python爬取github数据
爬虫流程
在上周写完用scrapy爬去知乎用户信息的爬虫之后,github上star个数一下就在公司小组内部排的上名次了,我还信誓旦旦的跟上级吹牛皮说如果再写一个,都不好意思和你再提star了,怕你们伤心。上级不屑的说,那就写一个爬虫爬一爬github,找一找python大牛,公司也正好在找人。临危受命,格外激动,当天就去研究github网站,琢磨怎么解析页面以及爬虫的运行策略。意外的发现github提供了非常nice的API以及文档文档,让我对github的爱已经深入骨髓。
说了这么多废话,讲讲真题吧。我需要下载github用户还有他们的reposities数据,展开方式也很简单,根据一个用户的following以及follower关系,遍历整个用户网就可以下载所有的数据了,听说github注册用户才几百万,一下就把所有的数据爬下来想想还有点小激动呢,下面是流程图:
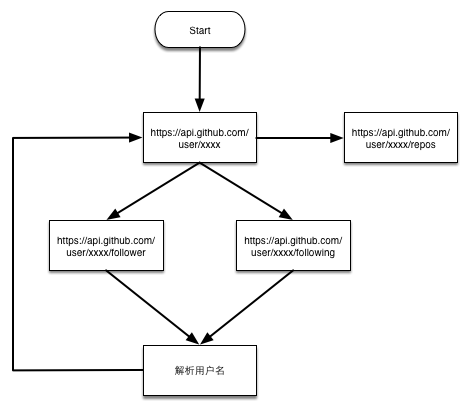
这是我根据这个流程实现的代码,网址:https://github.com/LiuRoy/github_spider
递归实现
运行命令
