Mysql篇-语句执行计划详解(explain)
概述
使用 explain 输出 SELECT 语句执行的详细信息,包括以下信息:
- 表的加载顺序
- sql 的查询类型
- 可能用到哪些索引,实际上用到哪些索引
- 读取的行数
Explain 执行计划包含字段信息如下:分别是 id、select_type、table、partitions、type、possible_keys、key、key_len、ref、rows、filtered、Extra 12个字段。
通过explain extended + show warnings可以在原本explain的基础上额外提供一些查询优化的信息,得到优化以后的可能的查询语句(不一定是最终优化的结果)。
测试环境:
CREATE TABLE `blog` (
`blog_id` int NOT NULL AUTO_INCREMENT COMMENT '唯一博文id--主键',
`blog_title` varchar(255) NOT NULL COMMENT '博文标题',
`blog_body` text NOT NULL COMMENT '博文内容',
`blog_time` datetime NOT NULL COMMENT '博文发布时间',
`update_time` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
`blog_state` int NOT NULL COMMENT '博文状态--0 删除 1正常',
`user_id` int NOT NULL COMMENT '用户id',
PRIMARY KEY (`blog_id`)
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8
CREATE TABLE `user` (
`user_id` int NOT NULL AUTO_INCREMENT COMMENT '用户唯一id--主键',
`user_name` varchar(30) NOT NULL COMMENT '用户名--不能重复',
`user_password` varchar(255) NOT NULL COMMENT '用户密码',
PRIMARY KEY (`user_id`),
KEY `name` (`user_name`)
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8
CREATE TABLE `discuss` (
`discuss_id` int NOT NULL AUTO_INCREMENT COMMENT '评论唯一id',
`discuss_body` varchar(255) NOT NULL COMMENT '评论内容',
`discuss_time` datetime NOT NULL COMMENT '评论时间',
`user_id` int NOT NULL COMMENT '用户id',
`blog_id` int NOT NULL COMMENT '博文id',
PRIMARY KEY (`discuss_id`)
) ENGINE=InnoDB AUTO_INCREMENT=61 DEFAULT CHARSET=utf8
id
表示查询中执行select子句或者操作表的顺序,id的值越大,代表优先级越高,越先执行
explain select discuss_body
from discuss
where blog_id = (
select blog_id from blog where user_id = (
select user_id from user where user_name = 'admin'));
三个表依次嵌套,发现最里层的子查询 id最大,最先执行。

select_type
表示 select 查询的类型,主要是用于区分各种复杂的查询,例如:普通查询、联合查询、子查询等。
- SIMPLE:表示最简单的 select 查询语句,在查询中不包含子查询或者交并差集等操作。
- PRIMARY:查询中最外层的SELECT(存在子查询的外层的表操作为PRIMARY)。
- SUBQUERY:子查询中首个SELECT。
- DERIVED:被驱动的SELECT子查询(子查询位于FROM子句)。
- UNION:在SELECT之后使用了UNION
table
查询的表名,并不一定是真实存在的表,有别名显示别名,也可能为临时表。当from子句中有子查询时,table列是<derivenN>的格式,表示当前查询依赖 id为N的查询,会先执行 id为N的查询。

partitions
查询时匹配到的分区信息,对于非分区表值为NULL,当查询的是分区表时,partitions显示分区表命中的分区情况。

type
查询使用了何种类型,它在 SQL优化中是一个非常重要的指标
访问效率:const > eq_ref > ref > range > index > ALL
system
当表仅有一行记录时(系统表),数据量很少,往往不需要进行磁盘IO,速度非常快。比如,Mysql系统表proxies_priv在Mysql服务启动时候已经加载在内存中,对这个表进行查询不需要进行磁盘 IO。

const
单表操作的时候,查询使用了主键或者唯一索引。

eq_ref
多表关联查询的时候,主键和唯一索引作为关联条件。如下图的sql,对于user表(外循环)的每一行,user_role表(内循环)只有一行满足join条件,只要查找到这行记录,就会跳出内循环,继续外循环的下一轮查询。

ref
查找条件列使用了索引而且不为主键和唯一索引。虽然使用了索引,但该索引列的值并不唯一,这样即使使用索引查找到了第一条数据,仍然不能停止,要在目标值附近进行小范围扫描。但它的好处是不需要扫全表,因为索引是有序的,即便有重复值,也是在一个非常小的范围内做扫描。

