探秘Transformer系列之(12)--- 多头自注意力
探秘Transformer系列之(12)--- 多头自注意力
0x00 概述
MHSA(多头自注意力) 是 Transformer 模型的核心模块。Transformer本质上是一个通用的可微计算机,集多种优秀特性于一身。
- Transformer 类似消息传递的架构具有通用性(即完整性)和强大功能(即效率),能够涵盖许多现实世界的算法,因此Transformer具备非常强大的表现力(在前向传播中)。
- 通过反向传播和梯度下降,Transformer可以持续不断的优化。
- 因为Transformer的计算图是浅而宽的,而且自注意力机制让我们在处理序列数据时,能够并行计算序列中的每个元素,所以Transformer能够更好地映射到我们的高并行计算架构(比如GPU)来进行高效计算。
- 多头注意力机制通过并行运行多个自注意力层并综合结果,能同时捕捉输入序列在不同子空间的信息,增强了模型的表达能力。这种特性使得Transformer可以更好地理解数据中的复杂模式和语义信息,在自然语言处理、计算机视觉等多领域都能出色应用,泛化能力强。
多头注意力机制就是蛋糕上的樱桃。多头注意力机制的巧妙之处在于,它能够通过并行运行多个具有独特视角的注意力头来同时处理数据,使得模型能够从多个角度分析输入序列,捕捉丰富的特征和依赖关系。类似于一组专家分析复杂问题的各个方面。或者像同时有多个视角在看同一个东西,每个视角都能看到一些不同的细节。下图形象化的解释了多头注意力运行机制,Query、Key和Value 被分为不同的Head,并在每个Head中独立计算自注意力。
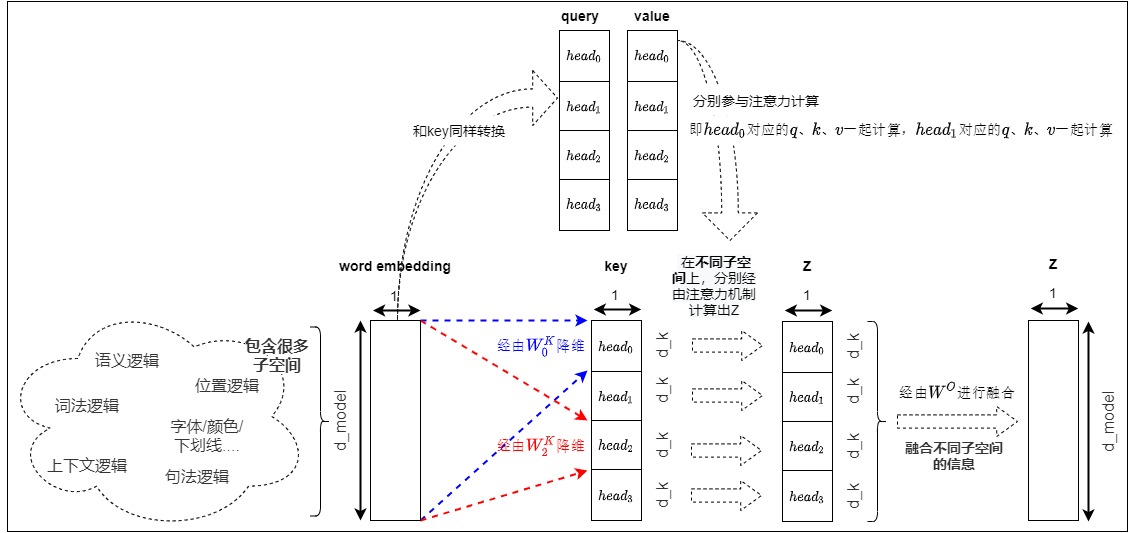
0x01 研究背景
1.1 问题
迄今为止,注意力机制看起来很美好,但是也暴露出来了一些缺陷:
比如,模型在编码时,容易会过度的将注意力集中于当前的位置,而忽略了其它位置的信息,从而错过某些重要的依赖关系或特征。用程序化的语言来说,因为Q、K、V都来自输入X,在计算\(QK^T\)时,模型容易关注到自身的位置上,即\(QK^T\)对角线上的激活值会明显比较大,这样会削弱模型关注其它高价值位置上的能力,限制了模型的理解和表达能力。
再比如,注意力机制是使用Q去找相关的K,但是”相关“可以有不同形式和定义,比如一项事物往往有多个方面,应该综合利用各方面的信息/特征,从多个角度进行衡量。比如下面句子中就有字体大小,背景颜色,字体颜色,加粗/下划线/斜线这几个不同的强调维度,需要多方考虑。

另外,人类注意力机制本身就是天然可以同时处理多个方面的信息的。设想你在一个拥挤的公交车上看书,你的大脑能自动关注到书的内容,同时也可以留意周围的环境声,譬如有人叫你的名字或是公交车到站播报声。
而迄今为止,在我们的学习历程中,当前的Transformer注意力机制只是注重事物的单独方面,而非注意多个方面。
1.2 根源
Embedding 才是多头注意力背后的真正内在成因。Embedding 是人类概念的映射,或者说是表达人类概念的途径或者方法。人类的概念是一个及其复杂的系统,因为概念需要有足够的内部复杂度才能应对外部世界的复杂度。比如对于一个词来说,其就有语义逻辑、语法逻辑、上下文逻辑、在全句中位置逻辑、分类逻辑等多种维度。而且,词与词之间的关系还不仅仅限于语义上的分类所导致的定位远近这么简单。一个词所代表的事物与其他词所代表的事物之间能产生内在联系的往往有成百上千上万种之多。
或者说,概念是被配置为能够跨任务工作的向量,是去除非本质信息,保留最确定性的结果。在这种基础上,存储在长期记忆中的单个概念向量可以通过不同的函数进行投影,以用于不同特定领域的任务。每个任务其实可以认为是一个独立的向量空间。比如对于上面的例子,字体和颜色就是两个不同的子空间(低维空间)。
而目前注意力只注重单独某个向量空间,势必导致虽然最终生成的向量可以在该空间上有效将人类概念进行映射,但是无法有效反映外部丰富的世界。因此,我们需要一种可以允许模型在不同的子空间中进行信息选择的机制。
1.3 解决方案
多头注意力就是研究人员给出的解决方案。多头注意力可以理解为高维向量被拆分或者转化为H份低维向量,并在H个低维空间里求解各自的注意力。这样模型就可以从不同角度来分析和理解输入信息,最终输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力。Transformer论文中对于多注意力机制的论述如下。
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
多头注意力机制基于自注意力机制基础上进行扩展。在传统的自注意力机制中,你只能使用一组查询(Q)、键(K)和值(V)来计算注意力权重。但是,在多头注意力机制中,你可以使用多组不同的Q、K和V来进行计算。每个注意力头都有自己独立的一组Q、K和V,多组Q、K和V通过独立的线性变换来生成。
不同的Q去查找不同方面的相关性,比如某个Q去捕捉语法依赖,另一个Q去捕捉语义依赖,这样每个注意力头可以关注文本中不同的方面和特征,才能不仅抓住主旨,同时也能理解各个词汇间的关联,进而从多角度捕捉上下文和微妙之处,并行地学习多组自注意力权重。最后,多个注意力头的结果会被拼接在一起,并通过另一个线性变换进行整合,得到最终的输出。多头注意力机制具体如下图所示。其中,D 表示 hidden size,H 表示 Head 个数,L 表示当前是在序列的第 L 个 Token。

针对上方句子的例子,我们使用多头注意力就是同时关注字体和颜色等多方面信息,每个注意力头关注不同的表示子空间,这样即可以有效定位网页中强调的内容,也可以灵活选择文字中的各种关系和特征,从而提取更丰富的信息。模型最终的“注意力”实际上是来自不同“表示子空间”的注意力的综合,均衡单一注意力机制可能产生的偏差。
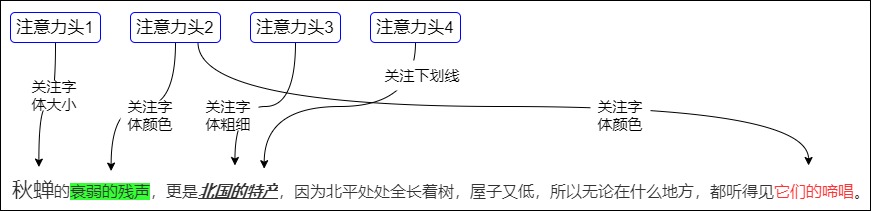
有两个比较确切的例子,可以让大家对多头自注意力有直观的感受。
例子1是从专家的专家角度来看。一个团队合作完成一个软件项目,每个团队成员负责自己擅长的领域。产品经理负责整体项目规划和需求分析;项目经理负责项目把控;前端开发工程师负责与用户界面相关的工作;后端工程师负责服务器逻辑和数据库管理;测试工程师负责项目质量保证。每个团队成员用自己的专业能力独立的对项目付出不同的贡献,最终将各自的成果整合在一起,形成一个完整的软件产品。
例子2更倾向于从合作的角度来看。在橄榄球领域内有一种说法,一场比赛要看四遍,第一遍从总体上粗略看,第二遍从进攻球员角度看,第三遍从防守球员角度看,第四遍则综合之前的理解再总体看一遍。但是这样要看四遍。不如让几个人一起来看一遍比赛,观看过程中,有人负责从从进攻球员角度看,有人负责从防守球员角度看,有人负责总体把握,有人负责看重点球员,有人看教练部署,最终有人将不同的意见和见解整合起来,形成对比赛的完整理解。
0x02 原理
2.1 架构图
多头注意力机制是自注意力机制的变体,多头注意力的架构及公式如下图,h 个 Scale Dot-Product Attention(左)并行组合为 Multi-Head Attention(右)。每个Scaled Dot-Product Attention 结构对输入上下文特征单独做了 一次 上下文信息融合。在此基础之上,我们把多个这样的特征融合操作并联起来,得到多个独立的输出特征张量,再把这些张量联接(concatenate)起来。
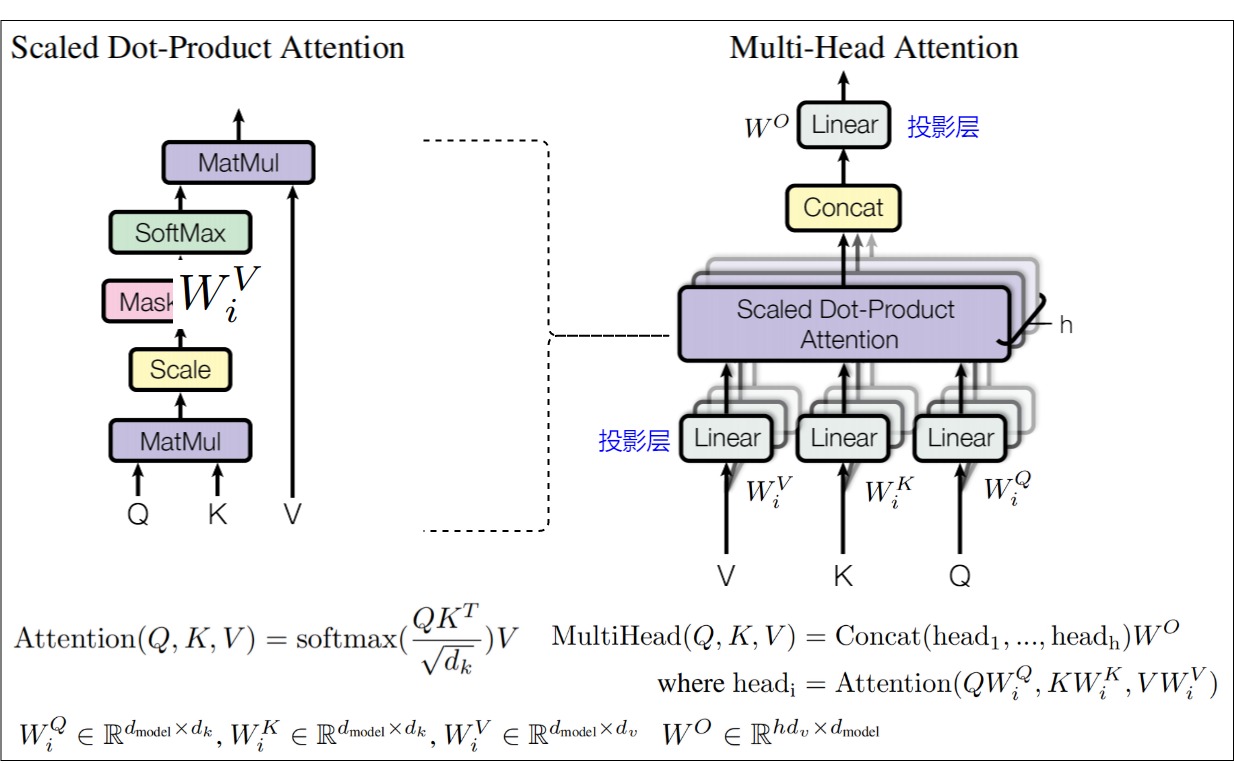
上图中,\(W^Q\),\(W^K\),\(W^V\) 这三个矩阵列数可以不同,但是行数都是\(d_{model}\)。\(d_{model}\)为多头注意力机制模块输入与输出张量的通道维度,h为head个数。论文中h=8,因此\(d_k=d_v=d_{model}/h=64\),\(d_{model}=512\)。
偏置
\(W^Q\),\(W^K\),\(W^V\)这三个投影层以及最后的投影层\(W^O\)(Z * Output_weights)可以选择添加或者不添加偏置。
举例:根据LLaMA3源码来看,其没有加入bias。
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
model_parallel_size = fs_init.get_model_parallel_world_size()
self.n_local_heads = args.n_heads // model_parallel_size
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False, # 没有偏置
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False, # 没有偏置
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False, # 没有偏置
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False, # 没有偏置
input_is_parallel=True,
init_method=lambda x: x,
)
另外,PaLM: Scaling Language Modeling with Pathways 这篇论文里提到,如果对全连接层以及 layer norm 不加偏置项,可以提高训练的稳定性。
No Biases – No biases were used in any of the dense kernels or layer norms. We found this to result in increased training stability for large models.
