Qwen3技术报告
原文: https://mp.weixin.qq.com/s/3RXdXT8hzlsMp_Uk_BvpfQ
全文摘要
本文介绍了最新的 Qwen 模型家族——Qwen3,它是一个大型语言模型系列,旨在提高性能、效率和多语言能力。该系列包括密集架构和混合专家(MoE)架构的模型,参数规模从 0.6 到 235 亿不等。Qwen3 的创新之处在于将思考模式(用于复杂、多步推理)和非思考模式(用于快速、基于上下文的响应)整合到一个统一框架中,消除了切换不同模型的需求,并可以根据用户查询或聊天模板动态切换模式。此外,Qwen3 引入了思考预算机制,允许在推断过程中适应性地分配计算资源,从而根据任务复杂度平衡延迟和性能。通过利用旗舰模型的知识,作者显著减少了构建小规模模型所需的计算资源,同时确保它们具有高度竞争力的表现。实验结果表明,Qwen3 在各种基准测试中实现了最先进的结果,包括代码生成、数学推理、代理任务等任务,在与更大规模的 MoE 模型和专有模型的竞争中表现出色。与前一代 Qwen2.5 相比,Qwen3 扩展了对 119 种语言和方言的支持,提高了跨语言理解和生成的能力,增强了全球可访问性。为了促进可重复性和社区驱动的研究和发展,所有 Qwen3 模型都以 Apache 2.0 许可证的形式公开可用。
论文地址:https://arxiv.org/abs/2505.09388
github: https://github.com/QwenLM/Qwen3
huggingface: https://huggingface.co/Qwen
论文方法
方法描述
本文提出了一种名为“Qwen3”的新型预训练模型,包括6个密集模型和2个MoE模型。这些模型使用了Grouped Query Attention、SwiGLU、Rotary Positional Embeddings以及RMSNorm等技术,并引入了QK-Norm来确保稳定的训练过程。此外,该模型采用了与Qwen2.5相似的基本架构,但在MoE模型中进行了创新,如实现细粒度专家分割和排除共享专家等。
Qwen3模型还利用了Qwen的分词器来进行文本识别和处理。在数据集方面,该模型收集了大量的高质量数据,覆盖了多种语言和领域,以提高模型的语言能力和跨语言能力。同时,通过多维度的数据标注系统,优化了数据混合的效果。
在预训练阶段,Qwen3模型采用了三个阶段的训练方式:第一阶段是通用阶段(S1),在此阶段中,所有模型都基于超过30万亿个标记的语料库进行训练;第二阶段是推理阶段(S2),在此阶段中,增加了STEM、编码、推理和合成数据的比例,并使用更高的质量标记进行进一步的训练;第三阶段是长序列阶段,在此阶段中,使用数百亿个标记的高质量长序列语料库扩展模型的上下文长度。最后,该模型根据前两个阶段的结果预测出每个模型的最佳学习率和批量大小策略。
方法改进
相比于之前的模型,Qwen3模型在多个方面进行了改进:
- 扩大了训练数据的规模和多样性,提高了模型的语言能力和跨语言能力。
- 引入了新的技术和算法,如QK-Norm、YARN和Dual Chunk Attention,提高了模型的性能。
- 实现了细粒度专家分割和排除共享专家等创新设计,提高了模型的效率和稳定性。
- 利用了多维度的数据标注系统,优化了数据混合的效果。
解决的问题
Qwen3模型解决了以下问题:
- 提高了模型的语言能力和跨语言能力,使其能够更好地应对多样化的自然语言处理任务。
- 改进了模型的性能,使其具有更好的推理能力和稳定性。
