Spark RDD 核心总结
摘要:
1.RDD的五大属性
1.1 partitions(分区)
1.2 partitioner(分区方法)
1.3 dependencies(依赖关系)
1.4 compute(获取分区迭代列表)
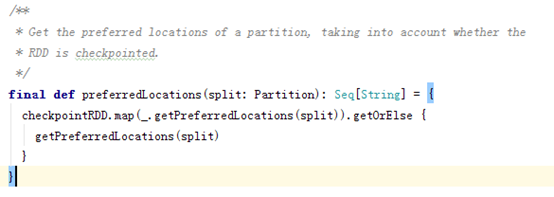
1.5 preferedLocations(优先分配节点列表)
2.RDD实现类举例
2.1 MapPartitionsRDD
2.2 ShuffledRDD
2.3 ReliableCheckpointRDD
3.RDD可以嵌套吗?
内容:
1.RDD的五大属性
1.1partitions(分区)
partitions : 分区属性: 每个RDD包括多个分区, 这既是RDD的数据单位, 也是计算粒度, 每个分区是由一个Task线程处理. 在RDD创建的时候可以指定分区的个数, 如果没有指定, 那么默认分区个数由参数spark.default.parallelism指定(如果未设置这个参数 ,则在yarn或者standalone模式下有如下推导:spark.default.parallelism = max(所有executor使用的core总数, 2)).
每一分区对应一个内存block, 由BlockManager分配.

子类可以通过调用下面的方法来获取分区列表,当处于检查点时,分区信息会被重写
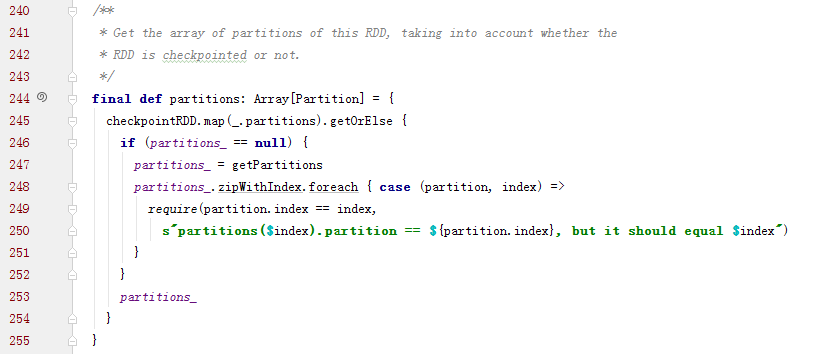
Partition实现:

partition 与 iterator 方法
RDD 的 iterator(split: Partition, context: TaskContext): Iterator[T] 方法用来获取 split 指定的 Partition 对应的数据的迭代器,有了这个迭代器就能一条一条取出数据来按 compute chain 来执行一个个transform 操作。iterator 的实现如下:

其先判断 RDD 的 storageLevel 是否为 NONE,若不是,则尝试从缓存中读取,读取不到则通过计算来获取该Partition对应的数据的迭代器;若是,尝试从 checkpoint 中获取 Partition 对应数据的迭代器,若 checkpoint 不存在则通过计算(compute属性)
1.2partitioner(分区方法)
RDD的分区方式, 这个属性指的是RDD的partitioner函数(分片函数), 分区函数就是将数据分配到指定的分区, 这个目前实现了HashPartitioner和RangePartitioner, 只有key-value的RDD才会有分片函数, 否则为none. 分片函数不仅决定了当前分片的个数, 同时决定parent shuffle RDD的输出的分区个数.