权重矩阵
如果是Scaled Dot-Product Attention,即单头注意力机制,其要学的参数其实就是三个矩阵 \(W^Q,W^K,W^V\),这个参数量往往不多,且容易是稀疏矩阵。当语义逐渐复杂后,容易因为参数量达到容量上限而造成模型性能不足。
多头就意味着需要把词嵌入分成若干的块,即每个字都转换为若干512/H维度的信息。然后我们将这些块分配到不同的头上,每个头将独立地进行注意力计算。对于每个头得到的Q、K和V,我们都需要分别进行线性变换。计算 Q、K 和 V 的过程还是一样,不过现在执行变换的权重矩阵从一组\((W^Q, W^K, W^V)\)变成了多组:\((W_0^Q, W_0^K, W_0^V)\),\((W_1^Q, W_1^K, W_1^V)\),....\((W_h^Q, W_h^K, W_h^V)\)。通过这些权重矩阵的转换,我们就可以让多组关注不同的上下文的 Q、K 和 V。
多头注意力机制通过更多的权重矩阵来增加了模型的容量,使得模型能够学习到更复杂的表示。在多头注意力中,每个注意力头只关注输入序列中的一个独立子空间,不同头(角度)有不同的关注点,综合多个头可以让模型就能够更全面地理解输入数据。或者这么理解:不同的注意力头可以学习到序列中不同位置之间的不同依赖关系,组合多头注意力可以捕捉多种依赖关系,提供更丰富、更强大的表示。从而使得多头的Q、K、V权重可以在参数量相同的情况提升模型的表达能力。
这些自注意力“头”的关注点并非预设,而是从随机开始,通过处理大量数据并自我学习,自然而然地识别出各种语言特征。它们学习到的一些特征我们能够理解,有些则更加难以捉摸。
\(W^O\)矩阵
上面的操作相当于把一个进程拆分成8个独立的子进程进行操作,每个进程处理原始Embedding的1/n。最终每个进程得到的向量长度是原来embedding长度的1/n。怎样把不同注意力头的输出合起来呢?系统会在d这个维度,通过 Concat 方式把8个子进程的结果串联起来,直接拼接成一个长向量。此时 Concat 后的矩阵实际上并不是有机地融合 8 个“小Embedding”,而只是简单地做了矩阵的前后链接 Concat。这就带来了几个问题:
多个头直接拼接的操作, 相当于默认了每个头或者说每个子空间的重要性是一样的, 在每个子空间里面学习到的相似性的重要度是一样的,即这些头的权重是一样的。然而,各个头的权重事实上肯定不同,如何有机融合?或者说,如何调整不同头之间的权重比例?
自注意力机制模块会接到全连接网络,FFN需要的输入是一个矩阵而不是多个矩阵。而且因为有残差连接的存在,多头注意力机制的输入和输出的维度应该是一样的。
综上,我们需要一个压缩、转换和融合的手段,把 8 个小的语义逻辑子空间有机地整合成一个总体的 Embedding,而且需要把多头注意力的输出恢复为原 Embedding 的维度大小,即512维的向量长度。但是有机融合是个复杂的情况,只凭借人力难以做好。因此研发人员提出来把融合直接做成可学习、可训练的。即设定一个可学习参数,如果它觉得某个头重要, 那干脆让那个头对应的可学习参数大些,输出的矩阵大些,这就类似于增加了对应头的权重。
最终就得到是\(W^O\)方案。利用\(W^O\) 对多头的输出进行压缩和融合来提升特征表征和泛化能力。\(W^{O}\)类似 \(W^{Q}\),\(W^{K}\),$W^{V} \(,也是在模型训练阶段一同训练出来的权重矩阵(右上角 O 意为输出 Output 的意思)。\)W^O$操作前后,维度没有变化。即最终输出的结果和输入的词嵌入形状一样。
2.2 设计思路
我们来反推或者猜测一下Transformer作者的设计思路大致为:以分治+融合的模式对数据进行加工。分治是对数据进行有差别的对待,而融合是做数据融合。
子空间&分治
Embedding
前面提到,Embedding 才是多头背后的真正内在成因。那么让我们再看看这个 Embedding 中的语义逻辑子空间。我们假设有8个注意力头,每个注意头都有自己的可学习权重矩阵\(W_i^Q\), \(W_i^K\)和\(W_i^V\)。$W^{Q} \(,\)W{K}$,$W$ 均是 Transformer 大模型在训练阶段时,通过海量的对照语料训练集训练出来的,他们是专门用来拆解每个 token 在 Embedding 空间中的逻辑细分子空间用的。
通过这些权重矩阵可以把原始高维向量分解成 8 个细分的 Embedding 向量,每个向量对应到一个细分语义逻辑子空间(语义逻辑、语法逻辑、上下文逻辑、分类逻辑等)。实际上便是把 Attention 机制分割在 Embedding 中的不同细分逻辑子空间中来运作了。每个注意力头互相独立的关注到不同的子空间上下文,同时考虑诸多问题,从而获得更丰富的特征信息。
特征提取
Transformer的多头注意力应该也借鉴了CNN中同一卷积层内使用多个卷积核的思想。CNN中使用了不同的卷积核来关注图像中的不同特征,学习不同的信息。然后CNN中逐通道卷积最后沿着通道求和做特征融合。
Transformer的角色定位是特征抽取器或者万能函数逼近器。我们期望捕捉更多的模式,从而利于下游多样的任务微调时,一旦这类模式有用,就可以激活出来让下游任务可以学习到。所以Transformer使用多头对一个向量切分不同的维度来捕捉不同的模式,让模型可能从多种维度去理解输入句子的含义。单个概念向量可以通过不同的函数进行投影,以用于不同特定领域的任务。然后也会接着一个特征融合过程。映射到不同子空间其实就是在模仿卷积神经网络以支持多通道模式的输出。
ensemble&融合
上面重点说的是将输入切分,然后提取不同子空间的信息。接下来我们从另一个方面来解释,多头的核心思想就是ensemble。
大量学术论文证明,很难只依靠单个头就可以同时捕捉到语法/句法/词法信息,因此需要多头。但是多头中每个头的功能不同,有的头可能识别不到啥信息,有的头可能主要识别位置信息,有的头可能主要识别语法信息,有的头主要识别词法信息。multi-head的作用就是为了保证这些pattern都能够被抽取出来。
我们可以把MHA的多个attention计算视为多个独立的小模型,每个head就像是一个弱分类器,最终整体的concat计算相当于把来自多个小模型的结果进行了融合,从而让最后得到的embedding关注多方面信息。而且,单头容易只关注自身的注意力权重,多头(需要让其有一定的头的基数)无疑是通过多次投票降低这种概率,这样效果比较好也是比较符合直觉的。做个比喻来说,这就好像是八个有不同阅读习惯的翻译家一同翻译同一个句子,他们每个人可能翻译时阅读顺序和关注点都有所不同,综合他们八个人的意见,最终得出来的翻译结果可能会更加准确。
缓解稀疏
通过观察大量样本的attention矩阵我们发现,其实几乎每一个token在全句中的注意力都是稀疏的,即每个token只关注非常有限个其他token,其余注意力基本可以看成是0(softmax无法严格为0)。
稀疏就意味着我们用较小的矩阵就可以来合较大的稀疏矩阵,其效果差不多,但是计算量却小很多。因此就不如把Q、K和V切分成多个小段,计算多次注意力矩阵,再再以某种方式整合,这样一来计算量其实跟直接 算单个注意力差不多,但这样模型融合的效果应该至少不差于单个注意力,甚至可能更好,因此有了多头注意力。
2.3 计算
计算流程
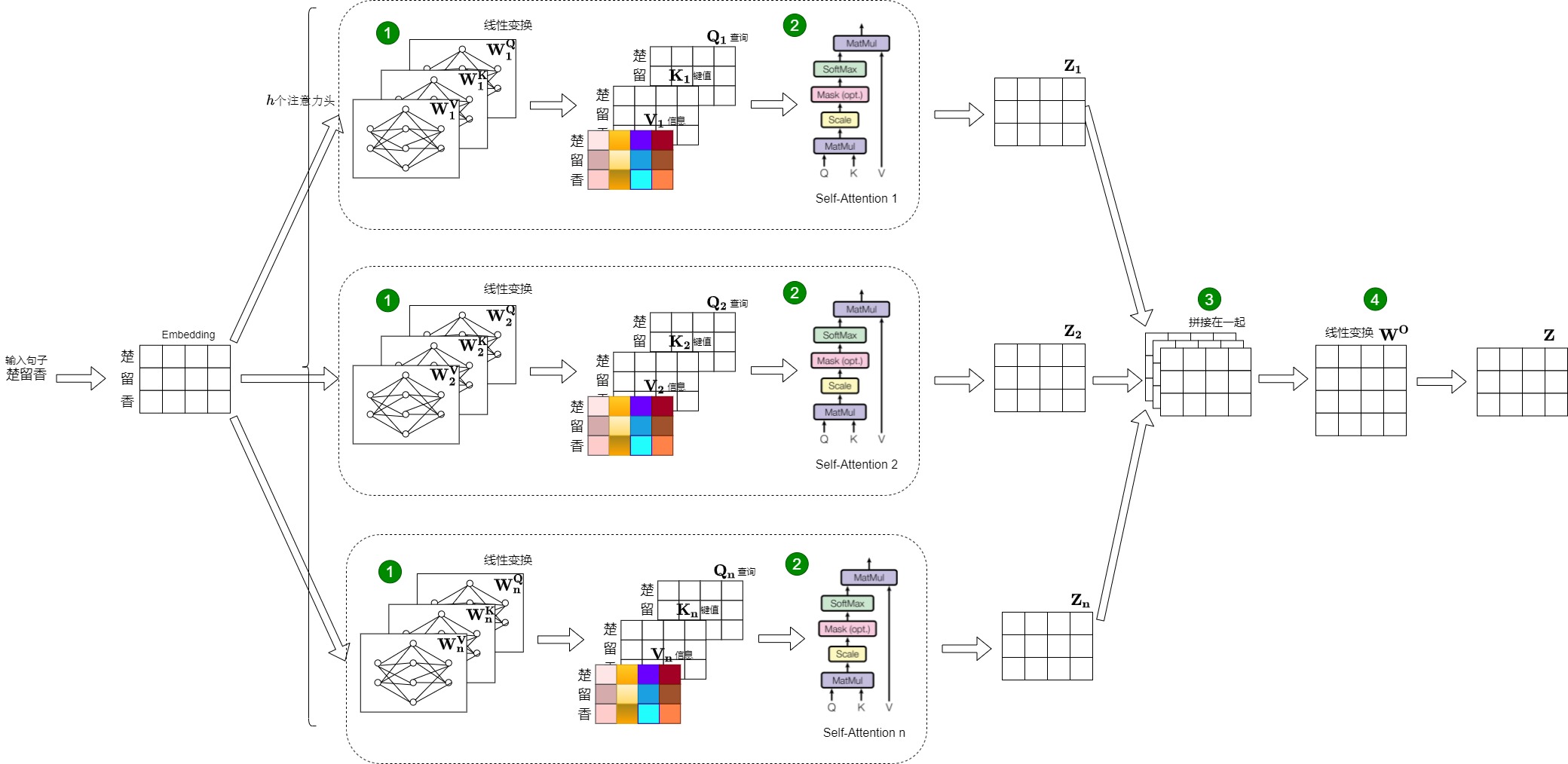
多头注意力的计算流程就是把高维向量切分为若干份低维向量,在若干低维空间内分别求解各自的Scaled Dot-Product Attention(点积自注意力)。总体流程分为:切分,计算,拼接,融合四部分,这里涉及很多步骤和矩阵运算,我们用一张大图把整个过程表示出来。
