【STL和泛型编程】4. hashtable、unordered_set、unordered_map
1. hashtable
前置知识:【数据结构】3.跳表和散列
基本原理:
- 将Key计算成一个数值,然后取余数得到它在表头中的位置
- table(篮子)里每个指针都指向一个链表(桶)来存储余数相同的值
- 如果桶内的元素个数比篮子个数还多,则将篮子的大小扩充
- 篮子是vector,数量是质数,初始为53,53扩充后为97
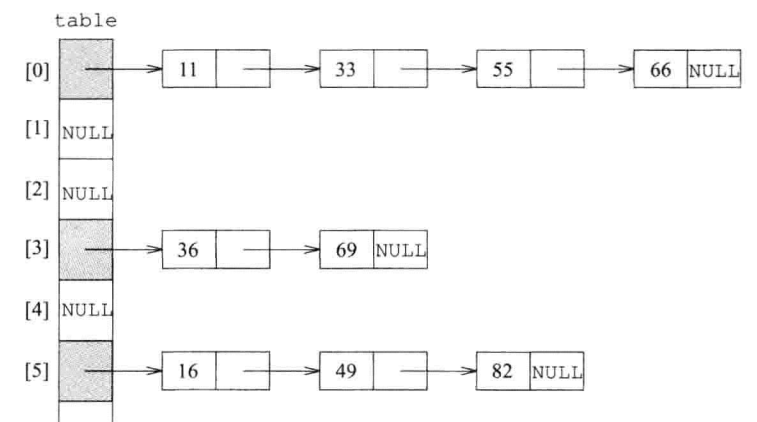
hashtable需要传入Value(Key+Data),Key,计算哈希的方法,从Value中取出Key的方法,比较Key是否相等的方法,以及分配器来实例化
template <class Value, class Key, class HashFcn, class ExtractKey, class EqualKey, class Alloc=alloc>
class hashtable {
public:
typedef HashFcn hasher;
typedef EqualKey key_equal;
typedef size_t size_type;
private:
hasher hash;
key_equal equals;
ExtractKey get_key; typedef __hashtable_node<Value> node; vector<node*, Alloc> bucket;
size_type num_element;
public:
size_type bucket_count() const {return bucket.size(); }
};
template <class Value>
struct __hashtable_node {
__hashtable_node* next;
Value val;
};
hashtable的篮子使用vector数组实现,迭代器中有两个指针,*cur指向当前元素位置,*ht指向它在篮子中的位置,实现操作者视角的++操作
template <class Value, class Key, class HashFcn, class ExtractKey, class EqualKey, class Alloc>
struct __hashtable_iterator {
//...
node* cur;
hashtable* ht;
// ...
};
2. unordered_set / multi
第二个模板参数中,C++底层提供的哈希函数 hash<Key> 只适用于基本数据类型(包括 string 类型);第三个模板参数中,仅支持可直接用 == 运算符做比较的数据类型
template < class Key, //容器中存储元素的类型
class Hash = hash<Key>, //确定元素存储位置所用的哈希函数
class Pred = equal_to<Key>, //判断各个元素是否相等所用的函数
class Alloc = allocator<Key> //指定分配器对象的类型
> class unordered_set;
3. unordered_map / multi
Key是键值对中的键、T是键值对中的data,<Key, T>组成hashtable中的Value。接下来的模板参数与unordered_set中相同
template < class Key, //键值对中键的类型
class T, //键值对中值的类型
class Hash = hash<Key>, //容器内部存储键值对所用的哈希函数
class Pred = equal_to<Key>, //判断各个键值对键相同的规则
class Alloc = allocator< pair<const Key,T> > // 指定分配器对象的类型
> class unordered_map;
4. unordered_map 和 map 对比
- map / set ,底层实现是红黑树
- + 自带排序的性质
- + 查找的时间复杂度是O(logn)
- - 每个节点都需要存储额外的信息
- unordered_map / unordered_set,底层是哈希表
- + 哈希表通过Key计算查找非常快 理想情况下是O(1)
- - 篮子数量>元素数量,每次扩充复制的时候比较耗时
【STL和泛型编程】4. hashtable、unordered_set、unordered_map的更多相关文章
- STL set multiset map multimap unordered_set unordered_map example
I decide to write to my blogs in English. When I meet something hard to depict, I'll add some Chines ...
- STL之map与pair与unordered_map常用函数详解
STL之map与pair与unordered_map常用函数详解 一.map的概述 map是STL的一个关联容器,它提供一对一(其中第一个可以称为关键字,每个关键字只能在map中出现一次,第二个可能称 ...
