SSD论文理解
SSD论文贡献:
1. 引入了一种单阶段的检测器,比以前的算法YOLO更准更快,并没有使用RPN和Pooling操作;
2. 使用一个小的卷积滤波器应用在不同的feature map层从而预测BB的类别的BB偏差;
3. 可以在更小的输入图片中得到更好的检测效果(相比Faster-rcnn);
4. 在多个数据集(PASCAL、VOC、COCO、ILSVRC)上面的测试结果表明,它可以获得更高的mAp值;
This results in a significant improvement in speed for high-accuracy detection(59 FPS with mAP 74.3% on VOC2007 test, vs Faster-rcnn 7 FPS with mAP 73.2% or YOLO 45 FPS with mAP 63.4%)
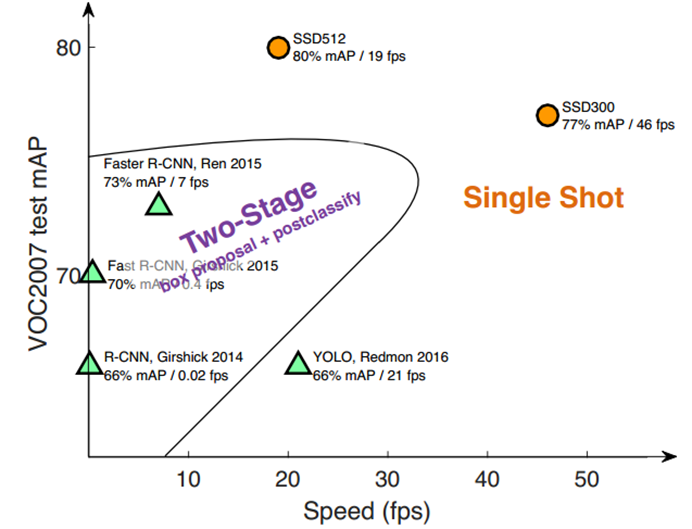
图1 SSD和其它算法的性能比较
一、SSD网络总体架构

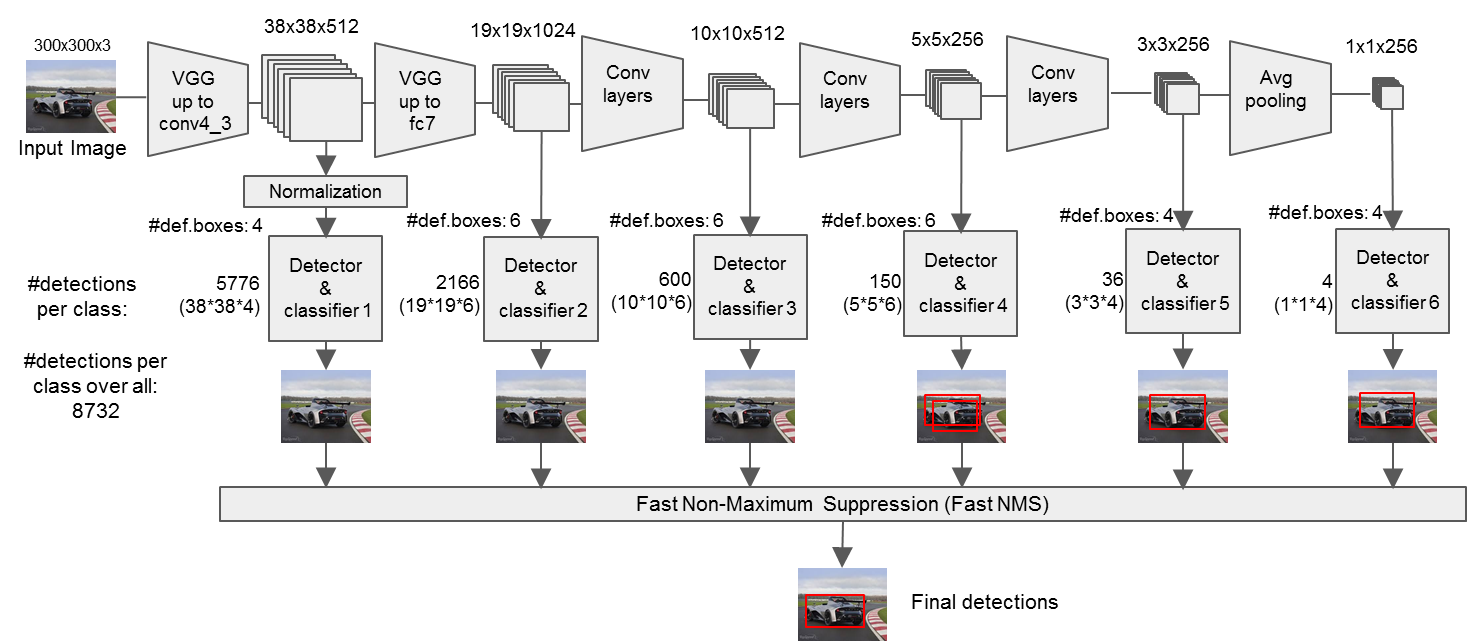
1. 输入一幅图片(300x300),将其输入到预训练好的分类网络中来获得不同大小的特征映射,修改了传统的VGG16网络;
- 将VGG16的FC6和FC7层转化为卷积层,如图1上的Conv6和Conv7;
- 去掉所有的Dropout层和FC8层;
- 添加了Atrous算法(hole算法);
- 将Pool5从2x2-S2变换到3x3-S1;
2. 抽取Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2层的feature map,然后分别在这些feature map层上面的每一个点构造6个不同尺度大小的BB,然后分别进行检测和分类,生成多个BB,如图1下面的图所示;