- 输入依然是原始的Q,K 和 V。
- 切分。每个注意头都有自己的可学习权重矩阵\(W_i^Q\), \(W_i^K\)和\(W_i^V\)。输入的Q、K和V经过这些权重矩阵进行多个线性变换后得到 N 组Query,Key 和 Value。这些组Q、K和V可以理解为把输入的高维向量线性投影到比较低的维度上。每个新形成的Q在本质上都要求不同类型的相关信息,从而允许注意力模型在上下文向量计算中引入更多信息。此处对于下图的标号1。
- 计算。每个头都使用 Self-Attention 计算得到 N 个向量。每个头可以专注学习输入的不同部分,从而使模型能够关注更多的信息。此处对于下图的标号2。
- 拼接。我们的目标是创建一个单一的上下文向量作为注意力模型的输出。因此,由单个注意头产生的上下文向量被拼接为一个向量。此处对于下图标号3。
- 融合。使用权重矩阵\(W^O\)以确保生成的上下文向量恢复为原 Embedding 的维度大小。这即是降维操作,也是融合操作。此处对于下图的标号4。
计算强度
我们以下图为基础来思考计算强度,D 表示 hidden size,H 表示 Head 个数,L 表示当前是在序列的第 L 个 Token。
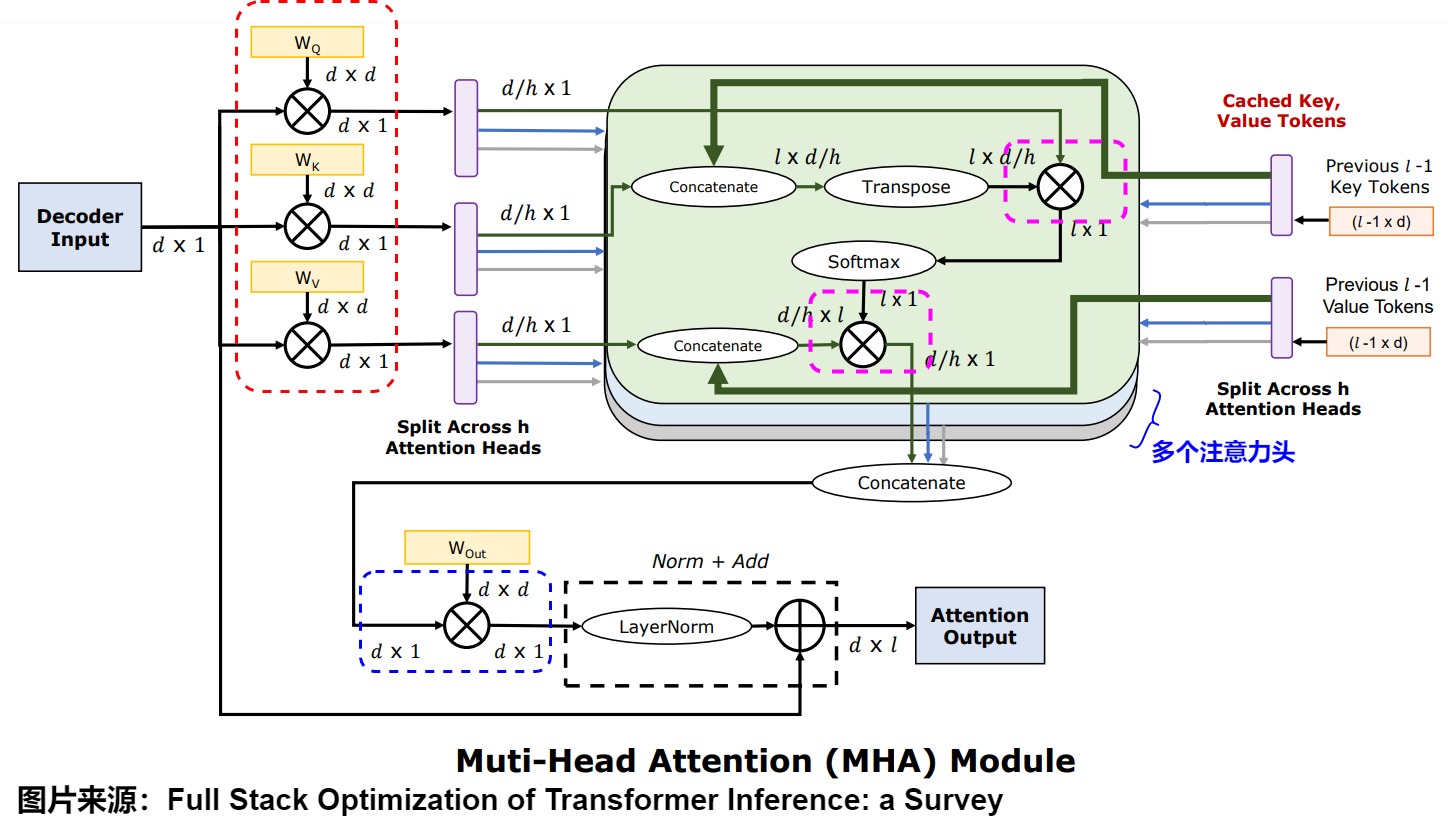
- 当 Batch Size 为 1 时,图中红色、紫色、蓝色虚线框处的矩阵乘法全部为矩阵乘向量,是 Memory Bound(内存受限操作),算术强度不到 1。
- 当 Batch Size 大于 1 时(比如 Continuous Batching):
- 红色和蓝色虚线框部分:因为是权重乘以激活,所以不同的请求之间可以共享 Weight。这里变成矩阵乘矩阵,并且 Batch Size 越大,算术强度越大,也就越趋近于 Compute Bound(FFN 层也类似)。
- 紫色虚线框部分:这里 Q、K 和 V 的 Attention 计算,是激活乘以激活,所以不同的请求之间没有任何相关性。即使 Batching,这里也是 Batched 矩阵乘向量,并且因为序列长度可能不同,这里不同请求的矩阵乘向量是不规则的。也就是说,这里算术强度始终不到 1,是明显的 Memory Bound。
从上可以看出,通过 Continuous Batching 可以很好的将 Memory Bound 问题转变为 Compute Bound,但 Q、K 和 V 的 Attention 计算的算术强度却始终小于 1。Sequence Length 越长,这里的计算量就越不可忽略,因为其属于系统的短板处。
2.4 效果
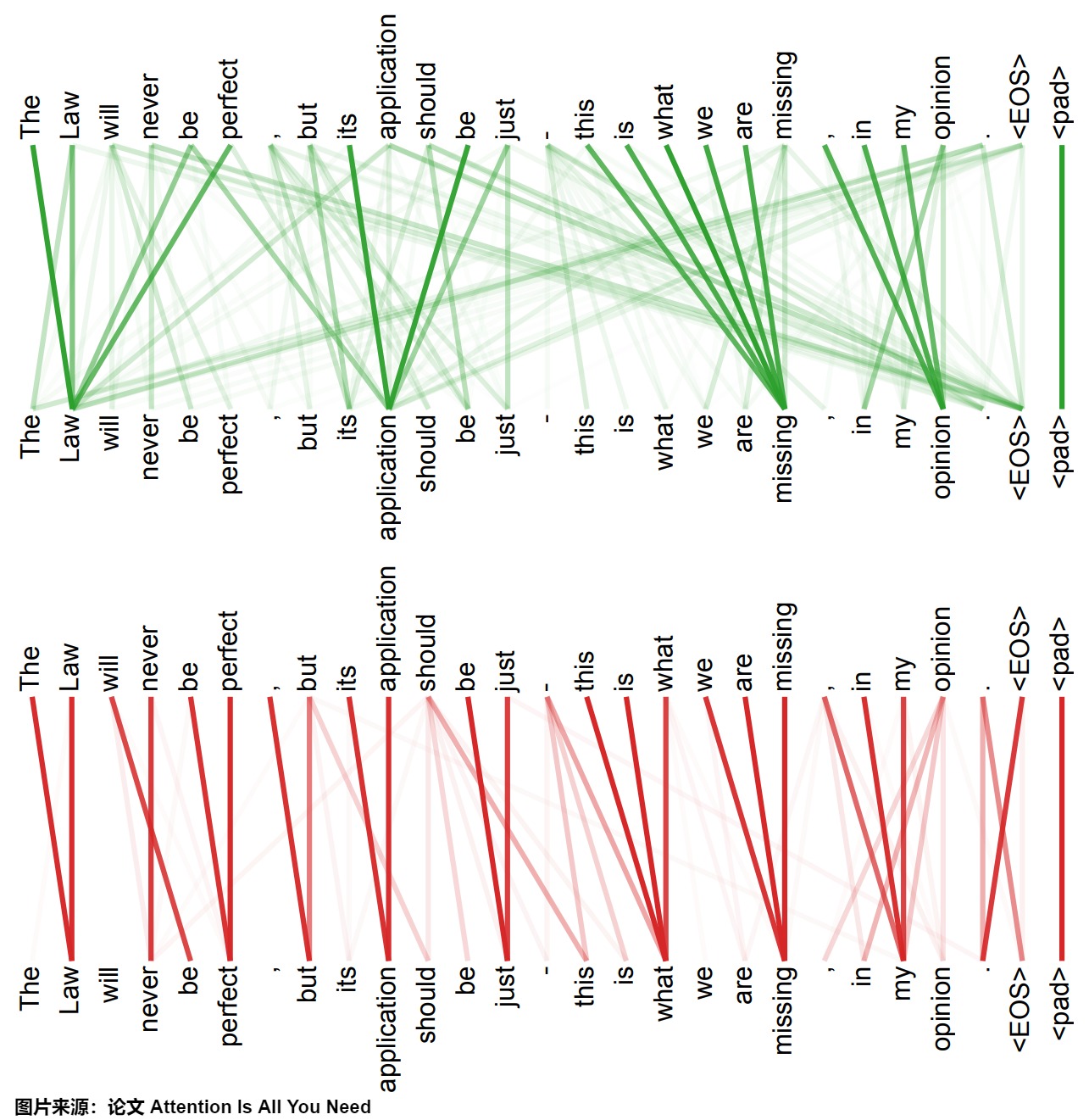
Transformer论文末尾给出了多头注意力机制中两个头的attention可视化结果,如下所示。图中,线条越粗表示attention的权重越大,可以看出,两个头关注的地方不一样,绿色图说明该头更关注全局信息,红色图说明该头更关注局部信息。
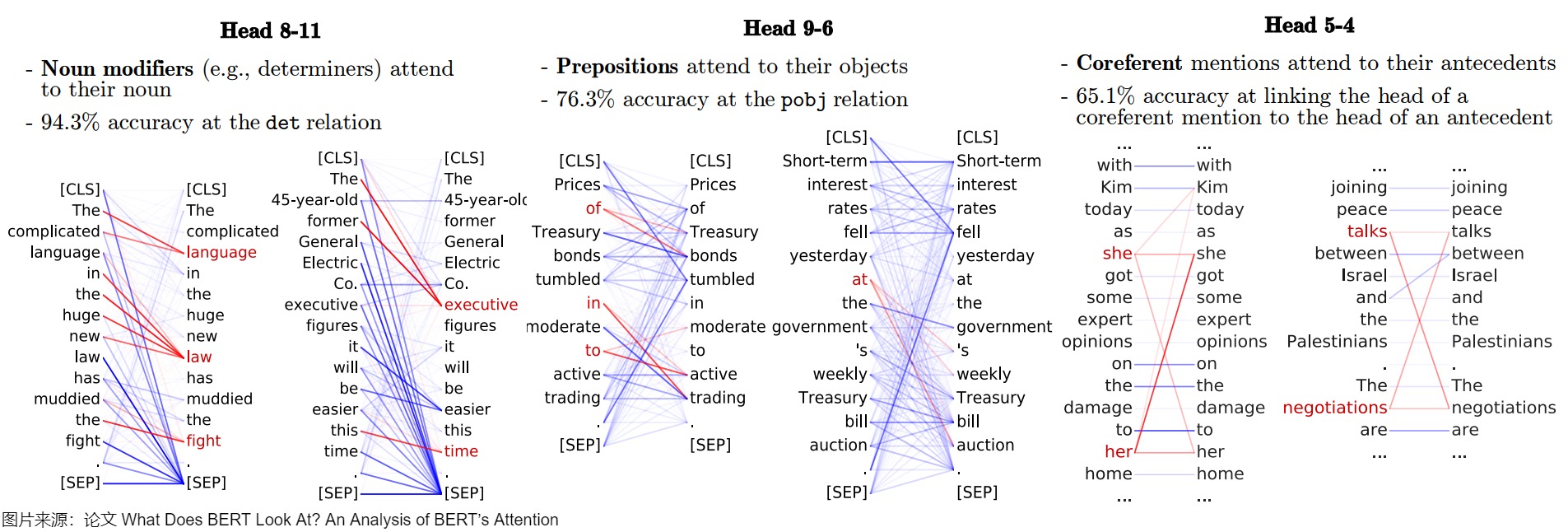
论文“What Does BERT Look At? An Analysis of BERT’s Attention”也给出了不同注意力头的示例。线条的粗细表示注意力权重的强度(一些注意力权重太低,以至于看不见)。
2.5 融合方式
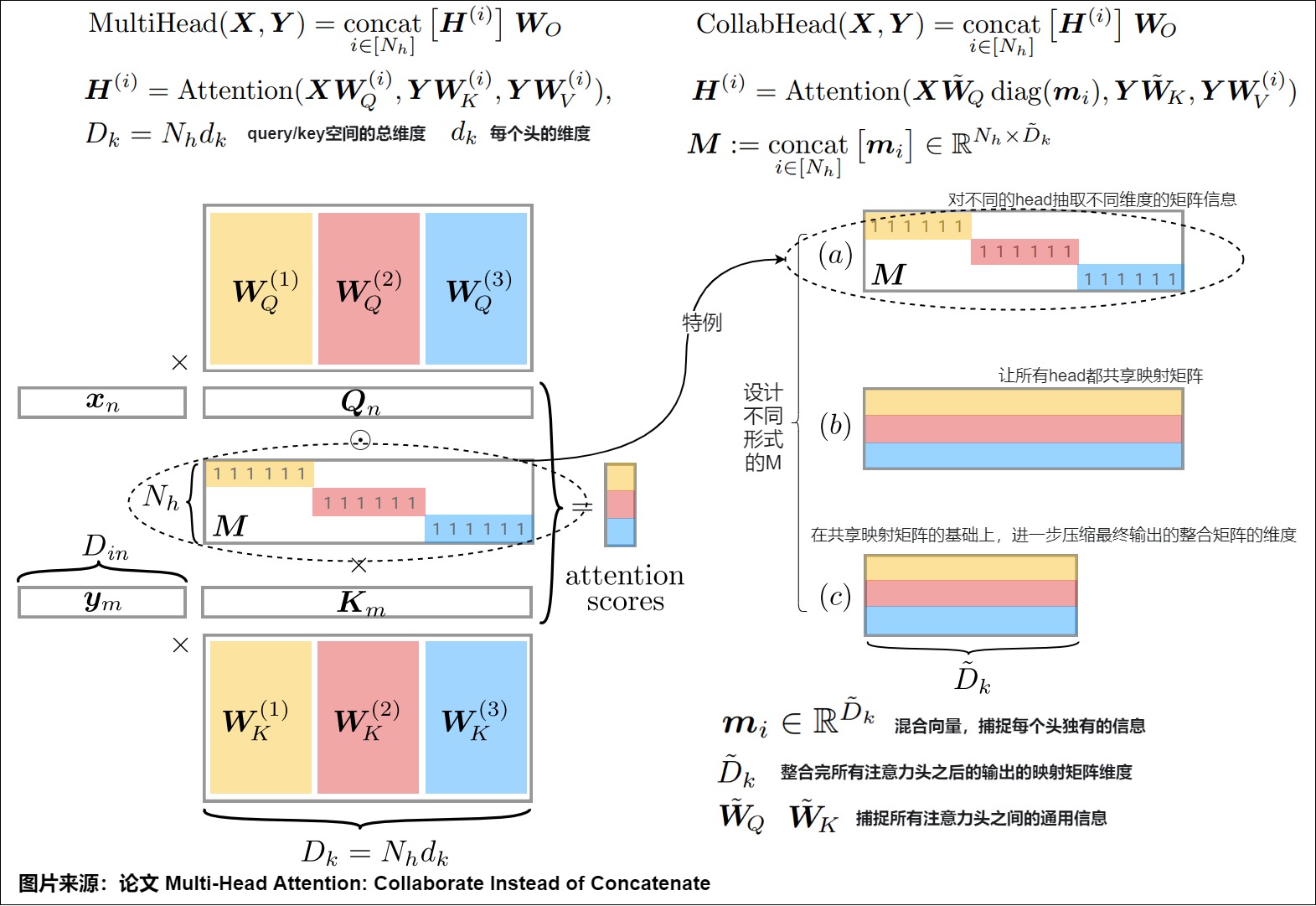
vanilla Transformer中,对于不同的注意力采取的整合方式是直接拼接。论文"Multi-Head Attention: Collaborate Instead of Concatenate“提出了其它整合方式。该论文发现所有注意力头之间捕捉的信息肯定是存在冗余的,头与头之间存在较多的通用信息。拼接后的 \(__^\) 只需要大概1/3的维度就足够捕捉绝大部分的信息了。因此论文作者设计了一个混合向量来提取注意力头之间的通用信息。这个向量可以通过跟模型一起学习得到,然后应用到原始的多头注意力计算中。这种方案可以让注意力头的表示方式更加灵活,注意力头的维度可以根据实际情况进行改变。也让参数计算更加高效。
下图左面是vanilla Transformer的原始拼接方式,右面是该论文提出的方案CollabHead。
- (a)是vanilla Transformer的原始拼接方式(相当于对不同的head抽取不同维度的矩阵信息),也是CollabHead方式的一种特例。\(m_i\)是一个由1和0两种元素组成的向量,其中1的元素位置为其对应注意力头的映射矩阵在拼接后的整体矩阵中的位置。这使得模型在整合注意力头的时候,让每个注意力头之间都互相独立。
- (b)是让所有head都共享映射矩阵。
- (c)在共享映射矩阵的基础上,进一步压缩最终输出的整合矩阵的维度,达到压缩维度的效果。
2.6 分析
研究人员对多头注意力做了深入的分析(比如论文"What Does BERT Look At? An Analysis of BERT’s Attention"),其中一些洞察和观点如下:
头数目
- 头数越少,注意力会更倾向于关注token自己本身或者其他的比较单一的模式,比如都关注CLS。
- 已有论文证明头数目不是越多越好(头的数量增多会导致各个子空间变小,这样子空间能表达的内容就减少了,而当有足够多的头,已经能够关注位置信息,语法信息,关注罕见词的能力了,再多一些头,可能是增进也可能是噪声)。头太多太少都会变差,具体多少要视模型规模,任务而定。目前可以看到的趋势是,模型越大(也就是hidden size越大),头数越多,就越能带来平均效果上的收益。
学习模式
- 对于大部分query,每个头都学习了某种固定的模式。
- 每个头确实学到东西有所不同,但大部分头之间的差异没有我们想的那么大(比如一个学句法,一个学词义这样明显的区分)。
- 少部分头可以比较好地捕捉到各种文本信息,而不会过分关注自身位置,一定程度缓解了上文提到的计算 \(QK^T\)之后对角线元素过大的问题。
下图给出了注意力头展示情况,有的注意力头关注所有的词(broadly),有的注意力头关注下一个token,有的注意力头关注SEP符号,有的注意力头关注标点符号。线条的粗细表示注意力权重的强度(一些注意力权重太低,以至于看不见)。

头与层级的关系
- 越靠近底层的注意力,其pattern种类越丰富,关注到的点越多。
- 模式随着层数的增加而慢慢固定。头之间的差距(或者说方差)随着所在层数变大而减少,即越来越包含更多的位置信息。
- 越到顶层的注意力,大部分注意力头的pattern趋同。
- 最后留下来的极少不相同的注意力头就是这个模型表达语义信息的注意力头。这也可以说明,为什么需要多层的Transformer堆叠,因为有些信息可能在某一层之中无法捕捉到,需要在其它层捕捉。
论文"What Does BERT Look At? An Analysis of BERT’s Attention"还分析了BERT对词语之间依存关系的识别效果。依存关系是词语和词语之间的依赖关系,比如“谓语”是一个句子的中心,其他成分与动词或直接或间接的产生关系。通过对词语之间依存关系的分析,论文作者发现BERT无法对所有的依存关系有比较好的处理,但是特定的层会对特定的依存关系识别的比较好。

论文”Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned“对多个Head进行了分析,发现多个Head的作用有大多数是冗余的,很多可以被砍掉。文中通过在多个数据集上跑实验,发现大部分Head可以分为以下几种:
- Positional Head:主要关注邻居的位置头。这个Head计算的权值通常指向临近的词,规则是这个Head在90%的情况下都会把最大的权值分配给左边或者右边的一个词。
- Syntactic Head:指向具有特定语法关系的token的句法头。这个Head计算的权值通常会将词语之间的关系联系起来,比如名词和动词的指向关系。
- Rare Head:指向句子中生僻词的头。这个Head通常会把大的权值分配给稀有词。
证明其头部分类重要性的最好方法是修剪其他类别。以下是他们的修剪策略示例,该策略基于普通transformer的 48 个头(8 个头乘以 6 个块)的头进行分类。
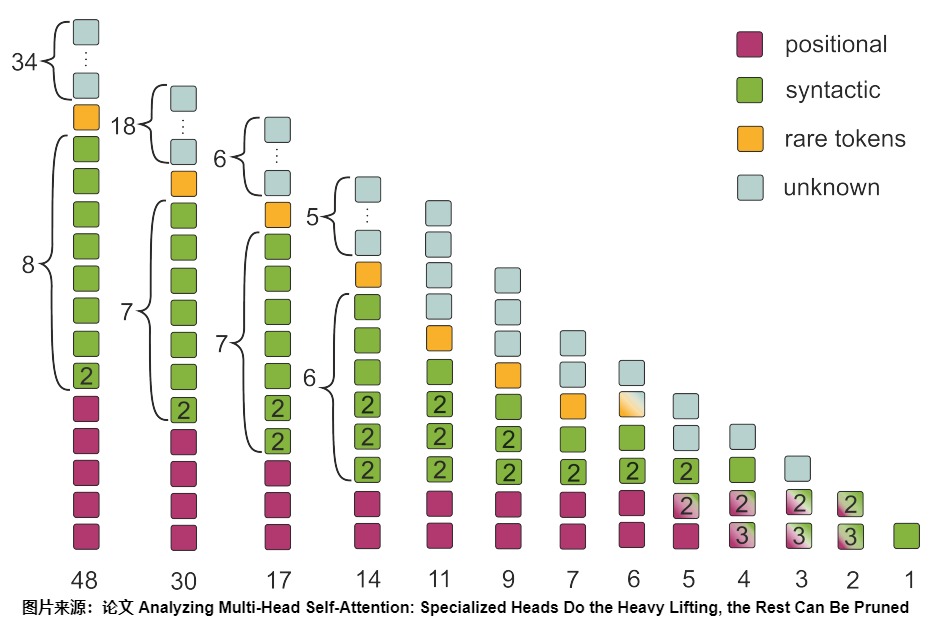
上图展示了修剪后保留编码器头的功能。每列代表不同修剪量。可以发现,通过保留被归类为主要类别的注意力头,他们设法保留了 48个头中的 17 个。请注意,这大约相当于编码器总头数的 2/3。每列下面数字代表剩余多少头。
该论文还分析了如何去精简Heads,优化的方法如下(给各个Head加个权值,相当于门控):

2.7 优点
多头注意力的优点如下:
- 丰富上下文理解增加模型的表达能力和学习能力,让模型可以捕捉到更加丰富的特征和信息。
- 提高计算效率:由于每个头工作在较低维度的空间中,注意力计算的复杂度降低,从而提高了计算效率。注意力计算的复杂度与维度的平方成正比,所以降维可以显著减少计算量。
- 并行化能力:多头注意力机制允许模型在不同的表示子空间上并行地学习,这提高了训练和推理的效率。
- 更好的泛化能力:由于多头注意力机制能够从多个角度分析输入数据,模型的泛化能力得到提升。同时,也使得模型对输入中的噪声和变化更加鲁棒。即使某些头被噪声或者不相关的信息干扰,其他头仍然可以提供有用的信息。
- 提高模型容量:即使每个头工作在较低维度的子空间中,组合多个头的结果可以捕捉到不同子空间中的信息,从而增加模型的容量。
0x03 实现

3.1 定义
多头注意力由类MultiHeadedAttention来实现,其中关键参数及变量如下。
- d_model是模型的维度,也就是单头注意力下,query,key,value和词嵌入的向量维度。我们假设是512。
- h是注意力头数,假设为8。
- d_k是单个头的注意力维度,大小是d_model / h,所以512/8=64。
另外,注释中:
- seq_len是句子长度,也就是token个数(可以认为是句子中最大包含多少单词),我们假设是10个单词。shape指的是张量形状。
- batch_size是batch size。
MultiHeadedAttention的初始化代码如下。
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
# 因为后续要给每个头分配等量的词特征,把词嵌入拆分成h组Q/K/V,所以要确保d_model可以被h整除,保证 d_k = d_v = d_model/h
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h # 单个头的注意力维度
self.h = h # 注意力头数量
# 定义W^Q, W^K, W^V和W^O矩阵,即四个线性层,每个线性层都具有d_model的输入维度和d_model的输出维度,前三个线性层分别用于对Q向量、K向量、V向量进行线性变换,第四个用来融合多头结果
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None # 初始化注意力权重
self.dropout = nn.Dropout(p=dropout) # 进行dropout操作时置0比率,默认是0.1
3.2 运算逻辑
结合哈佛代码中的具体函数从整体上把多头注意力的计算过程(这里从第一个编码层来演示,所以涵盖了词嵌入)梳理如下图所示。
注:
- 为方便理解,下图去掉 batch_size 维度,聚焦于剩下的维度。
- 图上限定为2个头。注意:代码之中没有切分线性层权重\(W^Q,W^K,W^V\)的部分,而是合用,因此图上省略。
- 实际上代码实现的时候可以忽略concat,最朴素的实现都是在通道维度reshape成多头,然后过两个矩阵乘就可以了。
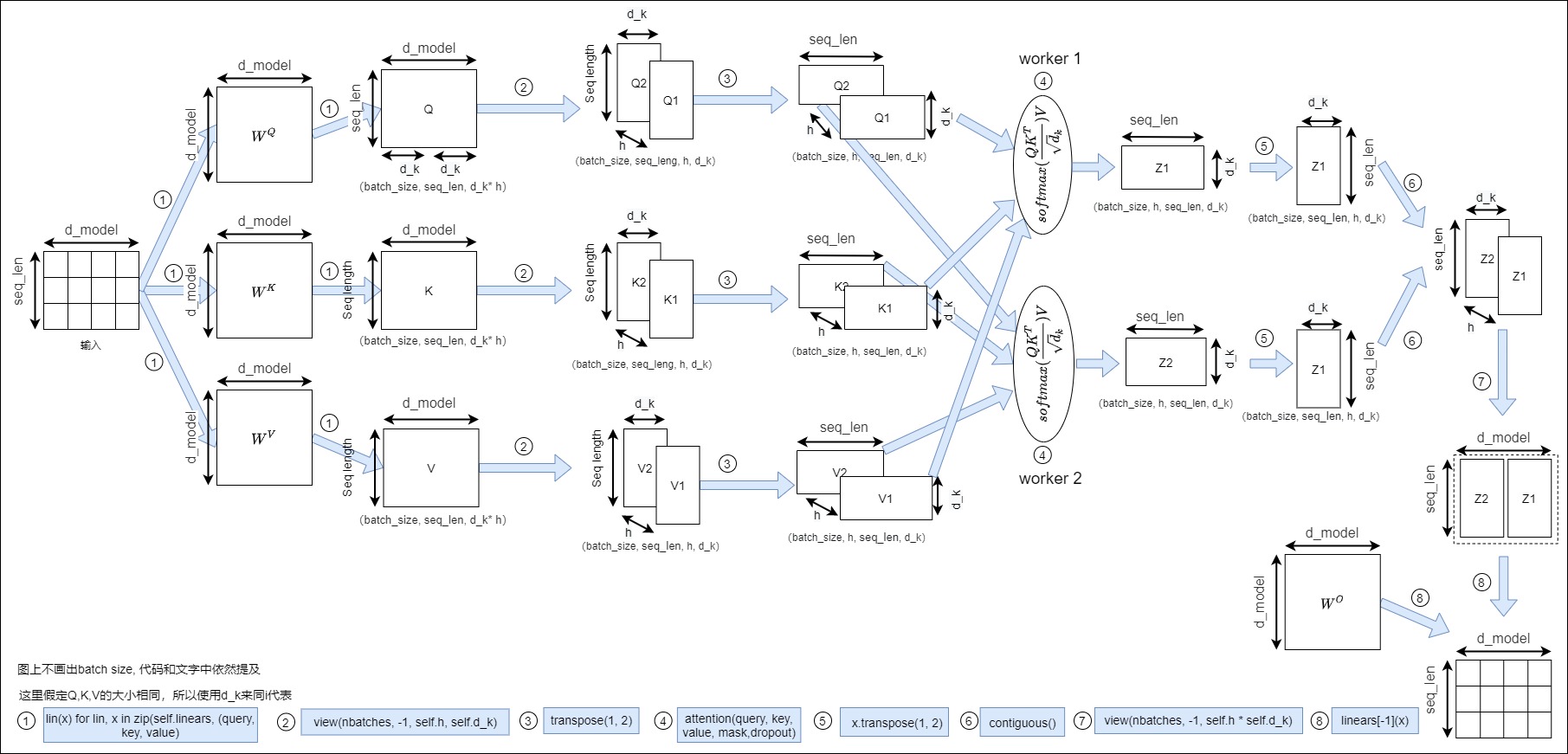
输入
编码器的输入是词嵌入,其数据维度为(batch_size, seq_len, d_model)。需要注意的是,论文的架构图中,投影和切分通过\(3 \times h\)个小权重矩阵来完成。
投影
此处对应图上的序号1。
在单头注意力机制中,输入会与 \(W^Q,W^K,W^V\) 矩阵相乘。\(W^Q,W^K,W^V\) 是三个独立的线性层。每个线性层都有自己独立的权重。输入数据与三个线性层分别相乘,产生 Q、K、V。而哈佛代码中此处依然是用三个大的权重矩阵\(W^Q,W^K,W^V\) ,并非论文所列出的\(3 \times h\)个小权重矩阵,然而,随着训练的进行,物理上的三个大的权重矩阵会自然而然的变成逻辑上的\(3 \times h\)个小权重矩阵。
切分数据
此处对应图上的序号2。切分并非是直接在物理层面上简单的把词嵌入切分成h份,而是要进行降维变化,即通过权重矩阵将它们从原始维度映射到较低的维度,得到 h 个具有独立语义逻辑的在不同子空间上小“Embedding”。
逻辑角度
经由线性层输出的 Q、K 和 V 矩阵将被分割到多个注意头中,以便每个注意头能够独立地处理它,此处会改变 Q、K 和 V 矩阵形状。从逻辑上来说是做如下操作。
\]
从向量角度而言,分割操作将张量中每一行 d_model (原始词嵌入)都拆成了h个 d_k长度的行向量(带有子语义逻辑的“小Embedding”)。即:(batch_size, seq_len, d_model) -> (batch_size, seq_len, nums_heads, d_k)。虽然从 Embedding 向量的角度看是从 d_model维降到了每一个头的 d_k 维,每个头注意力对应的维度减少了,但实际上每一个头 head 同样可以在某个子空间中表达某些细分的语义逻辑。
从神经网络角度而言:由于对于单层全连接网络,输入层与隐层节点的任何一个子集结合,都是一个完整的单隐层全连接网络。也就是说,这种拆分完全可以看做将前一步input_depth 个节点到 d_model 个节点的全连接网络,拆分成了h个小的 input_depth 个节点到d_k个节点的全连接网络。
物理角度
实际上在代码中会采用大矩阵的方式来进行。具体会通过view(nbatches, -1, self.h, self.d_k)操作把投影输出 Query, Key, Value拆分成多头,即增加一个维度,将最后一个维度变成d_k。或者说,把分拆最后一个维度到 (h, d_k)。现在每个 "切片"对应于每个头的一个矩阵。
如前所述,投影是逻辑投影,那么切分也只是逻辑上的切分。对于参数矩阵 Query, Key, Value 而言,并没有物理切分成对应于每个注意力头的独立矩阵,仅逻辑上每个注意力头对应于 Query, Key, Value 的独立一部分。同样,各注意力头没有单独的线性层,而是所有的注意力头共用线性层,只是不同的注意力头在独属于其的逻辑部分上进行操作。这种逻辑分割,是通过将输入数据以及线性层权重,均匀划分到各注意头中来完成的。
基于此,所有 Heads 的计算可通过对一个的矩阵操作来实现,而不需要h个单独操作。这使得计算更加有效,同时保持模型的简单:所需线性层更少,同时获得了多头注意力的效果。