- C++进阶(unordered_set+unordered_map模拟实现)
unordered_set unordered_set是以无特定顺序存储唯一元素的容器,并且允许根据它们的值快速检索单个元素,是一种K模型. 在unordered_set中,元素的值同时是它的key, ...
- 侯捷STL学习(十)--容器hashtable探索(unordered set/map)
layout: post title: 侯捷STL学习(十) date: 2017-07-23 tag: 侯捷STL --- 第二十三节 容器hashtable探索 hashtable冲突(碰撞)处理 ...
- [GeekBand] STL与泛型编程(1)
在C++语法的学习过程中,我们已经对模板有了基本的了解.泛型编程就是以模板为工具的.泛化的编程思想.本篇文章介绍了一些在之前的文章中没有涉及到的一些模板知识.泛型编程知识和几种容器.关于模板的一些重复 ...
- STL源码剖析——hashtable
二叉搜索树具有对数时间的搜索复杂度,但是这样的复杂度是再输入数据有足够的随机性的假设上哈希表在插入删除搜索操作上也具有常数时间的表现,而且这种表现是以统计为基础,不需要依赖输入元素的随机性 hasht ...
- 【STL】关联容器 — hashtable
C++ 11哈希表已被列入标准列.hashtable这是hash_set.hash_map.hash_multiset.hash_multimap的底层机制.即这四种容器中都包括一个hashtable ...
- [GeekBand] STL与泛型编程(2)
本篇文章在上一篇文章的基础上进一步介绍一些常用的容器以及STL的一些深入知识. 一. Stack和Queue 栈和队列是非常常用的两种数据结构,由deque适配而来.关于数据结构的知识这里就不在介绍了 ...
- STL容器(C11)--unordered_set用法
http://www.cplusplus.com/reference/unordered_set/
- STL关联容器值hashtable
hashtable(散列表)是一种数据结构,在元素的插入,删除,搜索操作上具有常数平均时间复杂度O(1); hashtable名词 散列函数:负责将某一元素映射为索引. 碰撞(collision):不 ...
随机推荐
- C#配置系统
读取JSON文件 NuGet两个包:Microsoft.Extensions.Configuration,Mircosoft.Extensions.Configuration.Json. { &quo ...
- ISCTF的MISC复现
1. 小蓝鲨的签到02 随波逐流 识别问题加上IS即可 2. 数字迷雾:在像素中寻找线索 还是随波逐流 加个} 3. 小蓝鲨的签到01 关注公众号发送ISCTF2024即可 4. 小蓝鲨的问卷 答完得 ...
- Windows平台调试器原理与编写02.一般断点与反汇编引擎
https://www.bpsend.net/thread-256-1-2.html 一般断点(软件断点) 断点的尊严 断的下来 走的过去 下次还来 所有合格的断点都应该满足这3个要求 OD下断点实际 ...
- 【公众号搬运】React-Native开发鸿蒙NEXT
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...
- HTTP接口的中文乱码问题【python版】
一.问题:在软件接口开发过程中,request返回的信息在print的时候出现了乱码.默认编码:ISO-8859-1问题原因:可以在request语句后面插入print(result.enco ...
- AI面试助手面试精灵重磅发布“双栏模式”:极速和精准可以兼得
引言 面试中的每一秒都至关重要,许多求职者反馈:面对面试官的犀利提问,要么因"卡壳"错失良机,要么因追求准确而延误回答时机.作为以顶级GPT为核心的AI面试助手,面试精灵始终致力于 ...
- GoLand2023设置GitBash为默认命令行终端
修改设置中的终端配置,将其修改为你的git bash启动脚本,注意需要带-login -i: 验证成功:
- manim边做边学--参数化曲线
在数学可视化领域,参数方程提供了一种灵活描述曲线的方式. Manim库中的ParametricFunction类正是为此而生,它允许用户通过参数方程创建各种复杂的二维和三维曲线. Parametric ...
- WineHQ 发布的 Framework Mono 6.14 的这个特性对Windows Forms 用户来说肯定很感兴趣
微软于 2024年8月 将 Mono 项目所有权正式捐赠给 WineHQ 组织,标志着该项目进入开源社区主导的新阶段,WineHQ 在 2025年3月8日 发布了接管后的首个版本 Framework ...
- WEB DYNPRO程序找文本
ABAP里代码扫描就是用的SOURCE SCAN. WEB DYNPRO里有个单独的 事务代码SE24进入,执行类CL_WDY_WB_NAMING_SERVICE的方法GET_CLASSNAME_FO ...