3. 将不同feature map获得的BB结合起来,经过NMS(非极大值抑制)方法来抑制掉一部分重叠或者不正确的BB,生成最终的BB集合(即检测结果);
二、 SSD算法细节
1. 多尺度特征映射
A.传统算法与SSD算法的思路比较:
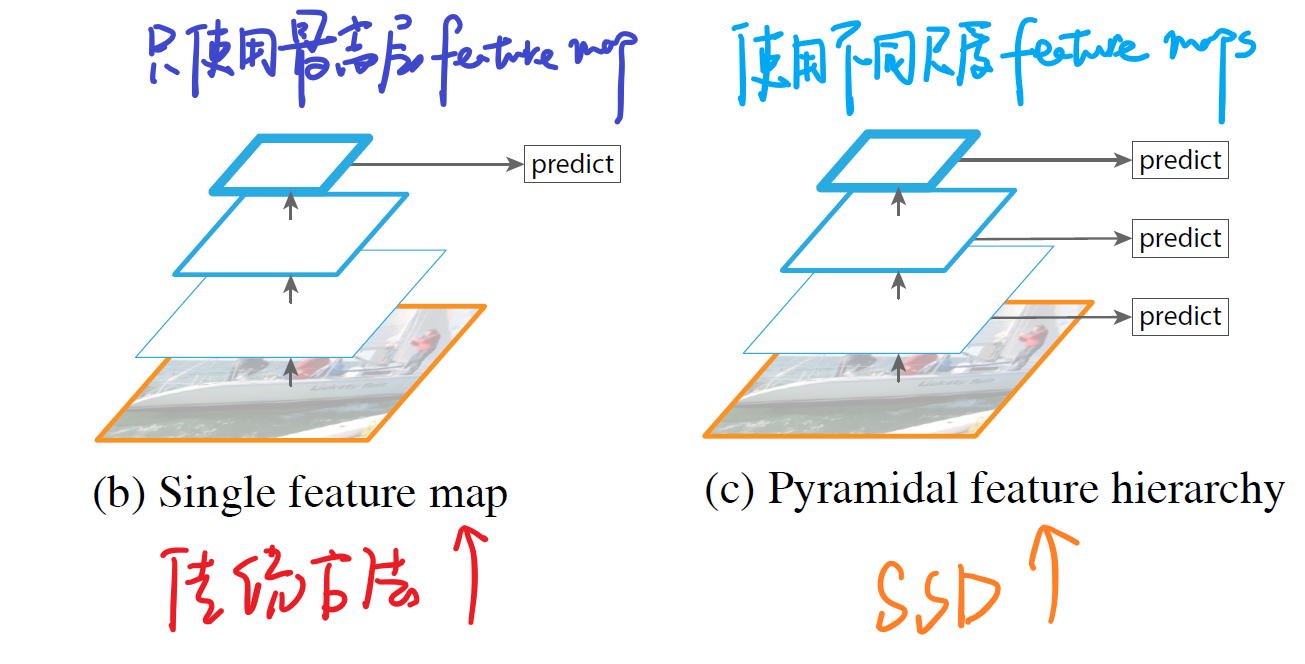
如上图所示,我们可以看到左边的方法针对输入的图片获取不同尺度的特征映射,但是在预测阶段仅仅使用了最后一层的特征映射;而SSD不仅获得不同尺度的特征映射,同时在不同的特征映射上面进行预测,它在增加运算量的同时可能会提高检测的精度,因为它具有更多的可能性。
B.Faster-rcnn与SSD比较:
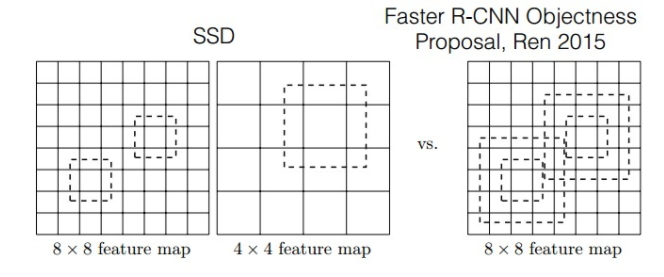
如图所示,对于BB的生成,Faster-rcnn和SSD有不同的策略,但是都是为了同一个目的,产生不同尺度,不同形状的BB,用来检测物体。对于Faster-rcnn而言,其在特定层的Feature map上面的每一点生成9个预定义好的BB,然后进行回归和分类操作进行初步检测,然后进行ROI Pooling和检测获得相应的BB;而SSD则在不同的特征层的feature map上的每个点同时获取6个不同的BB,然后将这些BB结合起来,最后经过NMS处理获得最后的BB。
C.原因剖析:
输入一幅汽车的图片,我们将其输入到一个卷积神经网络中,在这期间,经历了多个卷积层和池化层,我们可以看到在不同的卷积层会输出不同大小的feature map(这是由于pooling层的存在,它会将图片的尺寸变小),而且不同的feature map中含有不同的特征,而不同的特征可能对我们的检测有不同的作用。总的来说,浅层卷积层对边缘更加感兴趣,可以获得一些细节信息,而深层网络对由浅层特征构成的复杂特征更感兴趣,可以获得一些语义信息,对于检测任务而言,一幅图像中的目标有复杂的有简单的,对于简单的patch我们利用浅层网络的特征就可以将其检测出来,对于复杂的patch我们利用深层网络的特征就可以将其检测出来,因此,如果我们同时在不同的feature map上面进行目标检测,理论上面应该会获得更好的检测效果。