其实,也可采用小矩阵的方式进行计算,即把做 Query, Key, Value做物理切分,然后利于for循环一个一个计算头,再将结果列表进行concat,这样代码上更清晰一点,但是性能不如大矩阵的方案。
小结
输入的维度是:batch_size, seq_len, d_model)。\(W^Q,W^K,W^V\) 线性层的维度是(d_model, d_model),实际上线性层并没有针对多头做切分。实际上多头的 \(W^Q,W^K,W^V\) 矩阵仍然是三个单一矩阵,但可以把它们看作是每个注意力头的逻辑上独立的\(W^Q,W^K,W^V\) 矩阵。这样得到的单头对应的 Q、K 和 V 逻辑矩阵形状是(batch_size, seq_len, h, d_k)。
调整维度
此处对应图上的序号3。
为了更好的并行,接下来会通过交换 h和 seq_len 这两个维度改变 Q、K 和 V 矩阵的形状。图示中未表达出 batch 维度,实际上每一个注意力头的 'Q' 的维度是(batch_size, h, seq_len, d_k)。
为每个头计算注意力
如前所述,有两种方式来计算每个头的注意力。
- 大矩阵方式,该种方式将8个注意头全部平铺在三维输入矩阵的第0维batch_size上,一起进行点乘操作,点乘结果再通过reshape和转置整理为8个头在第2维上的拼接,这种方式计算快。
- for循环一个一个计算头,再将结果列表进行concat,代码上更清晰一点。
vanilla Transformer使用大矩阵方式。此处对应图上的序号4。
单独分组
目前在逻辑上已经把每个query,key,value按照各自的维度分割为若干段,形成若干独立的query,key,value分组,每个分组对应一个注意力头。接下来每个分组内进行点积运算和加权平均,比如query的第一段只和key的第一段进行点积,其结果也只是value第一段的权重,以此类推。这是独立的分组,在每个组内进行注意力操作,不会跨组操作。从原理层面上看,这是把 Attention 机制分割在 Embedding 中的不同细分逻辑子空间中(语义逻辑、语法逻辑、上下文逻辑、分类逻辑等)来运作了,即把原来在一个高维空间里衡量一个文本的任意两个字之间的相关度,变成了在8维空间里去分别衡量任意两个字的相关度的变化。
并行
每个头的注意力计算其实和单头注意力没啥区别,但是有一个点可以留意下,即单头计算是使用最后两个维度(seq_len, d_k),跳过前两个维度(batch_size, h)。而每个注意力头的输出形状为:(batch_size,h,seq_len,d_k)。之所以要这么处理,完全是因为计算的需要。因为Q、K和V的前两个维度(多头与 batch)是等价的,本质上都是并行计算。所以计算时也可以把它们放在同一个维度上:batch_size * num_heads。也正是因为计算的需要,注意力权重 ( QK^T ) 的形状有时是三维张量 (batch_size*num_heads, tgt_seq_len, src_seq_len),有时是四维张量 (batch_size, num_heads, tgt_seq_len, src_seq_len) ,会根据需要在二者间切换。
通常,独立计算具有非常简单的并行化过程。尽管这取决于 GPU 线程中的底层低级实现。理想情况下,我们会为每个batch 和每个头部分配一个 GPU 线程。例如,如果我们有 batch=2 和 heads=3,我们可以在 6 个不同的线程中运行计算。即使尺寸是d_k=d_model/heads。由于每个头的计算是并行进行的(不同的头拿到相同的输入,进行相同的计算),模型可以高效地处理大规模输入。相比于顺序处理的 RNN,注意力机制本身支持并行,而多头机制进一步增强了这一点。
融合每个头的Z
我们现在对每个头都有单独的Z,而编码器的下一层希望得到是一个矩阵,而不是h个矩阵,因此前面怎么拆分,现在还需要拼回去。将多头输出的多个Z通过全连接合并为一个输出Z。这个合并操作本质上是与分割操作相反,通过重塑结果矩阵以消除 d_k 维度来完成的。其步骤如下:
为了能够方便地将多头结果拼合起来,首先我们将h转置到倒数第二个维度,即交换头部和序列维度来重塑注意力分数矩阵。换句话说,矩阵的形状从(batch_size,h,seq_len,d_k)变成(batch_size,seq_len,h,d_k)。此处对应图上的序号5。
将意力分数矩阵放到一块连续的物理内存中,是深拷贝,不改变原数据。此处对应图上的序号6。
通过重塑 (batch_size,seq_len,d_model)来折叠头部维度。这就有效地将每个头的注意得分向量连接成一个合并的注意得分。此处对应图上的序号7。
通过全连接层的线性变换把拼合好的输出进行有机融合,经过全连接层融合后的最后一维仍然是
d_model。此处对应图上序号8。
可以看到 Multi-Head Attention 输出的矩阵Z与其输入的矩阵X的维度是一样的。
forward()函数
上面运算逻辑对应的是MultiHeadedAttention的forward()函数,具体如下。
def forward(self, query, key, value, mask=None):
"""
本函数是论文中图2(多头注意力的架构图)的实现。
- query, key, value:并非论文公式中经过W^Q, W^K, W^V计算后的Q, K, V,而是原始输入X。query, key, value的维度是(batch_size, seq_len, d_model)
- mask:注意力机制中可能需要的mask掩码张量,默认是None
"""
if mask is not None:
# 对所有h个头应用同样的mask
# 单头注意力下,mask和X的维度都是3,即(batch_size, seq_len, d_model),但是多头注意力机制下,会在第二个维度插入head数量,因此X的维度变成(batch_size, h,seq_len,d_model/h),所以mask也要相应的把自己拓展成4维,这样才能和后续的注意力分数进行处理
mask = mask.unsqueeze(1) # mask增加一个维度
nbatches = query.size(0) # 获取batch_size
# 1) Do all the linear projections in batch from d_model => h x d_k
"""
1). 批量执行从 d_model 到 h x d_k 的线性投影,即计算多头注意力的Q,K,V,所以query、value和key的shape从(batch_size,seq_len,d_model)变化为(batch_size,h,seq_len,d_model/h)。
zip(self.linears, (query, key, value)) 是把(self.linears[0],self.linears[1],self.linears[2])这三个线性层和(query, key, value)放到一起
然后利用for循环将(query, key, value)分别传到线性层中进行遍历,每次循环操作如下:
1.1 通过W^Q,W^K,W^V(self.linears的前三项)求出自注意力的Q,K,V,此时Q,K,V的shape为(batch_size,seq_len,d_model), 对应代码为linear(x)。
