Scrapy框架爬虫初探——中关村在线手机参数数据爬取
关于Scrapy如何安装部署的文章已经相当多了,但是网上实战的例子还不是很多,近来正好在学习该爬虫框架,就简单写了个Spider Demo来实践。
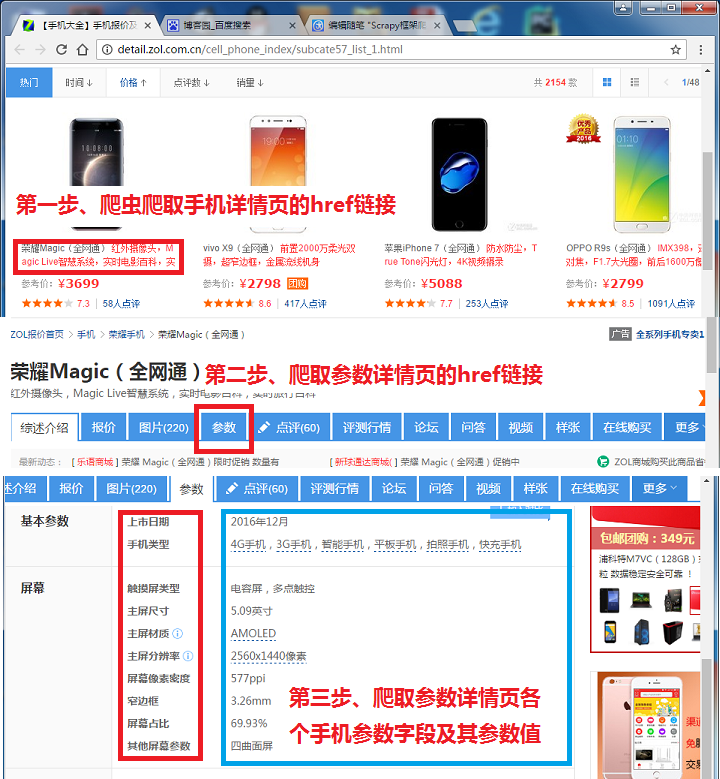
作为硬件数码控,我选择了经常光顾的中关村在线的手机页面进行爬取,大体思路如下图所示。
# coding:utf-8
import scrapy
import re
import os
import sqlite3
from myspider.items import SpiderItem class ZolSpider(scrapy.Spider):
name = "zol"
# allowed_domains = ["http://detail.zol.com.cn/"] # 用于限定爬取的服务器域名
start_urls = [
# 主要爬去中关村在线的手机信息页面,考虑到是演示目的就仅仅爬了首页,其实爬分页跟二级爬虫原理相同,出于节省时间目的这里就不爬了
# 这里可以写多个入口URL
"http://detail.zol.com.cn/cell_phone_index/subcate57_list_1.html"
]
item = SpiderItem() # 没法动态创建,索性没用上,用的meta在spider函数间传值
# 只是test一下就用sqlite吧,比较轻量化
#database = sqlite3.connect(":memory:")
database_file = os.path.dirname(os.path.abspath(__file__)) + "\\phonedata.db"
if os.path.exists(database_file):
os.remove(database_file)
database = sqlite3.connect(database_file)
# 先建个字段,方便理解字段含义就用中文了
database.execute(
'''
CREATE TABLE CELL_PHONES
(
手机型号 TEXT
);
'''
)
# 用于检查数据增改是否全面,与total_changes对比
counter = 0 # 手机报价首页爬取函数
def parse(self, response):
# 获取手机详情页链接并以其创建二级爬虫
hrefs = response.xpath("//h3/a")
for href in hrefs:
url = response.urljoin(href.xpath("@href")[0].extract())
yield scrapy.Request(url, self.parse_detail_page) # 手机详情页爬取函数
def parse_detail_page(self, response):
# 通过xpath获取手机型号
model = response.xpath("//h1").xpath("text()")[0].extract()
# 创建该型号手机的数据库记录
sql = 'INSERT INTO CELL_PHONES (手机型号) VALUES ("' + model + '")'
self.counter += 1
self.database.execute(sql)
self.database.commit()
# 获取参数详情页的链接
url = response.urljoin(response.xpath("//div[@id='tagNav']//a[text()='参数']").xpath("@href")[0].extract())
# 由于Scrapy是异步驱动的(逐级启动爬虫函数),所以当需绑定父子级爬虫函数间的某些变量时,可以采用meta字典传递,全局的item字段无法动态创建,在较灵活的爬取场景中不是很适用
yield scrapy.Request(url, callback=self.parse_param_page, meta={'model': model}) # 手机参数详情页爬取函数
def parse_param_page(self, response):
# 获取手机参数字段并一一遍历
params = response.xpath("//span[contains(@class,'param-name')]")
for param in params:
legal_param_name_field = param_name = param.xpath("text()")[0].extract()
# 将手机参数字段转变为合法的数据库字段(非数字开头,且防止SQL逻辑污染剔除了'/'符号)
if re.match(r'^\d', param_name):
legal_param_name_field = re.sub(r'^\d', "f" + param_name[0], param_name)