D.SSD多尺度特征映射细节:
SSD算法中使用到了conv4_3,conv_7,conv8_2,conv7_2,conv8_2,conv9_2,conv10_2,conv11_2这些大小不同的feature maps,其目的是为了能够准确的检测到不同尺度的物体,因为在低层的feature map,感受野比较小,高层的感受野比较大,在不同的feature map进行卷积,可以达到多尺度的目的。
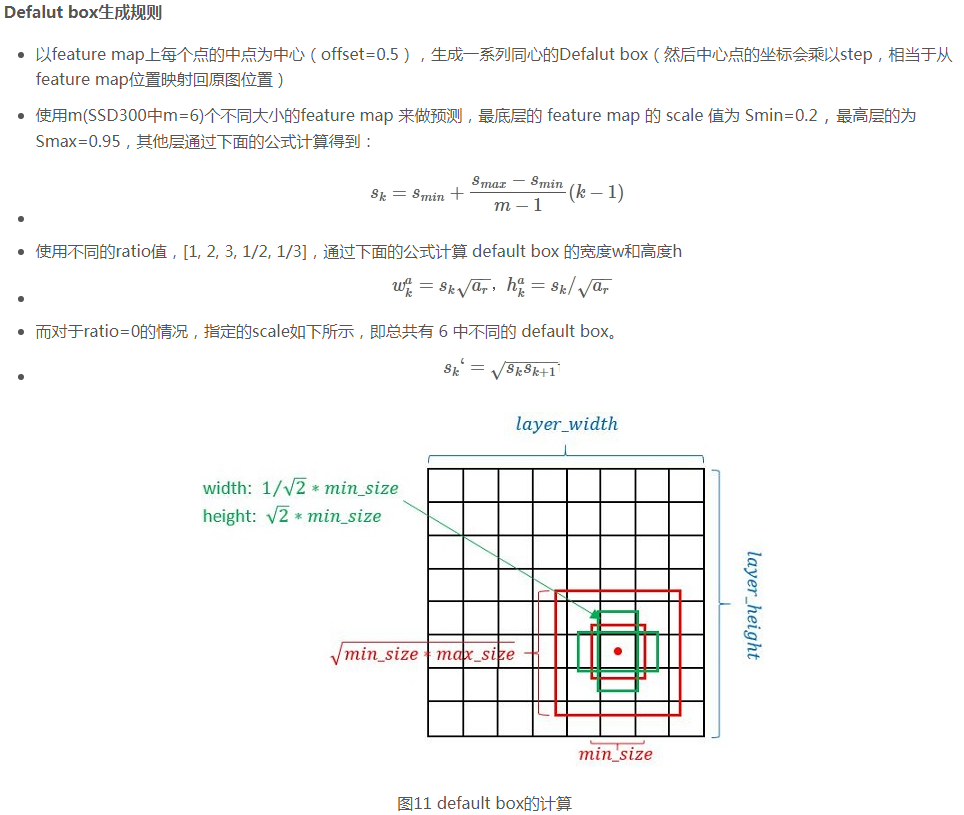
2. Defalut box
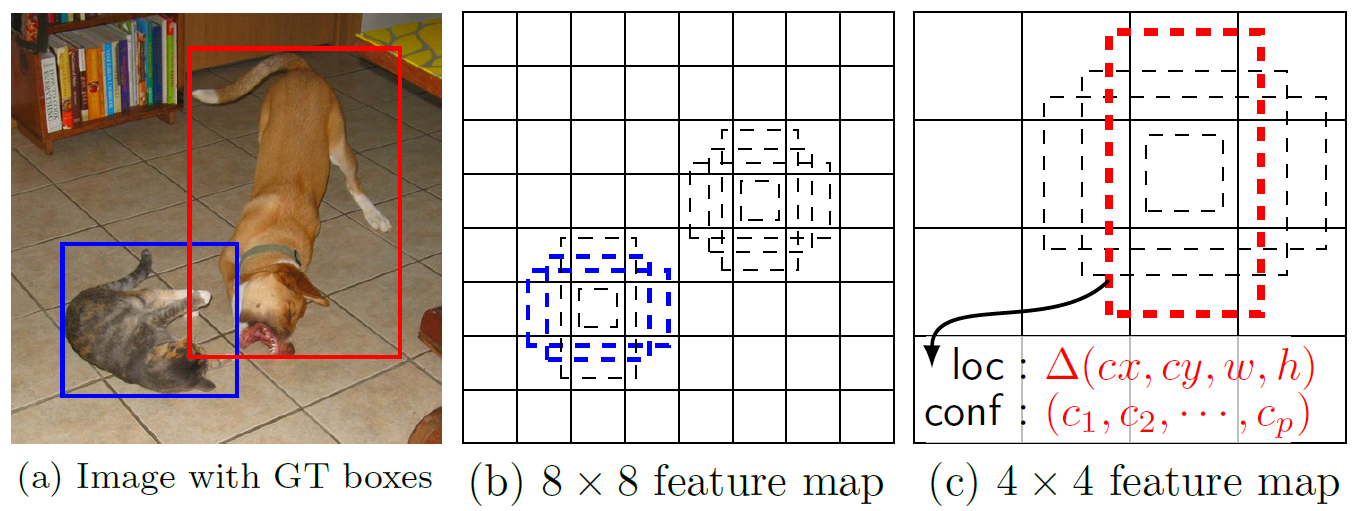
如上图所示,在特征图的每个位置预测K个BB,对于每一个BB,预测C个类别得分,以及相对于Default box的4个偏移量值,这样总共需要(C+4)* K个预测器,则在m*n的特征图上面将会产生(C+4)* K * m * n个预测值。
Defalut box分析:
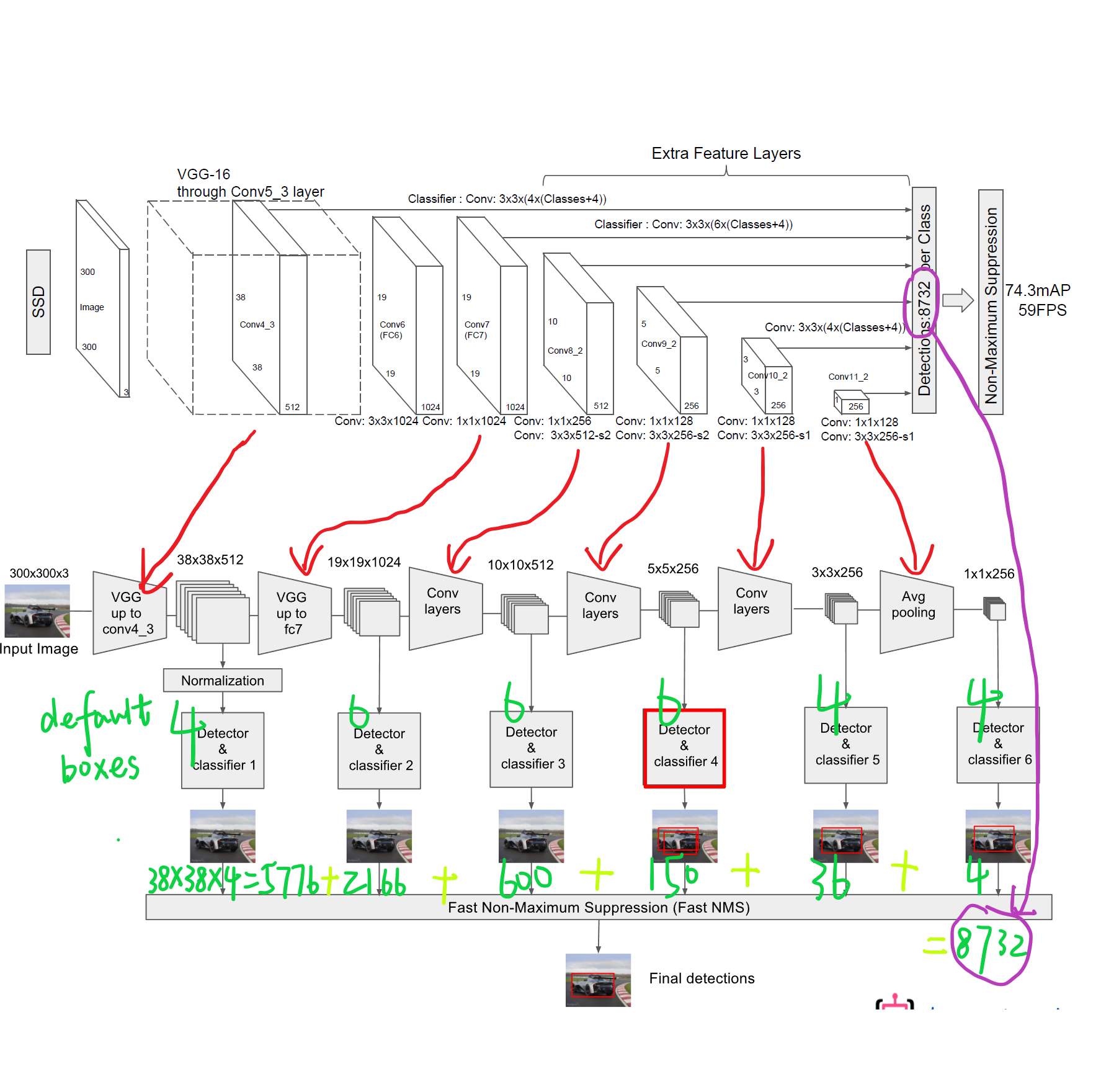
我们总共可以获得8732个box,然后我们将这些box送入NMS模块中,获得最终的检测结果。
3. LOSS计算
与常见的 Object Detection模型的目标函数相同,SSD算法的目标函数分为两部分:计算相应的default box与目标类别的confidence loss以及相应的位置回归。

其中N是match到Ground Truth的default box数量;而alpha参数用于调整confidence loss和location loss之间的比例,默认alpha=1。