以self.linears[0](query)为例,self.linears[0] 是一个 (512, 512) 的矩阵,query是(batch_size,seq_len,d_model),相乘之后得到的新query还是512(d_model)维的向量。
key和value 的运算完全相同。
1.2 把投影输出拆分成多头,即增加一个维度,将最后一个维度变成(h,d_model/h),投影输出的shape由(batch_size,seq_len,d_model)变为(batch_size,seq_len,h,d_model/h)。对应代码为`view(nbatches, -1, self.h, self.d_k)`,其中的-1代表自适应维度,计算机会根据这种变换自动计算这里的值。
因此我们分别得到8个头的64维的key和64维的value。这样就意味着每个头可以获得一部分词特征组成的句子。
1.3 交换“seq_len”和“head数”这两个维度,将head数放在前面,最终shape变为(batch_size,h,seq_len,d_model/h)。对应代码为`transpose(1, 2)`。交换的目的是方便后续矩阵乘法和不同头部的注意力计算。也是为了让代表句子长度维度和词向量维度能够相邻,这样注意力机制才能找到词义与句子位置的关系,从attention函数中可以看到,利用的是原始输入的倒数第一和第二维.这样我们就得到了每个头的输入。
多头与batch本质上都是并行计算。所以计算时把它们放在同一个维度上,在用GPU计算时,大多依据batch_size * head数来并行划分。就是多个样本并行计算,具体到某一个token上,可以理解为n个head一起并行计算。
"""
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) # 对应图上的序号2,3
for lin, x in zip(self.linears, (query, key, value)) # 对应图上的序号1
]
# 2) Apply attention on all the projected vectors in batch.
"""
2) 在投影的向量上批量应用注意力机制,具体就是求出Q,K,V后,通过attention函数计算出Attention结果。因为head数量已经放到了第二维度,所以就是Q、K、V的每个头进行一一对应的点积。则:
x的shape为(batch_size,h,seq_len,d_model/h)。
self.attn的shape为(batch_size,h,seq_len,seq_len)
"""
x, self.attn = attention( # 对应图上的序号4
query, key, value, mask=mask, dropout=self.dropout
)
# 3) "Concat" using a view and apply a final linear.
"""
3) 把多个头的输出拼接起来,变成和输入形状相同。
通过多头注意力计算后,我们就得到了每个头计算结果组成的4维张量,我们需要将其转换为输入的形状以方便后续的计算,即将多个头再合并起来,进行第一步处理环节的逆操作,先对第二和第三维进行转置,将x的shape由(batch_size,h,seq_len,d_model/h)转换为 (batch_size,seq_len,d_model)。
3.1 交换“head数”和“seq_len”这两个维度,结果为(batch_size,seq_len,h,d_model/h),对应代码为:`x.transpose(1, 2).contiguous()`。`contiguous()`方法将变量放到一块连续的物理内存中,是深拷贝,不改变原数据,这样能够让转置后的张量应用view方法,否则将无法直接使用。
3.2 然后将“head数”和“d_model/head数”这两个维度合并,结果为(batch_size,seq_len,d_model),代码是view(nbatches, -1, self.h * self.d_k)。
比如,把8个head的64维向量拼接成一个512的向量。然后再使用一个线性变换(512,512),shape不变。因为有残差连接的存在使得输入和输出的维度至少是一样的。
即(5, 8, 10, 64) ==> (5, 10, 512)
"""
x = (
x.transpose(1, 2) # 对应图上的序号5
.contiguous() # 对应图上的序号6
.view(nbatches, -1, self.h * self.d_k) # 对应图上的序号7
)
del query
del key
del value
# 当多头注意力机制计算完成后,将会得到一个形状为[src_len,d_model]的矩阵,也就是多个z_i水平堆叠后的结果。因此会初始化一个线性层(W^O矩阵)来对这一结果进行一个线性变换得到最终结果,并且作为多头注意力的输出来返回。
# self.linears[-1]形状是(512, 512),因此最终输出还是(batch_size, seq_len, d_model)。
return self.linears[-1](x) # 对应图上的序号8
3.3 调用
我们接下来看看如何调用。在 Transformer 里,有 3 个地方用到了 MultiHeadedAttention,Encoder层用到一处,Decoder层用到两处。
编码器
Encoder使用自注意力的目的是:找到自身的关系,因此对于其内部的多头自注意力(Multi-Head Attentyion)机制来说,调用MultiHeadedAttention.forward(query, key, value, mask)时候,query,key 和 value 都是相同的输入值X或者下层(对应Transformer架构图)的输出。在代码之中,对应如下:
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def forward(self, x, mask):
# 这里调用MultiHeadedAttention.forward(query, key, value, mask)
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
解码器
Decoder的目的是:
- 使用自注意力找到输出序列自身内部的语义关系。让目标序列之中,每个token都搜集到本字和目标序列之中其他哪几个字比较相关。
- 使用交叉注意力让源序列与目标序列对齐。
因此,
- 对于Decoder最前面的掩码多头注意力机制(Masked Multi-Head Attentyion)来说,调用MultiHeadedAttention.forward(query, key, value, mask)时候,query,key 和 value 都是相同的值X(Decoder的输入)。但是 Mask 使得它不能访问未来的输入,即为了并行一次喂入所有解码部分的输入,所以要用mask来进行掩盖当前时刻之后的位置信息。
- 对于Decoder中间的多头注意力机制(Multi-Head Attentyion)来说,会将Encoder的输出memory
作为key和value,将下层的输出作为本层的query。
代码如下:
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
0x04 改进
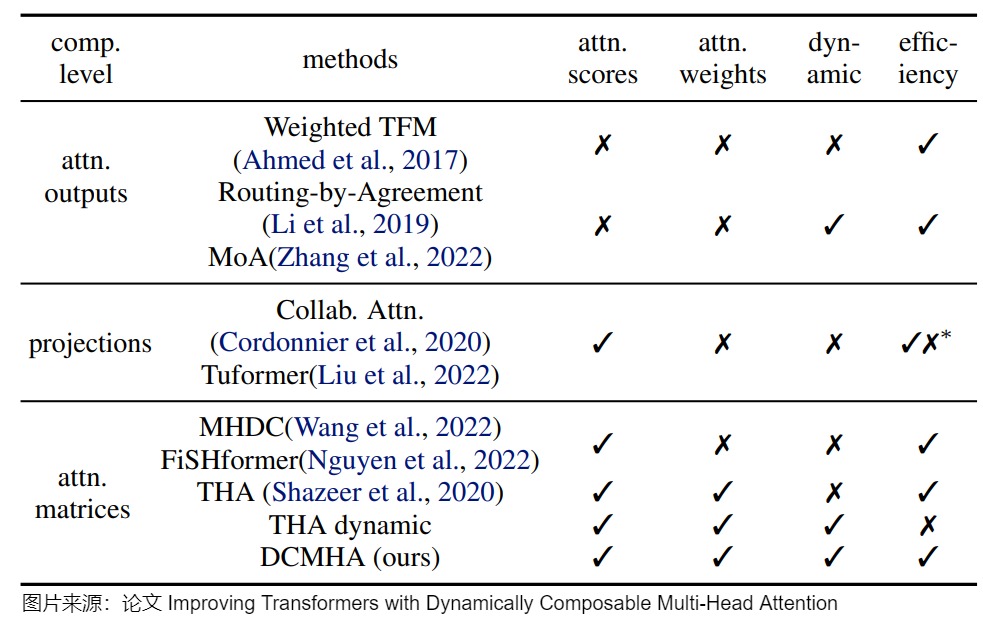
人们也对多头注意力进行了一些改进。下图给出了注意力头合并方式的一些方案(head composition approaches)的比较。