看到这么简单的流程,内心的第一想法就是先简单的写一个递归实现呗,要是性能差再慢慢优化,所以第一版代码很快就完成了(在目录recursion下)。数据存储使用mongo,重复请求判断使用的redis,写mongo数据采用celery的异步调用,需要rabbitmq服务正常启动,在settings.py正确配置后,使用下面的步骤启动:
- 进入github_spider目录
- 执行命令
celery -A github_spider.worker worker loglevel=info启动异步任务 - 执行命令
python github_spider/recursion/main.py启动爬虫
运行结果
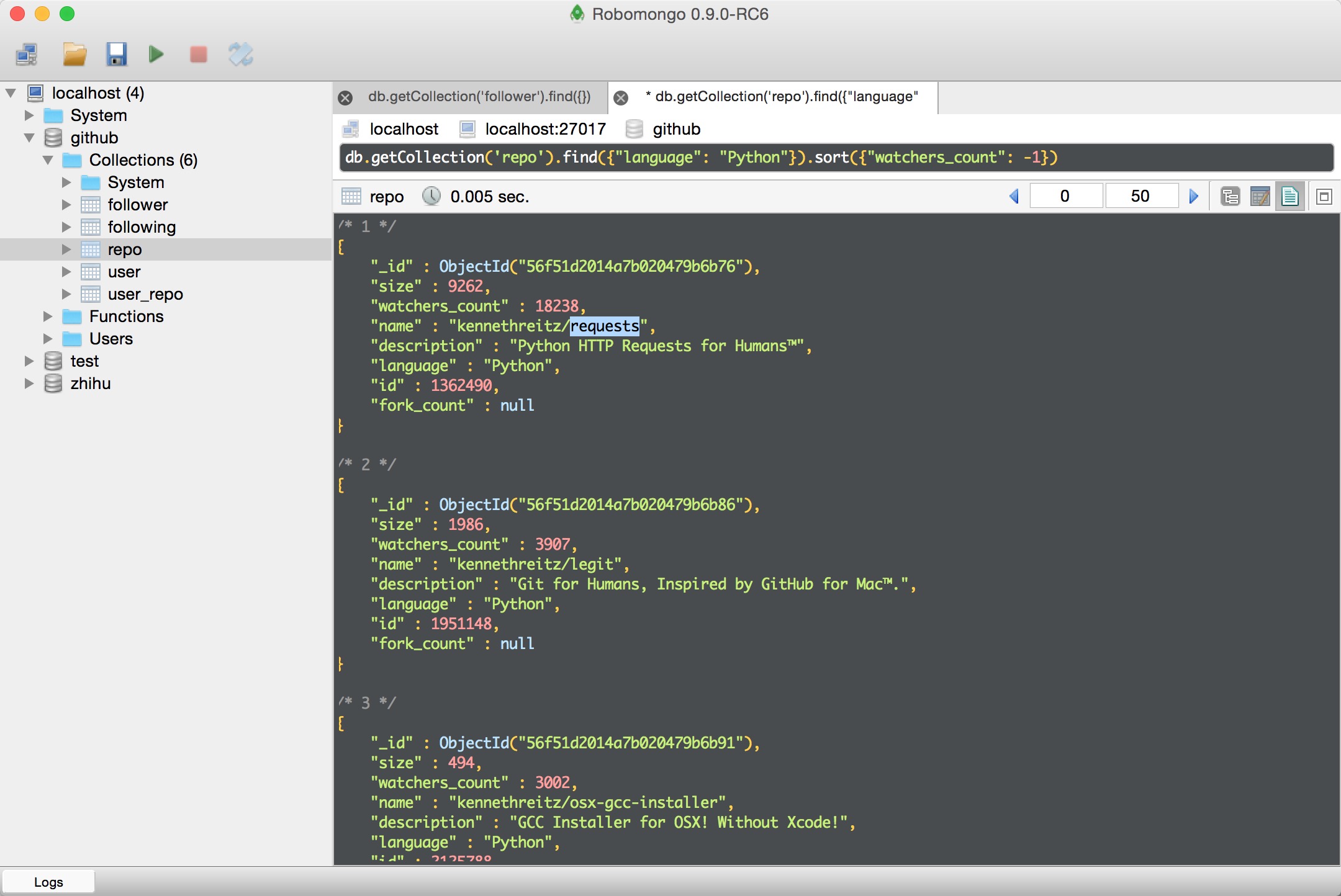
因为每个请求延时很高,爬虫运行效率很慢,访问了几千个请求之后拿到了部分数据,这是按照查看数降序排列的python项目:
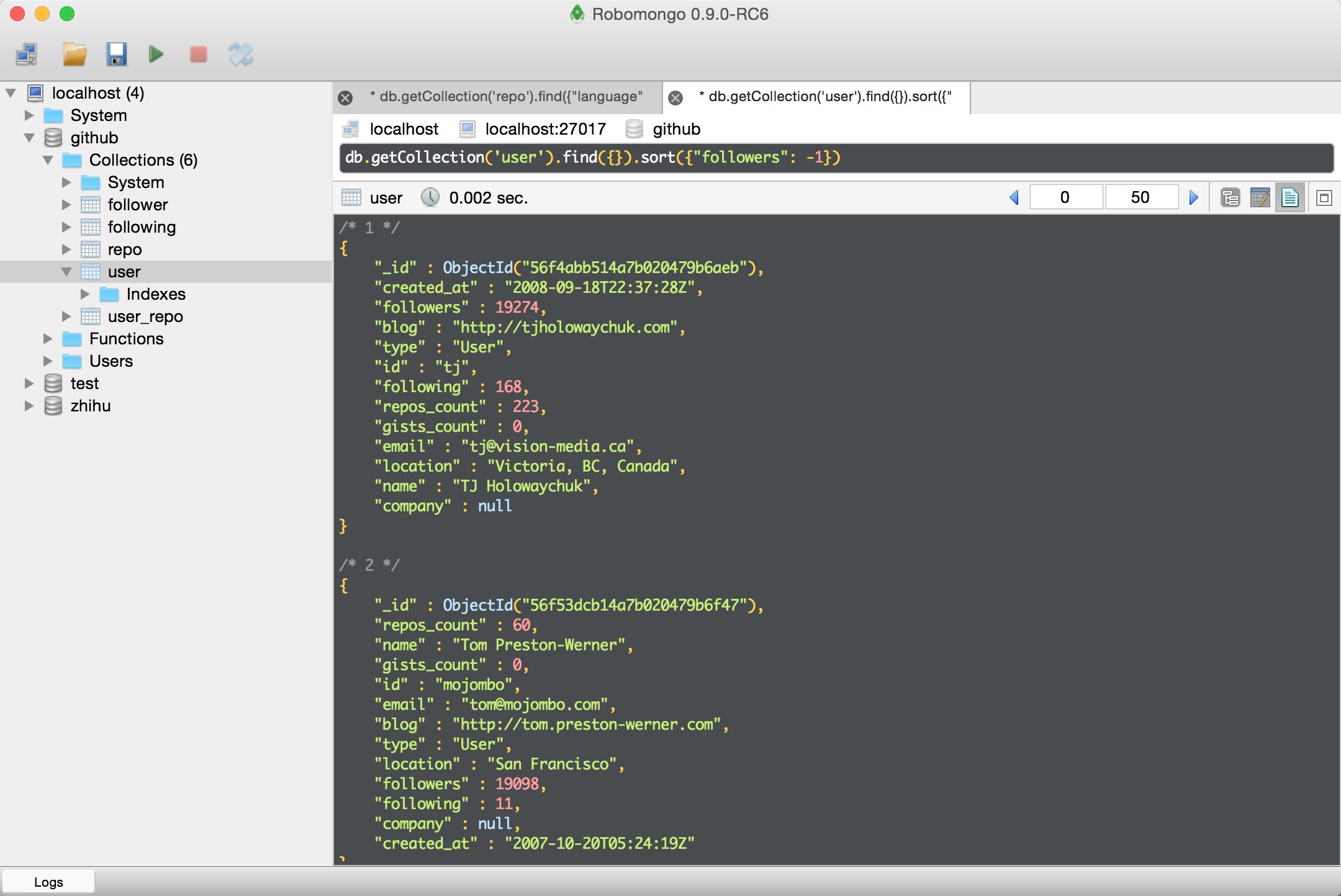
这是按粉丝数降序排列的用户列表
运行缺陷
作为一个有追求的程序员,当然不能因为一点小成就满足,总结一下递归实现的几个缺陷:
- 因为是深度优先,当整个用户图很大的时候,单机递归可能造成内存溢出从而使程序崩溃,只能在单机短时间运行。
- 单个请求延时过长,数据下载速度太慢。
- 针对一段时间内访问失败的链接没有重试机制,存在数据丢失的可能。