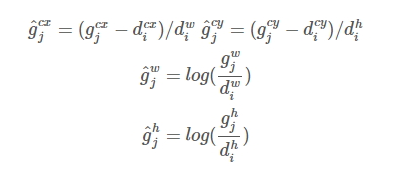
三、SSD提高精度的方法
1. 数据增强
SSD训练过程中使用的数据增强对网络性能影响很大,大约有6.7%的mAP提升。
(1) 随机剪裁:采样一个片段,使剪裁部分与目标重叠分别为0.1, 0.3, 0.5, 0.7, 0.9,剪裁完resize到固定尺寸。
(2) 以0.5的概率随机水平翻转。
2. Hard Negative Mining技术
一般情况下negative default boxes数量是远大于positive default boxes数量,如果随机选取样本训练会导致网络过于重视负样本(因为抽取到负样本的概率值更大一些),这会使得loss不稳定。因此需要平衡正负样本的个数,我们常用的方法就是Hard Ngative Mining,即依据confidience score对default box进行排序,挑选其中confidience高的box进行训练,将正负样本的比例控制在positive:negative=1:3,这样会取得更好的效果。如果我们不加控制的话,很可能会出现Sample到的所有样本都是负样本(即让网络从这些负样本中找正确目标,这显然是不可以的),这样就会使得网络的性能变差。
3. 匹配策略(即如何重多个default box中找到和ground truth最接近的box)
- 首先,寻找与每一个ground truth有最大的IoU的default box,这样就能保证ground truth至少有default box匹配;
- SSD之后又将剩余还没有配对的default box与任意一个ground truth尝试配对,只要两者之间的IoU大于阈值(SSD 300 阈值为0.5),就认为match;
- 配对到ground truth的default box就是positive,没有配对的default box就是negative。