ref_or_null
类似 ref,会额外搜索包含NULL值的行
index_merge
使用了索引合并优化方法,查询使用了两个以上的索引。新建comment表,id为主键,value_id为非唯一索引,执行explain select content from comment where value_id = 1181000 and id > 1000;,执行结果显示查询同时使用了id和value_id索引,type列的值为index_merge。

range
有范围的索引扫描,相对于index的全索引扫描,它有范围限制,因此要优于index。像between、and、>、<、in和or都是范围索引扫描。

index
index包括select索引列,order by主键两种情况。
order by主键。这种情况会按照索引顺序全表扫描数据,拿到的数据是按照主键排好序的,不需要额外进行排序。

select索引列。type为index,而且extra字段为using index,也称这种情况为索引覆盖。所需要取的数据都在索引列,无需回表查询。

all
全表扫描,查询没有用到索引,性能最差。

possible_keys
此次查询中可能选用的索引。但这个索引并不定一会是最终查询数据时所被用到的索引。
key
此次查询中确切使用到的索引
ref
ref 列显示使用哪个列或常数与key一起从表中选择数据行。常见的值有const、func、NULL、具体字段名。当 key 列为 NULL,即不使用索引时。如果值是func,则使用的值是某个函数的结果。
以下SQL的执行计划ref为const,因为使用了组合索引(user_id, blog_id),where user_id = 13中13为常量
mysql> explain select blog_id from user_like where user_id = 13;
+----+-------------+-----------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | user_like | NULL | ref | ul1,ul2 | ul1 | 4 | const | 2 | 100.00 | Using index |
+----+-------------+-----------+------------+------+---------------+------+---------+-------+------+----------+-------------+
而下面这个SQL的执行计划ref值为NULL,因为key为NULL,查询没有用到索引。
mysql> explain select user_id from user_like where status = 1;
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | user_like | NULL | ALL | NULL | NULL | NULL | NULL | 6 | 16.67 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
rows
估算要找到所需的记录,需要读取的行数。评估SQL 性能的一个比较重要的数据,mysql需要扫描的行数,很直观的显示 SQL 性能的好坏,一般情况下 rows 值越小越好
filtered
存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例
extra
表示额外的信息说明。为了方便测试,这里新建两张表。
CREATE TABLE `t_order` (
`id` int NOT NULL AUTO_INCREMENT,
`user_id` int DEFAULT NULL,
`order_id` int DEFAULT NULL,
`order_status` tinyint DEFAULT NULL,
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_userid_order_id_createdate` (`user_id`,`order_id`,`create_date`)
) ENGINE=InnoDB AUTO_INCREMENT=99 DEFAULT CHARSET=utf8
CREATE TABLE `t_orderdetail` (
`id` int NOT NULL AUTO_INCREMENT,
`order_id` int DEFAULT NULL,
`product_name` varchar(100) DEFAULT NULL,
`cnt` int DEFAULT NULL,
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_orderid_productname` (`order_id`,`product_name`)
) ENGINE=InnoDB AUTO_INCREMENT=152 DEFAULT CHARSET=utf8
using where
表示在查询过程中使用了WHERE条件进行数据过滤。当一 个查询中包含WHERE条件时,MySQL会根据该条件过滤出满足条件的数据行,然后再进行后续的操作。这个过程 就被称为"Using Where”。
表示查询的列未被索引覆盖,,且where筛选条件是索引列前导列的一个范围,或者是索引列的非前导列,或者是非索引列。对存储引擎返回的结果进行过滤(Post-filter,后过滤),一般发生在MySQL服务器,而不是存储引擎层,因此需要回表查询数据。

using index
查询的列被索引覆盖,并且where筛选条件符合最左前缀原则,通过索引查找就能直接找到符合条件的数据,不需要回表查询数据。

Using where&Using index
查询的列被索引覆盖,但无法通过索引查找找到符合条件的数据,不过可以通过索引扫描找到符合条件的数据,也不需要回表查询数据。
包括两种情况(组合索引为(user_id, orde)):
where筛选条件不符合最左前缀原则

