步骤2 - 数据集
path2 = "./data/Euro2012.csv" # Euro2012.csv
步骤3 - 将数据集命名为euro12
euro12 = pd.read_csv(path2)
euro12.tail()
输出:
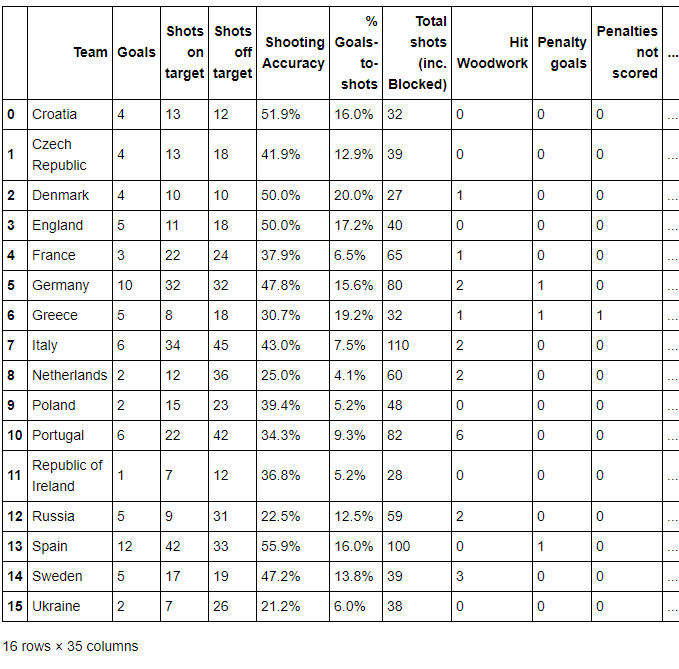
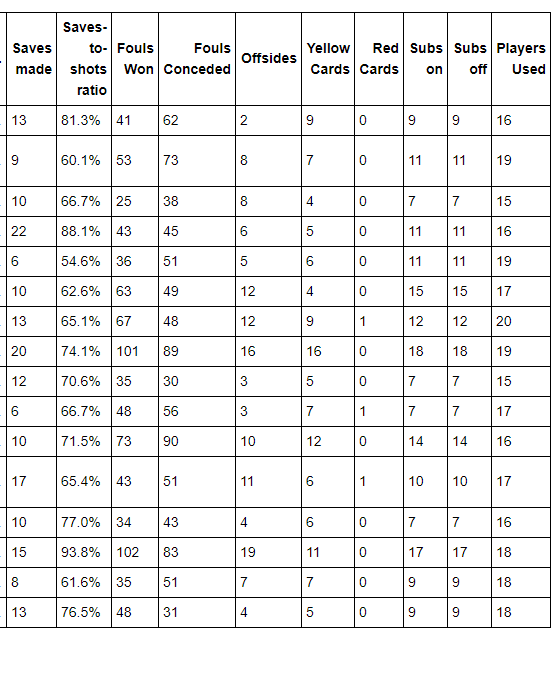
步骤4 选取 Goals 这一列
euro12.Goals # euro12['Goals']
输出:

步骤5 有多少球队参与了2012欧洲杯?
euro12.shape[0]
输出:
16
步骤6 该数据集中一共有多少列(columns)?
euro12.info()
输出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 16 entries, 0 to 15
Data columns (total 35 columns):
Team 16 non-null object
Goals 16 non-null int64
Shots on target 16 non-null int64
Shots off target 16 non-null int64
Shooting Accuracy 16 non-null object
% Goals-to-shots 16 non-null object
Total shots (inc. Blocked) 16 non-null int64
Hit Woodwork 16 non-null int64
Penalty goals 16 non-null int64
Penalties not scored 16 non-null int64
Headed goals 16 non-null int64
Passes 16 non-null int64
Passes completed 16 non-null int64
Passing Accuracy 16 non-null object
Touches 16 non-null int64
Crosses 16 non-null int64
Dribbles 16 non-null int64
Corners Taken 16 non-null int64
Tackles 16 non-null int64
Clearances 16 non-null int64
Interceptions 16 non-null int64
Clearances off line 15 non-null float64
Clean Sheets 16 non-null int64
Blocks 16 non-null int64
Goals conceded 16 non-null int64
Saves made 16 non-null int64
Saves-to-shots ratio 16 non-null object
Fouls Won 16 non-null int64
Fouls Conceded 16 non-null int64
Offsides 16 non-null int64
Yellow Cards 16 non-null int64
Red Cards 16 non-null int64
Subs on 16 non-null int64
Subs off 16 non-null int64
Players Used 16 non-null int64
dtypes: float64(1), int64(29), object(5)
memory usage: 4.5+ KB
步骤7 将数据集中的列Team, Yellow Cards和Red Cards单独存为一个名叫discipline的数据框
discipline = euro12[['Team', 'Yellow Cards', 'Red Cards']]
discipline
输出:

步骤8 对数据框discipline按照先Red Cards再Yellow Cards进行排序
discipline.sort_values(['Red Cards', 'Yellow Cards'], ascending = False)
输出:

步骤9 计算每个球队拿到的黄牌数的平均值
round(discipline['Yellow Cards'].mean())
输出:
7.0
步骤10 找到进球数Goals超过6的球队数据
euro12[euro12.Goals > 6]
输出:
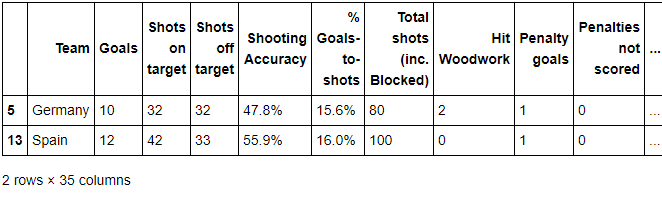

步骤11 选取以字母G开头或以e结尾的球队数据
# euro12[euro12.Team.str.startswith('G')]
euro12[euro12.Team.str.endswith('e')] # 以字母e结束的球队
输出:
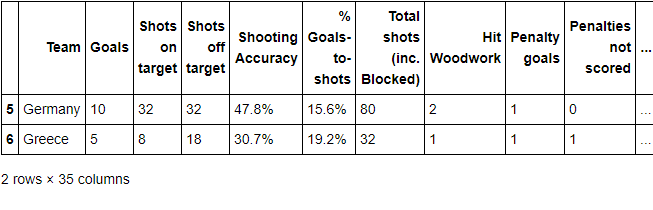
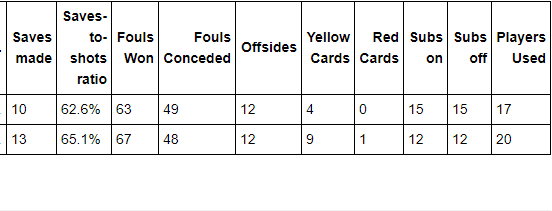
步骤12 选取前7列
euro12.iloc[: , 0:7]
输出:
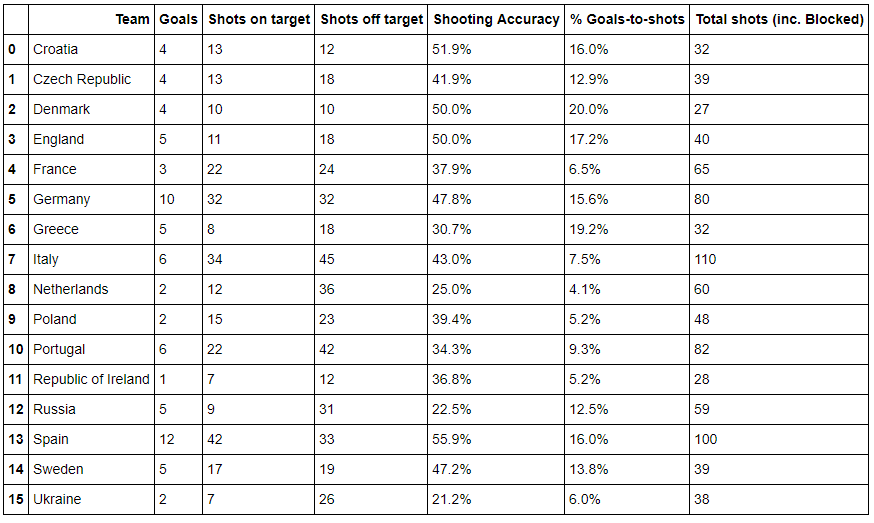
步骤13 选取除了最后3列之外的全部列
euro12.iloc[: , :-3]
输出:
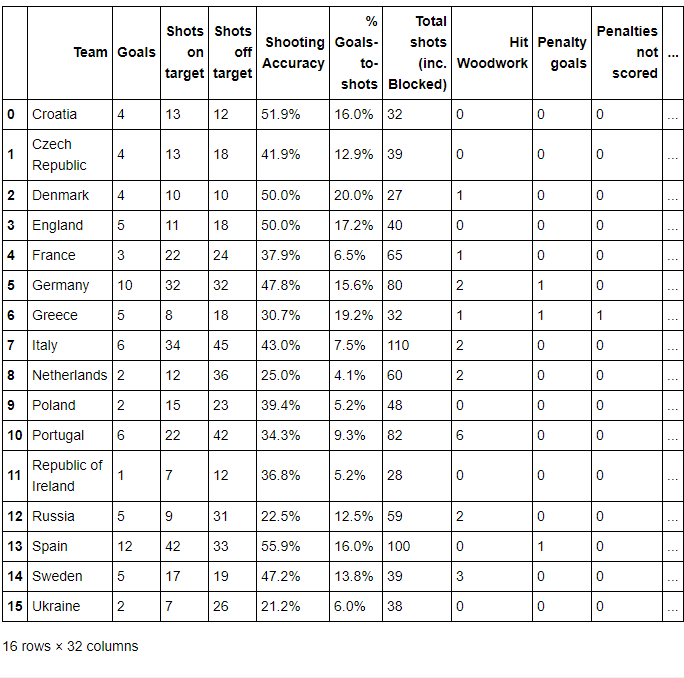
步骤14 找到英格兰(England)、意大利(Italy)和俄罗斯(Russia)的命中率(Shooting Accuracy)
euro12.loc[euro12.Team.isin(['England', 'Italy', 'Russia']), ['Team','Shooting Accuracy']]
输出:

参考链接:
1、http://pandas.pydata.org/pandas-docs/stable/cookbook.html#cookbook
2、https://www.analyticsvidhya.com/blog/2016/01/12-pandas-techniques-python-data-manipulation/
3、https://github.com/guipsamora/pandas_exercises
pandas练习(二)------ 数据过滤与排序的更多相关文章
- Vue 基本列表 && 数据过滤与排序
1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="UTF-8" /> 5 & ...
- pandas之DateFrame 数据过滤+遍历行+读写csv-txt-excel
# XLS转CSV df = pd.read_excel(r'列表.xls') df2 = pd.DataFrame()df2 = df2.append(list(df['列名']), ignore_ ...
- Oracle学习(二):过滤和排序
1.知识点:能够对比以下的录屏进行阅读 SQL> --字符串大写和小写敏感 SQL> --查询名叫KING的员工信息 SQL> select * 2 from emp 3 where ...
- python 数据清洗之数据合并、转换、过滤、排序
前面我们用pandas做了一些基本的操作,接下来进一步了解数据的操作, 数据清洗一直是数据分析中极为重要的一个环节. 数据合并 在pandas中可以通过merge对数据进行合并操作. import n ...
- [数据清洗]- Pandas 清洗“脏”数据(二)
概要 了解数据 分析数据问题 清洗数据 整合代码 了解数据 在处理任何数据之前,我们的第一任务是理解数据以及数据是干什么用的.我们尝试去理解数据的列/行.记录.数据格式.语义错误.缺失的条目以及错误的 ...
- mysql必知必会(四、检索数据,五、排序检索数据,六、过滤数据,七、数据过滤)
四.select语句 1.检索单个列 select prod_name from products; 2.检索多个列 select prod_name, prod_price from product ...
- [数据清洗]-使用 Pandas 清洗“脏”数据
概要 准备工作 检查数据 处理缺失数据 添加默认值 删除不完整的行 删除不完整的列 规范化数据类型 必要的转换 重命名列名 保存结果 更多资源 Pandas 是 Python 中很流行的类库,使用它可 ...
- [数据清洗]- Pandas 清洗“脏”数据(三)
预览数据 这次我们使用 Artworks.csv ,我们选取 100 行数据来完成本次内容.具体步骤: 导入 Pandas 读取 csv 数据到 DataFrame(要确保数据已经下载到指定路径) D ...
- Oracle01——基本查询、过滤和排序、单行函数、多行函数和多表查询
作者: kent鹏 转载请注明出处: http://www.cnblogs.com/xieyupeng/p/7272236.html Oracle的集群 Oracle的体系结构 SQL> --当 ...
随机推荐
- ES6 阮一峰阅读学习
参考: ECMAScript6入门 就是随便看看,了解一下. 一.ECMAScript6简介 1. 什么是ECMAScript6? JavaScript语言的下一代标准.2015年6月发布,正式名称是 ...
- git如何回滚当前修改的内容?
git如何回滚当前修改的内容? 1.打开git gui,在工具栏上点击 commit ,选择 Revert Changes, 这里可以回滚单个文件: 2.一键回滚所有修改: 打开git gui,在工 ...
- python3安装builtwith
>>> import builtwith Traceback (most recent call last): File , in <module> File excep ...
- hdu1754 I Hate It【线段树】
很多学校流行一种比较的习惯.老师们很喜欢询问,从某某到某某当中,分数最高的是多少. 这让很多学生很反感. 不管你喜不喜欢,现在需要你做的是,就是按照老师的要求,写一个程序,模拟老师的询问.当然,老 ...
- 使用keras导入densenet模型
从keras的keras_applications的文件夹内可以找到内置模型的源代码 Kera的应用模块Application提供了带有预训练权重的Keras模型,这些模型可以用来进行预测.特征提取和 ...
- MapReduce部分源码解读(一)
/** * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agree ...
- 扩展KMP算法小记
参考来自<拓展kmp算法总结>:http://blog.csdn.net/dyx404514/article/details/41831947 扩展KMP解决的问题: 定义母串S和子串T, ...
- win10 64bit安装redis及redis desktop manager的方法
下载地址: MSOpenTech/redis——Github 下载后随便解压到一个地方 在 命令行 启动服务端 命令内容如下: redis-server.exe redis.windows.conf ...
- MySQL半同步复制(5.5之后引入)
半同步复制架构在主库提交一个事务后,commit完成即反馈客户端,无需等待推送binlog完成,如图: 半同步复制在主库完成一个事务后,需等待事务信息写入binlog日志并且至少有一个从库写入rela ...
- 《前端JavaScript面试技巧》笔记一
思考: 拿到一个面试题,你第一时间看到的是什么 -> 考点 又如何看待网上搜出来的永远也看不完的题海 -> 不变应万变 如何对待接下来遇到的面试题 -> 题目到知识再到题目 知识体系 ...