HashPartitioner如何决定一个键对应的分区的:

其中nonNegativeMod方法考虑到了key的符号,如果key是负数,就返回key%numPartitions +numPartitions(补数);
HashPartitioner是基于Object的hashcode来分区的,所以不应该对集合类型进行哈希分区
RangePartitioner如何决定一个键对应的分区的:
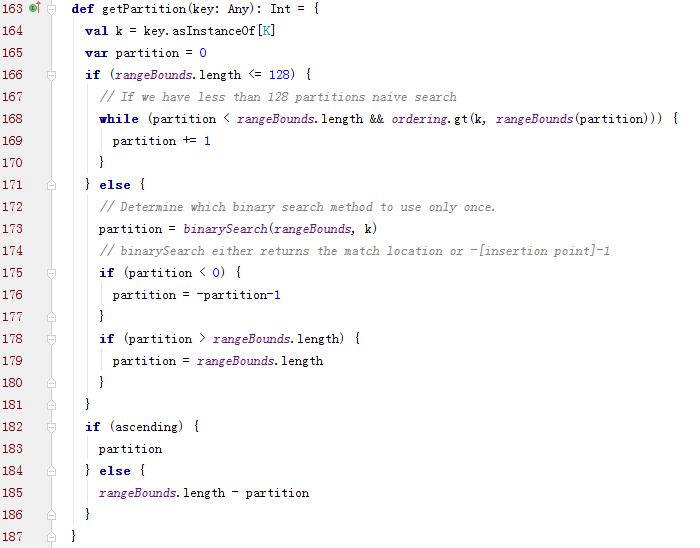
其中rangeBounds是各个分区的上边界的Array。而rangeBounds的具体计算是通过抽样进行估计的,具体代码可以参照RangePartitioner 实现简记
RangePartitioner是根据key值大小进行分区的,所以支持RDD的排序类算子
1.3dependencies(依赖关系)
Spark的运行过程就是RDD之间的转换, 因此, 必须记录RDD之间的生成关系(新RDD是由哪个或哪几个父RDD生成), 这就是所谓的依赖关系, 这样既有助于阶段和任务的划分, 也有助于在某个分区出错的时候, 只需要重新计算与当前出错的分区有关的分区,而不需要计算所有的分区.
dependencies_是一个记录Dependency关系的序列(Seq):

RDD是如何记录依赖关系的:
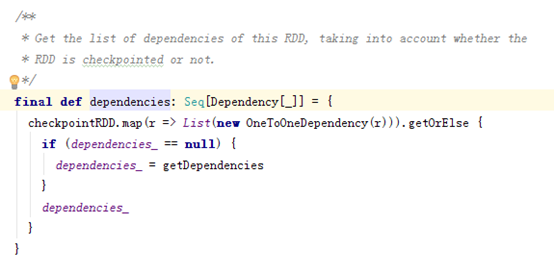 、
、
依赖类型:
- 窄依赖:父 RDD 的 partition 至多被一个子 RDD partition 依赖(OneToOneDependency,RangeDependency)
- 宽依赖:父 RDD 的 partition 被多个子 RDD partitions 依赖(ShuffleDependency)
图示:
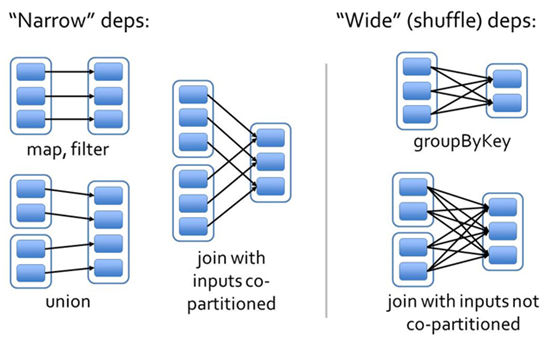
窄依赖是一对一的关系,所以可以直接从父分区中获取;宽依赖则不行。以下是宽依赖(实现是ShuffleDependency)的几个重要属性。更加具体的shuffle原理可以查看Spark Shuffle原理、Shuffle操作问题解决和参数调优