where筛选条件是索引列前导列的一个范围

null
查询的列未被索引覆盖,并且where筛选条件是索引的前导列,也就是用到了索引,但是部分字段未被索引覆盖,必须回表查询这些字段,Extra中为NULL。

using index condition
索引下推(index condition pushdown,ICP),先使用where条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行。
对于联合索引(a, b),在执行 select * from table where a > 1 and b = 2 语句的时候,只有 a 字段能用到索引,那在联合索引的 B+Tree 找到第一个满足条件的主键值(ID 为 2)后,还需要判断其他条件是否满足(看 b 是否等于 2),那是在联合索引里判断?还是回主键索引去判断呢?
MySQL 5.6 引入的索引下推优化(index condition pushdown), 可以在联合索引遍历过程中,对联合索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
不使用ICP的情况(set optimizer_switch='index_condition_pushdown=off'),如下图,在步骤4中,没有使用where条件过滤索引:

使用ICP的情况(set optimizer_switch='index_condition_pushdown=on'):

下面的例子使用了ICP:
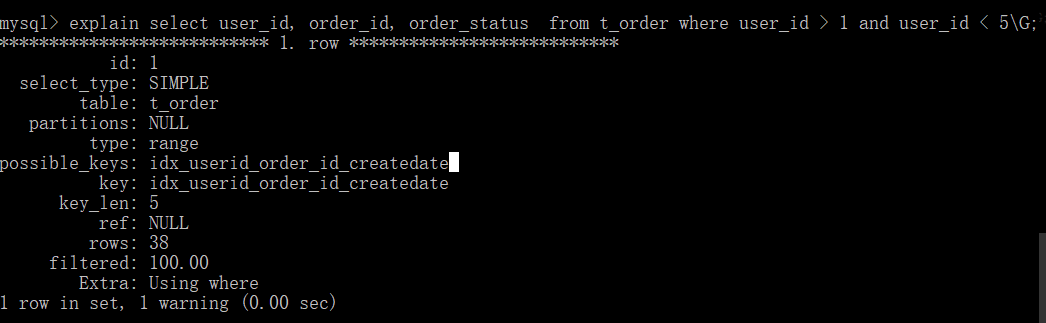
explain select user_id, order_id, order_status from t_order where user_id > 1 and user_id < 5\G;

关掉ICP之后(set optimizer_switch='index_condition_pushdown=off'),可以看到extra列为using where,不会使用索引下推。
using temporary
使用了临时表保存中间结果,常见于 order by 和 group by 中。典型的,当group by和order by同时存在,且作用于不同的字段时,就会建立临时表,以便计算出最终的结果集
filesort
文件排序。表示无法利用索引完成排序操作,以下情况会导致filesort:
- order by 的字段不是索引字段
- select 查询字段不全是索引字段
- select 查询字段都是索引字段,但是 order by 字段和索引字段的顺序不一致