4.1 MOHSA
Transformer模型成功的主要原因是不同 Token 之间的有效信息交换,从而使每个 Token 都能获得上下文的全局视图。然而,每个Head中的 Query 、 Key和Value 是分开的,没有重叠,当在各个Head中计算注意力时也没有信息交换。换句话说,在计算当前Head的注意力时,它没有其他Head中的信息。尽管 Token 在注意力之后会通过线性投影进行处理,但那时的信息交换仅限于每个 Token。
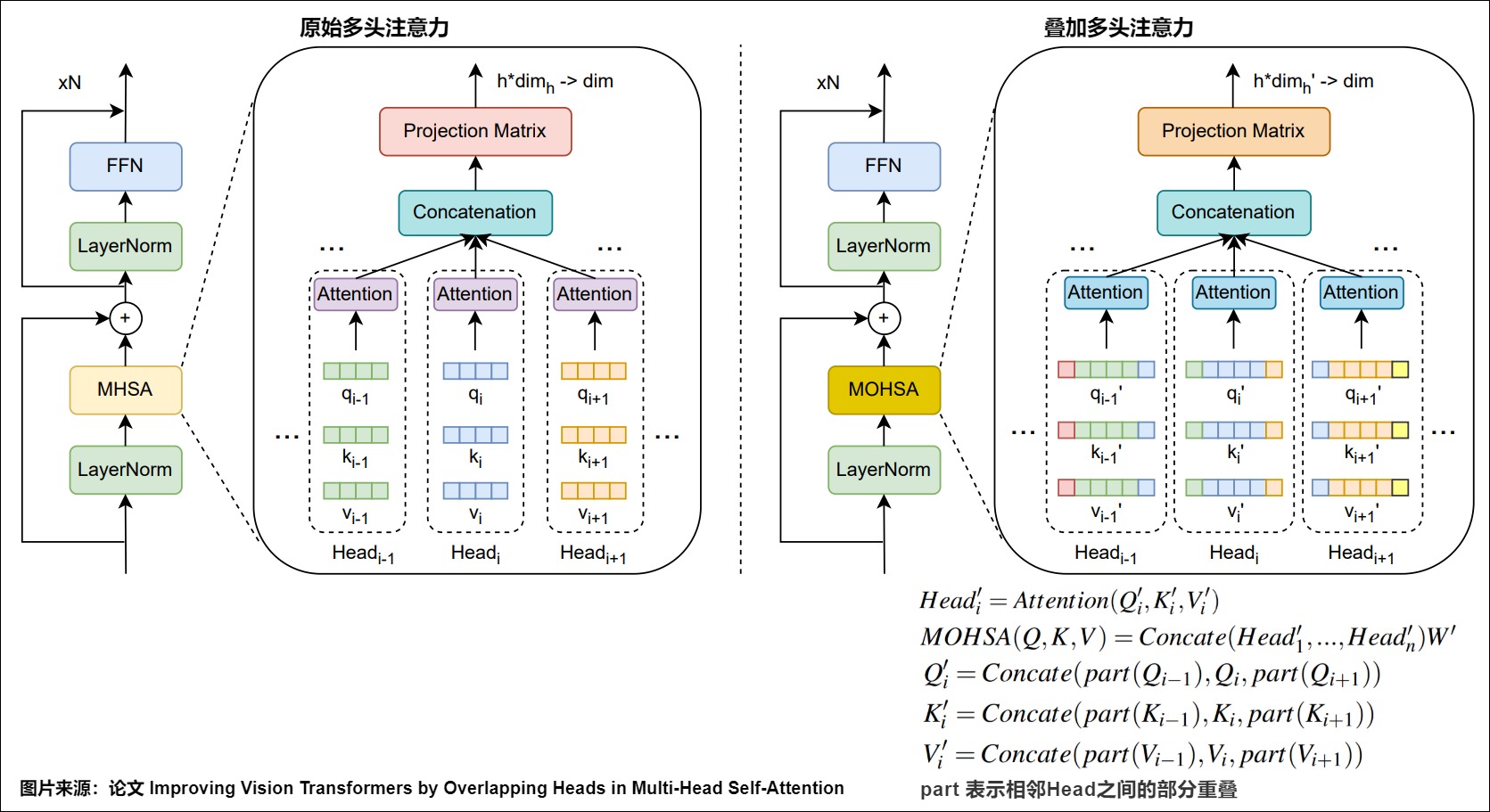
论文“Improving Vision Transformers by Overlapping Heads in Multi-Head Self-Attention”就对此进行了研究。作者提出信息交换在视觉 Transformer (Vision Transformers)的注意力计算过程中可以提高性能。这可以通过将每个Head的 queries、keys和values与相邻Head的 queries、keys和values重叠来实现。为此,作者提出了一种名为MOHSA(Multi-Overlapped-Head Self-Attention/多重叠头自注意力)的方法,通过重叠Head来改进多Head自注意力(Multi-Head Self-Attention)机制,使得在计算注意力时,每个Head中的 Q、 K和 V也可以被其相邻Head的 Q、 K和 V所影响,Head间信息交流可以为视觉 Transformer 带来更好的性能。如图所示。
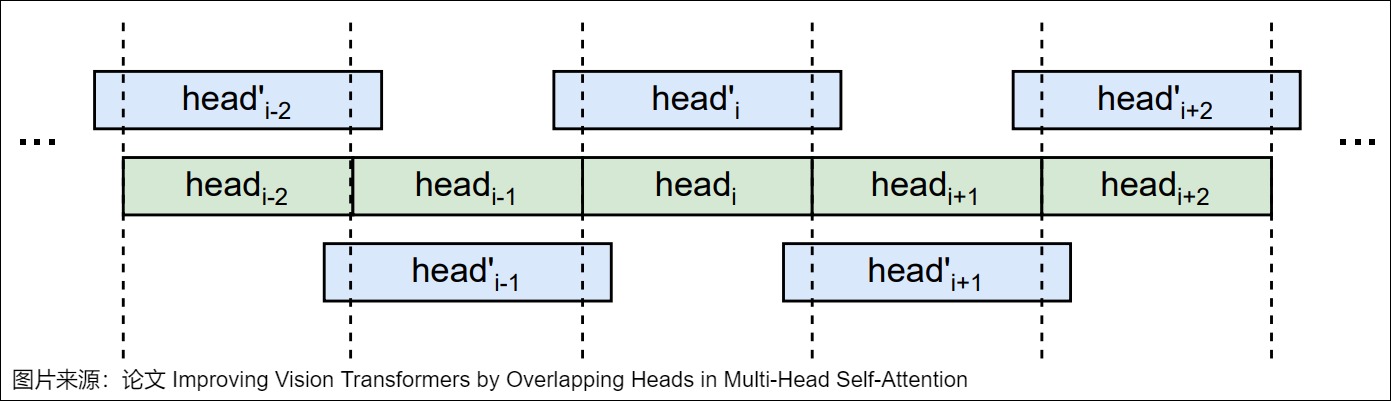
为了实现Head之间的信息交换,作者在Q、K和V被划分为不同Head时,使用重叠(Soft)除而不是直接除。通过重叠相邻Head,其他Head中的信息也可以参与当前Head的注意力计算。由于将不同Head的 Token 连接后,重叠会使 Token 维度增加,因此线性投影会将其减小回原始大小。
4.2 MoH
论文“MoH: Multi-Head Attention as Mixture-of-Head Attention”借鉴并非所有注意力头都具有同等重要性的观点,提出了混合头注意力(Mixture-of-Head,MoH)的新架构,将注意力头视为混合专家机制(Mixture-of-Experts,MoE)中的专家,这样就升级了Transformer模型的核心——多头注意力机制。MoH具有两个显著优点:
- 使每个词元能够选择合适的注意力头,从而提高推理效率而不牺牲准确率或增加参数数量;
- 用加权求和取代了多头注意力的标准求和,为注意力机制引入了灵活性,无需增加参数数量,并释放了额外的性能潜力。
MoH总体架构如下图右侧所示,包括多个注意力头和一个路由器(激活Top-K个头)。MoH的输出是K个选定头的输出的加权和。

MoH主要改进如下图所示。
- 共享头:指定一部分头为始终保持激活的共享头,在共享头中巩固共同知识,减少其他动态路由头之间的冗余。
- 两阶段路由:路由分数由每个单独头的分数和与头类型相关的分数共同决定。相关路由分数公式如下图标号1。
- 负载平衡损失:为避免不平衡负载,应用了负载平衡损失。公式如下图标号2。
- 总训练目标:总训练损失是任务特定损失和负载平衡损失的加权和,公式如下图标号3。其中β是权衡超参数,默认设置为0.01。

4.3 DCMHA
论文“Improving Transformers with Dynamically Composable Multi-Head Attention”提出用可动态组合的多头注意力(DCMHA,Dynamically Composable Multi-Head Attention)来替换Transformer核心组件多头注意力模块(MHA),从而解除了MHA注意力头的查找选择回路和变换回路的固定绑定,让它们可以根据输入动态组合,从根本上提升了模型的表达能力。
可以把DCMHA近似理解为,原来每层有固定的H个注意力头,现在用几乎同样的参数量和算力,可按需动态组合出多至HxH个注意力头。这样即插即用,可在任何Transformer架构中替换MHA,得到通用、高效和可扩展的新架构DCFormer。
研究背景
在Transformer的多头注意力模块(MHA)中,各个注意力头彼此完全独立的工作。这个设计因其简单易实现的优点已在实践中大获成功,但同时也带来注意力分数矩阵的低秩化削弱了表达能力、注意力头功能的重复冗余浪费了参数和计算资源等一些弊端。基于此,近年来有一些研究工作试图引入某种形式的注意力头间的交互。
动机
根据Transformer回路理论,在MHA中 ,每个注意力头的行为由\(W^Q\)、\(W^K\)、\(W^V\)、\(W^O\)四个权重矩阵刻画(其中\(W^O\)由MHA的输出投影矩阵切分得到),其中:
- \(W^QW^K\)叫做QK回路(或叫查找选择回路),决定从当前token关注上下文中的哪个(些)token
- \(W^OW^V\)叫做OV回路(或叫投影变换回路),决定从关注到的token取回什么信息(或投影什么属性)写入当前位置的残差流,进而预测下一个token。
研究人员注意到,查找(从哪拿)和变换(拿什么)本来是独立的两件事,理应可以分别指定并按需自由组合,MHA硬把它们放到一个注意力头的QKOV里“捆绑销售”,限制了灵活性和表达能力。
思路
以此为出发点,本文研究团队在MHA中引入compose操作,从而得到DCMHA如下图所示。

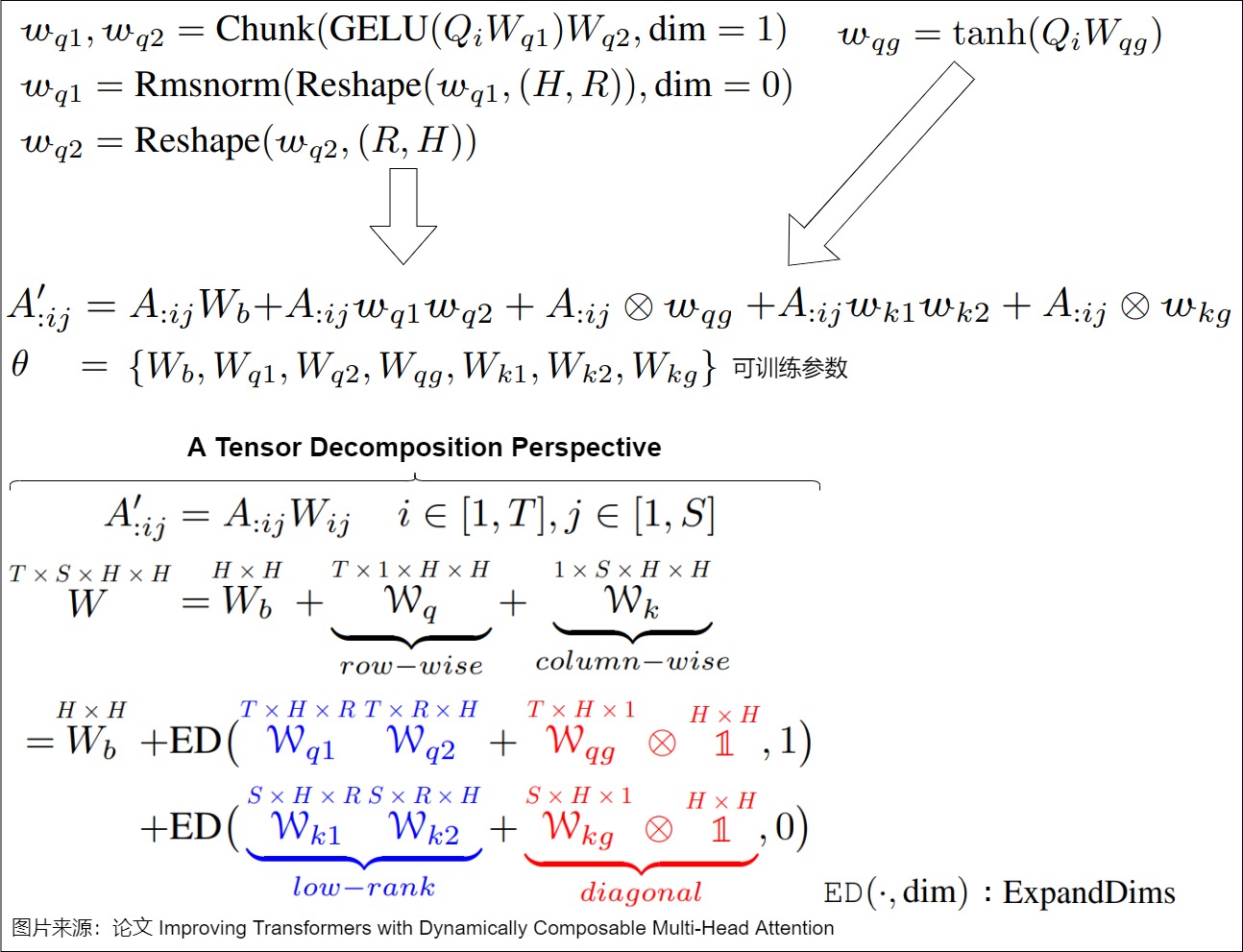
为了最大限度的增强表达能力,研究人员提出了动态决定注意力头怎样组合,即映射矩阵由输入动态生成。为了降低计算开销和显存占用,他们进一步将映射矩阵分解为一个输入无关的静态矩阵\(W_b\)、两个低秩矩阵\(w_1,w_2\)和一个对角矩阵\(Diag(w_g)\)之和,分别负责基础组合、注意力头间的有限方式(即秩R<=2)的动态组合和头自身的动态门控。其中后两个矩阵由Q矩阵和K矩阵动态生成。具体公式如下图:
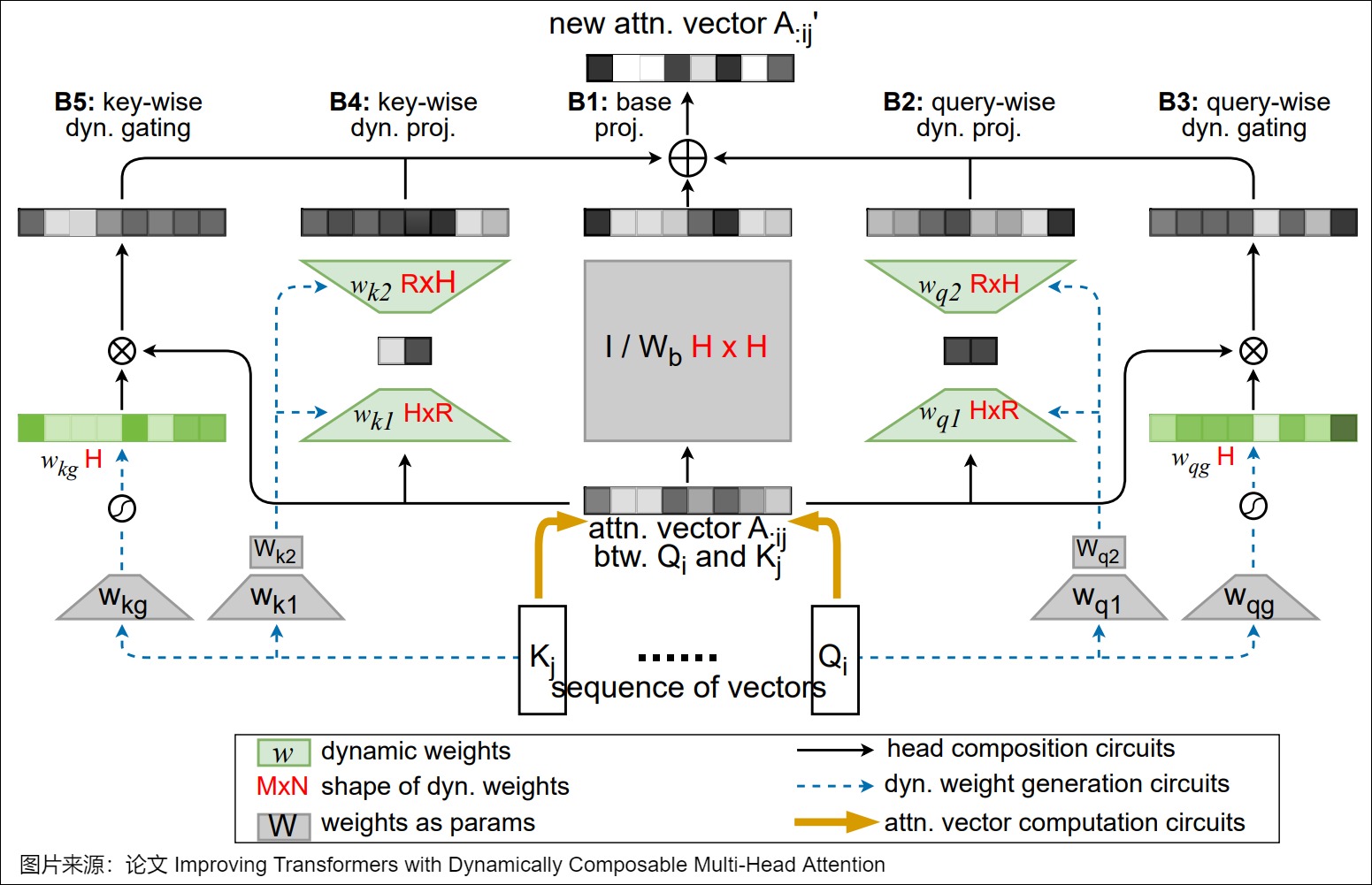
下图给出了compose的计算方式。
0xFF 参考
On the Role of Attention Masks and LayerNorm in Transformers
MOH: MULTI-HEAD ATTENTION AS MIXTURE-OFHEAD ATTENTION
Improving Transformers with Dynamically Composable Multi-Head Attention
PaLM: Scaling Language Modeling with Pathways
Multi-Head-Attention的作用到底是什么 MECH
[硬核]彻底搞懂多头注意力:全面解读Andrej Karpathy MHA代码 取个好名字真难
Transformer自下而上理解(5) 从Attention层到Transformer网络
Multiscale Visualization of Attention in the Transformer Model
What Does BERT Look At? An Analysis of BERT’s Attention
Improving Deep Transformer with Depth-Scaled Initialization and Merged Attention