- 提供了一个有效的数据混合方案,使模型能够更有效地利用大规模数据集。
论文实验
本文主要介绍了针对自然语言处理领域的大型预训练模型的系列实验,并对其进行了全面的评估和比较。作者使用了多种指标来衡量模型在不同任务上的表现,包括通用知识问答、数学计算、科学知识、编程等多领域。具体实验内容如下:
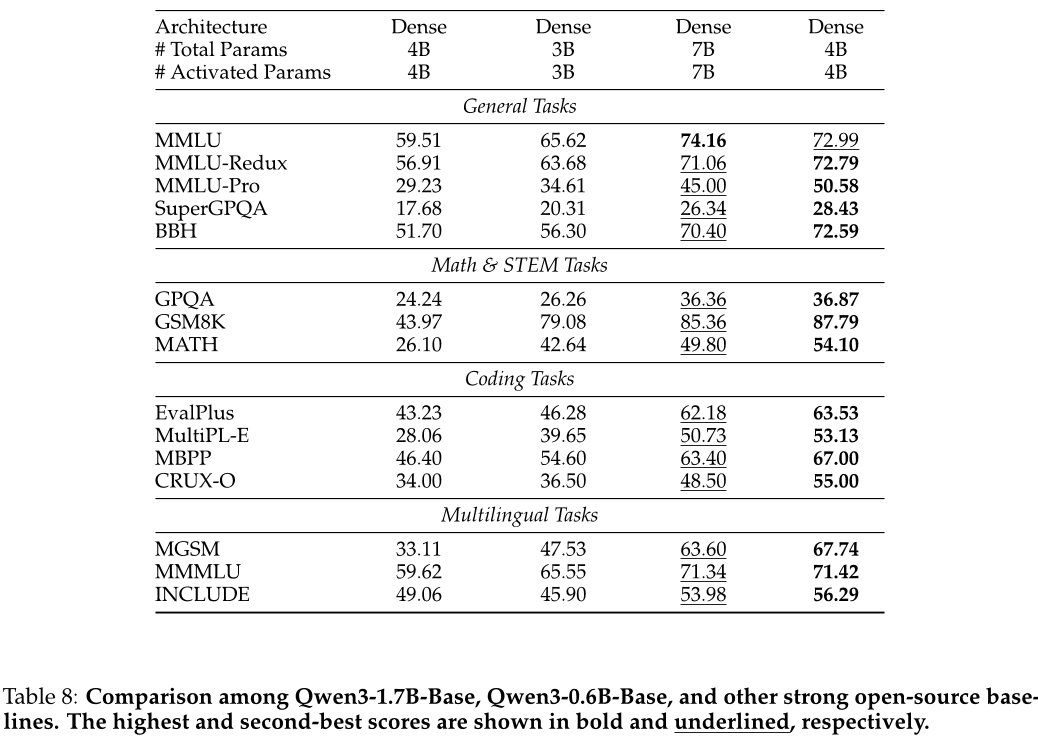
- 性能评估:对大型预训练模型(如Qwen3系列)与同类开源模型(如DeepSeek-V3 Base、Gemma-3、Llama-4-Maverick等)进行了性能评估,比较它们在多个基准测试数据集上的表现。结果显示,Qwen3系列模型在大多数任务上都表现出色,特别是在科学知识、编程等领域具有显著优势。
- 模型大小评估:将Qwen3系列模型与其他领先的开源模型(如Llama-4-Maverick、Qwen2.5-72B-Base等)进行了模型大小的比较。结果表明,Qwen3系列模型不仅在性能上有优势,而且相对于其他模型而言,其参数量和激活参数量都更少,具有更高的效率。
- 跨语言能力评估:通过MGLUE多语言评估数据集,对Qwen3系列模型的跨语言能力进行了评估。结果显示,Qwen3系列模型在不同语言的任务上都有较好的表现,证明了其在多语言环境下的应用潜力。
综上所述,本文通过对Qwen3系列模型进行全面的评估和比较,展示了其在各个任务和指标上的优越性能,为自然语言处理领域的研究提供了有力的支持。


论文总结
文章优点
该论文介绍了一种名为Qwen3的预训练模型,其特点是具有思考模式和非思考模式,并且可以根据任务需要动态管理使用的标记数量。该模型在包含36万亿个标记的大型数据集上进行了预训练,能够理解和生成119种语言和方言的文本。通过一系列全面的评估,Qwen3在标准基准测试中表现出色,包括代码生成、数学推理、代理等任务。 此外,该论文还介绍了作者团队的研究计划,包括提高模型架构和训练方法的有效压缩、扩展到非常长的上下文等方面的工作。这些工作将有助于构建更强大的代理系统,以应对复杂任务的需求。
方法创新点
该论文的主要贡献是提出了一种新的预训练模型Qwen3,它具有思考模式和非思考模式,可以动态管理使用的标记数量。这种设计使得该模型能够在处理不同类型的自然语言任务时更加灵活和高效。此外,该论文还提到了一些研究计划,如有效压缩、扩展到非常长的上下文等方面的工作,这些工作有望进一步提高模型的性能和应用范围。
未来展望
该论文的未来发展重点是在以下几个方面:首先,继续扩大数据集的质量和多样性,以进一步提高模型的性能;其次,改进模型架构和训练方法,以实现有效的压缩和扩展到非常长的上下文;最后,增加计算资源,特别是在强化学习方面的投入,以便构建更加强大的代理系统,以应对复杂任务的需求。这些努力将有助于推动自然语言处理技术的发展和应用。
Qwen3技术报告的更多相关文章
- rsync技术报告(翻译)
本篇为rsync官方推荐技术报告rsync technical report的翻译,主要内容是Rsync的算法原理以及rsync实现这些原理的方法.翻译过程中,在某些不易理解的地方加上了译者本人的注释 ...
- 技术报告:APT组织Wekby利用DNS请求作为C&C设施,攻击美国秘密机构
技术报告:APT组织Wekby利用DNS请求作为C&C设施,攻击美国秘密机构 最近几周Paloalto Networks的研究人员注意到,APT组织Wekby对美国的部分秘密机构展开了一次攻击 ...