总之,一个ground truth可能对应多个positive default box,而不再像MultiBox那样只取一个IoU最大的default box。其他的作为负样本(每个default box要么是正样本box要么是负样本box)。
4. 是否在基础网络部分的conv4_3进行检测
基础网络部分特征图分辨率高,原图中信息更完整,感受野较小,可以用来检测图像中的小目标,这也是SSD相对于YOLO检测小目标的优势所在。增加对基础网络conv4_3的特征图的检测可以使mAP提升4%。
5. 使用瘦高与宽扁默认框
数据集中目标的开关往往各式各样,因此挑选合适形状的默认框能够提高检测效果。作者实验得出使用瘦高与宽扁默认框相对于只使用正方形默认框有2.9%mAP提升。
6. Atrous Algothrim(获得更加密集的得分映射)
作用:既想利用已经训练好的模型进行fine-tuning,又想改变网络结构得到更加dense的score map。
这个解决办法就是采用Hole算法。
7. NMS(非极大值抑制)
在SSD算法中,NMS至关重要,因为多个feature map 最后会产生大量的BB,然而在这些BB中存在着大量的错误的、重叠的、不准确的BB,这不仅造成了巨大的计算量,如果处理不好会影响算法的性能。仅仅依赖于IOU(即预测的BB和GT的BB之间的重合率)是不现实的,IOU值设置的太大,可能就会丢失一部分检测的目标,即会出现大量的漏检情况;IOU值设置的太小,则会出现大量的重叠检测,会大大影响检测器的性能,因此IOU的选取也是一个经验活,常用的是0.65,建议使用论文中作者使用的IOU值,因为这些值一般都是最优值。即在IOU处理掉大部分的BB之后,仍然会存在大量的错误的、重叠的、不准确的BB,这就需要NMS进行迭代优化。
四、评价
1. SSD加速的原因

表2 SSD的BB个数