if '/' in param_name:
legal_param_name_field = legal_param_name_field.replace('/', '')
# 通过查询master表检查动态添加的字段是否已经存在,若不存在则增加该字段
sql = "SELECT * FROM sqlite_master WHERE name='CELL_PHONES' AND SQL LIKE '%" + legal_param_name_field + "%'"
if self.database.execute(sql).fetchone() is None:
sql = "ALTER TABLE CELL_PHONES ADD " + legal_param_name_field + " TEXT"
self.database.execute(sql)
self.database.commit()
# 根据参数字段名的xpath定位参数值元素
xpath = "//span[contains(@class,'param-name') and text()='" + param_name +\
"']/following-sibling::span[contains(@id,'newPmVal')]//text()"
vals = response.xpath(xpath)
# 由于有些字段的参数值是多个值,所以需将其附加到一起,合成一个字段,以方便存储。
# 如需数据细分选用like子句或支持全文索引的数据库也不错,当然nosql更好
pm_val = ""
for val in vals:
pm_val += val.extract()
re.sub(r'\r|\n',"",pm_val)
sql = "UPDATE CELL_PHONES SET %s = '%s' WHERE 手机型号 = '%s'" \
% (legal_param_name_field, pm_val, response.meta['model'])
self.database.execute(sql)
self.counter += 1
# 检查下爬取的数据对不对
results = self.database.execute("SELECT * FROM CELL_PHONES").fetchall()
# 千万别忘了commit否则持久化数据库可能结果不全
self.database.commit()
print(self.database.total_changes, self.counter) # 对比下数据库的增改情况是否有丢失
for row in results:
print(row, end='\n') # 其实这里有个小小的编码问题需要解决
# 最后愉快的用scrapy crawl zol 启动爬虫吧!
部分爬到数据库的数据最后建议在settings脚本中修改USER_AGENT,以模拟浏览器请求,避免反爬,例如:
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
当然高级点的反爬手段也有别的办法应付:
1.基于用户行为的爬取,可以增设爬取逻辑路由,以动态的爬行方式获取资源,并且频繁切换IP及UA,基于session及cookie的反爬亦可以基于此手段;
2.AJAX等异步js交互的页面,可自定义js请求,如果请求被加密了,结合selenium + webdriver来驱动浏览器,模拟用户交互异曲同工;
3.关于匹配方式,正则,XPath、CSS等等selector因人而异,前端经常调整的话不建议用CSS selector;
正则表达式从执行效率上较XPath会高一些,但是XPath可以基于元素逻辑层次、属性值条件,甚至结合XPath函数十分灵活的定位一个多个(组)元素;
总的来说做爬虫的同学,正则和XPath应该是基本功啦,特别是在定向爬取数据时尤为重要。
4.关于路由及任务调度问题,虽然Scrapy提供了非常简单的异步IO方案,能够轻松爬取多级页面,并根据base URL及灵活的自定义回调函数实现深层(有选择的)爬虫,
但对于爬取海量数据的场景,灵活性较差,因此队列管理(排重、防中断、防重跑)及分布式爬虫可能更为适用。
当然,学习Python爬虫,掌握urllib(2、3)、requests、BeautifulSoup、lxml等模块也会让你如虎添翼,还需因地制宜才是。
p.s.进来用Golang做爬虫的童鞋也多了起来,性能较之Python会好不少,可以尝试一下。会JAVA的童鞋,也可以关注下Nutch引擎。(路漫漫其修远兮啊,一起学习吧。)
Scrapy框架爬虫初探——中关村在线手机参数数据爬取的更多相关文章
- Python爬虫入门教程 29-100 手机APP数据抓取 pyspider
1. 手机APP数据----写在前面 继续练习pyspider的使用,最近搜索了一些这个框架的一些使用技巧,发现文档竟然挺难理解的,不过使用起来暂时没有障碍,估摸着,要在写个5篇左右关于这个框架的教程 ...