Adaptively Sparse Transformers
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
《Are Sixteen Heads Really Better than One?》
Transformer多头自注意力机制的本质洞察 作者:Nikolas Adaloglou 编译:王庆法
Transformer系列:Multi-Head Attention网络结构和代码解析 xiaogp
Transformer系列:残差连接原理详细解析和代码论证 xiaogp
PaLM: Scaling Language Modeling with Pathways
MHA -> GQA:提升 LLM 推理效率 AI闲谈 [AI闲谈](javascript:void(0)
Align Attention Heads Before Merging Them: An Effective Way for Converting MHA to GQA
由Karpathy对Transformer架构的讨论引发的思考 静域AI
探秘Transformer系列之(12)--- 多头自注意力的更多相关文章
- ABP(现代ASP.NET样板开发框架)系列之12、ABP领域层——工作单元(Unit Of work)
点这里进入ABP系列文章总目录 基于DDD的现代ASP.NET开发框架--ABP系列之12.ABP领域层——工作单元(Unit Of work) ABP是“ASP.NET Boilerplate Pr ...
- java高并发系列 - 第12天JUC:ReentrantLock重入锁
java高并发系列 - 第12天JUC:ReentrantLock重入锁 本篇文章开始将juc中常用的一些类,估计会有十来篇. synchronized的局限性 synchronized是java内置 ...
- Mysql高手系列 - 第12篇:子查询详解
这是Mysql系列第12篇. 环境:mysql5.7.25,cmd命令中进行演示. 本章节非常重要. 子查询 出现在select语句中的select语句,称为子查询或内查询. 外部的select查询语 ...
- SpringMVC学习系列(12) 完结篇 之 基于Hibernate+Spring+Spring MVC+Bootstrap的管理系统实现
到这里已经写到第12篇了,前11篇基本上把Spring MVC主要的内容都讲了,现在就直接上一个项目吧,希望能对有需要的朋友有一些帮助. 一.首先看一下项目结构: InfrastructureProj ...
- Jenkins进阶系列之——12详解Jenkins节点配置
2014-03-02:修正对于lable标签的理解.(1.532.1版本已经给出了官方解释) 2013-12-22:添加JNLP端口修改,修改了一些错误. Jenkins有个很强大的功能:分布式构建( ...
- 【转】C# 视频监控系列(12):H264播放器——播放录像文件
原文地址:http://www.cnblogs.com/over140/archive/2009/03/23/1419643.html?spm=5176.100239.blogcont51182.16 ...
- 解读ASP.NET 5 & MVC6系列(12):基于Lamda表达式的强类型Routing实现
前面的深入理解Routing章节,我们讲到了在MVC中,除了使用默认的ASP.NET 5的路由注册方式,还可以使用基于Attribute的特性(Route和HttpXXX系列方法)来定义.本章,我们将 ...
- DDD理论学习系列(12)-- 仓储
DDD理论学习系列--案例及目录 1. 引言 DDD中Repository这个单词,主要有两种翻译:资源库和仓储,本文取仓储之译. 说到仓储,我们肯定就想到了仓库,仓库一般用来存放货物,而仓库一般由仓 ...
- ABP入门系列(12)——如何升级Abp并调试源码
ABP入门系列目录--学习Abp框架之实操演练 源码路径:Github-LearningMpaAbp 1. 升级Abp 本系列教程是基于Abp V1.0版本,现在Abp版本已经升级至V1.4.2(截至 ...
- JVM系列第12讲:JVM参数之查看JVM参数
今天要说的是如何查看 JVM 中已经设置的参数,包括显示参数和隐式参数. 打印显式参数 -XX:+PrintVMOptions 该参数表示程序运行时,打印虚拟机接受到的命令行显式参数.我们用下面的命令 ...
随机推荐
- 使用Apache commons-pool2实现高效的FTPClient连接池的方法
一. 连接池概述 频繁的建立和关闭连接,会极大的降低系统的性能,而连接池会在初始化的时候会创建一定数量的连接,每次访问只需从连接池里获取连接,使用完毕后再放回连接池,并不是直接关闭连接,这样可以保证 ...
- WxPython跨平台开发框架之列表数据的通用打印处理
在WxPython跨平台开发框架中,我们大多数情况下,数据记录通过wx.Grid的数据表格进行展示,其中表格的数据记录的显示和相关处理,通过在基类窗体 BaseListFrame 进行统一的处理,因此 ...
- [转]CMake:相关概念与使用入门
CMake:相关概念与使用入门(一) CMake:搜索文件和指定头文件目录(三) CMake 子工程添加 根目录中他文件夹里的cpp文件 翻译 搜索 复制
- 推荐一个双语对照的 PDF 翻译工具的开源项目:PDFMathTranslate
今天给大家推荐一个双语对照的 PDF 翻译工具的开源项目:PDFMathTranslate . 项目介绍: 基于 AI 完整保留排版的 PDF 文档全文双语翻译,支持 Google/DeepL/Oll ...
- 前端vue项目本地运行内网访问的方法
有时候在公司里,领导想在内网访问到你本地的项目,所以就有了前端项目内网访问 (1)首先在package文件里面的host改成0.0.0.0,像这个样子 (2)其次在config下的index.js里的 ...
- G1原理—5.G1垃圾回收过程之Mixed GC
大纲 1.Mixed GC混合回收是什么 2.YGC可作为Mixed GC的初始标记阶段 3.Mixed GC并发标记算法详解(一) 4.Mixed GC并发标记算法详解(二) 5.Mixed GC并 ...
- 开箱你的 AI 语音女友「GitHub 热点速览」
随着大模型 API 服务的不断丰富,开发者无需再依赖昂贵的硬件,也能轻松开发出拥有强大 AI 能力的应用.这不仅降低了技术门槛,也激发了极客们的创造力. 就比如上周飙升 1.5k Star 的开源项目 ...
- Codeforces Round 958 (Div. 2)
题目链接:Codeforces Round 958 (Div. 2) 总结:C因为常数没转\(long long\) \(wa\)两发,难绷. A. Split the Multiset fag:模拟 ...
- 浅谈云主机在VPC中进行迁移的使用场景和操作方法
本文分享自天翼云开发者社区<浅谈云主机在VPC中进行迁移的使用场景和操作方法>,作者:刘****雪 一.客户经常遇到的网络迁移问题 客户在天翼云购买一台云主机并且部署完成想要的应用后,发现 ...
- Calcite 获取jdbc连接流程
一.类调用 简介:calcite可以连接各数据源,做查询.可以收口查询权限,查询多引擎需求 二. 获取Connection发送的请求 请求介绍文档:https://calcite.apache.org ...