using join buffer
Block Nested Loop,需要进行嵌套循环计算。两个关联表join,关联字段均未建立索引,就会出现这种情况。比如内层和外层的type均为ALL,rows均为4,需要循环进行4*4次计算。常见的优化方案是,在关联字段上添加索引,避免每次嵌套循环计算。
面试题专栏
Java面试题专栏已上线,欢迎访问。
- 如果你不知道简历怎么写,简历项目不知道怎么包装;
- 如果简历中有些内容你不知道该不该写上去;
- 如果有些综合性问题你不知道怎么答;
那么可以私信我,我会尽我所能帮助你。
Mysql篇-语句执行计划详解(explain)的更多相关文章
- [转]MySQL查询语句执行过程详解
Mysql查询语句执行原理 数据库查询语句如何执行?语法分析:首先进行语法分析,对使用sql表示的查询进行语法分析,生成查询语法分析树.语义检查:检查sql中所涉及的对象以及是否在数据库中存在,用户是 ...
- SQL执行计划详解explain
1.使用explain语句去查看分析结果 如explain select * from test1 where id=1;会出现:id selecttype table type possible_k ...
- mysql的sql执行计划详解(非常有用)
以前没有怎么了解mysql执行计划,以及sql 优化方面,今天算学习了. https://blog.csdn.net/heng_yan/article/details/78324176 https:/ ...
- mysql的sql执行计划详解
实际项目开发中,由于我们不知道实际查询的时候数据库里发生了什么事情,数据库软件是怎样扫描表.怎样使用索引的,因此,我们能感知到的就只有 sql语句运行的时间,在数据规模不大时,查询是瞬间的,因此,在写 ...
- MySQL性能分析, mysql explain执行计划详解
MySQL性能分析 MySQL性能分析及explain用法的知识是本文我们主要要介绍的内容,接下来就让我们通过一些实际的例子来介绍这一过程,希望能够对您有所帮助. 1.使用explain语句去查看分析 ...
- MySQL 执行计划详解
我们经常使用 MySQL 的执行计划来查看 SQL 语句的执行效率,接下来分析执行计划的各个显示内容. EXPLAIN SELECT * FROM users WHERE id IN (SELECT ...
- MySQL 语句执行过程详解
MySQL 原理篇 MySQL 索引机制 MySQL 体系结构及存储引擎 MySQL 语句执行过程详解 MySQL 执行计划详解 MySQL InnoDB 缓冲池 MySQL InnoDB 事务 My ...
- mysql中SQL执行过程详解与用于预处理语句的SQL语法
mysql中SQL执行过程详解 客户端发送一条查询给服务器: 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果.否则进入下一阶段. 服务器段进行SQL解析.预处理,在优化器生成对应的 ...
- Oracle执行计划详解
Oracle执行计划详解 --- 作者:TTT BLOG 本文地址:http://blog.chinaunix.net/u3/107265/showart_2192657.html --- 简介: ...
- [转]Oracle执行计划详解
Oracle执行计划详解 --- 作者:TTT BLOG 本文地址:http://blog.chinaunix.net/u3/107265/showart_2192657.html --- 简介: ...
随机推荐
- udp协议及包格式
UDP协议也是互联网基础协议之一.它和TCP一样同属于传输层当中的一个协议. 不过UDP协议是一个面向无连接的协议(TCP是向面连接的协议).一个UDP连接的建立,不必象TCP协议那样需要服务器端侦听 ...
- installer 命令介绍
installer 命令是 macOS 系统中用于在命令行界面下安装 .pkg 格式的安装包的工具.这个命令特别有用于自动化安装软件或者在没有图形用户界面的情况下进行软件安装,比如在远程管理或者终端会 ...
- 【GaussDB】应用报错 socket is not closed; Urgent packet sent to backend successfully; An I/O error occured while sending to the backend.detail:EOF Exception;
数据库原理差异 会话空闲时间超过sesseion_time后,数据库主动断开,客户端再发起请求,就会报此类错误: 当一个会话连接长时间没有执行SQL或者活动时,会将该会话释放,可以释放缓存避免出现例如 ...
- C++ lambda 引用捕获临时对象引发 core 的案例
今天复习前几年在项目过程中积累的各类技术案例,有一个小的 coredump 案例,当时小组里几位较资深的同事都没看出来,后面是我周末查了两三个小时解决掉的,今天再做一次系统的总结,给出一个复现的案例代 ...
- wxpython开发gui界面基础
wxpython 开发gui 基础知识 一 .前言 记录使用wxpython开发gui工具吧.gui界面主要就是先布局,每个模块都是一个对象. 二.基础知识 import wx class MyFra ...
- 搭建ipv6并发代理池
声明 本文章中所有内容仅供学习交流,抓包内容.敏感网址.数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除! 学习目标 ounter(l ...
- DECL: 针对噪声时间序列的去噪感知对比学习《Denoising-Aware Contrastive Learning for Noisy Time Series》(时间序列、对比学习、去噪)
今天是2024年9月12日,组会摸鱼,很久没看论文了,在摸鱼看代码,最近IJCAI 2024出来了,找了几篇论文看,首先这是第一篇. 论文:Denoising-Aware Contrastive Le ...
- HTML – script async defer
参考 Youtube – #3 JavaScript Loading Strategies (async and defer) | JavaScript Full Tutorial no async ...
- CSS & JS Effect – Image Overlay
介绍 一张背景图, 一行写字, 一层黑影 (Image Overlay), 如果没有做黑影, 字的颜色容易和图片撞, contrast 就会很烂. HTML 结构 <div class=&quo ...
- Nodejs+npm详细安装
Nodejs详细安装步骤1.去官网下载nodejs,下载地址:https://nodejs.org/en/download/ 根据自己要求下载,我这里下载的是windows installer的. 2 ...