如上图所示,当Faster-rcnn的输入分辨率为1000x600时,产生的BB是6000个;当SSD300的输入分辨率为300x300时,产生的BB是8372个;当SSD512的输入分辨率为512x512时,产生的BB是24564个,大家像一个情况,当SSD的分辨率也是1000x600时,会产生多少个BB呢?这个数字可能会很大!但是它却说自己比Faster-rcnn和YOLO等算法快很多,我们来分析分析原因。
原因1:首先SSD是一个单阶段网络,只需要一个阶段就可以输出结果;而Faster-rcnn是一个双阶段网络,尽管Faster-rcnn的BB少很多,但是其需要大量的前向和反向推理(训练阶段),而且需要交替的训练两个网络;
原因2:Faster-rcnn中不仅需要训练RPN,而且需要训练Fast-rcnn,而SSD其实相当于一个优化了的RPN网络,不需要进行后面的检测,仅仅前向推理就会花费很多时间;
原因3:YOLO网络虽然比SSD网络看起来简单,但是YOLO网络中含有大量的全连接层,和FC层相比,CONV层具有更少的参数;同时YOLO获得候选BB的操作比较费时;
原因4:SSD算法中,调整了VGG网络的架构,将其中的FC层替换为CONV层,这一点会大大的提升速度,因为VGG中的FC层都需要大量的运算,有大量的参数,需要进行前向推理;
原因5:使用了atrous算法,具体的提速原理还不清楚,不过论文中明确提出该算法能够提速20%。
原因6:SSD设置了输入图片的大小,它会将不同大小的图片裁剪为300x300,或者512x512,和Faster-rcnn相比,在输入上就会少很多的计算,不要说后面的啦,不快就怪啦!!!
2. SSD算法的优缺点
优点:运行速度超过YOLO,精度超过Faster-rcnn(一定条件下,对于稀疏场景的大目标而言)。
缺点:
需要人工设置prior box的min_size,max_size和aspect_ratio值。网络中default box的基础大小和形状不能直接通过学习获得,而是需要手工设置。而网络中每一层feature使用的default box大小和形状恰好都不一样,导致调试过程非常依赖经验。(相比之下,YOLO2使用聚类找出大部分的anchor box形状,这个思想能直接套在SSD上)
虽然采用了pyramdial feature hierarchy的思路,但是对小目标的recall依然一般,并没有达到碾压Faster RCNN的级别。可能是因为SSD使用conv4_3低级feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。
个人观点:SSD到底好不好,需要根据你的应用和需求来讲,真正合适你的应用场景的检测算法需要你去做性能验证,比如你的场景是密集的包含多个小目标的,我很建议你用Faster-rcnn,针对特定的网络进行优化,也是可以加速的;如果你的应用对速度要求很苛刻,那么肯定首先考虑SSD,至于那些测试集上的评估结果,和真实的数据还是有很大的差距,算法的性能也需要进一步进行评估。
参考:
https://blog.csdn.net/WZZ18191171661/article/details/79444217
https://www.cnblogs.com/fariver/p/7347197.html
SSD论文理解的更多相关文章
- ssd算法论文理解
这篇博客主要是讲下我在阅读ssd论文时对论文的理解,并且自行使用pytorch实现了下论文的内容,并测试可以用. 开篇放下论文地址https://arxiv.org/abs/1512.02325,可以 ...
- 翻译SSD论文(Single Shot MultiBox Detector)
转自http://lib.csdn.net/article/deeplearning/53059 作者:Ai_Smith 本文翻译而来,如有侵权,请联系博主删除.未经博主允许,请勿转载.每晚泡脚,闲来 ...