- python 手机app数据爬取
目录 一:爬取主要流程简述 二:抓包工具Charles 1.Charles的使用 2.安装 (1)安装链接 (2)须知 (3)安装后 3.证书配置 (1)证书配置说明 (2)windows系统安装证书 ...
- Python爬虫:用BeautifulSoup进行NBA数据爬取
爬虫主要就是要过滤掉网页中没用的信息.抓取网页中实用的信息 一般的爬虫架构为: 在python爬虫之前先要对网页的结构知识有一定的了解.如网页的标签,网页的语言等知识,推荐去W3School: W3s ...
- selenium在爬虫中的应用之动态数据爬取
一.selenium概念 selenium 是一个基于浏览器自动化的模块 selenium爬虫之间的关联: 1.便捷的获取动态加载的数据 2.实现模拟登录 基本使用 pip install selen ...
- (转)python爬虫----(scrapy框架提高(1),自定义Request爬取)
摘要 之前一直使用默认的parse入口,以及SgmlLinkExtractor自动抓取url.但是一般使用的时候都是需要自己写具体的url抓取函数的. python 爬虫 scrapy scrapy提 ...
- python3爬虫初探(五)之从爬取到保存
想一想,还是写个完整的代码,总结一下前面学的吧. import requests import re # 获取网页源码 url = 'http://www.ivsky.com/tupian/xiaoh ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
随机推荐
- 【.net 深呼吸】细说CodeDom(8):分支与循环
有人会问,为啥 CodeDom 不会生成 switch 语句,为啥没生成 while 语句之类.要注意,CodeDom只关心代码逻辑,而不是语法,语法是给写代码的人用的.如果用.net的“反编译”工具 ...
- Travis CI用来持续集成你的项目
这里持续集成基于GitHub搭建的博客为项目 工具: zqz@ubuntu:~$ node --version v4.2.6 zqz@ubuntu:~$ git --version git versi ...
- [linux]阿里云主机的免登陆安全SSH配置与思考
公司服务器使用的第三方云端服务,即阿里云,而本地需要经常去登录到服务器做相应的配置工作,鉴于此,每次登录都要使用密码是比较烦躁的,本着极速思想,我们需要配置我们的免登陆. 一 理论概述 SSH介绍 S ...
- 深入浅出Redis-redis底层数据结构(上)
1.概述 相信使用过Redis 的各位同学都很清楚,Redis 是一个基于键值对(key-value)的分布式存储系统,与Memcached类似,却优于Memcached的一个高性能的key-valu ...
- 百度推出新技术 MIP,网页加载更快,广告呢?
我们在2016年年初推出了MIP,帮助移动页面加速(原理).内测数据表明,MIP页面在1s内加载完成.现在已经有十多家网站加入MIP项目,有更多的网站正在加入中.在我们收到的反馈中,大部分都提到了广告 ...
- 预览github里面的网页或dome
1.问题所在: 之前把项目提交到github都可以在路径前面加上http://htmlpreview.github.io/?来预览demo,最近发现这种方式预览的时候加载不出来css,js(原因不详) ...
- CoreCRM 开发实录——Travis-CI 实现 .NET Core 程度在 macOS 上的构建和测试 [无水干货]
上一篇文章我提到:为了使用"国货",我把 Linux 上的构建和测试委托给了 DaoCloud,而 Travis-CI 不能放着不用啊.还好,这货支持 macOS 系统.所以就把 ...
- Java消息队列--JMS概述
1.什么是JMS JMS即Java消息服务(Java Message Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送 ...
- 代码的坏味道(16)——纯稚的数据类(Data Class)
坏味道--纯稚的数据类(Data Class) 特征 纯稚的数据类(Data Class) 指的是只包含字段和访问它们的getter和setter函数的类.这些仅仅是供其他类使用的数据容器.这些类不包 ...
- Android 工具-adb
Android 工具-adb 版权声明:本文为博主原创文章,未经博主允许不得转载. Android 开发中, adb 是开发者经常使用的工具,是 Android 开发者必须掌握的. Android D ...