异步优化
针对这种I/O耗时的问题,解决方法也就那几种,要么多并发,要么走异步访问,要么双管齐下。针对上面的问题2,我最开始的解决方式是异步请求API。因为最开始写代码的时候考虑到了这点,代码对调用方法已经做过优化,很快就改好了,实现方式使用了grequests。这个库和requests是同一个作者,代码也非常的简单,就是讲request请求用gevent做了一个简单的封装,可以非阻塞的请求数据。
但是当我运行之后,发现程序很快运行结束,一查发现公网IP被github封掉了,当时心中千万只草泥马奔腾而过,没办法只能祭出爬虫的终极杀器--代理。又专门写了一个辅助脚本从网上爬取免费的HTTPS代理存放在redis中,路径proxy/extract.py,每次请求的时候都带上代理,运行错误重试自动更换代理并把错误代理清楚。本来网上免费的HTTPS代理就很少,而且很多还不能用,由于大量的报错重试,访问速度不仅没有原来快,而且比原来慢一大截,此路不通只能走多并发实现了。
队列实现
实现原理
采取广度优先的遍历的方式,可以把要访问的网址存放在队列中,再套用生产者消费者的模式就可以很容易的实现多并发,从而解决上面的问题2。如果某段时间内一直失败,只需要将数据再仍会队列就可以彻底解决问题3。不仅如此,这种方式还可以支持中断后继续运行,程序流程图如下:
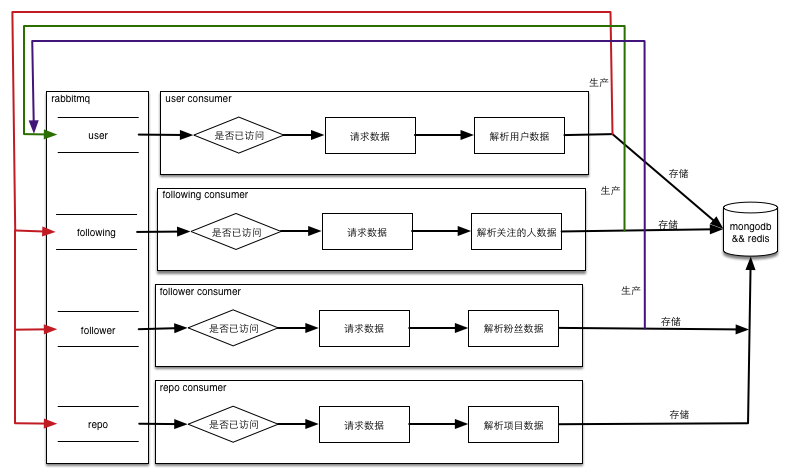
运行程序
为了实现多级部署(虽然我就只有一台机器),消息队列使用了rabbitmq,需要创建名为github,类型是direct的exchange,然后创建四个名称分别为user, repo, follower, following的队列,详细的绑定关系见下图:
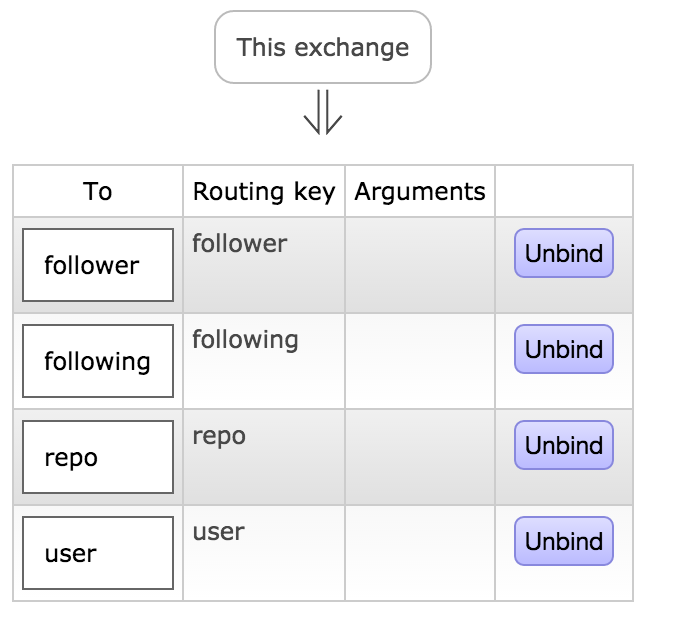
详细的启动步骤如下:
- 进入github_spider目录
- 执行命令
celery -A github_spider.worker worker loglevel=info启动异步任务 - 执行命令
python github_spider/proxy/extract.py更新代理 - 执行命令
python github_spider/queue/main.py启动脚本
队列状态图:

python爬取github数据的更多相关文章
- 如何使用Python爬取基金数据,并可视化显示
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 以下文章来源于Will的大食堂,作者打饭大叔 前言 美国疫情越来越严峻,大选也进入 ...