1.4compute(获取分区迭代列表)
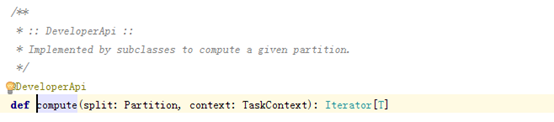
计算属性: 当调用 RDD#iterator 方法无法从缓存或 checkpoint 中获取指定 partition 的迭代器时,就需要调用 compute 方法来获取
RDD不仅包含有数据, 还有在数据上的计算, 每个RDD以分区为计算粒度, 每个RDD会实现compute函数, compute函数会和迭代器(RDD之间转换的迭代器)进行复合, 这样就不需要保存每次compute运行的结果.
代码:
下面举几个算子操作:
map
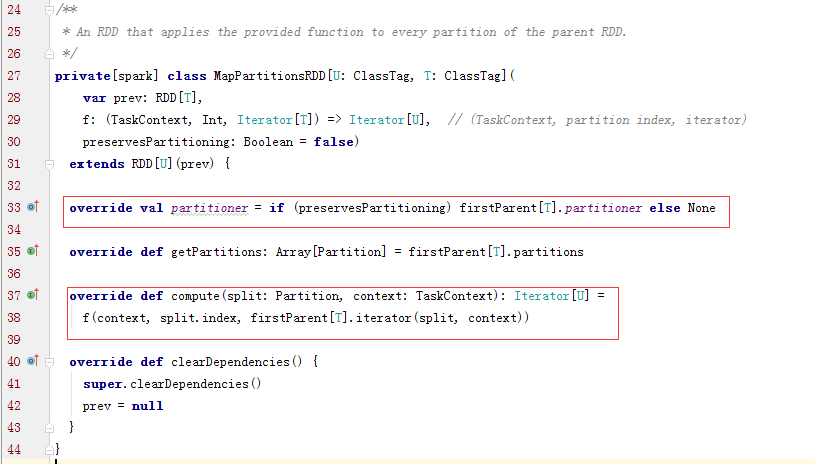

上面代码中的 firstParent 是指本 RDD 的依赖 dependencies: Seq[Dependency[_]] 中的第一个,MapPartitionsRDD 的依赖中只有一个父 RDD。而 MapPartitionsRDD 的 partition 与其唯一的父 RDD partition 是一一对应的,所以其 compute 方法可以描述为:对父 RDD partition 中的每一个元素执行传入 map (代码中的f(context,split.index,iterator)函数)的方法得到自身的 partition 及迭代器
图示:
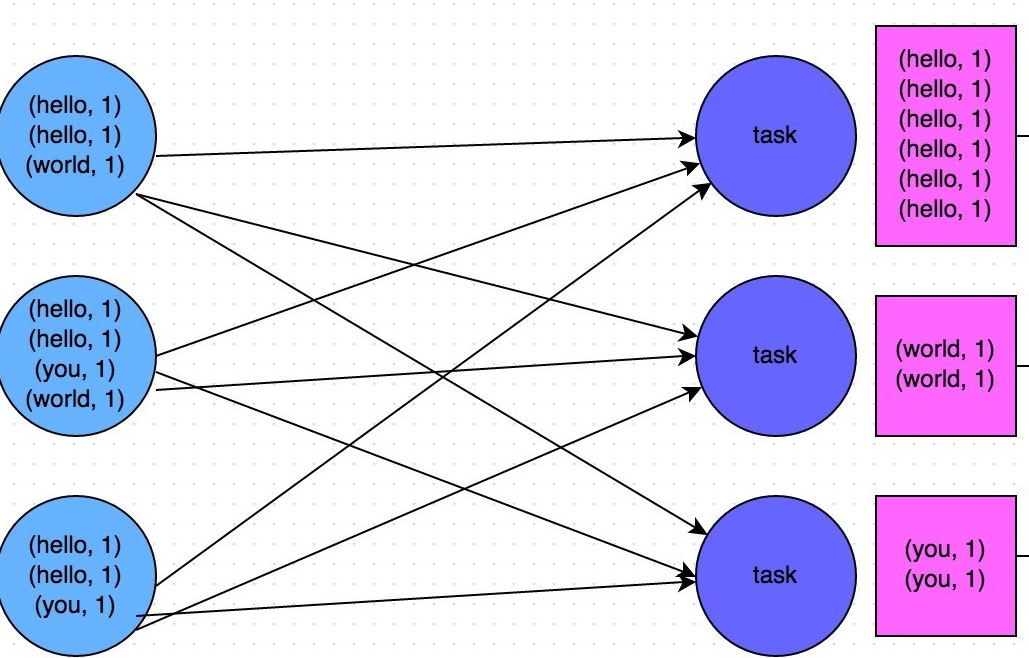
groupByKey
与 map、union 不同,groupByKey 是一个会产生宽依赖(ShuffleDependency)的 transform,其最终生成的 RDD 是 ShuffledRDD,来看看其 compute 实现:

可以看到,ShuffledRDD 的 compute 使用 ShuffleManager 来获取一个 reader,该 reader 将从本地或远程 BlockManager 拉取 map output 的 file 数据
图示:
1.5preferedLocations(优先分配节点列表)
对于分区而言返回数据本地化计算的节点列表
也就是说, 每个RDD会报出一个列表(Seq), 而这个列表保存着分片优先分配给哪个Worker节点计算, spark坚持移动计算而非移动数据的原则. 也就是尽量在存储数据的节点上进行计算.
要注意的是,并不是每个 RDD 都有 preferedLocation,比如从 Scala 集合中创建的 RDD 就没有,而从 HDFS 读取的 RDD 就有
spark 本地化级别:PROCESS_LOCAL => NODE_LOCAL => NO_PREF => RACK_LOCAL => ANY
PROCESS_LOCAL 进程本地化:task要计算的数据在同一个Executor中
NODE_LOCAL 节点本地化:速度比 PROCESS_LOCAL 稍慢,因为数据需要在不同进程之间传递或从文件中读取
NODE_PREF 没有最佳位置这一说,数据从哪里访问都一样快,不需要位置优先。比如说SparkSQL读取MySql中的数据
RACK_LOCAL 机架本地化,数据在同一机架的不同节点上。需要通过网络传输数据及文件 IO,比 NODE_LOCAL 慢
ANY 跨机架,数据在非同一机架的网络上,速度最慢
2.RDD实现类举例
2.1 MapPartitionsRDD
2.2 ShuffledRDD
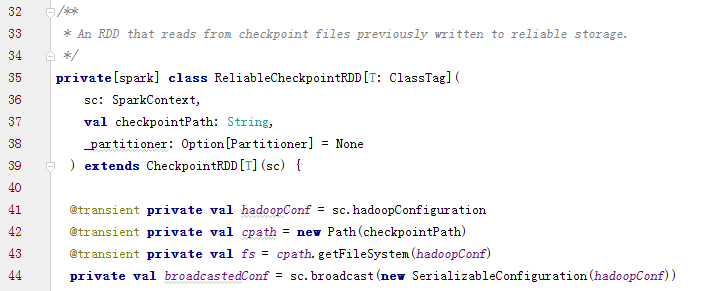
2.3 ReliableCheckpointRDD
ReliableCheckpointRDD将RDD写入到HDFS中
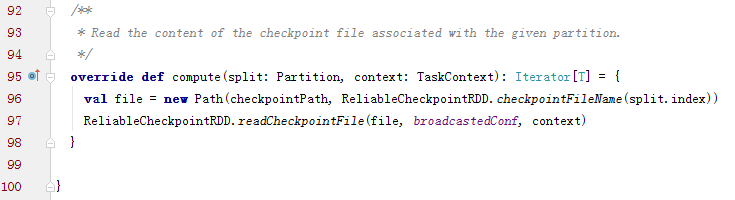
checkpointRDD的功能就是切断所有的之前RDD的依赖和迭代关系,所以compute方法只返回对应HDFS的文件反序列化流的一个迭代器就可以了
而且在ReliableCheckpointRDD中dependencies_属性是空的,也就没有实现getDependencies
另外多研究下RDD中的checkpoint方法:private def checkpointRDD: Option[CheckpointRDD[T]] = checkpointData.flatMap(_.checkpointRDD)
2.4 CoGroupedRDD (待补充)
3.RDD可以嵌套吗?
RDD嵌套是不被支持的,也即不能在一个RDD操作的内部再使用RDD。
Spark RDD 核心总结的更多相关文章
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- Spark RDD编程核心
一句话说,在Spark中对数据的操作其实就是对RDD的操作,而对RDD的操作不外乎创建.转换.调用求值. 什么是RDD RDD(Resilient Distributed Dataset),弹性分布式 ...
- [bigdata] Spark RDD整理
1. RDD是什么RDD:Spark的核心概念是RDD (resilient distributed dataset),指的是一个只读的,可分区的弹性分布式数据集,这个数据集的全部或部分可以缓存在内存 ...
- 《深入理解Spark:核心思想与源码分析》(第2章)
<深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 <深入理解Spark:核心思想与源码分析> ...
- Spark - RDD(弹性分布式数据集)
org.apache.spark.rddRDDabstract class RDD[T] extends Serializable with Logging A Resilient Distribut ...