- 商汤开源的mmdetection技术报告
目录 1. 简介 2. 支持的算法 3. 框架与架构 6. 相关链接 前言:让我惊艳的几个库: ultralytics的yolov3,在一众yolov3的pytorch版本实现算法中脱颖而出,收到开发 ...
- rsync(四)技术报告
1.1 摘要 本报告介绍了一种将一台机器上的文件更新到和另一台机器上的文件保持一致的算法.我们假定两台机器之间通过低带宽.高延迟的双向链路进行通信.该算法计算出源文件中和目标文件中一致的部分(译者注: ...
- 基于Web的实验室管理系统技术简要报告
基于Web的实验室管理系统技术简要报告 Copyright 朱向洋 Sunsea ALL Right Reserved 一.网站架构 该网站使用C#语言,利用SQL Server2008数据库,采用V ...
- 技术领导(Technical Leader)画像
程序员都讨厌被管理,而乐于被领导.管理的角色由PM(project manager)扮演,具体来说,PM负责提需求.改改改.大多数情况,PM是不懂技术的,这也是程序员觉得PM难以沟通的原因.而后者由技 ...
- 本学期Windows编程微型技术博客上线!
将两篇报告生成超链接模式方便阅读,以下为链接: https://files.cnblogs.com/files/Kitty-/Windows编程微型技术报告一.pdf https://files.cn ...
- C++ 风格与技术 FAQ(中文版)
Bjarne Stroustrup 的 C++ 风格与技术 FAQ(中文版) 原作:Bjarne Stroustrup 翻译:Antigloss 译者的话:尽管我已非常用心,力求完美,但受水平所 ...
- 大会聚焦 | 开源技术盛会LinuxCon首次来到中国,大咖齐聚关注业界动态
2017年6月19-20日,开源技术盛会LinuxCon + ContainerCon + CloudOpen(LC3)首次在中国举行.两天议程满满,包括 17 个主旨演讲.8 个分会场的 88 场技 ...
- PayPal高级工程总监:读完这100篇论文 就能成大数据高手(附论文下载)
100 open source Big Data architecture papers for data professionals. 读完这100篇论文 就能成大数据高手 作者 白宁超 2016年 ...
随机推荐
- linux 网络编程 新技能
{} 配对问题.这个在多个json文件中找到配对的{} 括号实在不容易. 使用 % 号吧少年. gg 跳到首部 GG 跳转到尾部. XXG 可以跳转到多少多少行. gcc -E 执行预处理的结果.变量 ...
- java 自定义窗口
简介 简单 java 核心编程 code /* * @Author: your name * @Date: 2020-11-08 14:44:58 * @LastEditTime: 2020-11-0 ...
- API开发平台,专注API高效开发平台
为什么要选择RestCloud API开发平台? API开发平台是RestCloud团队研发的基于微服务架构的专注API高效开发的专业化平台,与传统的API开发模式相比,具有更轻量级,开发速度更快,功 ...
- ETLCloud中多并行分支运行的设计技巧
在大数据处理领域,ETL(Extract, Transform, Load)流程是至关重要的一环,它涉及数据的提取.转换和加载,以确保数据的质量和可用性.而在ETL流程中,多并行分支的运行设计是一项关 ...
- ETL中如何运用好MQ消息集成
一.ETL的主要作用 ETL(Extract, Transform, Load)是数据仓库中的关键环节,其主要作用是将数据从源系统中抽取出来,经过转换和清洗后加载到数据仓库中.具体而言: Extrac ...
- ICEE-Power-ATX电源:功能、大体电路原理、各接口定义、启动方法、电源特点
主板工作原理: ATX(Advanced Technology Extended)是一种由Intel在1995年公布的PC主板结构规范. 线材(PC电源上使用)直径的标识: 线材以AWG(Americ ...
- Linux下设置MySQL的环境变量:-九五小庞
Linux下设置MySQL的环境变量: 在/etc/profile中添加: export PATH=$PATH:/usr/local/MySQL/bin 重新加载配置文件 source /etc/pr ...
- 如何在FastAPI中玩转GraphQL联邦架构,让数据源手拉手跳探戈?
扫描二维码关注或者微信搜一搜:编程智域 前端至全栈交流与成长 发现1000+提升效率与开发的AI工具和实用程序:https://tools.cmdragon.cn/ 使用FastAPI实现GraphQ ...
- js控制去掉字符串头尾空格
JS去掉首尾空格 简单方法大全(原生正则jquery) var str= ' http://www.baidu.com/ '; //去除首尾空格 str.replace(/(^\s*)|(\s*$)/ ...
- MyEMS能源管理系统后台配置-组合设备管理
MyEMS开源能源管理系统适用于建筑.工厂.商场.医院.园区的电.水.气等能源数据采集.分析.报表,还有光伏.储能.充电桩.微电网.设备控制.故障诊断.工单管理.人工智能优化等可选功能. 本文介绍My ...