- 深度学习 目标检测算法 SSD 论文简介
深度学习 目标检测算法 SSD 论文简介 一.论文简介: ECCV-2016 Paper:https://arxiv.org/pdf/1512.02325v5.pdf Slides:http://w ...
- [论文理解]关于ResNet的进一步理解
[论文理解]关于ResNet的理解 这两天回忆起resnet,感觉残差结构还是不怎么理解(可能当时理解了,时间长了忘了吧),重新梳理一下两点,关于resnet结构的思考. 要解决什么问题 论文的一大贡 ...
- [论文理解] CornerNet: Detecting Objects as Paired Keypoints
[论文理解] CornerNet: Detecting Objects as Paired Keypoints 简介 首先这是一篇anchor free的文章,看了之后觉得方法挺好的,预测左上角和右下 ...
- [论文理解]SSD:Single Shot MultiBox Detector
SSD:Single Shot MultiBox Detector Intro SSD是一套one-stage算法实现目标检测的框架,速度很快,在当时速度超过了yolo,精度也可以达到two-stag ...
- 深度学习笔记(七)SSD 论文阅读笔记简化
一. 算法概述 本文提出的SSD算法是一种直接预测目标类别和bounding box的多目标检测算法.与faster rcnn相比,该算法没有生成 proposal 的过程,这就极大提高了检测速度.针 ...
- 深度学习笔记(七)SSD 论文阅读笔记
一. 算法概述 本文提出的SSD算法是一种直接预测目标类别和bounding box的多目标检测算法.与faster rcnn相比,该算法没有生成 proposal 的过程,这就极大提高了检测速度.针 ...
- YOLO V2论文理解
概述 YOLO(You Only Look Once: Unified, Real-Time Object Detection)从v1版本进化到了v2版本,作者在darknet主页先行一步放出源代码, ...
随机推荐
- echarts2简单笔记
1.代码 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF- ...
- 009-hostname与/etc/hosts区别
- X-UA-Compatible
X-UA-Compatible是神马? X-UA-Compatible是IE8的一个专有<meta>属性,它告诉IE8采用何种IE版本去渲染网页,在html的<head>标签中 ...
- Devenv 命令行开关
Devenv 可用来设置集成开发环境 (IDE) 的各个选项,以及从命令行生成.调试和部署项目.使用这些开关从脚本或 .bat 文件(例如每夜生成的脚本)运行 IDE,或以特定配置启动 IDE. 说明 ...
- Java设计模式应用——策略模式
对于相同类型相同类型的输入输出,在不同场景下需要使用不同的逻辑处理,则可以使用策略模式. 比如排序算法有堆排序,快速排序,冒泡排序,选择排序等.为了保证排序效率,需要在不同场景下选择不同排序算法,这时 ...
- java后台获取和js拼接展示信息
java后台获取和js拼接展示信息: html页面代码: <div class="results-bd"> <table id="activityInf ...
- Vlock用于有多个用户访问控制台的共享 Linux 系统
当你在共享的系统上工作时,你可能不希望其他用户偷窥你的控制台中看你在做什么.如果是这样,我知道有个简单的技巧来锁定自己的会话,同时仍然允许其他用户在其他虚拟控制台上使用该系统. 要感谢Vlock(Vi ...
- Python Web学习笔记之TCP、UDP、ICMP、IGMP的解释和区别
TCP与UDP解释 TCP---传输控制协议,提供的是面向连接.可靠的字节流服务.当客户和服务器彼此交换数据前,必须先在双方之间建立一个TCP连接,之后才能传输数据.TCP提供超时重发,丢弃重复数据, ...
- Python3.x:抓取百事糗科段子
Python3.x:抓取百事糗科段子 实现代码: #Python3.6 获取糗事百科的段子 import urllib.request #导入各类要用到的包 import urllib import ...
- html模板生成静态页面及模板分页处理
它只让你修改页面的某一部分,当然这"某一部分"是由你来确定的.美工先做好一个页面,然后我们把这个页面当作模板(要注意的是这个模板就没必要使用EditRegion3这样的代码了,这种 ...