- 毕设之Python爬取天气数据及可视化分析
写在前面的一些P话:(https://jq.qq.com/?_wv=1027&k=RFkfeU8j) 天气预报我们每天都会关注,我们可以根据未来的天气增减衣物.安排出行,每天的气温.风速风向. ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- Python爬取房产数据,在地图上展现!
小伙伴,我又来了,这次我们写的是用python爬虫爬取乌鲁木齐的房产数据并展示在地图上,地图工具我用的是 BDP个人版-免费在线数据分析软件,数据可视化软件 ,这个可以导入csv或者excel数据. ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- python爬取拉勾网数据并进行数据可视化
爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做 ...
- 用Python爬取股票数据,绘制K线和均线并用机器学习预测股价(来自我出的书)
最近我出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中用股票范例讲述Pyth ...
- 用python爬取微博数据并生成词云
很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,放在今天应该比较应景. 一年一度的虐汪节,是继续蹲在角落默 ...
- 使用 Python 爬取网页数据
1. 使用 urllib.request 获取网页 urllib 是 Python 內建的 HTTP 库, 使用 urllib 可以只需要很简单的步骤就能高效采集数据; 配合 Beautiful 等 ...
随机推荐
- ASP.NET Aries 入门开发教程7:DataGrid的行操作(主键操作区)
前言: 抓紧勤奋,再接再励,预计共10篇来结束这个系列. 上一篇介绍:ASP.NET Aries 入门开发教程6:列表数据表格的格式化处理及行内编辑 本篇介绍主键操作区相关内容. 1:什么时候有默认的 ...
- Partition2:对表分区
在SQL Server中,普通表可以转化为分区表,而分区表不能转化为普通表,普通表转化成分区表的过程是不可逆的,将普通表转化为分区表的方法是: 在分区架构(Partition Scheme)上创建聚集 ...
- .NET同步与异步之相关背景知识(六)
在之前的五篇随笔中,已经介绍了.NET 类库中实现并行的常见方式及其基本用法,当然.这些基本用法远远不能覆盖所有,也只能作为一个引子出现在这里.以下是前五篇随笔的目录: .NET 同步与异步之封装成T ...
- [修正] Firemonkey TFrame 存档后,下次载入某些事件连结会消失(但源码还在)
问题:Firemonkey TFrame 存档后,下次载入某些事件连结会消失(但源码还在) 解决:(暂时方法) type TTestFrame = class(TFrame) public const ...
- PHP设计模式(六)原型模式(Prototype For PHP)
原型设计模式: 用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象. 原型设计模式简单的来说,顾名思义, 不去创建新的对象进而保留原型的一种设计模式. 缺点:原型设计模式是的最主要的缺点就 ...
- java观察者模式
像activeMQ等消息队列中,我们经常会使用发布订阅模式,但是你有没有想过,客户端时如何及时得到订阅的主题的信息?其实就里就用到了观察者模式.在软件系统中,当一个对象的行为依赖于另一个对象的状态 ...
- 【干货分享】流程DEMO-资产请购单
流程名: 资产请购 业务描述: 流程发起时,会检查预算,如果预算不够,流程必须经过总裁审批,如果预算够用,将发起流程,同时占用相应金额的预算,但撤销流程会释放相应金额的预算. 流程相关文件: 流程 ...
- CentOS:Yum源的配置
# cd /etc/yum.repos.d/ # mv CentOS-Base.repo CentOS-Base.repo.bak # wget http://mirrors.163.com/.hel ...
- 分享一个php的启动关闭脚本(原)
自己简单写的一个php服务的启动脚本和大家分享 思路(实现的原理): 1:function模块+case语句多分支判断 2:通过添加# chkconfig: 2345 43 89注释实现开机自启动(前 ...
- ASP.NET 5 (vNext) Linux部署
引言 工欲善其事,必先利其器. 首先,我们先明确下以下基本概念 Linux相关 Ubuntu Ubuntu是基于linux的免费开源桌面PC操作系统 十分契合英特尔的超极本定位 支持x86.64位和p ...