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD是什么?(四)
RDD是什么? 通俗地理解,RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的.详细见 Spark的数据存储 Spark的核心数据模型是RDD,但RDD是个抽象类 ...
- Spark RDD整理
参考资料: Spark和RDD模型研究:http://itindex.net/detail/51871-spark-rdd-模型 理解Spark的核心RDD:http://www.infoq.com/ ...
- Spark RDD概念学习系列之Spark的算子的作用(十四)
Spark的算子的作用 首先,关于spark算子的分类,详细见 http://www.cnblogs.com/zlslch/p/5723857.html 1.Transformation 变换/转换算 ...
随机推荐
- GitHub实战系列汇总篇
基础: 1.GitHub实战系列~1.环境部署+创建第一个文件 2015-12-9 http://www.cnblogs.com/dunitian/p/5034624.html 2.GitHub实战系 ...
- 基于SignalR实现B/S系统对windows服务运行状态的监测
通常来讲一个BS项目肯定不止单独的一个BS应用,可能涉及到很多后台服务来支持BS的运行,特别是针对耗时较长的某些任务来说,Windows服务肯定是必不可少的,我们还需要利用B/S与windows服务进 ...
- ASP.Net MVC4+Memcached+CodeFirst实现分布式缓存
ASP.Net MVC4+Memcached+CodeFirst实现分布式缓存 part 1:给我点时间,允许我感慨一下2016年 正好有时间,总结一下最近使用的一些技术,也算是为2016年画上一个完 ...
- 重新认识了下Entity Framework
什么是Entity Framework Entity Framework是一个对象关系映射O/RM框架. Entity Framework让开发者可以像操作领域对象(domain-specific o ...
- CSS 3学习——box-sizing和背景
box-sizing 在CSS 2中设置元素的width和height仅仅是设置了元素内容区的宽和高,元素实际的尺寸是margin + border + padding + 内容区. CSS 3(截止 ...
- .NET 基础 一步步 一幕幕[面向对象之对象和类]
对象和类 本篇正式进入面向对象的知识点简述: 何为对象,佛曰:一花一世界,一木一浮生,一草一天堂,一叶一如来,一砂一极乐,一方一净土,一笑一尘缘,一念一清静.可见"万物皆对象". ...
- gulp批量打包文件并提取公共文件
gulp是前端开发过程中对代码进行构建的工具,是自动化项目的构建利器. browseriyf是模块化打包工具. 一般情况下,Browserify 会把所有的模块打包成单个文件.单个文件在大多数情况下是 ...
- SAP CRM 用户界面对象类型和设计对象
在CRM中的用户界面对象类型的帮助下,我们可以做这些工作: 进行不同的视图配置 创建动态导航 从设计层控制字段标签.值帮助 控制BOL对象的属性的可视性 从导航栏访问自定义组件 一个用户界面对象类型之 ...
- SQL 数据优化索引建suo避免全表扫描
首先什么是全表扫描和索引扫描?全表扫描所有数据过一遍才能显示数据结果,索引扫描就是索引,只需要扫描一部分数据就可以得到结果.如果数据没建立索引. 无索引的情况下搜索数据的速度和占用内存就会比用索引的检 ...
- 跟着老男孩教育学Python开发【第五篇】:模块
递归的案例:阶乘 1*2*3*4*5*6*7- def func(num): if num == 1: return 1 return num * func(num - ...